BigQuery
データ ウェアハウスから自律型データ AI プラットフォームへ
BigQuery は、データの取り込みから AI による分析情報の取得まで、データ ライフサイクル全体を自動化する自律型のデータから AI へのプラットフォームです。これにより、データから AI への移行、そしてアクションまでをより迅速に行うことができます。
Gemini in BigQuery の機能が BigQuery 料金モデルに含まれるようになりました。
月額無料で毎月 10 GiB のデータ保存と最大 1 TiB のクエリ実行が可能です。新規のお客様には無料クレジット $300 分も差し上げます。BigQuery やその他の Google Cloud プロダクトをお試しいただけます。

機能
組み込みの予測分析と AI 推論
BigQuery AI を使用してデータを AI に接続します。SQL を使用して、BigQuery 内で直接、予測分析モデルのトレーニングや評価を行い、デプロイできます。モデルを Gemini Enterprise Agent Platform と簡単に統合して、高度な MLOps を実現します。テキストの要約、感情分析、データ拡充に、AI 関数を活用してワークフローで生成 AI を利用できます。従来のテーブルだけでなく、BigQuery Graph を使用して、データ内の複雑な関係やパターンを明らかにできます。エンベディングとベクトル検索、テキスト検索、ハイブリッド検索を使用して、洗練されたコンテキスト検索と RAG アプリケーションを構築し、キーワードだけでなく意味に基づいて情報を見つけます。

すべてのデータチームにエージェント エクスペリエンスを提供
すべての分析ワークフローで、すべてのデータユーザーが AI を活用した支援と自動化を利用できます。データ エンジニアリング エージェントを使用して、データ準備、エラー検出、変換、パイプライン構築を自動化します。データ サイエンス エージェントで簡単なプロンプトを入力するだけで、詳細な計画を生成し、データの読み込み、特徴量エンジニアリング、モデルのトレーニング、評価など、データ サイエンスのあらゆる側面を実行できます。会話型分析エージェントを使用して分析情報を誰でも利用できるようにすることで、誰もが平易な言葉で複雑な質問をし、グラウンディングされたコンテキストに応じた回答を得られるようになります。

エージェントの開発と分析のツール
Conversational Analytics API を使用して、ワークフローに自然言語クエリ機能を埋め込みます。BigQuery MCP サーバー、ADK インテグレーション、OSS MCP ツールボックスを使用して、Gemini CLI を含むさまざまな IDE やデベロッパー ツールから BigQuery に簡単に接続できます。ADK、LangGraph、UCP などのフレームワーク用の BigQuery エージェント オペレーション プラグインを使用すると、詳細なエージェントのインタラクションを BigQuery にストリーミングして、1 行のコードでパフォーマンスとコストを最適化できます。

Apache Iceberg の BigQuery のスケールとパフォーマンス
BigQuery、Google Cloud Managed Service for Apache Spark、その他の OSS エンジン間で読み取りと書き込みの相互運用性を実現し、データ移動をゼロにすることで、BigQuery の最高のパフォーマンスを Iceberg データにもたらします。高スループットのストリーミングを介してリアルタイムの分析情報を取得し、マルチステートメント トランザクションと CDC でパイプラインを簡素化します。Google Cloud Lakehouse は、コンパクションやクラスタリングなどの Iceberg の定期メンテナンスを自動化し、費用対効果を最適化して手動によるオーバーヘッドを排除します。
ガバナンスを自動化し、エージェントにコンテキストを与える
