Die BiDiStreamingAnalyzeContent API ist die primäre API für Audio- und multimodale Interaktionen der nächsten Generation in Conversational Agents und Agent Assist. Diese API erleichtert das Streamen von Audiodaten und gibt entweder Transkriptionen oder Vorschläge für Kundenservicemitarbeiter zurück.
Im Gegensatz zu früheren APIs bietet die vereinfachte Audiokonfiguration eine optimierte Unterstützung für Unterhaltungen zwischen Menschen und eine verlängerte Zeitüberschreitung von 15 Minuten. Mit Ausnahme der Live-Übersetzung unterstützt diese API auch alle Agent Assist-Funktionen, die von StreamingAnalyzeContent unterstützt werden.
Grundlagen zum Streaming
Das folgende Diagramm veranschaulicht die Funktionsweise des Streams.
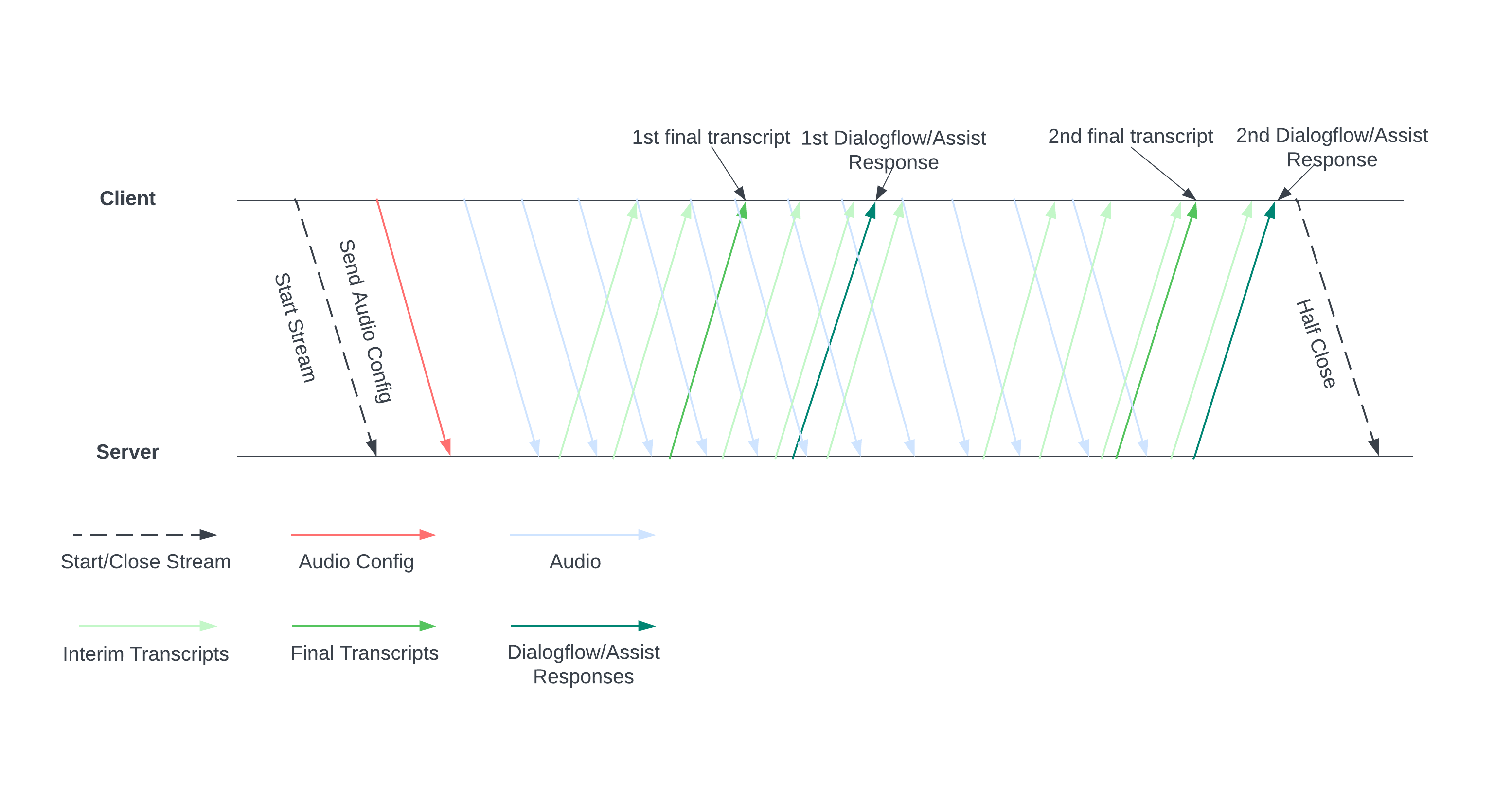
Starte einen Stream, indem du eine Audiokonfiguration an den Server sendest. Anschließend senden Sie Audiodateien und der Server sendet Ihnen ein Transkript oder Vorschläge für einen Kundenservicemitarbeiter. Senden Sie mehr Audiodaten, um mehr Transkripte und Vorschläge zu erhalten. Dieser Austausch wird fortgesetzt, bis Sie ihn beenden, indem Sie den Stream halb schließen.
