O serviço gerenciado do Google Cloud para o Prometheus cobra pelo número de amostras ingeridas no Cloud Monitoring e por solicitações de leitura para a API Monitoring. O número de amostras ingeridas é o principal colaborador do seu custo.
Neste documento, você verá como controlar os custos associados ao processamento de métricas e como identificar fontes de ingestão de alto volume.
Para mais informações sobre os preços do serviço gerenciado para o Prometheus, consulte as seções do Cloud Monitoring na página Preços da observabilidade do Google Cloud.
Ver sua fatura
Para conferir sua fatura do Google Cloud , faça o seguinte:
No console Google Cloud , acesse a página Faturamento.
Se você tiver mais de uma conta de faturamento, selecione Ir para a conta de faturamento vinculada para ver a conta do projeto atual. Para localizar outra conta de faturamento, selecione Gerenciar contas de faturamento e escolha aquela cujos relatórios de uso você quer receber.
Na seção Gerenciamento de custos do menu de navegação do Billing, selecione Relatórios.
No menu Serviços, selecione a opção Cloud Monitoring.
No menu SKUs, selecione as seguintes opções:
- Amostras do Prometheus ingeridas
- Solicitações da API Monitoring
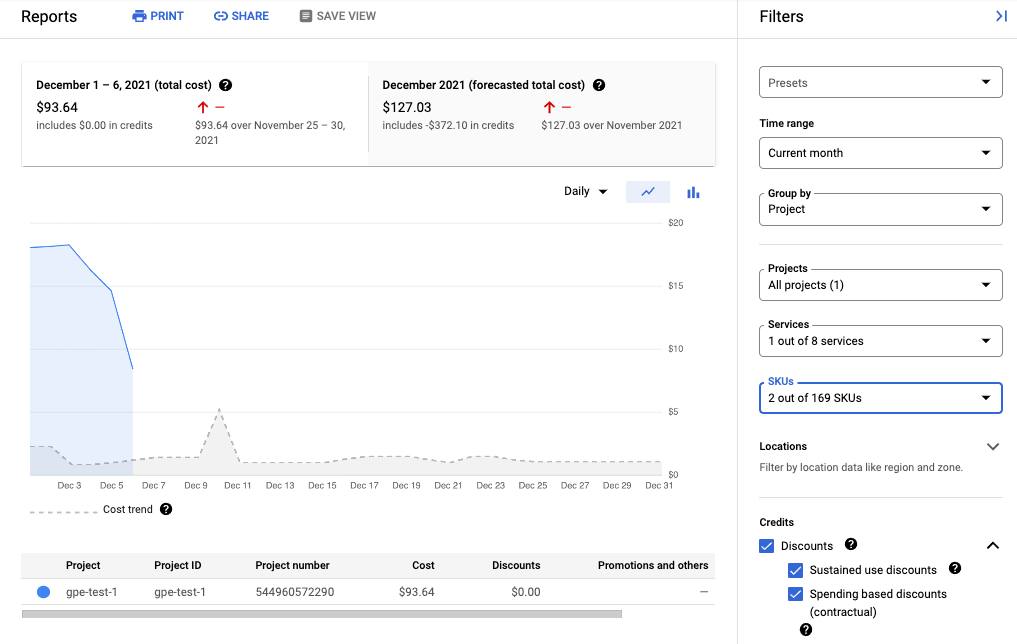
A captura de tela a seguir mostra o relatório de faturamento do serviço gerenciado para o Prometheus em um projeto:
Reduzir os custos
Para reduzir os custos associados ao uso do serviço gerenciado para o Prometheus, faça o seguinte:
- Filtre os dados de métricas gerados para reduzir o número de séries temporais que você envia ao serviço gerenciado.
- Reduza o número de amostras coletadas alterando o intervalo de extração.
- Limite o número de amostras de métricas de alta cardinalidade potencialmente configuradas incorretamente.
