Vision AI
画像、ドキュメント、動画から分析情報を抽出
API を介して高度なビジョンモデルにアクセスし、ビジョンタスクの自動化、分析の合理化、行動につながるインサイトの獲得を実現します。また、マネージド環境でノーコード モデル トレーニングと低コストでカスタムアプリを構築することもできます。
新規のお客様には、Vision AI や他の Google Cloud プロダクトを試すための無料クレジットを最大 $300 分差し上げます。
また、Google 推奨のドキュメントの要約ソリューションと AI/ML 画像処理ソリューションのデプロイもお試しください。
概要
コンピュータ ビジョンとは
コンピュータ ビジョンは人工知能(AI)の一分野であり、コンピュータとシステムが視覚データを解釈して分析し、デジタル画像、動画、その他の視覚入力から意味のある情報を導き出せるようにします。その代表的な実世界への応用には、オブジェクト検出、ビジュアル コンテンツ(画像、ドキュメント、動画)の処理、理解と分析、商品検索、画像の分類と検索、コンテンツ管理などがあります。
高度なマルチモーダル生成 AI
Google Cloud の Vertex AI では、最先端のマルチモーダル モデルのファミリーである Gemini にアクセスできます。Gemini は、ほぼすべての入力を理解し、さまざまな種類の情報を組み合わせて、ほぼすべての出力を生成できます。Gemini はビジュアル、テキスト、コードを混在させるタスクに適していますが、Gemini Pro Vision は、オブジェクト認識、デジタル コンテンツの理解、キャプションや説明など、さまざまな視覚関連のタスクに優れており、API を介してアクセスできます。
すぐに使える Vision AI
Google の事前トレーニング済みコンピュータ ビジョン ML モデルを搭載した Cloud Vision API は、すぐに利用できる API(REST および RPC)です。デベロッパーはこれを使用して、一般的なビジョン検出機能をアプリケーション内に簡単に統合できます。画像のラベル付け、顔やランドマークの検出、光学式文字認識(OCR)、不適切なコンテンツのタグ付け。
画像に適用した各機能が課金単位となります。Cloud Vision API では、毎月 1,000 ユニットの機能を無料で使用できます。詳細については、料金詳細をご覧ください。
生成 AI のドキュメント理解
Document AI は、コンピュータ ビジョンと自然言語処理などのテクノロジーを組み合わせて、スキャンされたドキュメントからテキストやデータを抽出し、非構造化データを構造化データやビジネス インサイトに変換するドキュメント理解プラットフォームです。
さまざまなタイプのドキュメント向けに最適化された幅広い事前トレーニング済みプロセッサを備えています。また、Document AI Workbench を使用すると、ドキュメントから構造化データを分類、分割、抽出するカスタム プロセッサを簡単に構築できます。

すぐに使える動画向け Vision AI
コンピュータ ビジョン技術を中核とする Video Intelligence API を使用すると、動画コンテンツを簡単に処理、分析、理解できます。
その事前トレーニング済み ML モデルは、保存された動画またはストリーミング動画に含まれる膨大な数のオブジェクト、場所、行動を優れた品質で自動的に認識します。コンテンツの管理とレコメンデーション、メディア アーカイブ、コンテキスト広告など、一般的なユースケースで非常に効率的です。また、特定のニーズに合わせて、Vertex AI Vision を使用してカスタム ML モデルをトレーニングすることもできます。

Visual Inspection AI