Knowledge Catalog を活用した自動メタデータ収集、データ プロファイリング、データ品質、リネージなどの主要な機能により、組み込みのコンテキストを取得できます。エージェントが企業データから包括的なコンテキストを取得できるようにします。セマンティック検索、Context API、MCP ツールによって、エージェントは、データアセットを即座に発見し、事前に生成されたメタデータを抽出して拡充できます。
エンタープライズ規模と効率性を追求した構築
BigQuery の独自のアーキテクチャでは、ストレージとコンピューティングが分離されているため、ペタバイト規模の分析が可能になります。また、圧縮ストレージ、コンピューティングの自動スケーリング、柔軟な料金設定などにより、費用を最適化できます。BigQuery では、Borg、Colossus、Jupiter、Dremel などのさまざまな Google インフラストラクチャ テクノロジーが採用されています。流動的なスケーリングなどのイノベーションにより、1 秒単位の課金を実現します。また、高度なランタイムと履歴ベースの最適化により、コードやスキーマを変更することなく、ネイティブ ワークロードと Iceberg ワークロードの処理が高速化されます。
ストリーミング データ パイプラインによるリアルタイム分析
Managed Service for Apache Kafka を使用して、リアルタイム ストリーミング アプリケーションをビルドして実行できます。BigQuery の継続的クエリによる SQL ベースの簡単なストリーミングから、人気のオープンソース Kafka プラットフォーム、Iceberg のサポートを含む Dataflow による高度なマルチモーダル データ ストリーミングや ML まで、リアルタイムのデータと AI の連携を実現できます。
マネージド障害復旧とオブザーバビリティ
クロスリージョンの障害復旧は、高度なオブザーバビリティとインターセクション ルーティングを強化したマネージド フェイルオーバー、バックアップ、データ復旧を提供します。BigQuery の運用健全性のモニタリングでは、組織全体の環境ビューが提供されます。このたび、エージェントを活用したオブザーバビリティが導入され、すぐに使えるトラブルシューティングが利用できるようになりました。さらに、Security Center を介したエージェント対応のセキュリティにより、統合されたきめ細かいアクセス制御が提供されます。これらの機能により、データ オペレーションの柔軟な復元、可視性の向上、堅牢なセキュリティが確保されます。

データ サイエンス
データを AI 活用へつなげるためのワークフローを簡素化
データを AI 活用へつなげるためのワークフローを簡素化
BigQuery DataFrames を使用して、組み込みのエージェントやオープンソースの Python ライブラリで、Colab Enterprise ノートブック上のエンドツーエンドのデータ サイエンス ワークフローを合理化します。SQL、サーバーレス Spark、その他のオープンソース フレームワークなど、お好みの処理エンジンを使用できます。BigQuery 内で ML モデルを直接トレーニング、評価、デプロイすることも、SQL を使用して TimesFM などの事前トレーニング済みモデルを使用することもできます。BigQuery で構築および使用されるモデルの特徴量を便利に保存できます。Gemini Enterprise Agent Platform に登録することで、1 つのインターフェースを使用して、モデルのバージョン管理、評価、デプロイを行い、オンライン予測を実行できるようになります。
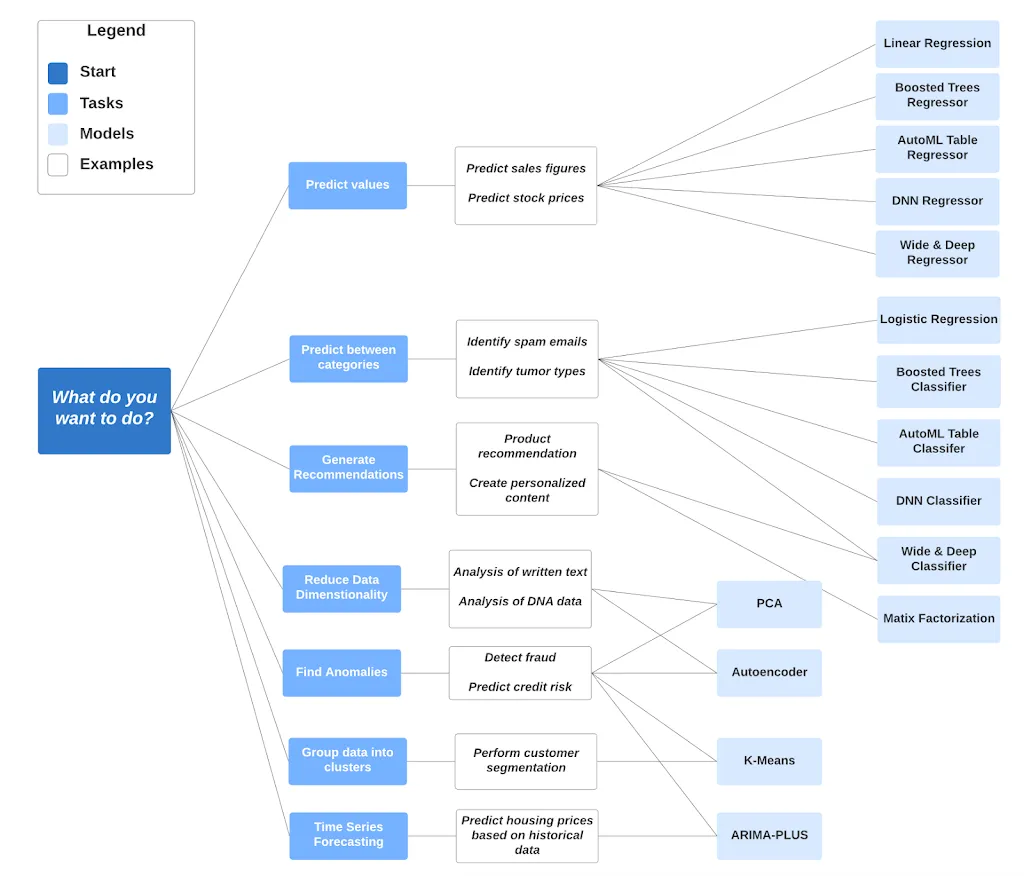
チュートリアル、クイックスタート、ラボ
データを AI 活用へつなげるためのワークフローを簡素化
データを AI 活用へつなげるためのワークフローを簡素化