Reduzir o número de séries temporais
A documentação do Prometheus de código aberto raramente recomenda a filtragem do volume de métricas, o que é razoável quando os custos são limitados pelos custos da máquina. No entanto, o pagar por um provedor de serviços gerenciados com base na unidade, enviar dados ilimitados pode gerar contas desnecessariamente altas.
Os exportadores incluídos no projeto kube-prometheus
(o serviço kube-state-metrics
em particular) podem emitir muitos dados de métricas.
Por exemplo, o serviço kube-state-metrics emite centenas de métricas,
muitas delas podem ser completamente sem valor para você como consumidor. Um
novo cluster de três nós que usa o projeto kube-prometheus envia
aproximadamente 900 amostras por segundo para o serviço gerenciado para o Prometheus.
Filtrar essas métricas externas pode ser suficiente para que sua fatura chegue a um
nível aceitável.
Para reduzir o número de métricas, faça o seguinte:
- Modifique suas configurações de scrape para coletar menos destinos.
- Filtre as métricas coletadas conforme descrito a seguir:
- Filtre as métricas exportadas ao usar a coleção gerenciada.
- Filtre as métricas exportadas ao usar a coleção autoimplantada.
Se você estiver usando o serviço kube-state-metrics, é possível adicionar uma
regra de reidentificação do Prometheus com uma ação
keep. Para a coleta gerenciada, essa regra fica na definição de PodMonitoring ou
ClusterPodMonitoring. Para
a coleta autoimplantada, essa regra entra na configurações de raspagem de dados do Prometheus ou na definição de
ServiceMonitor (para
prometheus-operator).
Por exemplo, usar o filtro a seguir em um novo cluster de três nós reduz o volume da amostra em aproximadamente 125 amostras por segundo:
metricRelabeling:
- action: keep
regex: kube_(daemonset|deployment|pod|namespace|node|statefulset|persistentvolume|horizontalpodautoscaler)_.+
sourceLabels: [__name__]
O filtro anterior usa uma expressão regular para especificar quais métricas devem ser mantidas com base no nome da métrica. Por exemplo, as métricas com nomes que começam com kube_daemonset_ são mantidas.
Também é possível especificar uma ação de drop, que filtra as métricas que correspondem à expressão regular.
Às vezes, pode parecer que um exportador inteiro é irrelevante. Por exemplo, por padrão,
o pacote kube-prometheus instala os seguintes monitores de serviço, muitos
dos quais são desnecessários em um ambiente gerenciado:
alertmanagercorednsgrafanakube-apiserverkube-controller-managerkube-schedulerkube-state-metricskubeletnode-exporterprometheusprometheus-adapterprometheus-operator
Para reduzir o número de métricas exportadas, exclua, desative ou
interrompa a coleta de monitores de serviço desnecessários. Por exemplo, desativar o
monitor de serviço kube-apiserver em um novo cluster de três nós reduz o
volume de amostras em aproximadamente 200 amostras por segundo.
Reduzir o número de amostras coletadas
A cobrança do Serviço gerenciado é feita por amostra no Prometheus. Para reduzir o número de amostras ingeridas, aumente o período de amostragem. Exemplo:
- Alterar um período de amostragem de 10 segundos para um período de amostragem de 30 segundos, pode reduzir o volume de amostras em 66%, sem muita perda de informações.
- Alterar um período de amostragem de 10 segundos para um período de amostragem de 60 segundos pode reduzir o volume da amostra em 83%.
Para informações sobre como as amostras são contadas e como o período de amostragem afeta o número de amostras, consulte Dados de métricas cobrados por amostras ingeridas.
Geralmente, é possível definir o intervalo de extração por job ou por segmentação.
Para a coleção gerenciada, defina o intervalo de extração no
recurso PodMonitoring usando o campo interval.
Para a coleção autoimplantada, defina o intervalo de amostragem nas configurações
de extração, geralmente definindo um campo interval ou scrape_interval.