Visual Inspection AI は、製造業やその他の産業環境における外観検査タスクを自動化します。高度なコンピュータ ビジョンとディープ ラーニング技術を活用して、画像と動画の分析、異常の特定、欠陥の検出と位置の特定、組み立て製品の欠落や欠陥のチェックを行います。
技術的な専門知識がなく、ラベル付き画像が最小限で済むカスタムモデルをトレーニングし、生産ラインで推論を効率的に実行し、製造現場からの最新データでモデルを継続的に更新できます。

統合ビジョン AI プラットフォーム
Vertex AI Vision は、デベロッパーが、画像、ビデオ、表形式データなどのさまざまなデータ モダリティを処理するコンピュータ ビジョン アプリケーションを簡単に構築、デプロイ、管理できるフルマネージドのアプリケーション開発環境です。現在のサービスの 10 分の 1 の費用で、構築時間を数日から数分に短縮します。
独自のカスタムモデルを構築してデプロイし、CI/CD パイプラインで管理とスケーリングを行うことができます。また、TensorFlow や PyTorch などの一般的なオープンソース ツールとも統合されます。

データのプライバシーとセキュリティ
Google Cloud は業界最先端の機能を備えており、お客様はご自身のデータを制御し、データがいつ、どのようにアクセスされるかを可視化できます。
Google Cloud のお客様のデータの所有者はお客様です。厳格なセキュリティ対策を実施して顧客データを保護し、お客様が条件に合わせてデータをコントロールできるようにするツールと機能を提供しています。顧客データを所有するのはお客様であり、Google ではありません。お客様のデータは常に契約に基づいた方法で処理されます。
詳しくは、プライバシー リソース センターをご覧ください。
コンピュータ ビジョン プロダクトを比較する
| 提供プロダクト | 最適な用途 | 主な機能 |
|---|---|---|
基本的な視覚機能をすばやく簡単に統合できます。 | 画像ラベリング、顔やランドマークの検出、OCR、セーフサーチなどの事前構築済みの機能。 費用対効果に優れ、従量課金制です。 | |
スキャンしたドキュメントや画像から分析情報を抽出し、ドキュメント ワークフローを自動化。 | OCR(生成 AI を活用)、NLP、ML によるドキュメント理解、テキスト抽出、エンティティ識別、ドキュメントの分類。 | |
動画コンテンツ、コンテンツの管理とレコメンデーション、メディア アーカイブ、コンテキスト広告の分析。 | オブジェクトの検出とトラッキング、シーンの理解、アクティビティ認識、顔の検出と分析、テキストの検出と認識。 | |
製造業や工場の外観検査タスクを自動化 | 異常の検出、欠陥の検出と位置の特定、組み立てのチェックを行います。 | |
特定のニーズに合わせたカスタムモデルの構築とデプロイ。 | データ準備ツール、モデルのトレーニングとデプロイにより、ソリューションを完全に制御できます。技術的な専門知識が必要です。 | |
ビジュアル分析と理解、マルチモーダル質問応答。 | 情報探索、オブジェクト認識、デジタル コンテンツの理解、構造化コンテンツの生成、キャプション / 説明、推定。 | |
自動的な画像の説明を取得する。 画像分類と検索。 コンテンツの管理と推奨事項。 | 画像生成、画像編集、画像キャプション、マルチモーダル エンべディング。 機能とリリース ステージの一覧をご覧ください。 |
さまざまな目的に合わせて最適化されたこれらのプロダクトを使用すると、事前トレーニング済み ML モデルを活用してすぐに利用でき、微調整も簡単です。
基本的な視覚機能をすばやく簡単に統合できます。
画像ラベリング、顔やランドマークの検出、OCR、セーフサーチなどの事前構築済みの機能。
費用対効果に優れ、従量課金制です。
スキャンしたドキュメントや画像から分析情報を抽出し、ドキュメント ワークフローを自動化。
