En este documento, se describe cómo puedes configurar un entorno que combine recopiladores autoimplementados con recopiladores administrados en diferentes clústeres y proyectos deGoogle Cloud .
Te recomendamos que uses la recopilación administrada para todos los entornos de Kubernetes. Así, prácticamente se elimina la sobrecarga que implica ejecutar recopiladores de Prometheus dentro del clúster. Puedes ejecutar recopiladores administrados y autoimplementados dentro del mismo clúster. Te recomendamos que uses un enfoque coherente en la supervisión, pero puedes optar por combinar métodos de implementación para algunos casos de uso específicos, como alojar una puerta de enlace de envío, como se muestra en este documento.
En el siguiente diagrama, se ilustra una configuración en la que se usan dos proyectos deGoogle Cloud , tres clústeres y una combinación de recopilación administrada y autoimplementada. Si usas solo la recopilación administrada o la autoimplementada, el diagrama seguirá siendo aplicable. Tan solo ignora el estilo de recopilación que no vayas a usar:
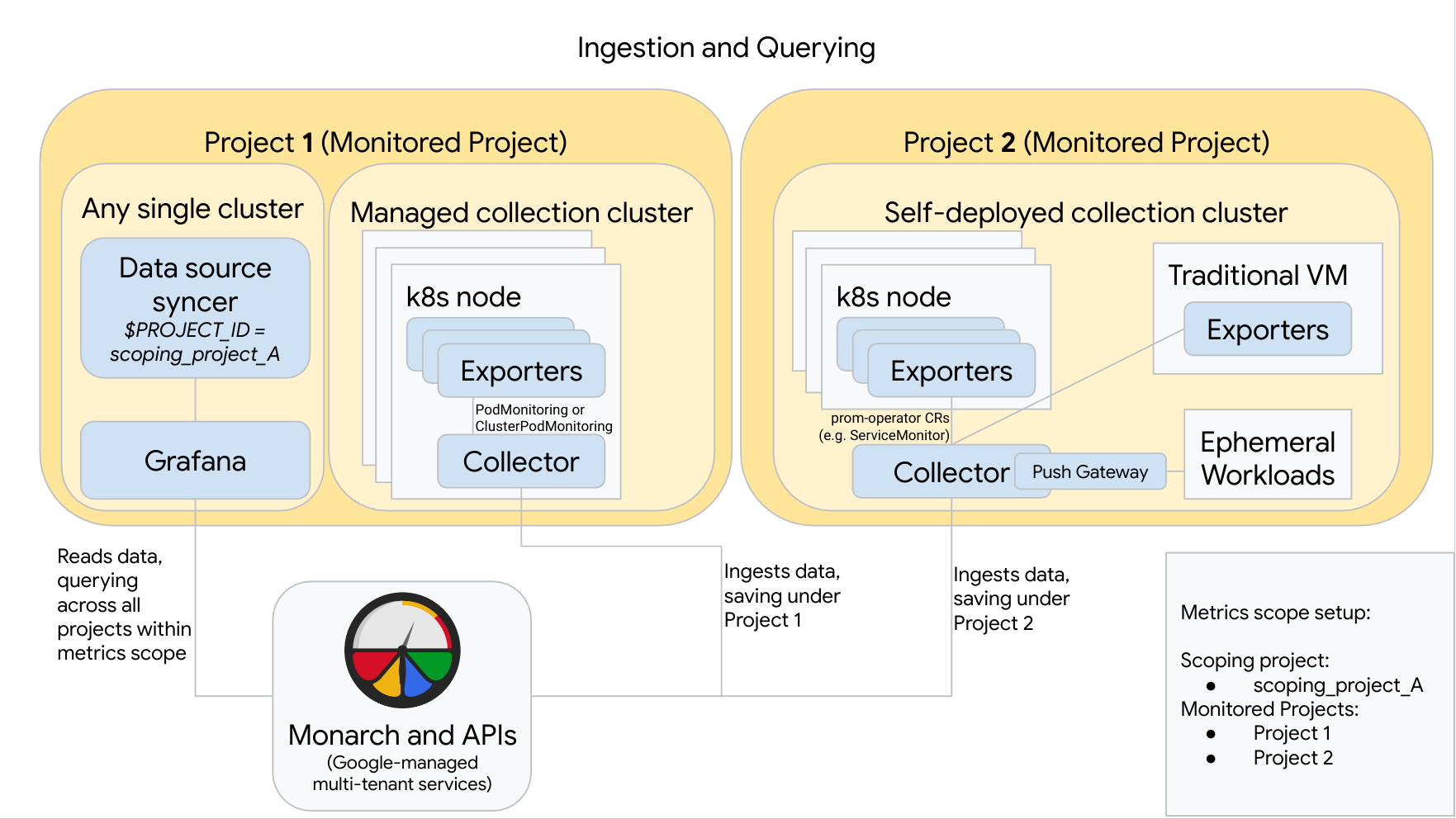
Para configurar y usar una configuración como la del diagrama, ten en cuenta lo siguiente:
Debes instalar cualquier exportador necesario en los clústeres. Google Cloud Managed Service para Prometheus no instala ningún exportador por ti.
El proyecto 1 tiene un clúster que ejecuta una recopilación administrada, que se ejecuta como un agente de nodo. Los recopiladores se configuran con recursos de PodMonitoring para recopilar destinos dentro de un espacio de nombres y con recursos de ClusterPodMonitoring para recopilar destinos en un clúster. Los PodsMonitoring deben aplicarse en cada espacio de nombres en el que quieras recopilar métricas. Los ClusterPodMonitoring se aplican una vez por clúster.
Todos los datos recopilados en el proyecto 1 se guardan en Monarch en el proyecto 1. Estos datos se almacenan de forma predeterminada en la región de Google Cloud desde la que se emiten.
El proyecto 2 tiene un clúster que ejecuta la recopilación autoimplementada con prometheus-operator y se ejecuta como un servicio independiente. Este clúster está configurado para usar ServiceMonitors o PodMonitors de prometheus-operator con el objetivo de recopilar los exportadores en Pods o VMs.
El proyecto 2 también aloja un sidecar de puerta de enlace de envío para recopilar métricas de cargas de trabajo efímeras.
Todos los datos recopilados en el proyecto 2 se guardan dentro de Monarch en el proyecto 2. Estos datos se almacenan de forma predeterminada en la región de Google Cloud desde la que se emiten.
El proyecto 1 también tiene un clúster que ejecuta Grafana y el sincronizador de fuentes de datos. En este ejemplo, estos componentes se alojan en un clúster independiente, pero se pueden alojar en cualquier clúster único.
El sincronizador de fuentes de datos está configurado para usar scoping_project_A, y su cuenta de servicio subyacente tiene los permisos de visualizador de Monitoring para scoping_project_A.
Cuando un usuario emite consultas desde Grafana, Monarch expande scoping_project_A a sus proyectos supervisados constituyentes y muestra resultados para los proyectos 1 y 2 en todas las regiones de Google Cloud . Todas las métricas conservan sus etiquetas originales
project_idylocation(región deGoogle Cloud ) para agrupación y filtrado.
Si el clúster no se ejecuta dentro de Google Cloud, debes configurar de forma manual
las etiquetas de project_id y location. Para obtener información sobre cómo configurar
estos valores, consulta Ejecuta Managed Service para Prometheus fuera de
Google Cloud.
No realices la federación cuando uses Managed Service para Prometheus. Para reducir la cardinalidad y los costos “agregando” datos antes de enviarlos a Monarch, usa la agregación local en su lugar. Para obtener más información, consulta Configura la agregación local.