Configurar agregação local (somente coleção autoimplantada)
Se você estiver configurando o serviço com coleção autoimplantada,
por exemplo, com o kube-prometheus, o prometheus-operator ou implantando manualmente
a imagem, será possível reduzir amostras enviadas ao serviço gerenciado para o Prometheus
agregando localmente métricas de alta cardinalidade. É possível usar regras de gravação para agregar identificadores como instance e usar a sinalização --export.match ou a variável de ambiente EXTRA_ARGS para enviar apenas dados agregados ao Monarch.
Por exemplo, suponha que você tenha três métricas, high_cardinality_metric_1, high_cardinality_metric_2 e low_cardinality_metric. Você quer reduzir as amostras enviadas para
high_cardinality_metric_1 e eliminar todas as amostras enviadas para
high_cardinality_metric_2, mantendo todos os dados brutos armazenados localmente, talvez
para fins de alerta. Sua configuração ficaria mais ou menos assim:
- Implante a imagem do serviço gerenciado para o Prometheus.
- Defina suas configurações de scrape para coletar todos os dados brutos no servidor local usando a quantidade de filtros que você quiser.
Configure as regras de gravação para executar agregações locais por
high_cardinality_metric_1ehigh_cardinality_metric_2, talvez agregando o rótuloinstanceou qualquer número de rótulos de métrica, dependendo do que fornece o melhor redução no número de séries temporais desnecessárias. Execute uma regra como esta, que descarta o rótuloinstancee soma a série temporal resultante sobre os rótulos restantes:record: job:high_cardinality_metric_1:sum expr: sum without (instance) (high_cardinality_metric_1)
Consulte operadores de agregação na documentação do Prometheus para ver mais opções de agregação.
Implante a imagem do Serviço gerenciado para o Prometheus com a seguinte sinalização de filtro, que impede que os dados brutos das métricas listadas sejam enviados para o Monarch:
--export.match='{__name__!="high_cardinality_metric_1",__name__!="high_cardinality_metric_2"}'Este exemplo de sinalização
export.matchusa seletores separados por vírgulas com o operador!=para filtrar dados brutos indesejados. Se você adicionar outras regras de gravação para agregar outras métricas de alta cardinalidade, também será necessário adicionar um novo seletor__name__ao filtro para que os dados brutos sejam descartados. Ao usar uma única sinalização com vários seletores com o operador!=para filtrar dados indesejados, só é necessário modificar o filtro ao criar uma nova agregação, em vez de sempre que você modificar ou adicionar uma configuração de scrape.Determinados métodos de implantação, como o operador Prometheus, podem exigir que você omita as aspas simples entre colchetes.
Esse fluxo de trabalho pode gerar alguma sobrecarga operacional na criação e no gerenciamento de
regras de gravação e sinalizações export.match, mas é provável que você reduza muito
o volume ao se concentrar apenas em métricas com cardinalidade excepcionalmente alta. Para
informações sobre como identificar quais métricas podem se beneficiar mais da pré-agregação
local, consulte Identificar métricas de alto volume.
Não implemente a federação ao usar o serviço gerenciado para o Prometheus. Esse fluxo de trabalho torna o uso de servidores de federação obsoletos, porque um único servidor do Prometheus implantado pode executar quaisquer agregações no nível do cluster necessárias. A federação pode causar efeitos inesperados, como métricas do tipo "desconhecido" e volume de processamento duplicado.
Limitar as amostras de métricas de alta cardinalidade (somente coleção autoimplantada)
É possível criar métricas de cardinalidade extremamente altas adicionando rótulos com um
grande número de valores em potencial, como um ID do usuário ou um endereço IP. Essas
métricas podem gerar um número muito grande de amostras. Usar rótulos
com um grande número de valores normalmente é uma configuração incorreta. É possível
proteger contra métricas de alta cardinalidade nos coletores autoimplantados
definindo um valor sample_limit
nas configurações de extração.
Se você usar esse limite, recomendamos defini-lo como um valor muito alto para que ele capture apenas métricas configuradas incorretamente. Todas as amostras acima do limite são descartadas e pode ser muito difícil diagnosticar problemas causados ao exceder o limite.