BigQuery DataFrames を使用して、組み込みのエージェントやオープンソースの Python ライブラリで、Colab Enterprise ノートブック上のエンドツーエンドのデータ サイエンス ワークフローを合理化します。SQL、サーバーレス Spark、その他のオープンソース フレームワークなど、お好みの処理エンジンを使用できます。BigQuery 内で ML モデルを直接トレーニング、評価、デプロイすることも、SQL を使用して TimesFM などの事前トレーニング済みモデルを使用することもできます。BigQuery で構築および使用されるモデルの特徴量を便利に保存できます。Gemini Enterprise Agent Platform に登録することで、1 つのインターフェースを使用して、モデルのバージョン管理、評価、デプロイを行い、オンライン予測を実行できるようになります。
非構造化データの分析
生成 AI をデータに適用
生成 AI をデータに適用
シンプルな SQL 関数を使用して、Google とパートナーの AI モデルを BigQuery のマルチモーダル データに直接接続できます。生成 AI 機能を使用して、画像、PDF、音声、動画からより深く、より意味のある理解を引き出します。専用のマネージド AI 関数を使用して、分類、順序付け、フィルタリングなどのルーティン タスクを自動化し、Cloud AI API を使用して音声文字起こしや機械翻訳などの特定のタスクを実行します。リモート関数とオブジェクト テーブルを使用して Cloud Storage の非構造化データを分析するか、BigQuery AI 関数を使用して推論を実行します。

チュートリアル、クイックスタート、ラボ
生成 AI をデータに適用
生成 AI をデータに適用
シンプルな SQL 関数を使用して、Google とパートナーの AI モデルを BigQuery のマルチモーダル データに直接接続できます。生成 AI 機能を使用して、画像、PDF、音声、動画からより深く、より意味のある理解を引き出します。専用のマネージド AI 関数を使用して、分類、順序付け、フィルタリングなどのルーティン タスクを自動化し、Cloud AI API を使用して音声文字起こしや機械翻訳などの特定のタスクを実行します。リモート関数とオブジェクト テーブルを使用して Cloud Storage の非構造化データを分析するか、BigQuery AI 関数を使用して推論を実行します。
データ ウェアハウスの移行
データ ウェアハウスを BigQuery に移行する
データ ウェアハウスを BigQuery に移行する
データ ウェアハウスを BigQuery に移行することで、現在の分析ニーズと今後の AI ユースケースに対応できます。AI を搭載した無料でフルマネージドの BigQuery Migration Service を使用して、Netezza、Oracle、Redshift、Teradata、Snowflake、Databricks から BigQuery への移行プロセスを合理化できます。
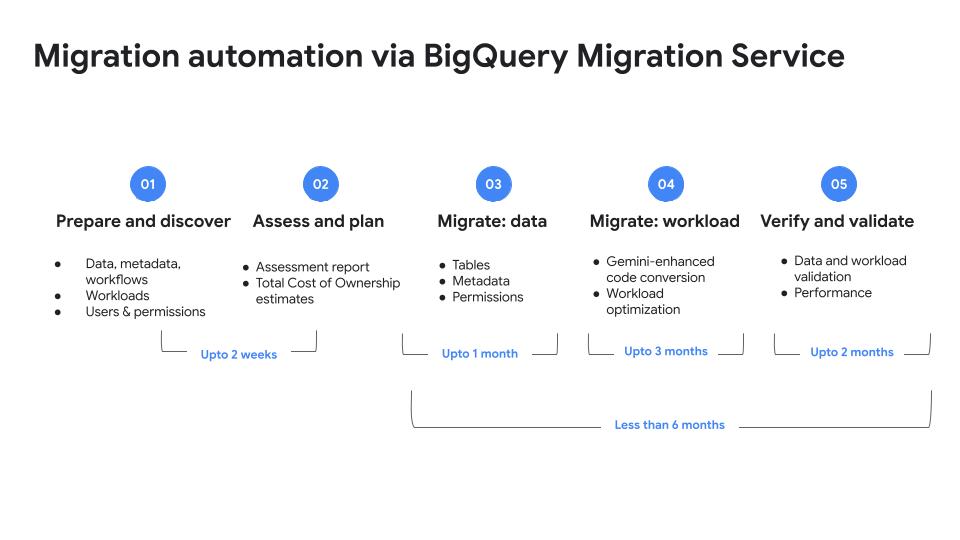
チュートリアル、クイックスタート、ラボ
データ ウェアハウスを BigQuery に移行する
データ ウェアハウスを BigQuery に移行する
データ ウェアハウスを BigQuery に移行することで、現在の分析ニーズと今後の AI ユースケースに対応できます。AI を搭載した無料でフルマネージドの BigQuery Migration Service を使用して、Netezza、Oracle、Redshift、Teradata、Snowflake、Databricks から BigQuery への移行プロセスを合理化できます。
データ統合と ELT
あらゆるデータを BigQuery に取り込む
あらゆるデータを BigQuery に取り込む
