Train, tune, and serve on an AI supercomputer
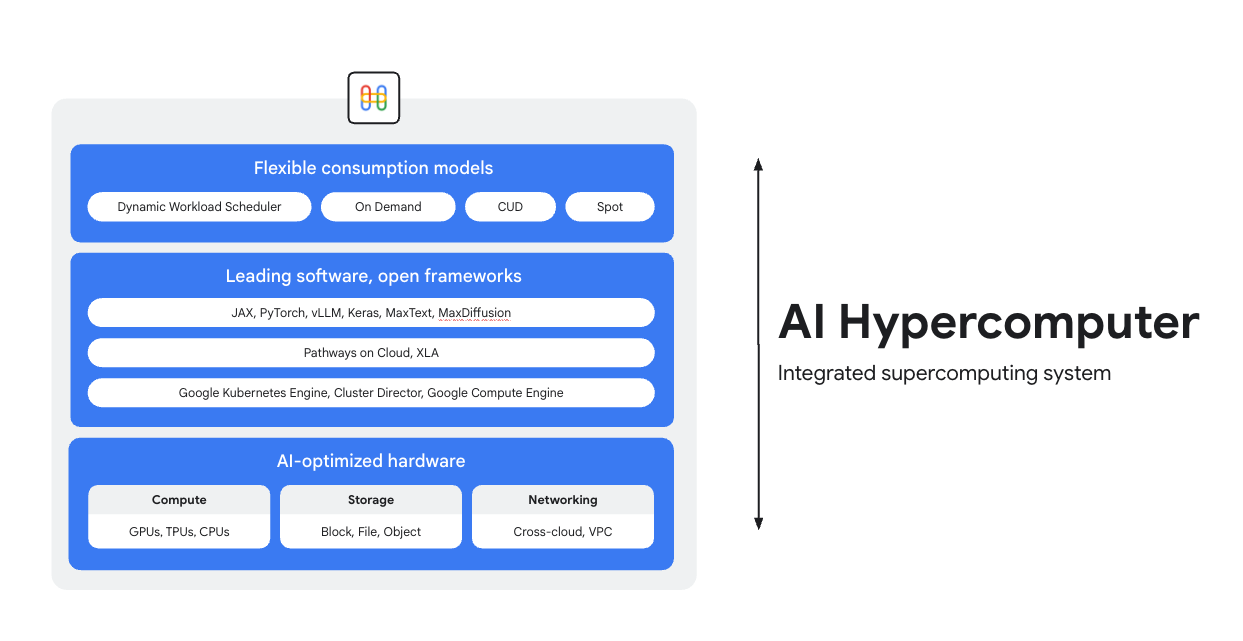
AI Hypercomputer is the integrated supercomputing system underneath every AI workload on Google Cloud. It is made up of hardware, software and consumption models designed to simplify AI deployment, improve system-level efficiency, and optimize costs.
Overview
AI-optimized hardware
Choose from compute (including AI accelerators), storage, and networking options optimized for granular, workload-level objectives, whether that's higher throughput, lower latency, faster time-to-results, or lower TCO. Learn more about: Cloud TPUs, Cloud GPUs, plus the latest in storage and networking.
Leading software, open frameworks
Get more from your hardware with industry-leading software, integrated with open frameworks, libraries, and compilers to make AI development, integration, and management more efficient.
- Support for PyTorch, JAX, Keras, vLLM, Megatron-LM, NeMo Megatron, MaxText, MaxDiffusion, and many more.
- Deep integration with the XLA compiler allows for interoperability between different accelerators, while Pathways on Cloud allows you to use the same distributed runtime that powers Google’s internal large-scale training and inference infrastructure.
- All of this is deployable in your environment of choice, whether that's Google Kubernetes Engine, Cluster Director or Google Compute Engine.
Flexible consumption models
Flexible consumption options allow customers to choose fixed costs with committed use discounts or dynamic on-demand models to meet your business needs. Dynamic Workload Scheduler and Spot VMs can help you get the capacity you need without over allocating. Plus, Google Cloud's cost optimization tools help automate resource utilization to reduce manual tasks for engineers.
Cost-effectively serve models at scale
Maximize price-performance and reliability for inference workloads
Inference is quickly becoming more diverse and complex, evolving in three main areas:
- First, how we interact with AI is changing. Conversations now have much longer and more diverse context.
- Second, sophisticated reasoning and multi-step inference are making Mixture-of-Experts (MoE) models more common. This is redefining how memory and compute scale from initial input to final output.