Usar um limite de amostra não é uma boa maneira de gerenciar a ingestão de amostra, mas
o limite pode protegê-lo contra erros de configuração acidentais. Para mais
informações, consulte
Como usar sample_limit para evitar sobrecarga.
Identifique e atribua custos
Use o Cloud Monitoring para identificar as métricas do Prometheus que estão gravando o maior número de amostras. Essas métricas estão contribuindo mais para seus custos. Depois de identificar as métricas mais caras, é possível modificar as configurações de verificação para filtrá-las de maneira adequada.
A página Gerenciamento de métricas do Cloud Monitoring fornece informações que podem ajudar a controlar o valor gasto em métricas sujeitas a cobrança, sem afetar a observabilidade. A página Gerenciamento de métricas mostra as seguintes informações:
- Volumes de ingestão para faturamento baseado em byte e amostra, em domínios de métricas e para métricas individuais.
- Dados sobre rótulos e cardinalidade de métricas.
- O número de leituras de cada métrica.
- O uso de métricas em políticas de alertas e painéis personalizados.
- A taxa de erros de gravação das métricas.
Você também pode usar o Gerenciamento de métricas para excluir métricas desnecessárias, eliminando o custo de ingestão delas.
Para visualizar a página Gerenciamento de métricas, faça o seguinte:
-
No Google Cloud console, acesse a página Gerenciamento de métricas:
Acesse os Gerenciamento de métricas
Se você usar a barra de pesquisa para encontrar essa página, selecione o resultado com o subtítulo Monitoramento.
- Na barra de ferramentas, selecione a janela de tempo. Por padrão, a página Gerenciamento de métricas exibe informações sobre as métricas coletadas no dia anterior.
Para mais informações sobre a página Gerenciamento de métricas, consulte Ver e gerenciar o uso de métricas.
As seções a seguir descrevem maneiras de analisar o número de amostras que você está enviando ao Managed Service para Prometheus e atribuir alto volume a métricas específicas, namespaces do Kubernetes e regiões do Google Cloud .
Identifique métricas de alto volume
Para identificar as métricas do Prometheus com os maiores volumes de ingestão, faça o seguinte:
-
No Google Cloud console, acesse a página Gerenciamento de métricas:
Acesse os Gerenciamento de métricas
Se você usar a barra de pesquisa para encontrar essa página, selecione o resultado com o subtítulo Monitoramento.
- Na visão geral Amostras faturáveis ingeridas, clique em Ver gráficos.
- Localize o gráfico Ingestão de volume de namespace e clique em more_vert Mais opções de gráfico.
- Selecione a opção de gráfico Ver no Metrics Explorer.
- No painel Builder do Metrics Explorer, modifique os campos da seguinte maneira:
- NaMétrica verifique se o recurso e a métrica a seguir estão selecionados:
Metric Ingestion AttributioneSamples written by attribution id. - No campo
Agregação, selecione
sum. - No campo por, selecione
os seguintes rótulos:
attribution_dimensionmetric_type
- No campo Filtro, use
attribution_dimension = namespace. Faça isso depois de agregar pelo rótuloattribution_dimension.
O gráfico resultante mostra os volumes de ingestão de cada tipo de métrica.