Streaming-Anleitung
Wenn Sie die BiDiStreamingAnalyzeContent API während der Laufzeit einer Unterhaltung verwenden möchten, folgen Sie diesen Richtlinien.
- Rufen Sie die Methode
BiDiStreamingAnalyzeContentauf und legen Sie die folgenden Felder fest:BiDiStreamingAnalyzeContentRequest.participant- Optional:
BiDiStreamingAnalyzeContentRequest.voice_session_config.input_audio_sample_rate_hertz(Wenn angegeben, wird die Konfiguration ausConversationProfile.stt_config.sample_rate_hertzüberschrieben.) - Optional:
BiDiStreamingAnalyzeContentRequest.voice_session_config.input_audio_encoding(Wenn angegeben, wird die Konfiguration ausConversationProfile.stt_config.audio_encodingüberschrieben.)
- Bereiten Sie den Stream vor und legen Sie die Audiokonfiguration mit Ihrer ersten
BiDiStreamingAnalyzeContent-Anfrage fest. - Senden Sie in nachfolgenden Anfragen Audiobytes über
BiDiStreamingAnalyzeContentRequest.audioan den Stream. - Nachdem Sie die zweite Anfrage mit einer Audio-Nutzlast gesendet haben, sollten Sie einige
BidiStreamingAnalyzeContentResponsesaus dem Stream erhalten.- Zwischen- und Endergebnisse der Transkription sind mit dem folgenden Befehl verfügbar:
BiDiStreamingAnalyzeContentResponse.recognition_result. - Mit dem folgenden Befehl können Sie auf Vorschläge von Kundenservicemitarbeitern und verarbeitete Unterhaltungsmeldungen zugreifen:
BiDiStreamingAnalyzeContentResponse.analyze_content_response.
- Zwischen- und Endergebnisse der Transkription sind mit dem folgenden Befehl verfügbar:
- Du kannst den Stream jederzeit halb schließen. Nachdem Sie den Stream halb geschlossen haben, sendet der Server die Antwort mit den verbleibenden Erkennungsergebnissen sowie möglichen Agent Assist-Vorschlägen zurück.
- Starte oder starte einen neuen Stream in den folgenden Fällen neu:
- Der Stream ist unterbrochen. Der Stream wurde beispielsweise beendet, obwohl er nicht hätte beendet werden sollen.
- Ihr Gespräch nähert sich dem maximalen Zeitlimit von 15 Minuten.
- Für eine optimale Qualität sollten Sie beim Starten eines Streams Audiodaten, die nach dem letzten
speech_end_offsetdesBiDiStreamingAnalyzeContentResponse.recognition_resultgeneriert wurden, mitis_final=trueanBidiStreamingAnalyzeContentsenden.
API über die Python-Clientbibliothek verwenden
Clientbibliotheken erleichtern den Zugriff auf Google-APIs über eine bestimmte Programmiersprache. Sie können die Python-Clientbibliothek für Agent Assist mit BidiStreamingAnalyzeContent so verwenden:
from google.cloud import dialogflow_v2beta1
from google.api_core.client_options import ClientOptions
from google.cloud import storage
import time
import google.auth
import participant_management
import conversation_management
PROJECT_ID="your-project-id"
CONVERSATION_PROFILE_ID="your-conversation-profile-id"
BUCKET_NAME="your-audio-bucket-name"
SAMPLE_RATE =48000
# Calculate the bytes with Sample_rate_hertz * bit Depth / 8 -> bytes
# 48000(sample/second) * 16(bits/sample) / 8 = 96000 byte per second,
# 96000 / 10 = 9600 we send 0.1 second to the stream API
POINT_ONE_SECOND_IN_BYTES = 9600
FOLDER_PTAH_FOR_CUSTOMER_AUDIO="your-customer-audios-files-path"
FOLDER_PTAH_FOR_AGENT_AUDIO="your-agent-audios-file-path"
client_options = ClientOptions(api_endpoint="dialogflow.googleapis.com")
credentials, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform",
"https://www.googleapis.com/auth/dialogflow"])
storage_client = storage.Client(credentials = credentials, project=PROJECT_ID)
participant_client = dialogflow_v2beta1.ParticipantsClient(client_options=client_options,
credentials=credentials)
def download_blob(bucket_name, folder_path, audio_array : list):
"""Uploads a file to the bucket."""
bucket = storage_client.bucket(bucket_name, user_project=PROJECT_ID)
blobs = bucket.list_blobs(prefix=folder_path)
for blob in blobs:
if not blob.name.endswith('/'):
audio_array.append(blob.download_as_string())
def request_iterator(participant : dialogflow_v2beta1.Participant, audios):
"""Iterate the request for bidi streaming analyze content
"""
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
config={
"participant": participant.name,
"voice_session_config": {
"input_audio_encoding": dialogflow_v2beta1.AudioEncoding.AUDIO_ENCODING_LINEAR_16,
"input_audio_sample_rate_hertz": SAMPLE_RATE,
},
}
)
print(f"participant {participant}")
for i in range(0, len(audios)):
audios_array = audio_request_iterator(audios[i])
for chunk in audios_array:
if not chunk:
break
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
input={
"audio":chunk
},
)
time.sleep(0.1)
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
config={
"participant": participant.name,
}
)
time.sleep(0.1)
def participant_bidi_streaming_analyze_content(participant, audios):
"""call bidi streaming analyze content API
"""
bidi_responses = participant_client.bidi_streaming_analyze_content(
requests=request_iterator(participant, audios)
)
for response in bidi_responses:
bidi_streaming_analyze_content_response_handler(response)
def bidi_streaming_analyze_content_response_handler(response: dialogflow_v2beta1.BidiStreamingAnalyzeContentResponse):
"""Call Bidi Streaming Analyze Content
"""
if response.recognition_result:
print(f"Recognition result: { response.recognition_result.transcript}", )
def audio_request_iterator(audio):
"""Iterate the request for bidi streaming analyze content
"""
total_audio_length = len(audio)
print(f"total audio length {total_audio_length}")
array = []
for i in range(0, total_audio_length, POINT_ONE_SECOND_IN_BYTES):
chunk = audio[i : i + POINT_ONE_SECOND_IN_BYTES]
array.append(chunk)
if not chunk:
break
return array
def python_client_handler():
"""Downloads audios from the google cloud storage bucket and stream to
the Bidi streaming AnalyzeContent site.
"""
print("Start streaming")
conversation = conversation_management.create_conversation(
project_id=PROJECT_ID, conversation_profile_id=CONVERSATION_PROFILE_ID_STAGING
)
conversation_id = conversation.name.split("conversations/")[1].rstrip()
human_agent = human_agent = participant_management.create_participant(
project_id=PROJECT_ID, conversation_id=conversation_id, role="HUMAN_AGENT"
)
end_user = end_user = participant_management.create_participant(
project_id=PROJECT_ID, conversation_id=conversation_id, role="END_USER"
)
end_user_requests = []
agent_request= []
download_blob(BUCKET_NAME, FOLDER_PTAH_FOR_CUSTOMER_AUDIO, end_user_requests)
download_blob(BUCKET_NAME, FOLDER_PTAH_FOR_AGENT_AUDIO, agent_request)
participant_bidi_streaming_analyze_content( human_agent, agent_request)
participant_bidi_streaming_analyze_content( end_user, end_user_requests)
conversation_management.complete_conversation(PROJECT_ID, conversation_id)
SipRec-Integration für Telefonie aktivieren
Sie können die Telefonie-SipRec-Integration aktivieren, um BidiStreamingAnalyzeContent für die Audioverarbeitung zu verwenden. Sie können die Audioverarbeitung entweder mit der Agent Assist Console oder mit einer direkten API-Anfrage konfigurieren.
Konsole
So konfigurieren Sie die Audioverarbeitung für die Verwendung von BidiStreamingAnalyzeContent:
Rufen Sie die Agent Assist Console auf und wählen Sie Ihr Projekt aus.
Klicken Sie auf Konversationsprofile > den Namen eines Profils.
Rufen Sie die Telefonieeinstellungen auf.
Klicken Sie, um Bidirectional Streaming API verwenden zu aktivieren> Speichern.
API
Sie können die API direkt aufrufen, um ein Unterhaltungsprofil zu erstellen oder zu aktualisieren. Konfigurieren Sie dazu das Flag unter ConversationProfile.use_bidi_streaming.
Konfigurationsbeispiel:
{
"name": "projects/PROJECT_ID/locations/global/conversationProfiles/CONVERSATION_PROFILE_ID",f
"displayName": "CONVERSATION_PROFILE_NAME",
"automatedAgentConfig": {
},
"humanAgentAssistantConfig": {
"notificationConfig": {
"topic": "projects/PROJECT_ID/topics/FEATURE_SUGGESTION_TOPIC_ID",
"messageFormat": "JSON"
},
},
"useBidiStreaming": true,
"languageCode": "en-US"
}
Kontingente
Die Anzahl der gleichzeitigen BidiStreamingAnalyzeContent-Anfragen ist durch ein neues Kontingent ConcurrentBidiStreamingSessionsPerProjectPerRegion begrenzt. Informationen zur Kontingentnutzung und zum Anfordern einer Erhöhung des Kontingentlimits finden Sie im Google Cloud Leitfaden zu Kontingenten.
Bei Kontingenten wird die Verwendung von BidiStreamingAnalyzeContent-Anfragen an den globalen Dialogflow-Endpunkt in der Region us-central1 berücksichtigt.