What is Retrieval-Augmented Generation (RAG)?
RAG, which stands for Retrieval-Augmented Generation, is an AI framework that combines the strengths of traditional information retrieval systems (such as search and databases) with the capabilities of generative large language models (LLMs). By combining your data and world knowledge with LLM language skills, grounded generation is more accurate, up-to-date, and relevant to your specific needs. Check out this ebook to unlock your “Enterprise Truth.”
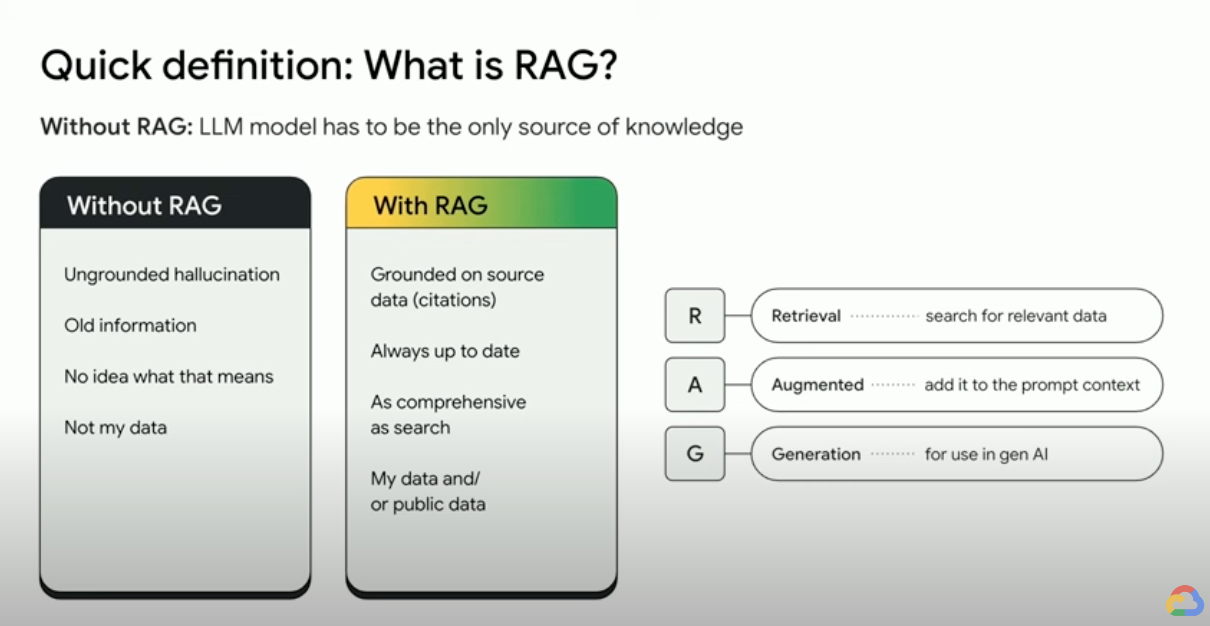
How does Retrieval-Augmented Generation work?
RAGs operate with a few main steps to help enhance generative AI outputs:
- Retrieval and pre-processing: RAGs leverage powerful search algorithms to query external data, such as web pages, knowledge bases, and databases. Once retrieved, the relevant information undergoes pre-processing, including tokenization, stemming, and removal of stop words.
- Grounded generation: The pre-processed retrieved information is then seamlessly incorporated into the pre-trained LLM. This integration enhances the LLM's context, providing it with a more comprehensive understanding of the topic. This augmented context enables the LLM to generate more precise, informative, and engaging responses.
Why use RAG?
RAG offers several advantages augmenting traditional methods of text generation, especially when dealing with factual information or data-driven responses. Here are some key reasons why using RAG can be beneficial:
Access to fresh information
LLMs are limited to their pre-trained data. This leads to outdated and potentially inaccurate responses. RAG overcomes this by providing up-to-date information to LLMs.
Factual grounding
LLMs are powerful tools for generating creative and engaging text, but they can sometimes struggle with factual accuracy. This is because LLMs are trained on massive amounts of text data, which may contain inaccuracies or biases.
Providing “facts” to the LLM as part of the input prompt can mitigate “gen AI hallucinations.” The crux of this approach is ensuring that the most relevant facts are provided to the LLM, and that the LLM output is entirely grounded on those facts while also answering the user’s question and adhering to system instructions and safety constraints.