OCR(生成 AI を活用)、NLP、ML によるドキュメント理解、テキスト抽出、エンティティ識別、ドキュメントの分類。
動画コンテンツ、コンテンツの管理とレコメンデーション、メディア アーカイブ、コンテキスト広告の分析。
オブジェクトの検出とトラッキング、シーンの理解、アクティビティ認識、顔の検出と分析、テキストの検出と認識。
特定のニーズに合わせたカスタムモデルの構築とデプロイ。
データ準備ツール、モデルのトレーニングとデプロイにより、ソリューションを完全に制御できます。技術的な専門知識が必要です。
ビジュアル分析と理解、マルチモーダル質問応答。
情報探索、オブジェクト認識、デジタル コンテンツの理解、構造化コンテンツの生成、キャプション / 説明、推定。
自動的な画像の説明を取得する。
画像分類と検索。
コンテンツの管理と推奨事項。
画像生成、画像編集、画像キャプション、マルチモーダル エンべディング。
機能とリリース ステージの一覧をご覧ください。
さまざまな目的に合わせて最適化されたこれらのプロダクトを使用すると、事前トレーニング済み ML モデルを活用してすぐに利用でき、微調整も簡単です。

デモ
自分のファイルでコンピュータ ビジョンがどのように機能するかを確認する
一般的な使用例
未加工ファイル内のテキストを検出して自動的に要約
生成 AI で大規模なドキュメントを要約する
右側のアーキテクチャ図に示すソリューションは、新しい PDF ドキュメントを Cloud Storage バケットに追加したときにトリガーされるパイプラインをデプロイします。パイプラインは、ドキュメントからテキストを抽出し、抽出されたテキストから要約を作成します。その要約は、表示と検索ができるようにデータベースに保存されます。
このアプリケーションを呼び出すには、Jupyter ノートブックからファイルをアップロードするか、Google Cloud コンソールで Cloud Storage に直接ファイルをアップロードします。

推定デプロイ時間: 11 分(構成に 1 分、デプロイに 10 分)。
入門ガイド
生成 AI で大規模なドキュメントを要約する
右側のアーキテクチャ図に示すソリューションは、新しい PDF ドキュメントを Cloud Storage バケットに追加したときにトリガーされるパイプラインをデプロイします。パイプラインは、ドキュメントからテキストを抽出し、抽出されたテキストから要約を作成します。その要約は、表示と検索ができるようにデータベースに保存されます。
このアプリケーションを呼び出すには、Jupyter ノートブックからファイルをアップロードするか、Google Cloud コンソールで Cloud Storage に直接ファイルをアップロードします。
推定デプロイ時間: 11 分(構成に 1 分、デプロイに 10 分)。
画像処理パイプラインを構築する
サーバーレス アーキテクチャでのスケーラブルな画像処理
右側の図に示すソリューションでは、事前トレーニング済みの ML モデルを使用して、ユーザーから提供された画像を分析し、画像アノテーションを生成します。このソリューションをデプロイすると画像処理サービスが作成され、安全でない、または有害なユーザー作成コンテンツの処理、物理的なドキュメントのテキストのデジタル化、画像内のオブジェクトの検出と分類などが可能になります。
構成とセキュリティの設定を確認し、さまざまなニーズに合わせて画像処理サービスを調整する方法を理解できるようになります。

推定デプロイ時間: 12 分(構成に 2 分、デプロイに 10 分)。
入門ガイド
サーバーレス アーキテクチャでのスケーラブルな画像処理