- Finally, it's clear that the real value isn't just about raw tokens per dollar, but the usefulness of the response. Does the model have the right expertise? Did it answer a critical business question correctly? That's why we believe customers need better measurements, focusing on the total cost of system operations, not the price of their processors.
Explore AI Inference resources
- What is AI inference? Our comprehensive guide to types, comparisons, and use cases
- Run best practice inference recipes with GKE Inference Quickstart
- Take a course on AI inference on Cloud Run
- Watch this video on the secret to cost-efficient AI inference
- Discover how to accelerate AI inference workloads
AI turns sports fans into kit designers
PUMA partnered with Google Cloud for its integrated AI infrastructure (AI Hypercomputer), allowing them to use Gemini for user prompts alongside Dynamic Workload Scheduler to dynamically scale inference on GPUs, dramatically reducing costs and generation time.
Impact:
- They slashed AI kit generation time from 2-5 minutes down to just 30 seconds. This transformed the platform into a fast, truly interactive experience that kept users engaged.
- In just 10 days, fans created 180,000 kits and cast 1.7 million ratings.
- The project proved a new way for PUMA to connect with its community. It moved beyond a simple brand-to-consumer relationship by successfully turning fans into active co-creators, providing the company with direct, real-time insight into the creative desires of its most passionate consumers.



How-tos
Maximize price-performance and reliability for inference workloads
Inference is quickly becoming more diverse and complex, evolving in three main areas:
- First, how we interact with AI is changing. Conversations now have much longer and more diverse context.
- Second, sophisticated reasoning and multi-step inference are making Mixture-of-Experts (MoE) models more common. This is redefining how memory and compute scale from initial input to final output.
- Finally, it's clear that the real value isn't just about raw tokens per dollar, but the usefulness of the response. Does the model have the right expertise? Did it answer a critical business question correctly? That's why we believe customers need better measurements, focusing on the total cost of system operations, not the price of their processors.
Additional resources
Explore AI Inference resources
- What is AI inference? Our comprehensive guide to types, comparisons, and use cases
- Run best practice inference recipes with GKE Inference Quickstart
- Take a course on AI inference on Cloud Run
- Watch this video on the secret to cost-efficient AI inference
- Discover how to accelerate AI inference workloads
Customer examples
AI turns sports fans into kit designers
PUMA partnered with Google Cloud for its integrated AI infrastructure (AI Hypercomputer), allowing them to use Gemini for user prompts alongside Dynamic Workload Scheduler to dynamically scale inference on GPUs, dramatically reducing costs and generation time.
Impact:
- They slashed AI kit generation time from 2-5 minutes down to just 30 seconds. This transformed the platform into a fast, truly interactive experience that kept users engaged.
- In just 10 days, fans created 180,000 kits and cast 1.7 million ratings.
- The project proved a new way for PUMA to connect with its community. It moved beyond a simple brand-to-consumer relationship by successfully turning fans into active co-creators, providing the company with direct, real-time insight into the creative desires of its most passionate consumers.
Run large-scale AI training and pre-training
Powerful, scalable, and efficient AI training
Training workloads need to run as highly synchronized jobs across thousands of nodes in tightly coupled clusters. A single degraded node can disrupt an entire job, delaying time-to-market. You need to:
- Ensure the cluster is set up quickly and tuned for the workload in question
- Predict failures and troubleshoot them quickly
- And continue with a workload, even when failures do happen
We want to make it extremely easy for customers to deploy and scale training workloads on Google Cloud.
Powerful, scalable, and efficient AI training
To create an AI cluster, get started with one of our tutorials:
- Create a Slurm cluster with GPUs (A4 VMs) and Cluster Toolkit
- Create a GKE cluster with Cluster Director for GKE or Cluster Toolkit
Moloco built an ad-serving platform to process billions of daily requests
Moloco relied on AI Hypercomputer's fully integrated stack to automatically scale on advanced hardware like TPUs and GPUs, which freed up Moloco engineers, while integration with Google's industry-leading data platform created a cohesive, end-to-end system for AI workloads.
After launching its first deep learning models, Moloco experienced hockey-stick growth and profitability, growing 5x in 2.5 years and achieved.
- 10x faster model training with Cloud TPUs on GKE, along with a 4x reduction in training costs
- Scaled to serve over 1,000 internal users, giving them access to a planet-scale machine learning system that helps them find profitable growth from their own data


AssemblyAI
AssemblyAI uses Google Cloud to train models quickly and at-scale

LG AI Research dramatically cut costs and accelerated development while adhering to strict data security and residency requirements

Anthropic announced plans to access up to 1 million TPUs to train and serve Claude models, worth tens of billions of dollars. But how are they running on Google Cloud? Watch this video to see how Anthropic is pushing the computing limits of AI at scale with GKE.