ELT は、データを BigQuery に取り込むための推奨パターンです。データ統合を柔軟に行うためのツールは多数あります。バッチ読み込み: BigQuery Data Transfer Service(DTS)を使用して、サポートされているデータソースから BigQuery へのデータの一括読み込みを自動化します。ストリーミング読み込み: Pub/Sub BigQuery サブスクリプションは、受信した Pub/Sub メッセージを既存の BigQuery テーブルに書き込みます。変更データ キャプチャ(CDC): Datastream は、データベースから BigQuery への非干渉型の変更データ キャプチャ(CDC)を可能にします。最後に、データの移動を必要としない外部データソースへの連携が可能です。
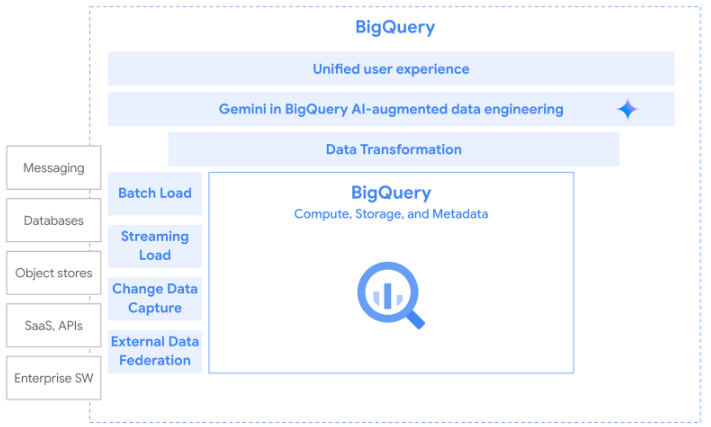
チュートリアル、クイックスタート、ラボ
あらゆるデータを BigQuery に取り込む
あらゆるデータを BigQuery に取り込む
ELT は、データを BigQuery に取り込むための推奨パターンです。データ統合を柔軟に行うためのツールは多数あります。バッチ読み込み: BigQuery Data Transfer Service(DTS)を使用して、サポートされているデータソースから BigQuery へのデータの一括読み込みを自動化します。ストリーミング読み込み: Pub/Sub BigQuery サブスクリプションは、受信した Pub/Sub メッセージを既存の BigQuery テーブルに書き込みます。変更データ キャプチャ(CDC): Datastream は、データベースから BigQuery への非干渉型の変更データ キャプチャ(CDC)を可能にします。最後に、データの移動を必要としない外部データソースへの連携が可能です。
リアルタイム分析
イベント ドリブン分析
イベント ドリブン分析
イベント ドリブンな分析でビジネス イベントにリアルタイムで対応します。SQL ベースの継続的クエリなどの組み込みのストリーミング機能を使用すると、ストリーミング データを自動的に取り込み、直ちにクエリできます。これにより、アジリティの維持や、最新のデータに基づいたビジネス上の意思決定が可能になります。一方、Dataflow を使用すると、包括的なソリューションとしてシンプルで高速なストリーミング データ パイプラインを実現できます。

チュートリアル、クイックスタート、ラボ
イベント ドリブン分析
イベント ドリブン分析
イベント ドリブンな分析でビジネス イベントにリアルタイムで対応します。SQL ベースの継続的クエリなどの組み込みのストリーミング機能を使用すると、ストリーミング データを自動的に取り込み、直ちにクエリできます。これにより、アジリティの維持や、最新のデータに基づいたビジネス上の意思決定が可能になります。一方、Dataflow を使用すると、包括的なソリューションとしてシンプルで高速なストリーミング データ パイプラインを実現できます。
地理空間分析
豊富で使いやすい地理空間データセットで地球規模の分析情報を引き出します
豊富で使いやすい地理空間データセットで地球規模の分析情報を引き出します
豊富な地理空間データ、強力なクラウド コンピューティング、組み込みの AI ツールからなるポートフォリオにアクセスして、分析情報をより簡単に引き出し、より多くの情報に基づいてより迅速に、ビジネスやサステナビリティに関する意思決定を行うことができます。リモート センシングや GIS の専門知識は不要です。Earth Engine の画像と Google Maps Platform の多様なデータセットを BigQuery ワークフローに直接取り込むことができます。これには、プレイス、ルート、ストリートビュー、航空画像と衛星画像、人口動態、大気質、花粉、天気データへのシームレスなアクセスが含まれます。
チュートリアル、クイックスタート、ラボ
豊富で使いやすい地理空間データセットで地球規模の分析情報を引き出します
豊富で使いやすい地理空間データセットで地球規模の分析情報を引き出します
豊富な地理空間データ、強力なクラウド コンピューティング、組み込みの AI ツールからなるポートフォリオにアクセスして、分析情報をより簡単に引き出し、より多くの情報に基づいてより迅速に、ビジネスやサステナビリティに関する意思決定を行うことができます。リモート センシングや GIS の専門知識は不要です。Earth Engine の画像と Google Maps Platform の多様なデータセットを BigQuery ワークフローに直接取り込むことができます。これには、プレイス、ルート、ストリートビュー、航空画像と衛星画像、人口動態、大気質、花粉、天気データへのシームレスなアクセスが含まれます。
料金
| BigQuery の料金の仕組み | BigQuery の料金は、コンピューティング(分析)、ストレージ、追加サービス、データの取り込みと抽出に基づいています。データの読み込みとエクスポートは無料です。 | |
|---|---|---|
| サービスと用途 | サブスクリプション タイプ | 料金(米ドル) |
無料枠 | BigQuery の無料枠では、10 GiB のストレージ、オンデマンド コンピューティングで 1 か月あたり最大 1 TiB のクエリ、その他のリソースを無料でご利用いただけます。 | 無料 |
コンピューティング(分析) | オンデマンド 通常、最大 2,000 個の同時実行スロットが提供されます。これらのスロットは 1 つのプロジェクトのすべてのクエリで共有されます。 | 目安 $6.25 スキャンした TiB あたり。毎月 1 TiB まで無料。 |
エディション: Standard、Enterprise、Enterprise Plus Gemini in BigQuery の AI アシスタンス機能が含まれます。 | 目安 $0.04 スロット時間あたり | |
ストレージ | 論理ストレージ 過去 90 日間に変更が加えられたテーブルまたはテーブル パーティションで使用されている、未圧縮のバイト数に基づいて計算されます。 | 目安 $0.01 1 GiB あたり。毎月 10 GiB まで無料。 |
物理ストレージ 連続する 90 日間に変更が加えられたテーブルまたはテーブル パーティションで使用されている、圧縮されたバイト数に基づいて計算されます。 | 目安 $0.02 1 GiB あたり。毎月 10 GiB まで無料。 | |
データの取り込み | バッチ読み込み Cloud Storage からテーブルをインポートします。 | 無料 共有スロットプールを使用する場合 |
ストリーミング挿入 挿入に成功した行が課金対象になります。最小 1 KB で各行が計算されます。 | $0.01 200 MiB あたり | |
BigQuery Storage Write API BigQuery に読み込まれたデータには、BigQuery ストレージの料金または Cloud Storage の料金が適用されます。 | $0.025 1 GiB あたり。毎月 2 TiB まで無料。 | |
データの抽出 | バッチ エクスポート テーブルデータを Cloud Storage にエクスポートします。 | 無料 共有スロットプールを使用する場合 |
ストリーミング読み取り Storage Read API を使用して、テーブルデータをストリーミング読み取りします。 | 目安 $1.10 読み取った TiB あたり | |
エージェント | 入力データ データ サイエンス エージェント、データ エンジニアリング エージェント、会話型分析エージェント | $3 トークン 100 万個あたり |
出力データ データ サイエンス エージェント、データ エンジニアリング エージェント、会話型分析エージェント | $20 トークン 100 万個あたり | |
BigQuery の料金の詳細をご覧ください。 すべての料金の詳細を見る。
BigQuery の料金の仕組み
BigQuery の料金は、コンピューティング(分析)、ストレージ、追加サービス、データの取り込みと抽出に基づいています。データの読み込みとエクスポートは無料です。
無料枠
BigQuery の無料枠では、10 GiB のストレージ、オンデマンド コンピューティングで 1 か月あたり最大 1 TiB のクエリ、その他のリソースを無料でご利用いただけます。
無料
コンピューティング(分析)
オンデマンド
通常、最大 2,000 個の同時実行スロットが提供されます。これらのスロットは 1 つのプロジェクトのすべてのクエリで共有されます。
Starting at
$6.25
スキャンした TiB あたり。毎月 1 TiB まで無料。
エディション: Standard、Enterprise、Enterprise Plus
Gemini in BigQuery の AI アシスタンス機能が含まれます。
Starting at
$0.04
スロット時間あたり
ストレージ
論理ストレージ
過去 90 日間に変更が加えられたテーブルまたはテーブル パーティションで使用されている、未圧縮のバイト数に基づいて計算されます。
Starting at
$0.01
1 GiB あたり。毎月 10 GiB まで無料。
物理ストレージ
連続する 90 日間に変更が加えられたテーブルまたはテーブル パーティションで使用されている、圧縮されたバイト数に基づいて計算されます。
Starting at
$0.02
1 GiB あたり。毎月 10 GiB まで無料。
データの取り込み
バッチ読み込み
Cloud Storage からテーブルをインポートします。
無料
共有スロットプールを使用する場合
ストリーミング挿入
挿入に成功した行が課金対象になります。最小 1 KB で各行が計算されます。
$0.01
200 MiB あたり
BigQuery Storage Write API
BigQuery に読み込まれたデータには、BigQuery ストレージの料金または Cloud Storage の料金が適用されます。
$0.025
1 GiB あたり。毎月 2 TiB まで無料。
データの抽出
バッチ エクスポート
テーブルデータを Cloud Storage にエクスポートします。
無料
共有スロットプールを使用する場合
ストリーミング読み取り
Storage Read API を使用して、テーブルデータをストリーミング読み取りします。
Starting at
$1.10
読み取った TiB あたり
エージェント
入力データ
データ サイエンス エージェント、データ エンジニアリング エージェント、会話型分析エージェント
$3
トークン 100 万個あたり
出力データ
データ サイエンス エージェント、データ エンジニアリング エージェント、会話型分析エージェント
$20
トークン 100 万個あたり
BigQuery の料金の詳細をご覧ください。 すべての料金の詳細を見る。
ビジネスケース
何万ものお客様がデータから AI プラットフォームを構築するために BigQuery を選択しています
Mattel は BigQuery で自社のデータを AI と連携させることで、時間と費用を削減しています。
Mattel 社リード データ サイエンティスト TJ Allard 氏
「BigQuery と Vertex AI により、Google のデータと AI がすべて単一のプラットフォームに統合されます。これにより、お客様からのフィードバックに対する対応方法が、長時間の手作業から数秒で完了するシンプルな自然言語クエリへと変化し、お客様の分析情報を数か月ではなく数分で取得できるようになりました。」
BigQuery の相違点を確認
AI を活用したイノベーション。会話型検索、インテリジェント検索、まったく新しいエージェント エクスペリエンスを、セマンティック レイヤで強化して精度を高めています。
データを AI プラットフォームに統合し、ガバナンス、ランタイム メタデータ、セキュリティを統合して、マルチモーダル データのシームレスな分析、AI の共同処理、リアルタイムの分析情報を実現します。
柔軟で将来性のある低コストの AI と、サードパーティやオープンソースとのシームレスな相互運用性。
パートナーとインテグレーション
BigQuery の専門知識を持つパートナーとの連携



































































































ETL とデータ統合
リバース ETL と MDM
BI とデータの可視化
データのガバナンスとセキュリティ
コネクタとデベロッパー ツール
ML と高度な分析
データ品質とオブザーバビリティ
コンサルティング パートナー
データの取り込みから可視化まで、多くのパートナーが独自のデータ ソリューションを BigQuery に統合しています。上に記しているのは Google Cloud Ready - BigQuery に対応したパートナー インテグレーションです。
BigQuery パートナーについては、Partners ディレクトリをご覧ください。
その他のお問い合わせとサポート
よくある質問
BigQuery は他のエンタープライズ データ ウェアハウスとどのような点で異なりますか?
BigQuery は、Google Cloud が提供するフルマネージドの完全にサーバーレスなエンタープライズ データ ウェアハウスです。すべてのデータ型をサポートし、各種のクラウドで機能します。また、統合プラットフォーム内に 機械学習 とビジネス インテリジェンスがすべて組み込まれています。ネイティブの Vertex AI 統合により、BigQuery から離れることなく、データを業界をリードする Google の AI に簡単に接続できます。
エンタープライズ データ ウェアハウスとは何ですか?
エンタープライズ データ ウェアハウスは、さまざまなソースの構造化データと半構造化データの分析とレポートに使用されるシステムです。多くの組織はオンプレミスにある従来のデータ ウェアハウスからクラウド データ ウェアハウスに移行することで、さらに費用を削減し、スケーラビリティと柔軟性の向上を実現しています。
BigQuery はどのくらい安全ですか?
BigQuery では、高可用性と 99.99% の稼働時間 SLA を実現する強固なセキュリティ、ガバナンス、信頼性を確保できます。データはデフォルトで暗号化され、顧客管理の暗号鍵によって保護されます。
BigQuery の使用を開始するにはどうすればよいですか?
BigQuery の使用を開始する方法はいくつかあります。新規のお客様には、BigQuery のお支払いに使用できる無料クレジットを $300 分進呈します。すべてのお客様は、10 GB のストレージと 1 か月あたり最大 1 TB のクエリを無料でご利用になれます。クレジットに対する課金はありません。これらのクレジットは、BigQuery の無料トライアルにお申し込みいただくと獲得できます。まだご決断されていない場合は、BigQuery サンドボックスをぜひお試しください。クレジット カードの登録は不要です。
BigQuery サンドボックスとは何ですか?
BigQuery サンドボックスでは、クレジット カードなしで BigQuery を試すことができます。BigQuery の無料枠は自動的に維持されます。サンドボックスでは、一般公開データセットを使ったクエリや分析を実際にお試しいただけます。独自のデータを BigQuery サンドボックスに取り込んで分析することもできます。無料トライアルに更新した新規のお客様には、BigQuery で使える $300 分のクレジットを差し上げています。
企業による BigQuery の最も一般的な使用方法はどのようなものですか?
あらゆる規模の企業が、すべてのビジネスデータを対象にデータ分析を行って知見を得るために、サイロ化したデータを BigQuery で 1 か所に集約しています。これにより、リアルタイムで意思決定を行い、ビジネス レポートを合理化し、ML をデータ分析に組み込んで将来のビジネス チャンスを予測できます。


















