IA da Text-to-Speech
Converta texto em fala com som natural usando uma API desenvolvida com as melhores tecnologias de IA do Google.
Novos clientes ganham até US $300 em créditos para testar a Text-to-Speech e outros produtos do Google Cloud.
Melhore as interações com os clientes com respostas inteligentes e realistas
Envolva os usuários com a interface do usuário de voz nos seus dispositivos e aplicativos
Personalize sua comunicação com base na preferência do usuário por voz e idioma

Vantagens
Fala de alta fidelidade
Implante as tecnologias inovadoras do Google para gerar voz com entonação similar à humana. Criada com base na experiência em síntese de fala da DeepMind, a API proporciona vozes com qualidade semelhante às humanas.
Seleção de voz mais ampla
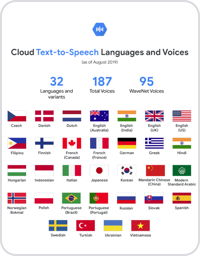
Escolha dentre um conjunto de mais de 380 vozes em mais de 50 idiomas e variantes, incluindo mandarim, hindi, espanhol, árabe, russo e muitos outros. Escolha a voz que combina mais com seu usuário e aplicativo.
Voz exclusiva
Crie uma voz exclusiva para representar sua marca em todos os pontos de contato com o cliente, em vez de usar uma voz comum compartilhada com outras organizações.
Demonstração
Coloque a Text-to-Speech em ação
Digite o que você quer ouvir, selecione um idioma e clique em “Speak It”.
Principais recursos
Principais recursos
Chirp 3: vozes em alta definição
Crie agentes carismáticos usando as novas vozes de conversação espontânea baseadas no AudioLM. Essas vozes oferecem áudio de alta qualidade, streaming de baixa latência e fala com som natural, incorporando hesitações humanas e entonação precisa.
Vozes de estúdio
Surpreenda seus ouvintes com conteúdo narrado por profissionais e gravado com qualidade de estúdio. Coloque seus fones de ouvido!
Agora você pode gerar diálogos com vários falantes para criar cenários mais interativos.
Vozes Neural2
Internacionalize sua experiência usando vozes pré-criadas com base na pesquisa mais recente sobre a voz personalizada.
Voz personalizada instantânea
Crie modelos de voz personalizados com apenas 10 segundos de entrada de áudio. Confira o acesso antecipado.
Suporte a texto e SSML
Personalize sua fala com tags SSML que permitem adicionar pausas, números, datas, formatação de data e hora, e outras instruções de pronúncia.
O que há de novo
O que há de novo
Inscreva-se na newsletter do Google Cloud para receber atualizações de produtos, informações sobre eventos, ofertas especiais e muito mais.




Documentação
Casos de uso
Casos de uso
Bots de voz em centrais de atendimento
Ofereça uma melhor experiência de voz para o atendimento ao cliente com bots de voz no Dialogflow que geram fala dinamicamente, em vez de reproduzir áudio estático, pré-gravado. Interaja com vozes sintetizadas de alta qualidade que proporcionam aos autores da chamada uma sensação de familiaridade e personalização.

Geração de voz em dispositivos
Permita comunicações naturais com seus usuários, capacitando seus dispositivos a gerar vozes semelhantes às humanas como um leitor de texto. Crie uma interface de usuário de voz completa junto com a Speech-to-Text e a Natural Language para melhorar a experiência do usuário com interações fáceis e atrativas.

EPGs (guias de programação eletrônica) acessíveis
Os EPGs podem ler o texto em voz alta para fornecer uma melhor experiência de usuário aos seus clientes e atender aos requisitos de acessibilidade para seus serviços e aplicativos. Experimente a demonstração do EPG.
Implemente com facilidade a funcionalidade de conversão de texto em voz nos EPGs para oferecer uma melhor experiência de usuário aos clientes e atender aos requisitos de acessibilidade para seus serviços e aplicativos.

Todos os recursos
Todos os recursos
| Voz personalizada instantânea | Crie modelos de voz personalizados usando suas próprias gravações de áudio e gere uma voz única e natural para sua organização. Isso possibilita a geração rápida de vozes pessoais, que podem ser usadas para sintetizar áudio usando a API Cloud TTS, com suporte para streaming e textos longos. Saiba mais |
| Síntese de áudio longa | Sintetize até 1 milhão de bytes de entrada de maneira assíncrona com o recurso Síntese de áudio longa. |
| Seleção de voz e idioma | Escolha dentre uma ampla seleção de mais de 220 vozes em mais de 40 idiomas e variantes. Em breve, serão feitas mais adições. |
| Vozes WaveNet | Aproveite as mais de 90 vozes WaveNet criadas com base na pesquisa inovadora da DeepMind para gerar falas que trazem um resultado significativamente mais próximo ao humano. |
| Suporte a texto e SSML | Personalize sua fala com tags SSML que permitem a você adicionar pausas, números, formatação de data e hora, e outras instruções de pronúncia. |
| Ajuste de tom | Personalize o tom da sua voz selecionada em até 20 semitons acima ou abaixo do padrão. |
| Ajuste da taxa de fala | Aumente ou diminua a velocidade da sua fala em até quatro vezes. |
| Controle do ganho de volume | Aumente o volume da saída em até 16 dB ou reduza-o em até -96 dB. |
| APIs REST e gRPC integradas | Faça integrações facilmente com qualquer aplicativo ou dispositivo que possa enviar uma solicitação REST ou gRPC, incluindo smartphones, PCs, tablets e dispositivos de IoT, como carros, TVs e alto-falantes. |
| Flexibilidade no formato de áudio | Converta texto em MP3, Linear16, OGG Opus e vários outros formatos de áudio. |
| Perfis de áudio | Otimize para o tipo de alto-falante em que sua fala deve ser reproduzida, como fones de ouvido ou linhas telefônicas. |
Preços
Preços
Os preços da Text-to-Speech se baseiam no número de caracteres enviados para que o serviço os sintetize em áudio a cada mês. O primeiro milhão de caracteres para vozes WaveNet é gratuito todos os meses. Para vozes padrão (não WaveNet), os primeiros 4 milhões de caracteres são gratuitos todos os meses. Depois que o Nível gratuito é atingido, a Text-to-Speech é cobrada a cada um milhão de caracteres de texto processado.
Se você não paga em dólar americano, valem os preços na sua moeda local listados na página SKUs do Google Cloud.
Vá além
Clientes novos ganham US$ 300 em créditos para testar a Text-to-Speech e outros produtos do Google Cloud.
Precisa de ajuda para começar?
Entre em contato com a equipe de vendasTrabalhe com um parceiro confiável
Encontre um parceiroContinue navegando
Ver todos os produtos