How-tos
Powerful, scalable, and efficient AI training
Training workloads need to run as highly synchronized jobs across thousands of nodes in tightly coupled clusters. A single degraded node can disrupt an entire job, delaying time-to-market. You need to:
- Ensure the cluster is set up quickly and tuned for the workload in question
- Predict failures and troubleshoot them quickly
- And continue with a workload, even when failures do happen
We want to make it extremely easy for customers to deploy and scale training workloads on Google Cloud.
Additional resources
Powerful, scalable, and efficient AI training
To create an AI cluster, get started with one of our tutorials:
- Create a Slurm cluster with GPUs (A4 VMs) and Cluster Toolkit
- Create a GKE cluster with Cluster Director for GKE or Cluster Toolkit
Customer examples
Moloco built an ad-serving platform to process billions of daily requests
Moloco relied on AI Hypercomputer's fully integrated stack to automatically scale on advanced hardware like TPUs and GPUs, which freed up Moloco engineers, while integration with Google's industry-leading data platform created a cohesive, end-to-end system for AI workloads.
After launching its first deep learning models, Moloco experienced hockey-stick growth and profitability, growing 5x in 2.5 years and achieved.
- 10x faster model training with Cloud TPUs on GKE, along with a 4x reduction in training costs
- Scaled to serve over 1,000 internal users, giving them access to a planet-scale machine learning system that helps them find profitable growth from their own data
AssemblyAI
AssemblyAI uses Google Cloud to train models quickly and at-scale
LG AI Research dramatically cut costs and accelerated development while adhering to strict data security and residency requirements
Anthropic announced plans to access up to 1 million TPUs to train and serve Claude models, worth tens of billions of dollars. But how are they running on Google Cloud? Watch this video to see how Anthropic is pushing the computing limits of AI at scale with GKE.
Deploy and orchestrate AI applications
Leverage leading AI orchestration software and open frameworks to deliver AI powered experiences
Google Cloud provides images that contain common operating systems, frameworks, libraries, and drivers. AI Hypercomputer optimizes these pre-configured images to support your AI workloads.
- AI and ML frameworks and libraries: Use Deep Learning Software Layer (DLSL) Docker images to run ML models such as NeMO and MaxText on a Google Kubernetes Engine (GKE) cluster
- Cluster deployment and AI orchestration: You can deploy your AI workloads on GKE clusters, Slurm clusters, or Compute Engine instances; for more information, see VM and cluster creation overview
Explore software resources
- Pathways on Cloud is a system designed to enable the creation of large-scale, multi-task, and sparsely activated machine learning systems
- Optimize your ML productivity by leveraging our Goodput recipes
- Schedule GKE workloads with Topology Aware Scheduling
- Try one of our benchmarking recipes for running DeepSeek, Mixtral, Llama, and GPT models on GPUs
- Choose a consumption option to get and use compute resources more efficiently
Priceline: Helping travelers curate unique experiences
"Working with Google Cloud to incorporate generative AI allows us to create a bespoke travel concierge within our chatbot. We want our customers to go beyond planning a trip and help them curate their unique travel experience." Martin Brodbeck, CTO, Priceline




How-tos
Leverage leading AI orchestration software and open frameworks to deliver AI powered experiences
Google Cloud provides images that contain common operating systems, frameworks, libraries, and drivers. AI Hypercomputer optimizes these pre-configured images to support your AI workloads.
- AI and ML frameworks and libraries: Use Deep Learning Software Layer (DLSL) Docker images to run ML models such as NeMO and MaxText on a Google Kubernetes Engine (GKE) cluster
- Cluster deployment and AI orchestration: You can deploy your AI workloads on GKE clusters, Slurm clusters, or Compute Engine instances; for more information, see VM and cluster creation overview
Additional resources
Explore software resources
- Pathways on Cloud is a system designed to enable the creation of large-scale, multi-task, and sparsely activated machine learning systems
- Optimize your ML productivity by leveraging our Goodput recipes
- Schedule GKE workloads with Topology Aware Scheduling
- Try one of our benchmarking recipes for running DeepSeek, Mixtral, Llama, and GPT models on GPUs
- Choose a consumption option to get and use compute resources more efficiently
Customer examples
Priceline: Helping travelers curate unique experiences
"Working with Google Cloud to incorporate generative AI allows us to create a bespoke travel concierge within our chatbot. We want our customers to go beyond planning a trip and help them curate their unique travel experience." Martin Brodbeck, CTO, Priceline
FAQ
How does AI Hypercomputer compare to just using individual cloud services?