Using Gemini’s long context window (LCW) is a great way to provide source materials to the LLM. If you need to provide more information than fits into the LCW, or if you need to scale up performance, you can use a RAG approach that will reduce the number of tokens, saving you time and cost.
Search with vector databases and relevancy re-rankers
RAGs usually retrieve facts via search, and modern search engines now leverage vector databases to efficiently retrieve relevant documents. Vector databases store documents as embeddings in a high-dimensional space, allowing for fast and accurate retrieval based on semantic similarity. Multi-modal embeddings can be used for images, audio and video, and more and these media embeddings can be retrieved alongside text embeddings or multi-language embeddings.
Advanced search engines like Agent Search on Gemini Enterprise Agent Platform use semantic search and keyword search together (called hybrid search), and a re-ranker which scores search results to ensure the top returned results are the most relevant. Additionally searches perform better with a clear, focused query without misspellings; so prior to lookup, sophisticated search engines will transform a query and fix spelling mistakes.
Relevance, accuracy, and quality
The retrieval mechanism in RAG is critically important. You need the best semantic search on top of a curated knowledge base to ensure that the retrieved information is relevant to the input query or context. If your retrieved information is irrelevant, your generation could be grounded but off-topic or incorrect.
By fine-tuning or prompt-engineering the LLM to generate text entirely based on the retrieved knowledge, RAG helps to minimize contradictions and inconsistencies in the generated text. This significantly improves the quality of the generated text, and improves the user experience.
The Model evaluation in Gemini Enterprise Agent Platform now scores LLM generated text and retrieved chunks on metrics like “coherence,” “fluency,” “groundedness,” "safety," “instruction_following,” “question_answering_quality,” and more. These metrics help you measure the grounded text you get from the LLM (for some metrics that is a comparison to a ground truth answer you have provided). Implementing these evaluations gives you a baseline measurement and you can optimize for RAG quality by configuring your search engine, curating your source data, improving source layout parsing or chunking strategies, or refining the user’s question prior to search. A RAG Ops, metrics driven approach like this will help you hill climb to high quality RAG and grounded generation.
RAGs, agents, and chatbots
RAG and grounding can be integrated into any LLM application or agent which needs access to fresh, private, or specialized data. By accessing external information, RAG-powered chatbots and conversational agents leverage external knowledge to provide more comprehensive, informative, and context-aware responses, improving the overall user experience.
Your data and your use case are what differentiate what you are building with gen AI. RAG and grounding bring your data to LLMs efficiently and scalably.
What Google Cloud products and services are related to RAG?
The following Google Cloud products are related to Retrieval-Augmented Generation:
 Gemini Enterprise Agent Platform RAG EngineData framework for developing context-augmented LLM applications, and facilitates retrieval-augmented generation.
Gemini Enterprise Agent Platform RAG EngineData framework for developing context-augmented LLM applications, and facilitates retrieval-augmented generation.- Agent Search on Gemini Enterprise Agent PlatformAgent Search is Google Search for your data, a fully managed, out-of-the-box search and RAG builder.
 Vector Search on Gemini Enterprise Agent PlatformThe ultra performant vector index that powers Agent Search; it enables semantic and hybrid search and retrieval from huge collections of embeddings with high recall at high query rate.
Vector Search on Gemini Enterprise Agent PlatformThe ultra performant vector index that powers Agent Search; it enables semantic and hybrid search and retrieval from huge collections of embeddings with high recall at high query rate. BigQueryLarge datasets that you can use to train machine learning models, including models for Vector Search on Agent Platform.
BigQueryLarge datasets that you can use to train machine learning models, including models for Vector Search on Agent Platform.- Grounded Generation APIGemini high-fidelity mode grounded with Google Search or inline facts or bring your own search engine.
 AlloyDB AIRun models in Agent Platform and access them in your application using familiar SQL queries. Use Google models, such as Gemini, or your own custom models.
AlloyDB AIRun models in Agent Platform and access them in your application using familiar SQL queries. Use Google models, such as Gemini, or your own custom models.
Further reading
Learn more about using retrieval augmented generation with these resources.
- RAGs powered by Google Search technology
- RAG with databases on Google Cloud
- APIs to build your own search and Retrieval Augmented Generation (RAG) systems
- How to use RAG in BigQuery to bolster LLMs
- Code sample and quickstart to get familiar with RAG
- Infrastructure for a RAG-capable generative AI application using GKE
Take the next step
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Need help getting started?
Contact salesWork with a trusted partner
Find a partnerContinue browsing
See all products


















