In dieser Anleitung wird eine einsatzbereite Lösung vorgestellt, die Google Distributed Cloud und Config Sync verwendet, um Kubernetes-Cluster in großem Maßstab auf Edge-Geräten bereitzustellen. Diese Anleitung richtet sich an Plattformbetreiber und Entwickler. Sie sollten mit den folgenden Technologien und Konzepten vertraut sein:
- Ansible-Playbooks.
- Edge-Bereitstellungen und ihre Herausforderungen
- Mit einem Google Cloud-Projekt arbeiten
- Container-Webanwendung bereitstellen
gcloud- undkubectl-Befehlszeilenschnittstellen.
In dieser Anleitung verwenden Sie virtuelle Compute Engine-Maschinen (VMs), um auf Edge-Geräten bereitgestellte Knoten zu emulieren, und eine Beispiel-Point-of-Sale-Anwendung als Edge-Arbeitslast. Google Distributed Cloud und Config Sync bieten eine zentrale Verwaltung und Steuerung für Ihren Edge-Cluster. Config Sync ruft neue Konfigurationen dynamisch aus GitHub ab und wendet diese Richtlinien und Konfigurationen auf Ihre Cluster an.
Edge-Bereitstellungsarchitektur
Eine Edge-Bereitstellung für den Einzelhandel ist eine gute Möglichkeit, die Architektur zu veranschaulichen, die in einer typischen Google Distributed Cloud-Bereitstellung verwendet wird.
Ein Ladengeschäft ist der nächstgelegene Interaktionspunkt zwischen einer Geschäftseinheit eines Unternehmens und dem Kunden. Softwaresysteme in Geschäften müssen ihre Arbeitslasten ausführen, zeitnah Updates erhalten und kritische Messwerte getrennt vom zentralen Verwaltungssystem des Unternehmens melden. Darüber hinaus müssen diese Softwaresysteme so konzipiert werden, dass sie in Zukunft auf weitere Filialstandorte erweitert werden können. Während Google Distributed Cloud alle diese Anforderungen an Ladensoftwaresysteme erfüllt, ermöglicht das Edge-Profil einen wichtigen Anwendungsfall: Bereitstellungen in Umgebungen mit begrenzten Hardwareressourcen, z. B. in Ladengeschäften.
Das folgende Diagramm zeigt eine Google Distributed Cloud-Bereitstellung, die das Edge-Profil in einem Einzelhandelsgeschäft verwendet:
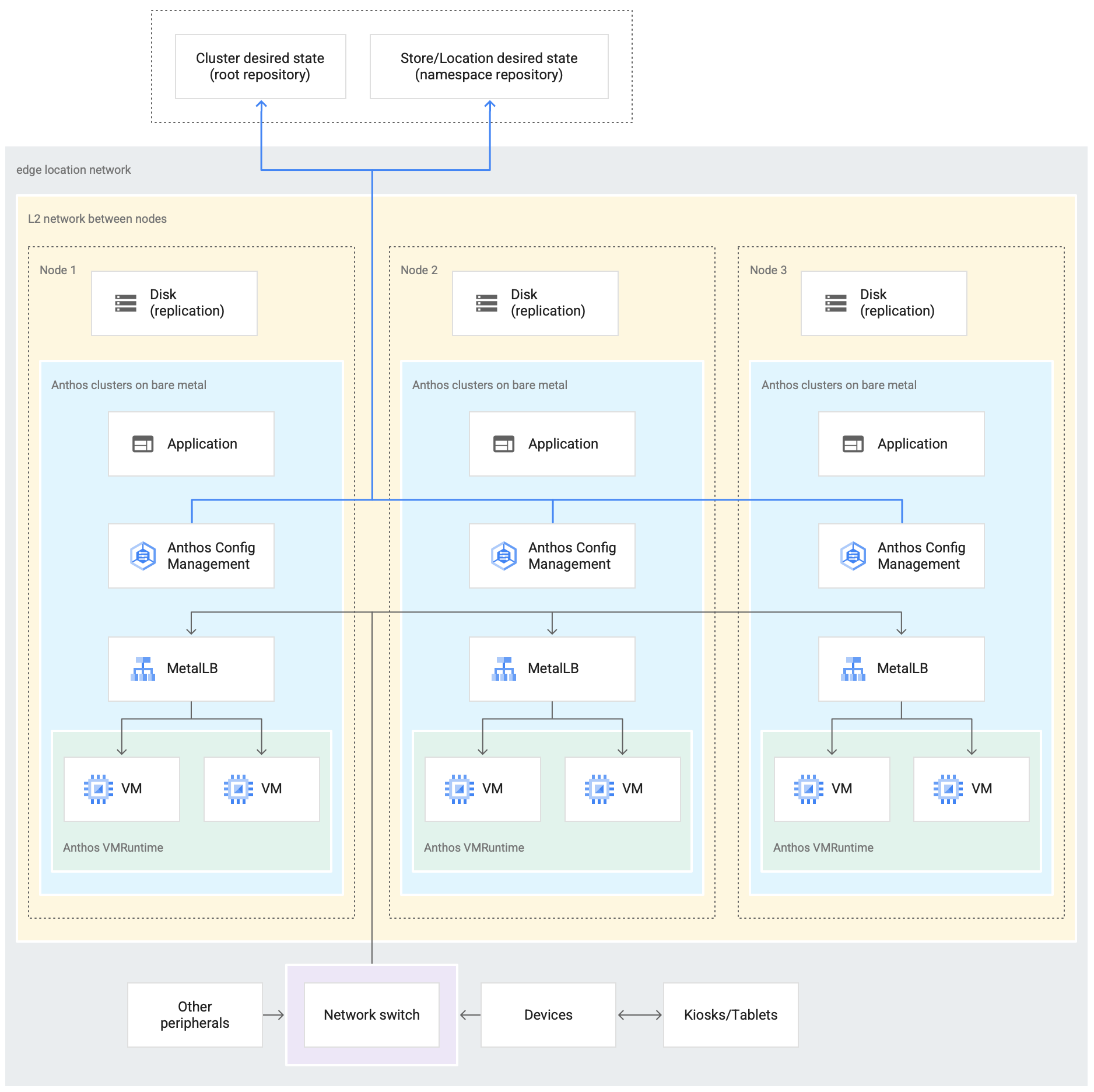
Das obige Diagramm zeigt ein typisches Ladengeschäft. Das Geschäft verfügt über intelligente Geräte wie Kartenlesegeräte, Kassenautomaten, Kameras und Drucker.