右側の図に示すソリューションでは、事前トレーニング済みの ML モデルを使用して、ユーザーから提供された画像を分析し、画像アノテーションを生成します。このソリューションをデプロイすると画像処理サービスが作成され、安全でない、または有害なユーザー作成コンテンツの処理、物理的なドキュメントのテキストのデジタル化、画像内のオブジェクトの検出と分類などが可能になります。
構成とセキュリティの設定を確認し、さまざまなニーズに合わせて画像処理サービスを調整する方法を理解できるようになります。
推定デプロイ時間: 12 分(構成に 2 分、デプロイに 10 分)。
生成 AI で画像の説明を自動的に取得する
Imagen の Visual Captioning 機能を使用すると、画像に関連する説明を生成できます。この機能を使用すると、画像に関するより詳細なメタデータを取得して保存および検索し、自動字幕起こしを生成できます。また、ユーザー補助のユースケースをサポートしたり、プロダクトやビジュアル アセットの簡単な説明を受け取ったりできます。
この機能は、英語、フランス語、ドイツ語、イタリア語、スペイン語で利用でき、Google Cloud コンソールまたは API 呼び出しを介してアクセスできます。
入門ガイド
Imagen の Visual Captioning 機能を使用すると、画像に関連する説明を生成できます。この機能を使用すると、画像に関するより詳細なメタデータを取得して保存および検索し、自動字幕起こしを生成できます。また、ユーザー補助のユースケースをサポートしたり、プロダクトやビジュアル アセットの簡単な説明を受け取ったりできます。
この機能は、英語、フランス語、ドイツ語、イタリア語、スペイン語で利用でき、Google Cloud コンソールまたは API 呼び出しを介してアクセスできます。
動画のストリーミング処理
Vertex AI Vision でストリーミング動画から分析情報を取得する
アプリケーションで動画データを分析する前に、Vertex AI Vision の Stream サービスを使用して、連続的なデータフローのためのパイプラインを作成します。取り込まれたデータは、Google の事前トレーニング済みモデルまたはお客様のカスタムモデルによって分析されます。Stream からの分析出力は Vertex AI Vision Warehouse に保存され、そこで AI を活用した高度な検索機能を使用して、非構造化メディア コンテンツをクエリできます。
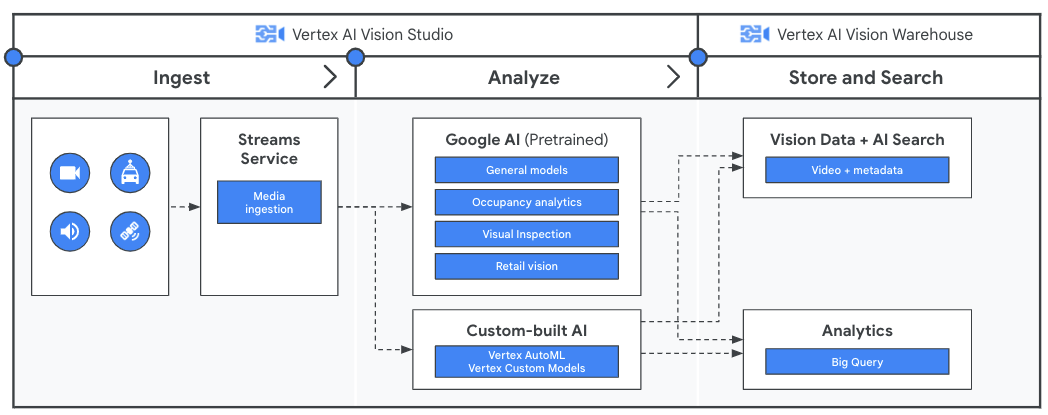
入門ガイド
Vertex AI Vision でストリーミング動画から分析情報を取得する
アプリケーションで動画データを分析する前に、Vertex AI Vision の Stream サービスを使用して、連続的なデータフローのためのパイプラインを作成します。取り込まれたデータは、Google の事前トレーニング済みモデルまたはお客様のカスタムモデルによって分析されます。Stream からの分析出力は Vertex AI Vision Warehouse に保存され、そこで AI を活用した高度な検索機能を使用して、非構造化メディア コンテンツをクエリできます。
生成 AI でドキュメントからテキストと分析情報を抽出する
Document AI で微妙なニュアンスを含むドキュメントから分析情報を引き出す
基盤モデルを活用した Document AI カスタム エクストラクタは、汎用的および分野固有のドキュメントからテキストとデータを迅速かつ正確に抽出します。わずか 5~10 個のドキュメントで簡単に微調整できるため、パフォーマンスがさらに向上します。
独自のモデルをトレーニングする場合は、基盤モデルを使用してデータセットに自動的にラベル付けを行い、本番環境への移行までの時間を短縮します。
トレーニング済みの専用プロセッサを使用することもできます。プロセッサの一覧をご覧ください。
入門ガイド
Document AI で微妙なニュアンスを含むドキュメントから分析情報を引き出す