- NaMétrica verifique se o recurso e a métrica a seguir estão selecionados:
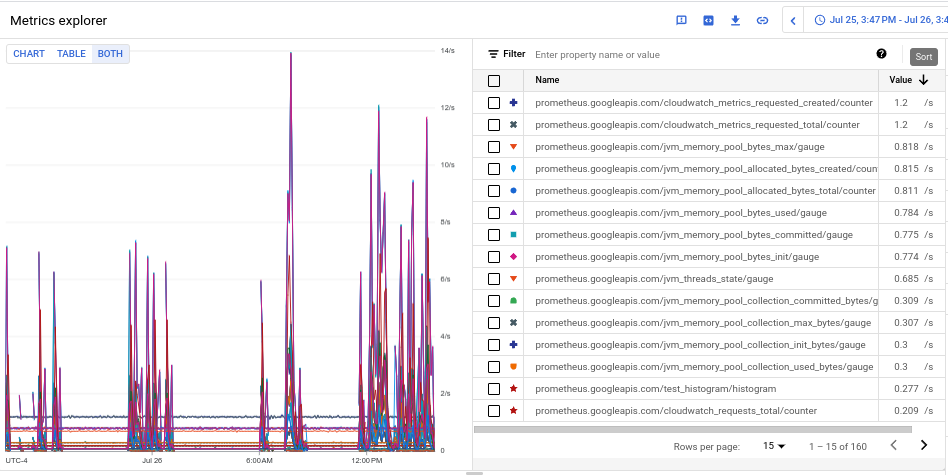
- Para ver o volume de ingestão de cada uma das métricas, alterne para Tabela de gráficos ambos, selecione Ambos. A tabela mostra o volume ingerido de cada métrica na coluna Valor.
- Clique no cabeçalho da coluna Valor duas vezes para classificar as métricas por volume de ingestão decrescente.
O gráfico resultante, que mostra suas principais métricas por volume classificado por média, se parece com a seguinte captura de tela:
Identifique namespaces de alto volume
Para atribuir volume de processamento a namespaces específicos do Kubernetes, faça o seguinte:
-
No Google Cloud console, acesse a página Gerenciamento de métricas:
Acesse os Gerenciamento de métricas
Se você usar a barra de pesquisa para encontrar essa página, selecione o resultado com o subtítulo Monitoramento.
- Na visão geral Amostras faturáveis ingeridas, clique em Ver gráficos.
- Localize o gráfico Ingestão de volume de namespace e clique em more_vert Mais opções de gráfico.
- Selecione a opção de gráfico Ver no Metrics Explorer.
- No painel Builder do Metrics Explorer, modifique os campos da seguinte maneira:
- NaMétrica verifique se o recurso e a métrica a seguir estão selecionados:
Metric Ingestion AttributioneSamples written by attribution id. - Configure o restante dos parâmetros de consulta conforme apropriado:
- Para correlacionar o volume de ingestão geral com namespaces:
- No campo
Agregação, selecione
sum. - No campo por, selecione os
seguintes rótulos:
attribution_dimensionattribution_id
- No campo Filtro, use
attribution_dimension = namespace.
- No campo
Agregação, selecione
- Para correlacionar o volume de ingestão de métricas individuais com namespaces:
- No campo
Agregação, selecione
sum. - No campo por, selecione
os seguintes rótulos:
attribution_dimensionattribution_idmetric_type
- No campo Filtro, use
attribution_dimension = namespace.
- No campo
Agregação, selecione
- Para identificar os namespaces responsáveis por uma métrica específica de alto volume:
- Identifique o tipo de métrica da métrica de alto volume usando um dos outros exemplos para identificar tipos de métricas de alto volume. O tipo de métrica é a string na visualização em tabela que começa com
prometheus.googleapis.com/. Para mais informações, consulte Identificar métricas de alto volume. - Restrinja os dados do gráfico ao tipo de métrica identificado
adicionando um filtro para o tipo de métrica no campo
Filtro. Por exemplo:
metric_type= prometheus.googleapis.com/container_tasks_state/gauge. - No campo
Agregação, selecione
sum. - No campo por, selecione
os seguintes rótulos:
attribution_dimensionattribution_id
- No campo Filtro, use
attribution_dimension = namespace.
- Identifique o tipo de métrica da métrica de alto volume usando um dos outros exemplos para identificar tipos de métricas de alto volume. O tipo de métrica é a string na visualização em tabela que começa com
- Para ver o processamento por região Google Cloud , adicione o
rótulo
locationao campo por. - Para ver a ingestão por projeto do Google Cloud , adicione o
rótulo
resource_containerao campo por.
- Para correlacionar o volume de ingestão geral com namespaces:
- NaMétrica verifique se o recurso e a métrica a seguir estão selecionados: