本文說明在使用自行部署的收集作業的 Managed Service for Prometheus 部署中,規則和警示評估的設定。
下圖說明在兩個 Google Cloud 專案中使用多個叢集,並同時使用規則和警示評估的部署方式:
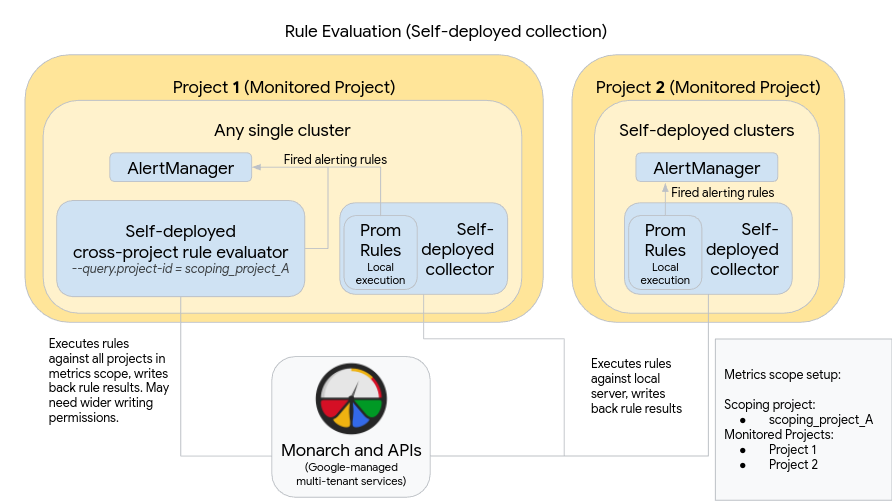
如要設定及使用圖表中的部署作業,請注意下列事項:
就像使用標準 Prometheus 一樣,規則會安裝在每個 Managed Service for Prometheus 收集伺服器中。規則評估會針對各伺服器上本機儲存的資料執行。伺服器會保留足夠長的資料,涵蓋所有規則的回溯期,通常不超過 1 小時。評估完成後,系統會將規則結果寫入 Monarch。
在每個叢集中手動部署 Prometheus AlertManager 例項。如要設定 Prometheus 伺服器,請編輯設定檔的
alertmanager_config欄位,將觸發的警示規則傳送至本機 AlertManager 例項。靜默、確認和事件管理工作流程通常會在第三方工具 (例如 PagerDuty) 中處理。您可以使用 Kubernetes Endpoints 資源,將多個叢集的警示管理集中到單一 AlertManager。
在 Google Cloud 中執行的單一叢集會指定為指標範圍的全球規則評估叢集。獨立規則評估器會部署在該叢集中,並使用標準 Prometheus 規則檔案格式安裝規則。
獨立規則評估工具已設定為使用 scoping_project_A,其中包含專案 1 和 2。針對 scoping_project_A 執行的規則會自動擴散至專案 1 和 2。基礎服務帳戶必須具備 scoping_project_A 的 Monitoring Viewer 權限。
規則評估工具已設定為使用設定檔的
alertmanager_config欄位,將警示傳送至本機 Prometheus Alertmanager。
使用自行部署的全域規則評估器可能會產生意想不到的效果,這取決於您是否保留或匯總規則中的 project_id、location、cluster 和 namespace 標籤:
如果規則保留
project_id標籤 (使用by(project_id)子句),則會使用基礎時間序列的原始project_id值,將規則結果寫回 Monarch。在這種情況下,您必須確保底層服務帳戶具備 scoping_project_A 中每個監控專案的 Monitoring Metric Writer 權限。如果您要將新的監控專案新增至 scoping_project_A,則必須手動為服務帳戶新增權限。
如果規則未保留
project_id標籤 (未使用by(project_id)子句),則系統會使用執行全域規則評估器的叢集project_id值,將規則結果寫回 Monarch。在這種情況下,您不需要進一步修改基礎服務帳戶。
如果您的規則保留
location標籤 (透過使用by(location)子句),則會使用基礎時序資料來源的每個原始 Google Cloud 區域,將規則結果寫回 Monarch。如果規則未保留
location標籤,資料就會寫回全域規則評估工具執行的叢集位置。
強烈建議您盡可能保留規則評估結果中的 cluster 和 namespace 標籤。否則,查詢效能可能會降低,且可能會遇到基數限制。強烈建議您不要移除兩個標籤。