The BiDiStreamingAnalyzeContent API is the primary API for next-generation audio and multi-modal experiences in both Conversational Agents and Agent Assist. This API facilitates the streaming of audio data and returns either transcriptions or human agent suggestions to you.
Unlike previous APIs, the simplified audio configuration has optimized support for human-to-human conversations and an extended deadline limit of 15 minutes. Except for live translation, this API also supports all the Agent Assist features that StreamingAnalyzeContent supports.
Streaming basics
The following diagram illustrates how the stream works.
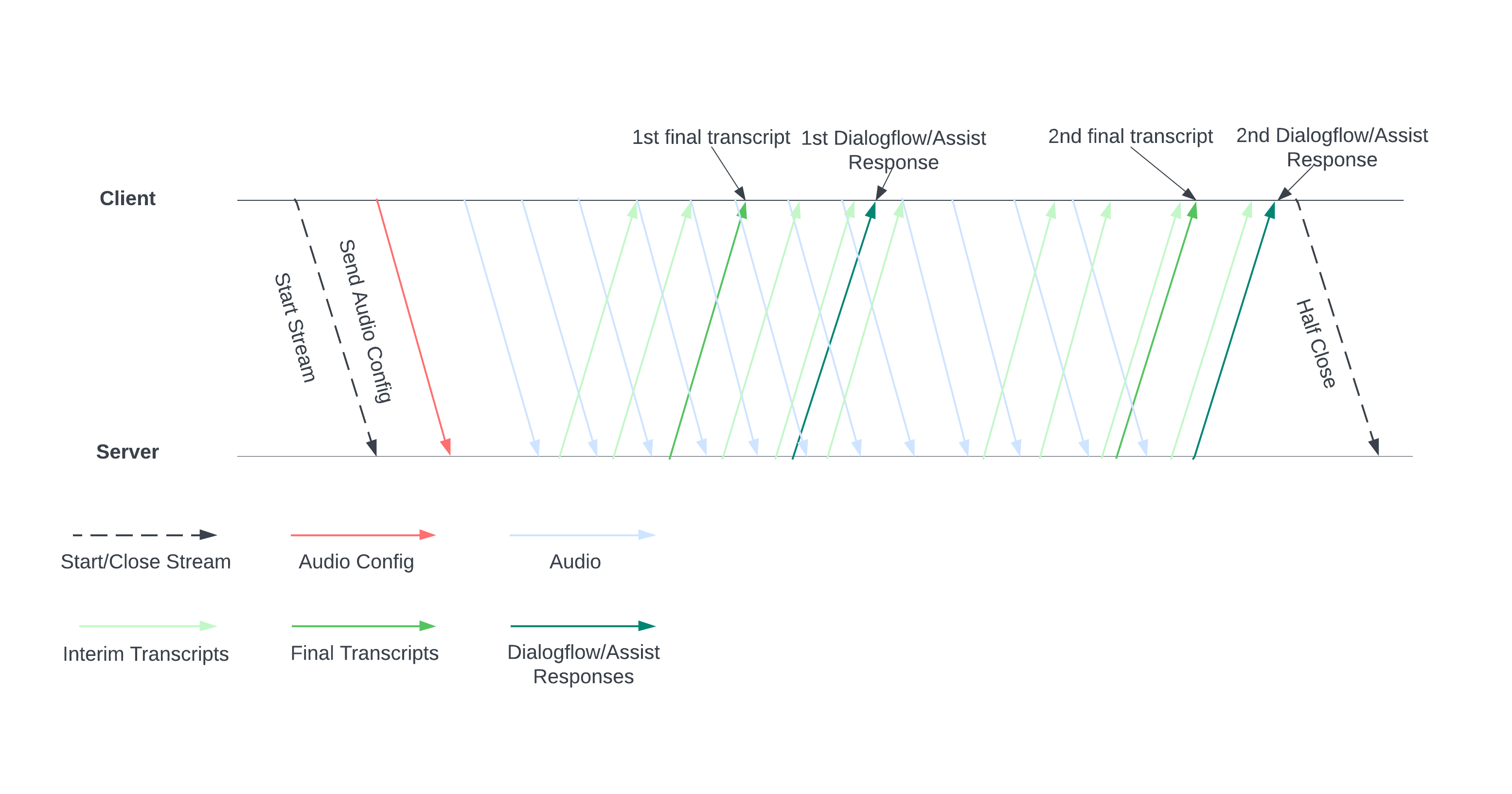
Start a stream by sending an audio configuration to the server. Then you send audio files, and the server sends you a transcript or suggestions for a human agent. Send more audio data for more transcripts and suggestions. This exchange continues until you end it by half closing the stream.
Streaming guide
To use the BiDiStreamingAnalyzeContent API at conversation runtime, follow these guidelines.
- Call
BiDiStreamingAnalyzeContentmethod and set the following fields:BiDiStreamingAnalyzeContentRequest.participant- (Optional)
BiDiStreamingAnalyzeContentRequest.voice_session_config.input_audio_sample_rate_hertz(When specified, this overrides the configuration fromConversationProfile.stt_config.sample_rate_hertz.) - (Optional)
BiDiStreamingAnalyzeContentRequest.voice_session_config.input_audio_encoding(When specified, this overrides the configuration fromConversationProfile.stt_config.audio_encoding.)
- Prepare the stream and set your audio configuration with your first
BiDiStreamingAnalyzeContentrequest. - In subsequent requests, send audio bytes to the stream through
BiDiStreamingAnalyzeContentRequest.audio. - After you send the second request with an audio payload, you should receive some
BidiStreamingAnalyzeContentResponsesfrom the stream.- Intermediate and final transcription results are available with the following command:
BiDiStreamingAnalyzeContentResponse.recognition_result. - You can access human agent suggestions and processed conversation messages with the following command:
BiDiStreamingAnalyzeContentResponse.analyze_content_response.
- Intermediate and final transcription results are available with the following command:
- You can half close the stream at any time. After you half close the stream, the server sends back the response containing remaining recognition results, along with potential Agent Assist suggestions.
- Start or restart a new stream in the following cases:
- The stream is broken. For example, the stream stopped when it wasn't supposed to.
- Your conversation is approaching the request maximum of 15 minutes.
- For best quality, when you start a stream, send audio data generated after the last
speech_end_offsetof theBiDiStreamingAnalyzeContentResponse.recognition_resultwithis_final=truetoBidiStreamingAnalyzeContent.
Use the API through Python client library
Client libraries help you access Google APIs from a particular code language. You can use the Python client library for Agent Assist with BidiStreamingAnalyzeContent as follows.
from google.cloud import dialogflow_v2beta1
from google.api_core.client_options import ClientOptions
from google.cloud import storage
import time
import google.auth
import participant_management
import conversation_management
PROJECT_ID="your-project-id"
CONVERSATION_PROFILE_ID="your-conversation-profile-id"
BUCKET_NAME="your-audio-bucket-name"
SAMPLE_RATE =48000
# Calculate the bytes with Sample_rate_hertz * bit Depth / 8 -> bytes
# 48000(sample/second) * 16(bits/sample) / 8 = 96000 byte per second,
# 96000 / 10 = 9600 we send 0.1 second to the stream API
POINT_ONE_SECOND_IN_BYTES = 9600
FOLDER_PTAH_FOR_CUSTOMER_AUDIO="your-customer-audios-files-path"
FOLDER_PTAH_FOR_AGENT_AUDIO="your-agent-audios-file-path"
client_options = ClientOptions(api_endpoint="dialogflow.googleapis.com")
credentials, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform",
"https://www.googleapis.com/auth/dialogflow"])
storage_client = storage.Client(credentials = credentials, project=PROJECT_ID)
participant_client = dialogflow_v2beta1.ParticipantsClient(client_options=client_options,
credentials=credentials)
def download_blob(bucket_name, folder_path, audio_array : list):
"""Uploads a file to the bucket."""
bucket = storage_client.bucket(bucket_name, user_project=PROJECT_ID)
blobs = bucket.list_blobs(prefix=folder_path)
for blob in blobs:
if not blob.name.endswith('/'):
audio_array.append(blob.download_as_string())
def request_iterator(participant : dialogflow_v2beta1.Participant, audios):
"""Iterate the request for bidi streaming analyze content
"""
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
config={
"participant": participant.name,
"voice_session_config": {
"input_audio_encoding": dialogflow_v2beta1.AudioEncoding.AUDIO_ENCODING_LINEAR_16,
"input_audio_sample_rate_hertz": SAMPLE_RATE,
},
}
)
print(f"participant {participant}")
for i in range(0, len(audios)):
audios_array = audio_request_iterator(audios[i])
for chunk in audios_array:
if not chunk:
break
yield dialogflow_v2beta1.BidiStreamingAnalyzeContentRequest(
input={
"audio":chunk
},
)
time.sleep(0.1)
time.sleep(0.1)
def participant_bidi_streaming_analyze_content(participant, audios):
"""call bidi streaming analyze content API
"""
bidi_responses = participant_client.bidi_streaming_analyze_content(
requests=request_iterator(participant, audios)
)
for response in bidi_responses:
bidi_streaming_analyze_content_response_handler(response)
def bidi_streaming_analyze_content_response_handler(response: dialogflow_v2beta1.BidiStreamingAnalyzeContentResponse):
"""Call Bidi Streaming Analyze Content
"""
if response.recognition_result:
print(f"Recognition result: { response.recognition_result.transcript}", )
def audio_request_iterator(audio):
"""Iterate the request for bidi streaming analyze content
"""
total_audio_length = len(audio)
print(f"total audio length {total_audio_length}")
array = []
for i in range(0, total_audio_length, POINT_ONE_SECOND_IN_BYTES):
chunk = audio[i : i + POINT_ONE_SECOND_IN_BYTES]
array.append(chunk)
if not chunk:
break
return array
def python_client_handler():
"""Downloads audios from the google cloud storage bucket and stream to
the Bidi streaming AnalyzeContent site.
"""
print("Start streaming")
conversation = conversation_management.create_conversation(
project_id=PROJECT_ID, conversation_profile_id=CONVERSATION_PROFILE_ID_STAGING
)
conversation_id = conversation.name.split("conversations/")[1].rstrip()
human_agent = human_agent = participant_management.create_participant(
project_id=PROJECT_ID, conversation_id=conversation_id, role="HUMAN_AGENT"
)
end_user = end_user = participant_management.create_participant(
project_id=PROJECT_ID, conversation_id=conversation_id, role="END_USER"
)
end_user_requests = []
agent_request= []
download_blob(BUCKET_NAME, FOLDER_PTAH_FOR_CUSTOMER_AUDIO, end_user_requests)
download_blob(BUCKET_NAME, FOLDER_PTAH_FOR_AGENT_AUDIO, agent_request)
participant_bidi_streaming_analyze_content( human_agent, agent_request)
participant_bidi_streaming_analyze_content( end_user, end_user_requests)
conversation_management.complete_conversation(PROJECT_ID, conversation_id)
Enable for telephony SipRec integration
You can enable telephony SipRec integration to use BidiStreamingAnalyzeContent for audio processing. Configure your audio processing either with the Agent Assist console or a direct API request.
Console
Follow these steps to configure your audio processing to use BidiStreamingAnalyzeContent.
Go to the Agent Assist console and select your project.
Click Conversation Profiles > the name of a profile.
Navigate to Telephony settings.
Click to enable Use Bidirectional Streaming API> Save.
API
You can call the API directly to create or update a conversation profile by configuring the flag at ConversationProfile.use_bidi_streaming.
Example configuration:
{
"name": "projects/PROJECT_ID/locations/global/conversationProfiles/CONVERSATION_PROFILE_ID",f
"displayName": "CONVERSATION_PROFILE_NAME",
"automatedAgentConfig": {
},
"humanAgentAssistantConfig": {
"notificationConfig": {
"topic": "projects/PROJECT_ID/topics/FEATURE_SUGGESTION_TOPIC_ID",
"messageFormat": "JSON"
},
},
"useBidiStreaming": true,
"languageCode": "en-US"
}
Quotas
The number of concurrent BidiStreamingAnalyzeContent requests is limited by a new quota ConcurrentBidiStreamingSessionsPerProjectPerRegion. See the Google Cloud quotas guide for information on quota usage and how to request a quota limit increase.
For quotas, the use of BidiStreamingAnalyzeContent requests to the global Dialogflow endpoint is in the us-central1 region.