While individual services offer specific capabilities, AI Hypercomputer provides an integrated system where hardware, software, and consumption models are designed to work optimally together. This integration delivers system-level efficiencies in performance, cost, and time-to-market that are harder to achieve by stitching together disparate services. It simplifies complexity and provides a holistic approach to AI infrastructure.
Can AI Hypercomputer be used in a hybrid or multicloud environment?
Yes, AI Hypercomputer is designed with flexibility in mind. Technologies like Cross-Cloud Interconnect provide high-bandwidth connectivity to on-premises data centers and other clouds, facilitating hybrid and multicloud AI strategies. We operate with open standards and integrate popular third-party software to enable you to build solutions that span multiple environments, and change services as you please.
How does AI Hypercomputer address security for AI workloads?
Security is a core aspect of AI Hypercomputer. It benefits from Google Cloud’s multi-layered security model. Specific features include Titan security microcontrollers (ensuring systems boot from a trusted state), RDMA Firewall (for zero-trust networking between TPUs/GPUs during training), and integration with solutions like Model Armor for AI safety. These are complemented by robust infrastructure security policies and principles like the Secure AI Framework.
What’s the easiest way to use AI Hypercomputer as infrastructure?
- If you don’t want to manage VMs, we recommend starting with Google Kubernetes Engine (GKE)
- If you need to use multiple schedulers, or can’t use GKE, we recommend using Cluster Director
- If you want complete control over your infrastructure, the only way to achieve that is by working directly with VMs, and for that Compute Engine is your best option
Is it only useful for large/high scale workloads?
No. AI Hypercomputer can be used for any sized workload. Smaller sized workloads still realize all the benefits of an integrated system, such as efficiency and simplified deployment. AI Hypercomputer also supports customers as their businesses scale, from small proof-of-concepts and experiments to large scale production deployments.
Is AI Hypercomputer the easiest way to get started with AI Workloads on Google Cloud?
For most customers, a managed AI platform like Vertex AI is the easiest way to get started with AI because it has all of the tools, templates, and models baked in. Plus, Vertex AI is powered by AI Hypercomputer under the hood in a way that is optimized on your behalf. Vertex AI is the easiest way to get started because it’s the simplest experience. If you prefer to configure and optimize every component of your infrastructure, you can access AI Hypercomputer’s components as infrastructure and assemble it in a way that meets your needs.
Since AI Hypercomputer is a composable system, there are lots of options - do you have best practices for each use case?
Yes, we are building a library of recipes in Github. You can also use the Cluster Toolkit for pre-built cluster blueprints.
What are the available options when I use AI Hypercomputer as IaaS?
AI-optimized hardware
Storage
- Training: Managed Lustre is ideal for demanding AI training with high throughput and PB-scale capacity. GCS Fuse (optionally with Anywhere Cache) suits larger capacity needs with more relaxed latency. Both integrate with GKE and Cluster Director.
- Inference: GCS Fuse with Anywhere Cache offers a simple solution. For higher performance, consider Hyperdisk ML. If using Managed Lustre for training in the same zone, it can also be used for inference.
Networking
- Training: Benefit from technologies like RDMA networking in VPCs, and high-bandwidth Cloud and Cross-Cloud Interconnect for rapid data transfer.
- Inference: Utilize solutions like the GKE Inference Gateway and enhanced Cloud Load Balancing for low-latency serving. Model Armor can be integrated for AI safety and security.
Compute: Access Google Cloud TPUs (Trillium), NVIDIA GPUs (Blackwell), and CPUs (Axion). This allows for optimization based on specific workload needs for throughput, latency, or TCO.
Leading software and open frameworks
- ML Frameworks and Libraries: PyTorch, JAX, TensorFlow, Keras, vLLM, JetStream, MaxText, LangChain, Hugging Face, NVIDIA (CUDA, NeMo, Triton), and many more open source and third party options.
- Compilers, Runtimes and Tools: XLA (for performance and interoperability), Pathways on Cloud, Multislice Training, Cluster Toolkit (for pre-built cluster blueprints), and many more open source and third party options.
- Orchestration: Google Kubernetes Engine (GKE), Cluster Director (for Slurm, non-managed Kubernetes, BYO schedulers), and Google Compute Engine (GCE).
Consumption models:
- On Demand: Pay-as-you-go.
- Committed Use Discounts (CUDs): Save significantly (up to 70%) for long-term commitments.
- Spot VMs: Ideal for fault-tolerant batch jobs, offering deep discounts (up to 91%).
- Dynamic Workload Scheduler (DWS): Save up to 50% for batch/fault tolerant jobs.