Außerdem verfügt der Speicher über drei physische Computer-Hardwaregeräte (Node 1, Node 2 und Node 3). Alle diese Geräte sind mit einem zentralen Netzwerk-Switch verbunden. Daher sind die drei Rechengeräte über ein Schicht-2-Netzwerk miteinander verbunden. Die miteinander verbundenen Rechengeräte bilden die Bare-Metal-Infrastruktur.
Google Distributed Cloud wird auf jedem der drei Rechengeräte ausgeführt. Diese Geräte haben außerdem einen eigenen Laufwerkspeicher und sind für die Datenreplikation zwischen ihnen für Hochverfügbarkeit konfiguriert.
Das Diagramm zeigt auch die folgenden Hauptkomponenten, die Teil einer Google Distributed Cloud-Bereitstellung sind:
- Die als MetalLB gekennzeichnete Komponente ist der gebündelte Load-Balancer, der mit Google Distributed Cloud bereitgestellt wird.
- Die Config Sync-Komponente ermöglicht die Synchronisierung des Clusterstatus mit Quell-Repositories. Dieses optionale Add-on wird dringend empfohlen und erfordert eine separate Installation und Konfiguration. Weitere Informationen zum Einrichten von Config Sync und zur anderen Nomenklatur finden Sie in der Config Sync-Dokumentation.
Das Root-Repository und das Namespace-Repository, die sich oben im Diagramm außerhalb des Speicherstandorts befinden, stellen zwei Quell-Repositories dar.
Änderungen am Cluster werden an diese zentralen Quell-Repositories übertragen. Google Distributed Cloud-Bereitstellungen an verschiedenen Edge-Standorten rufen Updates aus den Quell-Repositories ab. Dieses Verhalten wird durch die Pfeile dargestellt, die die beiden Repositories im Diagramm mit den Config Sync-Komponenten innerhalb des GKE on Bare Metal-Clusters verbinden, der auf den Geräten ausgeführt wird.
Eine weitere wichtige Komponente, die als Teil des Clusters dargestellt wird, ist die VM-Laufzeit auf GDC. Mit der VM-Laufzeit auf GDC können vorhandene VM-basierte Arbeitslasten im Cluster ohne Containerisierung ausgeführt werden. In der Dokumentation zur VM-Laufzeit auf GDC wird erläutert, wie Sie sie aktivieren und Ihre VM-Arbeitslasten im Cluster bereitstellen.
Die als Anwendung gekennzeichnete Komponente bezeichnet Software, die vom Einzelhandelsgeschäft im Cluster bereitgestellt wird. Die Kassenanwendung, die an den Kiosken eines Einzelhandelsgeschäfts angezeigt wird, könnte ein Beispiel für eine solche Anwendung sein.
Die Felder unten im Diagramm stellen die vielen Geräte (z. B. Kioske, Tablets oder Kameras) in einem Einzelhandelsgeschäft dar, die alle mit einem zentralen Netzwerk-Switch verbunden sind. Das lokale Netzwerk im Speicher ermöglicht es den Anwendungen, die in der Google Distributed Cloud-Bereitstellung ausgeführt werden, diese Geräte zu erreichen.
Im nächsten Abschnitt sehen Sie die Emulation dieser Bereitstellung in einem Einzelhandelsgeschäft in Google Cloud mithilfe von Compute Engine-VMs. Diese Emulation verwenden Sie in der folgenden Anleitung, um mit Google Distributed Cloud zu experimentieren.
Emulierte Edge-Bereitstellung in Google Cloud
Im folgenden Diagramm sehen Sie alles, was Sie in dieser Anleitung in Google Cloud eingerichtet haben. Dieses Diagramm entspricht dem Einzelhandelsdiagramm aus dem vorherigen Abschnitt. Diese Bereitstellung stellt einen emulierten Edge-Standort dar, an dem die Point-of-Sale-Anwendung bereitgestellt wird. Die Architektur zeigt auch eine einfache Arbeitslast einer Beispielanwendung für eine Kasse, die Sie in dieser Anleitung verwenden. Sie greifen über einen Webbrowser als Kiosk auf die Point-of-Sale-Anwendung im Cluster zu.
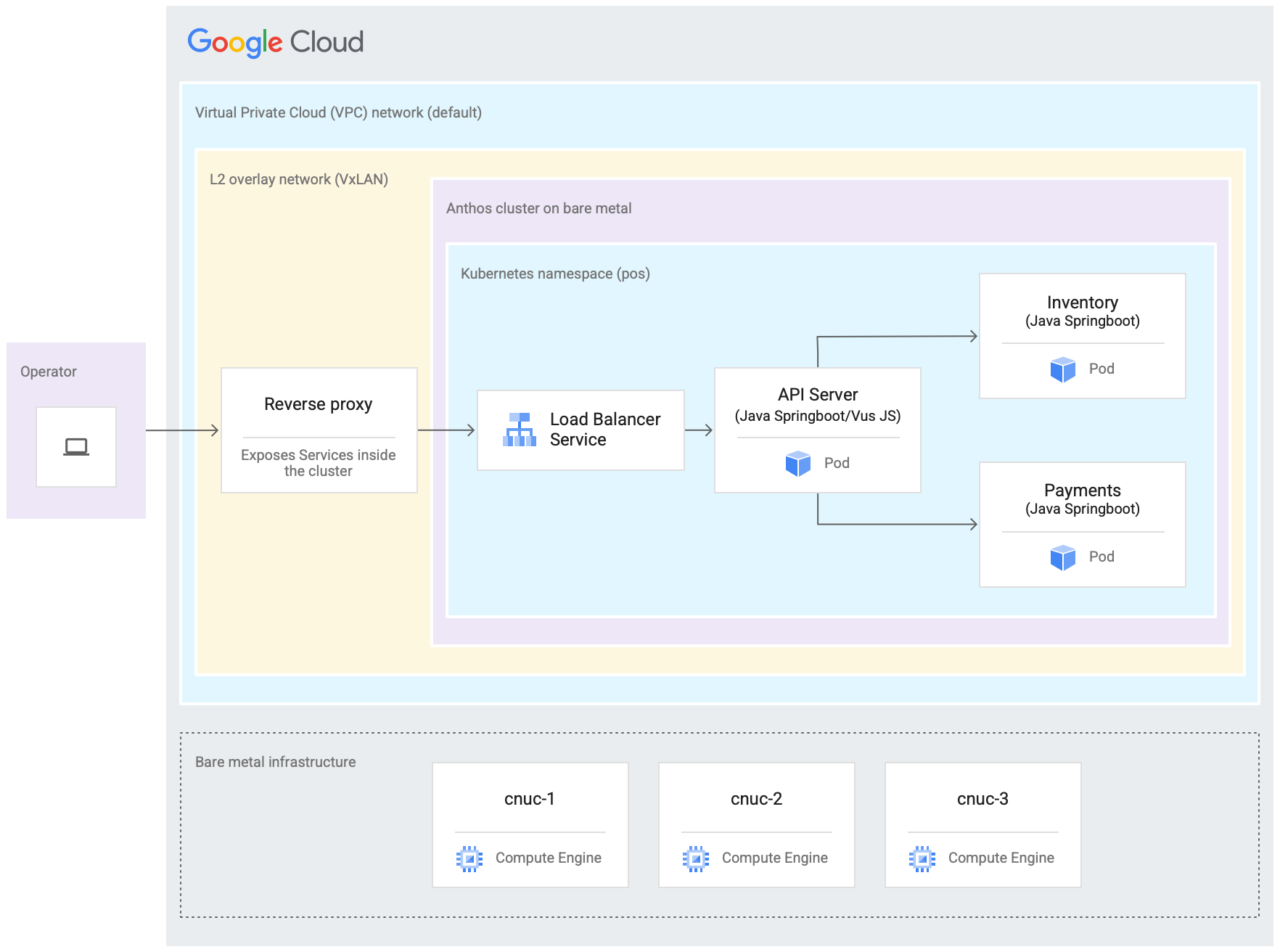
Die drei virtuellen Compute Engine-Maschinen (VMs) im vorherigen Diagramm stellen die physische Hardware (oder Knoten) an einem typischen Edge-Standort dar. Diese Hardware wird über Netzwerk-Switches verbunden, um die Bare-Metal-Infrastruktur zu erstellen. In unserer emulierten Umgebung in Google Cloud sind diese VMs über das standardmäßige VPC-Netzwerk (Virtual Private Cloud) im Google Cloud-Projekt miteinander verbunden.
In einer typischen Google Distributed Cloud-Installation können Sie eigene Load-Balancer konfigurieren. In dieser Anleitung richten Sie jedoch keinen externen Load-Balancer ein. Verwenden Sie stattdessen den gebündelten MetalLB-Load-Balancer, der mit Google Distributed Cloud installiert ist. Der gebündelte MetalLB-Load-Balancer erfordert eine Ebene-2-Netzwerkverbindung zwischen den Knoten. Daher wird die Ebene-2-Verbindung zwischen den Compute Engine-VMs durch Erstellen eines VxLAN-Overlay-Netzwerks auf dem standardmäßigen VPC-Netzwerk (Virtual Private Cloud) aktiviert.
Im Rechteck mit der Bezeichnung L2 Overlay Network (VxLAN) sind die Softwarekomponenten zu sehen, die in den drei Compute Engine-VMs ausgeführt werden. Dieses Rechteck enthält den GKE on Bare Metal-Cluster und einen Reverse-Proxy. Der Cluster wird durch das Rechteck Google Distributed Cloud dargestellt. Dieses Rechteck, das den Cluster darstellt, enthält ein weiteres Rechteck mit der Kennzeichnung Kubernetes-Namespace (pos). Dies stellt einen Kubernetes-Namespace im Cluster dar. Alle Komponenten in diesem Kubernetes-Namespace bilden die Point-of-Sale-Anwendung, die im GKE on Bare Metal-Cluster bereitgestellt wird. Die Point-of-Sale-Anwendung umfasst drei Mikrodienste: API-Server, Inventar und Zahlungen. Alle diese Komponenten stellen zusammen eine "Anwendung" dar, die im früheren Diagramm der Edge-Rollout-Architektur gezeigt wurde.
Der gebündelte MetalLB-Load-Balancer des GKE on Bare Metal-Clusters kann nicht direkt von außerhalb der VMs erreicht werden. Das Diagramm zeigt einen NGINX-Reverse-Proxy, der so konfiguriert wird, dass er in den VMs ausgeführt wird, um den von den Compute Engine-VMs eingehenden Traffic an den Load-Balancer weiterzuleiten. Dies ist nur eine Problemumgehung für die Zwecke dieser Anleitung, in der die Edge-Knoten mit Google Cloud Compute Engine-VMs emuliert werden. An einem echten Edge-Standort kann dies mit der richtigen Netzwerkkonfiguration erfolgen.
Lernziele
- Mit Compute Engine-VMs eine Bare-Metal-Infrastruktur emulieren, die an einem Edge-Standort ausgeführt wird.
- GKE on Bare Metal-Cluster in der emulierten Edge-Infrastruktur erstellen.
- Verbinden Sie den Cluster und registrieren Sie ihn bei Google Cloud.
- Stellen Sie eine Beispielarbeitslast für eine Kassenanwendung im GKE on Bare Metal-Cluster bereit.
- Verwenden Sie die Google Cloud Console, um die Point-of-Sale-Anwendung, die am Edge-Standort ausgeführt wird, zu prüfen und zu überwachen.
- Verwenden Sie Config Sync, um die Point-of-Sale-Anwendung zu aktualisieren, die im GKE on Bare Metal-Cluster ausgeführt wird.
Hinweise
Wählen Sie in der Google Cloud Console auf der Seite der Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Installieren und initialize Sie die Google Cloud CLI.
Anthos-Beispiel-Repository verzweigen und klonen
Alle in dieser Anleitung verwendeten Skripts werden im Repository anthos-samples gespeichert. Die Ordnerstruktur unter /anthos-bm-edge-deployment/acm-config-sink ist entsprechend den Anforderungen von Config Sync organisiert.
Klonen Sie dieses Repository in Ihr eigenes GitHub-Konto, bevor Sie mit den folgenden Schritten fortfahren.
Erstellen Sie ein Konto auf GitHub, falls Sie noch keines haben.
Erstellen Sie ein persönliches Zugriffstoken, das Sie in der Config Sync-Konfiguration verwenden können. Dies ist erforderlich, damit die Config Sync-Komponenten im Cluster sich bei Ihrem GitHub-Konto authentifizieren, wenn versucht wird, neue Änderungen zu synchronisieren.
- Wählen Sie nur den Bereich
public_repoaus. - Speichern Sie das erstellte Zugriffstoken an einem sicheren Ort, um es später zu verwenden.
- Wählen Sie nur den Bereich
Erstellen Sie einen Fork des Repositorys
anthos-samplesin Ihrem eigenen GitHub-Konto:- Rufen Sie das Repository "anthos-samples" auf.
- Klicken Sie in der oberen rechten Ecke der Seite auf das Symbol Fork.
- Klicken Sie auf das GitHub-Nutzerkonto, das den Fork des Repositorys enthalten soll. Sie werden automatisch zur Seite mit der Fork-Version des Repositorys
anthos-samplesweitergeleitet.
Öffnen Sie ein Terminal in der lokalen Umgebung.
Klonen Sie das verzweigte Repository mit dem folgenden Befehl, wobei GITHUB_USERNAME der Nutzername für Ihr GitHub-Konto ist:
git clone https://github.com/GITHUB_USERNAME/anthos-samples cd anthos-samples/anthos-bm-edge-deployment
Workstation-Umgebung einrichten
Um die in diesem Dokument beschriebene Edge-Bereitstellung abzuschließen, benötigen Sie eine Workstation mit Zugriff auf das Internet und die folgenden installierten Tools:
- Docker
- envsubst-Befehlszeilentool (normalerweise unter Linux und anderen Unix-ähnlichen Betriebssystemen vorinstalliert)
Führen Sie alle Befehle in der Anleitung auf der Workstation aus, die Sie in diesem Abschnitt konfigurieren.
Initialisieren Sie auf Ihrer Workstation die Umgebungsvariablen in einer neuen Shell-Instanz:
export PROJECT_ID="PROJECT_ID" export REGION="us-central1" export ZONE="us-central1-a" # port on the admin Compute Engine instance you use to set up an nginx proxy # this allows to reach the workloads inside the cluster via the VM IP export PROXY_PORT="8082" # should be a multiple of 3 since N/3 clusters are created with each having 3 nodes export GCE_COUNT="3" # url to the fork of: https://github.com/GoogleCloudPlatform/anthos-samples export ROOT_REPO_URL="https://github.com/GITHUB_USERNAME/anthos-samples" # this is the username used to authenticate to your fork of this repository export SCM_TOKEN_USER="GITHUB_USERNAME" # access token created in the earlier step export SCM_TOKEN_TOKEN="ACCESS_TOKEN"Ersetzen Sie die folgenden Werte:
- PROJECT_ID ist Ihre Google Cloud-Projekt-ID.
- GITHUB_USERNAME ist Ihr GitHub-Nutzername
- ACCESS_TOKEN: das persönliche Zugriffstoken, das Sie für Ihr GitHub-Repository erstellt haben.
Behalten Sie die Standardwerte für die anderen Umgebungsvariablen bei. Diese werden in den folgenden Abschnitten erläutert.
Initialisieren Sie auf Ihrer Workstation die Google Cloud CLI:
gcloud config set project "${PROJECT_ID}" gcloud services enable compute.googleapis.com gcloud config set compute/region "${REGION}" gcloud config set compute/zone "${ZONE}"Erstellen Sie auf Ihrer Workstation das Google Cloud-Dienstkonto für die Compute Engine-Instanzen. Dieses Skript erstellt die JSON-Schlüsseldatei für das neue Dienstkonto unter
<REPO_ROOT>/anthos-bm-edge-deployment/build-artifacts/consumer-edge-gsa.json. Außerdem werden der Schlüsselbund und der Schlüssel für den Cloud Key Management Service für die Verschlüsselung des privaten SSH-Schlüssels eingerichtet../scripts/create-primary-gsa.shDas folgende Beispiel ist nur ein Teil des Skripts. Um das gesamte Skript anzusehen, klicken Sie auf Auf GitHub ansehen.
Compute Engine-Instanzen bereitstellen
In diesem Abschnitt erstellen Sie die Compute Engine-VMs, in denen Google Distributed Cloud installiert wird. Außerdem prüfen Sie die Verbindung zu diesen VMs, bevor Sie mit dem Installationsabschnitt fortfahren.
Erstellen Sie auf Ihrer Workstation SSH-Schlüssel, die für die Kommunikation zwischen den Compute Engine-Instanzen verwendet werden.
ssh-keygen -f ./build-artifacts/consumer-edge-machineVerschlüsseln Sie den privaten SSH-Schlüssel mit dem Cloud Key Management Service.
gcloud kms encrypt \ --key gdc-ssh-key \ --keyring gdc-ce-keyring \ --location global \ --plaintext-file build-artifacts/consumer-edge-machine \ --ciphertext-file build-artifacts/consumer-edge-machine.encryptedGenerieren Sie die Umgebungskonfigurationsdatei
.envrcund beschaffen Sie sie als Quelle. Prüfen Sie nach dem Erstellen die Datei.envrc, um sicherzustellen, dass die Umgebungsvariablen durch die richtigen Werte ersetzt wurden.envsubst < templates/envrc-template.sh > .envrc source .envrcDas folgende Beispiel zeigt eine
.envrc-Datei, die durch Ersetzen der Umgebungsvariablen in der Dateitemplates/envrc-template.shgeneriert wird. Die aktualisierten Zeilen sind hervorgehoben:Erstellen Sie Compute Engine-Instanzen, in denen Google Distributed Cloud installiert ist.
./scripts/cloud/create-cloud-gce-baseline.sh -c "$GCE_COUNT" | \ tee ./build-artifacts/gce-info
Google Distributed Cloud mit Ansible installieren
Das in diesem Leitfaden verwendete Skript erstellt GKE on Bare Metal-Cluster in Gruppen von drei Compute Engine-Instanzen. Die Anzahl der erstellten Cluster wird von der Umgebungsvariable GCE_COUNT gesteuert. Sie legen beispielsweise die Umgebungsvariable GCE_COUNT auf 6 fest, um zwei GKE on Bare Metal-Cluster mit jeweils 3 VM-Instanzen zu erstellen. Die Umgebungsvariable GCE_COUNT ist standardmäßig auf 3 festgelegt. Daher wird in dieser Anleitung ein Cluster mit 3 Compute Engine-Instanzen erstellt. Die VM-Instanzen sind mit dem Präfix cnuc- gefolgt von einer Zahl benannt. Die erste VM-Instanz jedes Clusters fungiert als Administratorworkstation, von der aus die Installation ausgelöst wird. Der Cluster erhält auch denselben Namen wie die VM der Administratorworkstation (z. B. cnuc-1, cnuc-4, cnuc-7).
Das Ansible-Playbook tut Folgendes:
- Konfiguriert die Compute Engine-Instanzen mit den erforderlichen Tools, z. B.
docker,bmctl,gcloudundnomos. - Installiert Google Distributed Cloud in den konfigurierten Compute Engine-Instanzen.
- Erstellt einen eigenständigen GKE on Bare Metal-Cluster namens
cnuc-1. - Registriert den Cluster
cnuc-1bei Google Cloud. - Config Sync wird im Cluster
cnuc-1installiert. - Konfiguriert Config Sync für die Synchronisierung mit den Clusterkonfigurationen unter
anthos-bm-edge-deployment/acm-config-sinkin Ihrem verzweigten Repository. - Erzeugt den
Login tokenfür den Cluster.
Führe die folgenden Schritte aus, um die Installation einzurichten und zu starten:
Erstellen Sie auf Ihrer Workstation das für die Installation verwendete Docker-Image. Dieses Image enthält alle für den Installationsprozess erforderlichen Tools, z. B. Ansible, Python und die Google Cloud CLI.
gcloud builds submit --config docker-build/cloudbuild.yaml docker-build/Wenn der Build erfolgreich ausgeführt wird, gibt er eine Ausgabe wie die folgende zurück:
... latest: digest: sha256:99ded20d221a0b2bcd8edf3372c8b1f85d6c1737988b240dd28ea1291f8b151a size: 4498 DONE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ID CREATE_TIME DURATION SOURCE IMAGES STATUS 2238baa2-1f41-440e-a157-c65900b7666b 2022-08-17T19:28:57+00:00 6M53S gs://my_project_cloudbuild/source/1660764535.808019-69238d8c870044f0b4b2bde77a16111d.tgz gcr.io/my_project/consumer-edge-install (+1 more) SUCCESSGenerieren Sie die Ansible-Inventardatei aus einer Vorlage.
envsubst < templates/inventory-cloud-example.yaml > inventory/gcp.yamlFühren Sie das Installationsskript aus, mit dem ein Docker-Container aus dem zuvor erstellten Image gestartet wird. Das Skript verwendet intern Docker, um den Container mit einer Volume-Bereitstellung im aktuellen Arbeitsverzeichnis zu erstellen. Nach erfolgreicher Ausführung dieses Skripts müssen Sie sich im erstellten Docker-Container befinden. Sie lösen die Ansible-Installation aus diesem Container heraus aus.
./install.shWenn das Skript erfolgreich ausgeführt wird, gibt es eine Ausgabe wie die folgende aus:
... Check the values above and if correct, do you want to proceed? (y/N): y Starting the installation Pulling docker install image... ============================== Starting the docker container. You will need to run the following 2 commands (cut-copy-paste) ============================== 1: ./scripts/health-check.sh 2: ansible-playbook all-full-install.yaml -i inventory 3: Type 'exit' to exit the Docker shell after installation ============================== Thank you for using the quick helper script! (you are now inside the Docker shell)Überprüfen Sie im Docker-Container den Zugriff auf die Compute Engine-Instanzen.
./scripts/health-check.shWenn das Skript erfolgreich ausgeführt wird, gibt es eine Ausgabe wie die folgende aus:
... cnuc-2 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"} cnuc-3 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"} cnuc-1 | SUCCESS => {"ansible_facts": {"discovered_interpreter_python": "/usr/bin/python3"},"changed": false,"ping": "pong"}Führen Sie im Docker-Container das Ansible-Playbook zum Installieren von Google Distributed Cloud auf Compute Engine-Instanzen aus. Anschließend wird
Login Tokenfür den Cluster auf dem Bildschirm angezeigt.ansible-playbook all-full-install.yaml -i inventory | tee ./build-artifacts/ansible-run.logWenn die Installation erfolgreich ausgeführt wird, wird eine Ausgabe wie die folgende ausgegeben:
... TASK [abm-login-token : Display login token] ************************************************************************** ok: [cnuc-1] => { "msg": "eyJhbGciOiJSUzI1NiIsImtpZCI6Imk2X3duZ3BzckQyWmszb09sZHFMN0FoWU9mV1kzOWNGZzMyb0x2WlMyalkifQ.eymljZS1hY2NvdW iZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZWNyZXQubmFtZSI6ImVkZ2Etc2EtdG9rZW4tc2R4MmQiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2Nvd 4CwanGlof6s-fbu8" } skipping: [cnuc-2] skipping: [cnuc-3] PLAY RECAP *********************************************************************************************************** cnuc-1 : ok=205 changed=156 unreachable=0 failed=0 skipped=48 rescued=0 ignored=12 cnuc-2 : ok=128 changed=99 unreachable=0 failed=0 skipped=108 rescued=0 ignored=2 cnuc-3 : ok=128 changed=99 unreachable=0 failed=0 skipped=108 rescued=0 ignored=2
In der Google Cloud Console beim GKE on Bare Metal-Cluster anmelden
Nachdem das Ansible-Playbook vollständig ausgeführt wurde, wird ein eigenständiger GKE on Bare Metal-Cluster in den Compute Engine-VMs installiert. Dieser Cluster ist mit dem Connect Agent auch in Google Cloud registriert. Wenn Sie jedoch Details zu diesem Cluster sehen möchten, müssen Sie sich über die Google Cloud Console beim Cluster anmelden. Führen Sie die folgenden Schritte aus, um sich beim GKE-Cluster anzumelden.
Kopieren Sie das Token aus der Ausgabe des Ansible-Playbooks im vorherigen Abschnitt.
Rufen Sie in der Google Cloud Console die Seite Kubernetes-Cluster auf und melden Sie sich mit dem kopierten Token beim
cnuc-1-Cluster an.Zur Seite "Kubernetes-Cluster"
- Klicken Sie in der Liste der Cluster neben dem Cluster
cnuc-1auf Aktionen und dann auf Anmelden. - Wählen Sie Token aus und fügen Sie das kopierte Token ein.
- Klicken Sie auf Anmelden.
- Klicken Sie in der Liste der Cluster neben dem Cluster
- Rufen Sie in der Google Cloud Console im Abschnitt Features die Seite Konfiguration auf.
Prüfen Sie auf dem Tab Pakete in der Clustertabelle die Spalte Synchronisierungsstatus.
Prüfen Sie, ob der Status Synchronisiert lautet. Der Status Synchronisiert gibt an, dass Config Sync Ihre GitHub-Konfigurationen erfolgreich mit dem bereitgestellten Cluster cnuc-1 synchronisiert hat.
Proxy für externen Traffic konfigurieren
Der in den vorherigen Schritten installierte GKE on Bare Metal-Cluster verwendet einen gebündelten Load-Balancer namens MetalLB.
Auf diesen Load-Balancer-Dienst kann nur über eine VPC-IP-Adresse (Virtual Private Cloud) zugegriffen werden. Wenn Sie Traffic, der über die externe IP-Adresse eingeht, an den gebündelten Load-Balancer weiterleiten möchten, richten Sie im Administratorhost (cnuc-1) einen Reverse-Proxy-Dienst ein. Mit diesem Reverse-Proxy-Dienst können Sie den API-Server der Point-of-Sale-Anwendung über die externe IP-Adresse des Administratorhosts (cnuc-1) erreichen.
Mit den Installationsskripts in den vorherigen Schritten wurde NGINX zusammen mit einer Beispielkonfigurationsdatei auf den Administratorhosts installiert. Aktualisieren Sie diese Datei, um die IP-Adresse des Load-Balancer-Dienstes zu verwenden, und starten Sie NGINX neu.
Melden Sie sich auf Ihrer Workstation mit SSH bei der Administrator-Workstation an:
ssh -F ./build-artifacts/ssh-config abm-admin@cnuc-1Richten Sie in der Administratorworkstation den NGINX-Reverse-Proxy ein, um Traffic an den Load-Balancer-Dienst des API-Servers weiterzuleiten. Rufen Sie die IP-Adresse des Kubernetes-Dienstes des Load-Balancers ab:
ABM_INTERNAL_IP=$(kubectl get services api-server-lb -n pos | awk '{print $4}' | tail -n 1)Aktualisieren Sie die Vorlagenkonfigurationsdatei mit der abgerufenen IP-Adresse:
sudo sh -c "sed 's/<K8_LB_IP>/${ABM_INTERNAL_IP}/g' \ /etc/nginx/nginx.conf.template > /etc/nginx/nginx.conf"Starten Sie NGINX neu, um sicherzustellen, dass die neue Konfiguration angewendet wird:
sudo systemctl restart nginxÜberprüfe und verifiziere den Status des NGINX-Servers, um den Status "active (running)" zu melden:
sudo systemctl status nginxWenn NGINX erfolgreich ausgeführt wird, wird eine Ausgabe wie im folgenden Beispiel erzeugt:
● nginx.service - A high performance web server and a reverse proxy server Loaded: loaded (/lib/systemd/system/nginx.service; enabled; vendor preset: enabled) Active: active (running) since Fri 2021-09-17 02:41:01 UTC; 2s ago Docs: man:nginx(8) Process: 92571 ExecStartPre=/usr/sbin/nginx -t -q -g daemon on; master_process on; (code=exited, status=0/SUCCESS) Process: 92572 ExecStart=/usr/sbin/nginx -g daemon on; master_process on; (code=exited, status=0/SUCCESS) Main PID: 92573 (nginx) Tasks: 17 (limit: 72331) Memory: 13.2M CGroup: /system.slice/nginx.service ├─92573 nginx: master process /usr/sbin/nginx -g daemon on; master_process on; ├─92574 nginx: worker process ├─92575 nginx: worker process ├─92577 nginx: .... ... ...Beenden Sie die SSH-Sitzung und rufen Sie die Administrator-Workstation auf:
exitBeenden Sie die Shell-Sitzung zum Docker-Container. Nach dem Beenden der Admin-Instanz befinden Sie sich noch in dem Docker-Container, der für die Installation verwendet wurde:
exit
Auf die Kassenanwendung zugreifen
Mit der Einrichtung eines externen Proxys können Sie auf die Anwendung zugreifen, die im GKE-Cluster ausgeführt wird. Führen Sie die folgenden Schritte aus, um auf die Beispiel-Kassenanwendung zuzugreifen:
Rufen Sie auf Ihrer Workstation die externe IP-Adresse der Compute Engine-Administratorinstanz ab und greifen Sie auf die UI der Point-of-Sale-Anwendung zu:
EXTERNAL_IP=$(gcloud compute instances list \ --project ${PROJECT_ID} \ --filter="name:cnuc-1" \ --format="get(networkInterfaces[0].accessConfigs[0].natIP)") echo "Point the browser to: ${EXTERNAL_IP}:${PROXY_PORT}"Wenn die Skripts erfolgreich ausgeführt werden, produzieren sie in etwa folgende Ausgabe:
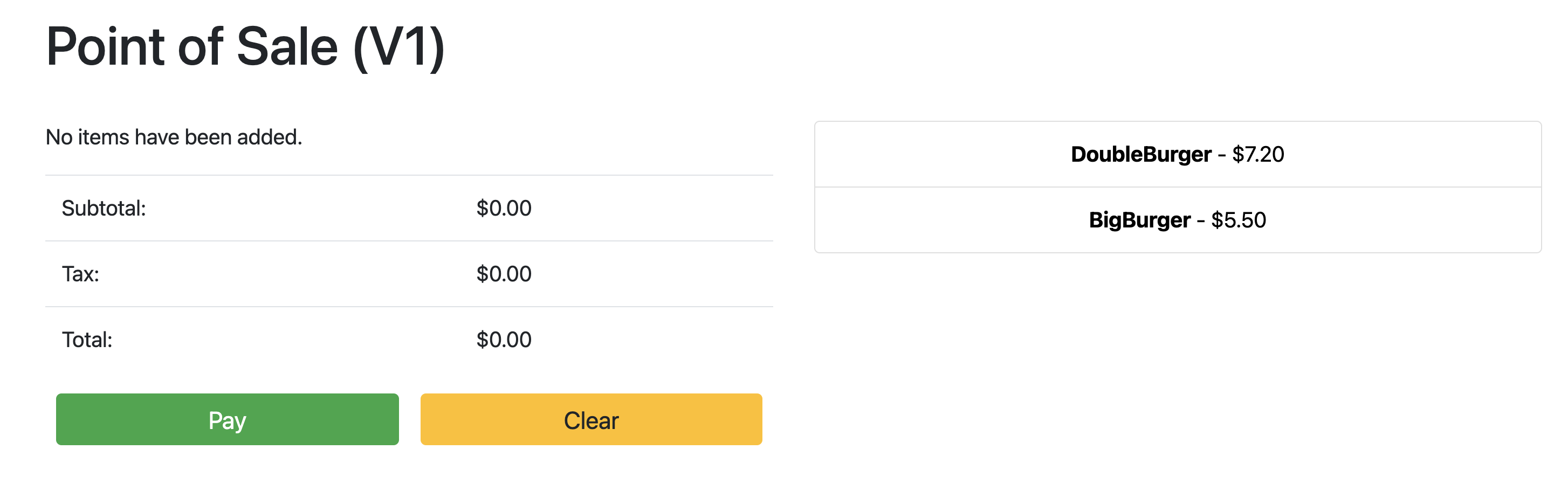
Point the browser to: 34.134.194.84:8082Öffnen Sie Ihren Webbrowser und rufen Sie die IP-Adresse auf, die in der Ausgabe des vorherigen Befehls angezeigt wurde. Sie können auf die Beispiel-Kassenanwendung zugreifen und sie testen, wie im folgenden Beispielscreenshot gezeigt:
API-Server mit Config Sync aktualisieren
Die Beispielanwendung kann auf eine neuere Version aktualisiert werden, indem die Konfigurationsdateien im Root-Repository aktualisiert werden. Config Sync erkennt die Aktualisierungen und nimmt die Änderungen automatisch am Cluster vor. In diesem Beispiel ist das Root-Repository das Repository anthos-samples, das Sie zu Beginn dieses Leitfadens geklont haben. Führen Sie die folgenden Schritte aus, um zu sehen, wie die Beispiel-Point-of-Sale-Anwendung eine Upgrade-Bereitstellung auf eine neuere Version durchlaufen kann.
Aktualisieren Sie auf Ihrer Workstation das Feld
image, um die Version des API-Servers vonv1inv2zu ändern. Die YAML-Konfiguration für die Bereitstellung befindet sich in der Dateianthos-bm-edge-deployment/acm-config-sink/namespaces/pos/api-server.yaml.Fügen Sie die Änderungen dem verzweigten Repository hinzu, führen Sie einen Commit durch und übertragen Sie die Änderungen per Push:
git add acm-config-sink/namespaces/pos/api-server.yaml git commit -m "chore: updated api-server version to v2" git pushRufen Sie in der Google Cloud Console die Seite Config Sync auf, um den Status der Konfigurationsspezifikation zu prüfen. Prüfen Sie, ob der Status Synchronisiert lautet.
Rufen Sie in der Google Cloud Console die Seite Kubernetes Engine-Arbeitslasten auf, um nachzusehen, ob das Deployment aktualisiert wurde.
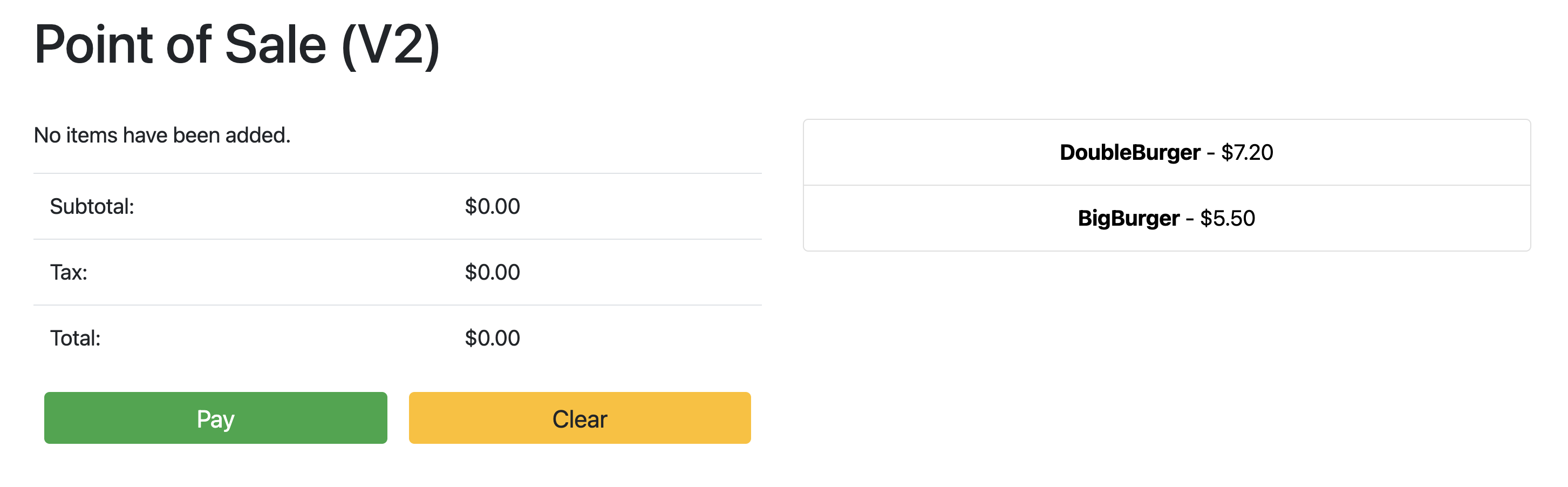
Wenn der Status der Bereitstellung OK lautet, zeigen Sie mit dem Browser die IP-Adresse aus dem vorherigen Abschnitt an, um die Kassenanwendung aufzurufen. Beachten Sie, dass als Version im Titel "V2" angezeigt wird. Dies bedeutet, dass Ihre Anwendungsänderung bereitgestellt wurde, wie im folgenden Beispiel-Screenshot dargestellt:
Möglicherweise müssen Sie den Browsertab aktualisieren, damit die Änderungen angezeigt werden.
Bereinigen
Löschen Sie die für diese Anleitung verwendeten Ressourcen, um unnötige Google Cloud-Gebühren zu vermeiden. Sie können diese Ressourcen entweder manuell löschen oder Ihr Google Cloud-Projekt löschen, wodurch auch alle Ressourcen entfernt werden. Darüber hinaus können Sie auch die Änderungen bereinigen, die Sie auf Ihrer lokalen Workstation vorgenommen haben:
Lokale Workstation
Die folgenden Dateien müssen aktualisiert werden, um Änderungen zu löschen, die von den Installationsskripts vorgenommen wurden.
- Entfernen Sie die Compute Engine-VM-IP-Adressen, die der Datei
/etc/hostshinzugefügt wurden. - Entfernen Sie die SSH-Konfiguration für
cnuc-*in der Datei~/.ssh/config. - Entfernen Sie die Fingerabdrücke der Compute Engine-VM aus der Datei
~/.ssh/known_hosts.
Projekt löschen
Wenn Sie für dieses Verfahren ein dediziertes Projekt erstellt haben, löschen Sie das Google Cloud-Projekt aus der Google Cloud Console.
Manuell
Wenn Sie für dieses Verfahren ein vorhandenes Projekt verwendet haben, gehen Sie so vor:
- Heben Sie die Registrierung aller Kubernetes-Cluster mit einem Namen auf, dem
cnuc-vorangestellt ist. - Löschen Sie alle Compute Engine-VMs mit einem Namen, dem das Präfix
cnuc-vorangestellt ist. - Löschen Sie den Cloud Storage-Bucket mit einem Namen, dem
abm-edge-bootvorangestellt ist. - Löschen Sie die Firewallregeln
allow-pod-ingressundallow-pod-egress. - Löschen Sie das Secret Manager-Secret
install-pub-key.
Nächste Schritte
Sie können diese Anleitung erweitern, indem Sie einen weiteren Edge-Standort hinzufügen. Wenn Sie die Umgebungsvariable GCE_COUNT auf 6 festlegen und dieselben Schritte wie in den vorherigen Abschnitten noch einmal ausführen, werden drei neue Compute Engine-Instanzen (cnuc-4, cnuc-5, cnuc-6) und ein neuer eigenständiger GKE on Bare Metal-Cluster namens cnuc-4 erstellt.
Sie können auch die Clusterkonfigurationen in Ihrem verzweigten Repository aktualisieren, um selektiv verschiedene Versionen der Point-of-Sale-Anwendung auf die beiden Cluster cnuc-1 und cnuc-4 mit ClusterSelectors anzuwenden.
Weitere Informationen zu den einzelnen Schritten in dieser Anleitung und den betroffenen Skripts finden Sie im Repository anthos-samples.