基盤モデルを活用した Document AI カスタム エクストラクタは、汎用的および分野固有のドキュメントからテキストとデータを迅速かつ正確に抽出します。わずか 5~10 個のドキュメントで簡単に微調整できるため、パフォーマンスがさらに向上します。
独自のモデルをトレーニングする場合は、基盤モデルを使用してデータセットに自動的にラベル付けを行い、本番環境への移行までの時間を短縮します。
トレーニング済みの専用プロセッサを使用することもできます。プロセッサの一覧をご覧ください。
高精度の外観検査
Visual Inspection AI で品質検査を自動化する
Visual Inspection AI はすべてのステップで最適化されるため、セットアップが簡単で、ROI を迅速に確認できます。汎用 ML プラットフォームと比較して、高性能検査モデルのトレーニングを開始するためのラベル付き画像の数が最大で 300 分の 1 で、精度が最大 10 倍であることが示されています。技術的な専門知識がなくてもオンプレミスでモデルをトレーニングできます。何よりも、製造現場から流れるデータによってモデルを継続的に更新できるため、新しいユースケースが見つかるたびに精度が向上します。
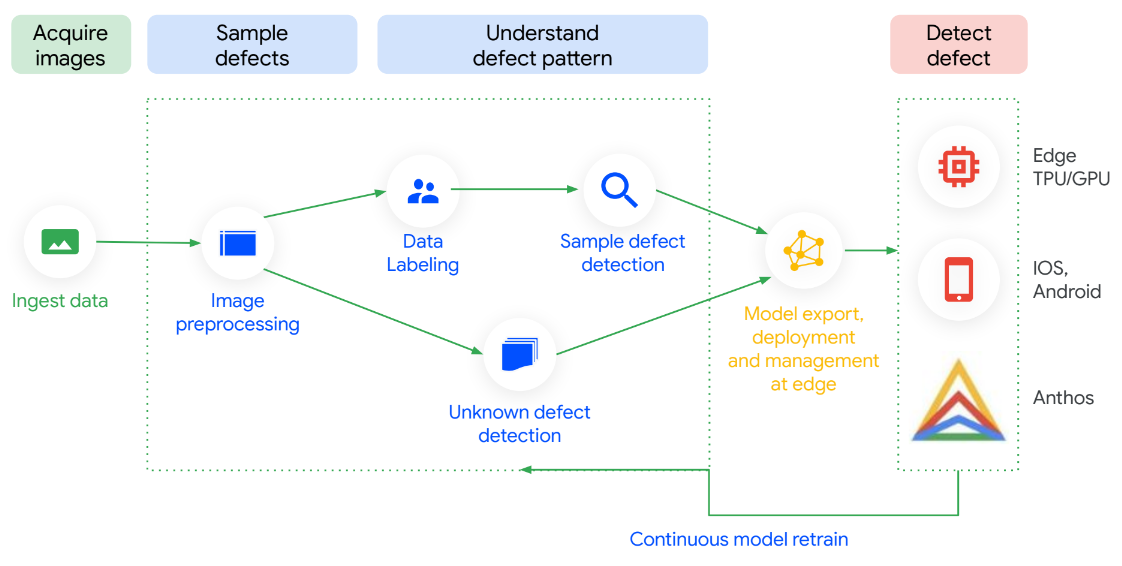
入門ガイド
Visual Inspection AI で品質検査を自動化する
Visual Inspection AI はすべてのステップで最適化されるため、セットアップが簡単で、ROI を迅速に確認できます。汎用 ML プラットフォームと比較して、高性能検査モデルのトレーニングを開始するためのラベル付き画像の数が最大で 300 分の 1 で、精度が最大 10 倍であることが示されています。技術的な専門知識がなくてもオンプレミスでモデルをトレーニングできます。何よりも、製造現場から流れるデータによってモデルを継続的に更新できるため、新しいユースケースが見つかるたびに精度が向上します。
料金
| Vision AI の料金の仕組み | 各 Vision サービスには一連の機能またはプロセッサがあり、それぞれ料金が異なります。詳細については、料金の詳細ページをご覧ください。 | ||
|---|---|---|---|
| 無料枠 | プロダクト / サービス | 割引価格 | 詳細 |
Vision API | 最初の 1,000 ユニット 毎月無料 | 5,000,001 以上のユニット 月額 | |
Document AI | なし 料金はプロセッサによって異なります。 | 5,000,001 ページ以上 Enterprise Document OCR プロセッサの月額 | |
Video Intelligence API | 最初の 1,000 分 月額無料 | 100,000 分以上 月額 | |
Vertex AI Vision | なし 料金は機能によって異なります。 |
| |
Imagen - マルチモーダル エンベディング |
|
| 米国 $0.0001 画像入力ごと |
Imagen - 画像キャプション |
|
| 米国 $0.0015 イメージごと |
Gemini Pro Vision | |||
Vision AI の料金の仕組み
各 Vision サービスには一連の機能またはプロセッサがあり、それぞれ料金が異なります。詳細については、料金の詳細ページをご覧ください。
Document AI
なし
料金はプロセッサによって異なります。
5,000,001 ページ以上
Enterprise Document OCR プロセッサの月額
Imagen - マルチモーダル エンベディング
米国 $0.0001
画像入力ごと
Imagen - 画像キャプション
米国 $0.0015
イメージごと











