Google Cloud で最新の統合分析データ プラットフォームを構築
Google Cloud 上に構築された最新の統合分析データ プラットフォームを作成するために必要な意思決定のポイントについて説明します。
著者: Firat Tekiner、Susan Pierce

概要
作成されるデータは尽きることがありません。 IDC の調査によると、2025 年までに世界中のデータは 175 ゼタバイトまで増加します1。日々生成されるデータの量は驚異的であり、企業がアクセシブルで使用しやすい方法でデータを収集、保存、整理することは実際、データ プロフェッショナルの 90% が信頼性の低いデータソースによって業務が滞ったと答えています。 データ アナリストの約 86% は古いデータに悩まされており、データワーカーの 60% 以上は毎月データのクリーニングと準備を行っている間、エンジニアリング リソースを待機しなければならず、影響を受けています2。
非効率的な組織構造とアーキテクチャの決定が、企業がデータを集計することと、それを実際に活用することの間にギャップを生む原因となっています。企業はデータ分析システムをモダナイズするためにクラウドへの移行を望んでいますが、それだけではサイロ化したデータソースや脆弱な処理パイプラインといった根本的な問題を解決することはできません。組織のデータ プラットフォームをより効果的なものにするには、データの所有権に関する戦略的意思決定とストレージ メカニズムに関する技術的な意思決定を、包括的な方法で行う必要があります。
この記事では、Google Cloud 上に構築された最新の統合分析データ プラットフォームを作成するために必要な意思決定のポイントについて説明します。
この 20 年間、ビッグデータは素晴らしいビジネス チャンスをもたらしました。しかし、組織にとって、関連性があり実用的でタイムリーなデータをビジネス ユーザーに提示することは複雑な課題です。調査によると、アナリストの 86% が今でも古いデータに悩まされており3、データから具体的な価値を生み出すにいたっている企業はわずか 32% しかありません4。第一の問題はデータの更新頻度です。 第二の問題は、異種のシステムや以前のシステムを複数のサイロから統合することの難しさに起因するものです。 組織はクラウドに移行しつつありますが、それだけでは、個々の事業部門のニーズに合わせて縦割りで構築された古いレガシー システムが抱えていた本当の問題は解決されません。
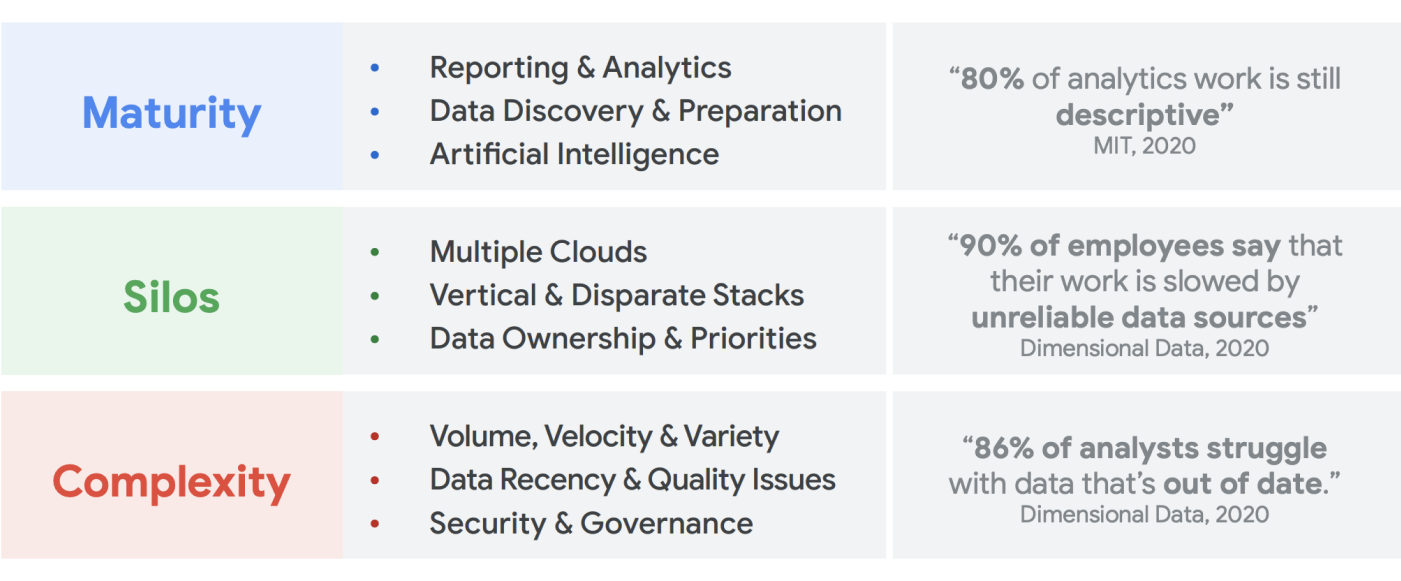
組織データのニーズを検討する際、往々にして過度な一般化をしてしまい、ただ一つの一貫性のあるデータソース、ただ一つのエンタープライズ データ ウェアハウス、ただ一つのセマンティクス、そしてただ一つのビジネス インテリジェンス用ツールからなる、単一で単純化された構造を考えがちです。非常に小規模で高度に一元化された組織であれば、この方法は有効かもしれませんし、IT とデータ エンジニアリングのチームが統合された単一のビジネス ユニットでも有効かもしれません。しかし、実際には、どの組織もそれほど単純ではなく、データの取り込み、処理、使用に関する想定外の複雑さが常に存在し、問題をさらに複雑にしています。
何百ものお客様とお話しする中で見えてきたのは、データと分析に対するより包括的なアプローチの必要性です。複数のビジネス ユニットとユーザー ペルソナのニーズを満たすことができ、データ処理から余分なステップをできるだけ排したプラットフォームが求められています。これは、単に新しいアーキテクチャやソフトウェア・コンポーネントのセットを購入するだけにとどまりません。企業は、全体的なデータ成熟度を把握し、技術的なアップグレードに加えて、システム的、組織的な変更を行う必要に迫られています。
2024 年の終わりまでに、企業の 75% は AI の試験運用から本格的な運用に移行し、ストリーミング データと分析インフラストラクチャは 5 倍増加することでしょう5。独立したデータ サイエンス チームとサイロ化された環境で AI を試験的に運用するのは簡単です。 しかし、これらの分析情報が本番環境システムに解放されることを阻む根本的な問題は、データのオーナーシップをセグメント化してしまう、組織やアーキテクチャにおける軋轢にあります。その結果、組織の事業運営に組み込まれる分析情報のほとんどは記述的なものであり、予測分析は研究チームの領域のものとして追いやられています。

データ ライフサイクル全体を念頭に置いたあらゆるユーザー向けのプラットフォーム
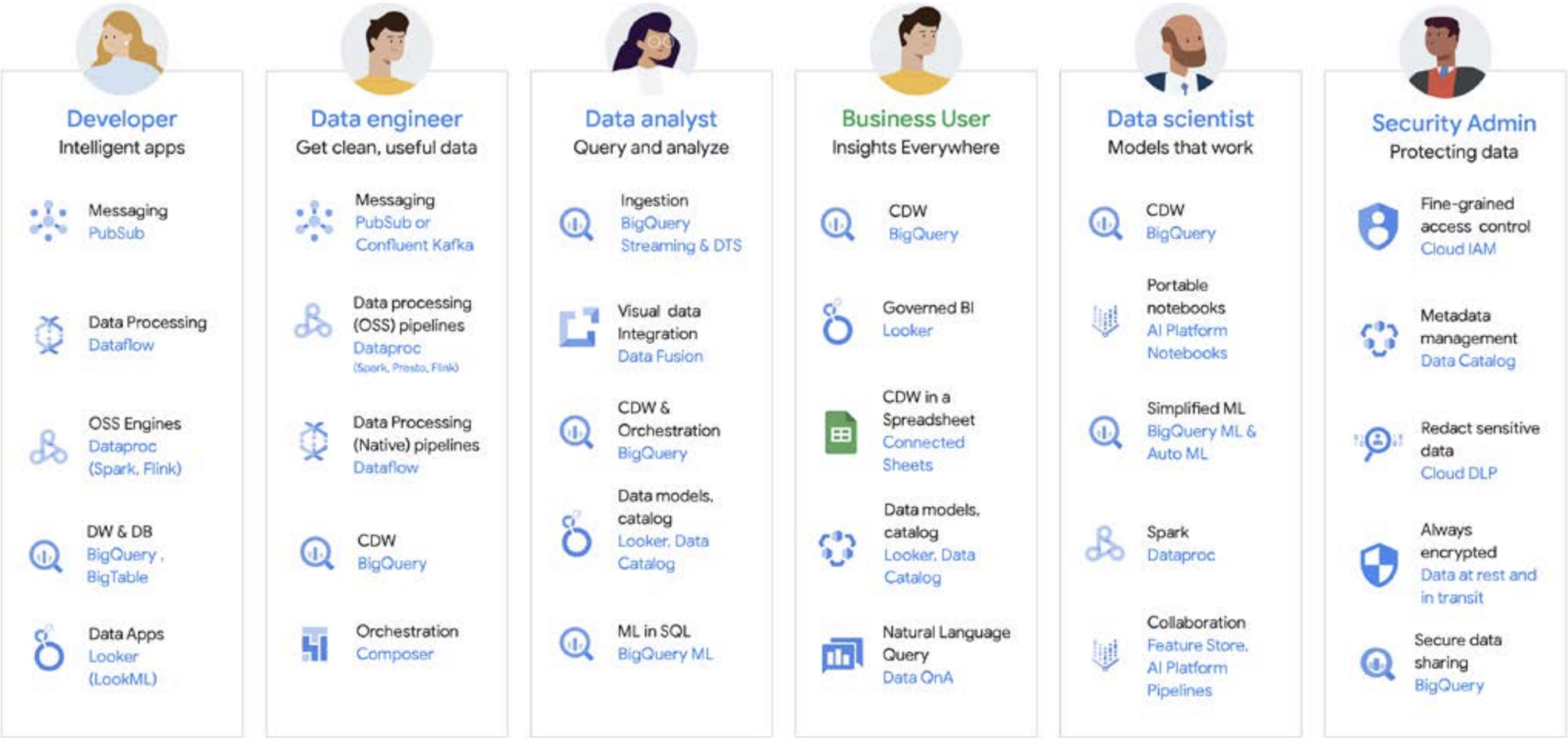
データ作業が一人で行われることはほとんどありません。組織内では多くのユーザーがデータに関わっており、データ ライフサイクルで重要な役割を担っています。それぞれが、データ ガバナンス、鮮度、検出可能性、メタデータ、処理のタイムライン、クエリ可能性などについて、異なる視点を持っています。ほとんどの場合、組織内のユーザー全員が異なるシステムとソフトウェアを使用しており、異なる処理ステージで同じデータを操作します。
例としてある企業における機械学習のライフサイクルを見ていきましょう。データ エンジニアは、データ サイエンス チームが利用できる最新のデータを適切なセキュリティとプライバシーの制約のもとで確保する責任を担います。データ サイエンティストは、データ エンジニアから提供される事前集計済みのデータソースの理想的なセットに基づいてトレーニング データセットとテスト データセットを作成し、モデルを構築してテストし、別のチームが分析情報を利用できるようにします。ML エンジニアは、他のデータ処理パイプラインを中断させない方法で、本番環境システムにデプロイするためのモデルのパッケージ化の責任を担います。 プロダクト マネージャーやビジネス アナリストは、Data QnA(BigQuery データでの分析用自然言語インターフェース)や可視化ソフトウェアを使用して、導き出された分析情報を確認したり、IDE やコマンドライン インターフェースを通じて結果セットに直接クエリを実行したりします。このようにユーザーは数え切れないほど存在し、ニーズもそれぞれ異なります。Google はそうしたユーザーすべてに対応するため、包括的なプラットフォームを構築しました。 Google Cloud は、ビジネスニーズに対応したツールで、お客様の現状に応えます。
ビッグデータに関する重要な決断: データ ウェアハウスとデータレイクのどちらを選択すべきか?
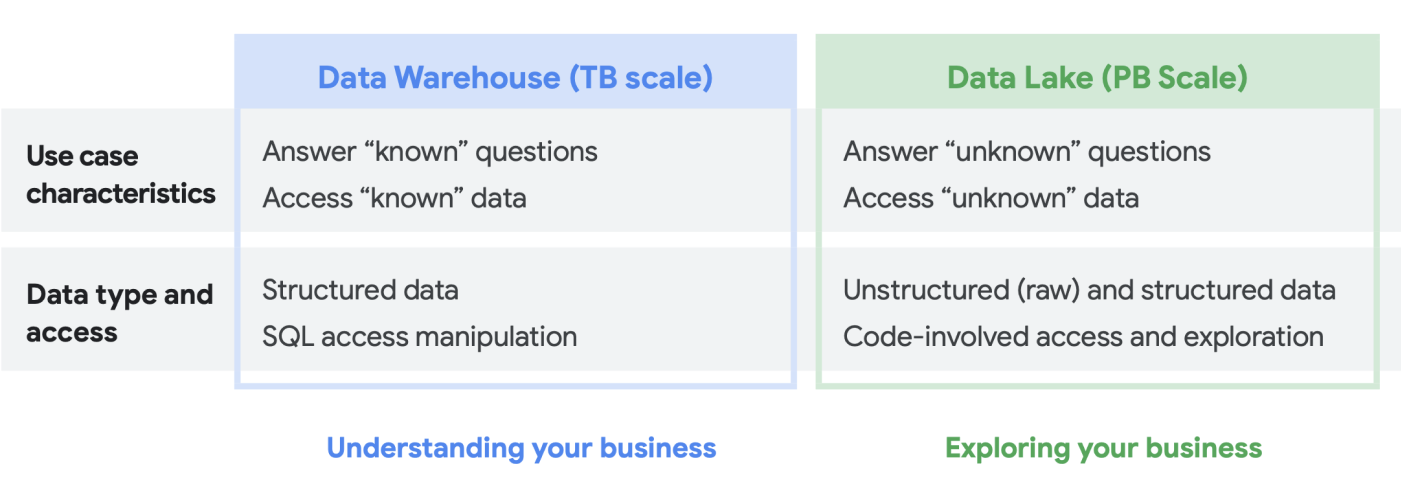
データ分析のニーズについてお客様と話すとき、「データレイクとデータ ウェアハウスはどちらが必要か?」という質問をよく耳にします。組織内のデータユーザーやニーズは多種多様であり、この質問の答えは、意図する用途、データの種類、人員によって異なるため、回答するのが難しい場合があります。
- どのデータセットの分析が必要かを認識していて、その構造を明確に理解できており、答えるべき疑問もわかっている場合、データ ウェアハウスが適している可能性が高くなります。
- 一方、複数のデータタイプにまたがった検索が容易であることが不可欠であり、実行する分析の種類が不明確で、あらかじめ設定された分析情報を提示するよりも探索する機会を求めており、この環境を効果的に管理および探索するためのリソースがある場合は、データレイクの方がニーズに合っている可能性が高いと言えます。
しかし、意思決定に必要なのはこれだけではありません。そこで、それぞれに関するいくつかの組織的な課題について説明します。データ ウェアハウスは多くの場合管理が難しくなります。 過去 40 年間うまく機能してきたレガシー システムは高額な費用がかかることがわかっているほか、データの更新頻度、スケーリング、高コストなど多くの課題を抱えていることが判明しています。 さらに、AI やリアルタイム機能は、後から追加しない限り、簡単に提供できません。 これらの問題は、オンプレミスの従来のデータ ウェアハウスだけに存在するわけではなく、新しく作成されたクラウドベースのデータ ウェアハウスでも見られます。多くは、謳い文句とは裏腹に、統合された AI 機能を搭載していません。 これらの新しいデータ ウェアハウスは、本質的にレガシー環境をクラウドに移植したものにすぎません。データ ウェアハウスのユーザーはアナリストである傾向が高く、多くの場合、特定のビジネス ユニットに組み込まれています。 これらのユーザーはビジネスへの理解を深めるために有用な追加のデータセットについてアイデアがあるかもしれません。 分析、データ処理、ビジネス インテリジェンス機能の要件における改善のアイデアもあるかもしれません。
しかし、従来の組織では、これらのユーザーがデータのオーナーに直接アクセスできないことが多く、データセットやツールを決定する技術的な意思決定者に影響を与えるのも容易ではありません。また、元データから切り離されているため、仮説をテストしたり、基盤となるデータの深い理解を促進したりすることができません。 データレイクにも独自の課題があります。 理論上は低費用で簡単にスケーリングできますが、多くのお客様がオンプレミスのデータレイクで異なる現実を目の当たりにしています。十分なストレージを計画し、プロビジョニングすることは、特にデータの生成量が大きく変動する組織では、費用がかかり、困難を伴う場合があります。オンプレミスのデータレイクは柔軟性に欠け、既存システムのメンテナンスにも時間がかかります。新機能の開発に時間を割くべきエンジニアが、データクラスタの維持管理に追われるケースは珍しくありません。率直に言えば、新しい価値を創造するのではなく、価値を維持しているのです。 全体として、多くの企業で総所有コストが予想以上に高くなっています。 それだけでなく、システムをまたぐガバナンスの問題も簡単には解決できていません。部署ごとに異なるセキュリティ モデルを使用している場合はなおさらです。 その結果、データレイクはサイロ化およびセグメント化され、チーム間でデータやモデルを共有することが難しくなります。
データレイクのユーザーは通常、元データソース重視であり、データを分析するツールと能力を有しています。 従来の組織では、このようなユーザーはデータそのものに焦点を当て、ビジネスの他の部分から距離を置かれていることが多い傾向にありました。 こうした断絶は、ビジネス ユニットが、収益向上、費用削減、リスク低減、新たなビジネス機会といったビジネスの目標を推進するための分析情報を得る機会を逸してしまうことを意味します。 このようなトレードオフを考慮したうえで、多くの企業はデータレイクを設定して一部のデータをデータ ウェアハウスに移行するか、データ ウェアハウスに追加のテストと分析用の副次的なデータレイクを持つハイブリッド アプローチを採用することになります。 しかし、複数のチームが個々のニーズに合わせて独自のデータ アーキテクチャを作成しているため、データの共有と忠実度は主幹 IT チームにとってさらに複雑な課題となっています。あるチームは未来のビジネスを探索し、別のチームはビジネスの現状を理解するというように、別々のチームが別々の目標を持つのではなく、これらの機能とデータシステムを統合することで、ビジネスをより深く理解することが探索を推進し、探索がビジネスをより深く理解することにつながるという好循環を生み出すことができるのです。
データ ウェアハウスをデータレイクのように扱う
Google Cloud では、データ ウェアハウスとデータレイクを別々に構築できますが、どちらか一つを選ぶ必要はありません。多くの場合、お客様が使用する基本的なプロダクトは両方とも同じで、データレイクとデータ ウェアハウスの実装の違いは、採用するデータアクセス ポリシーのみです。実際、この 2 つは、より統一された機能セットである最新の分析データ プラットフォームへと収束し始めています。 Google Cloud でこれがどのように機能するのかを見てみましょう。
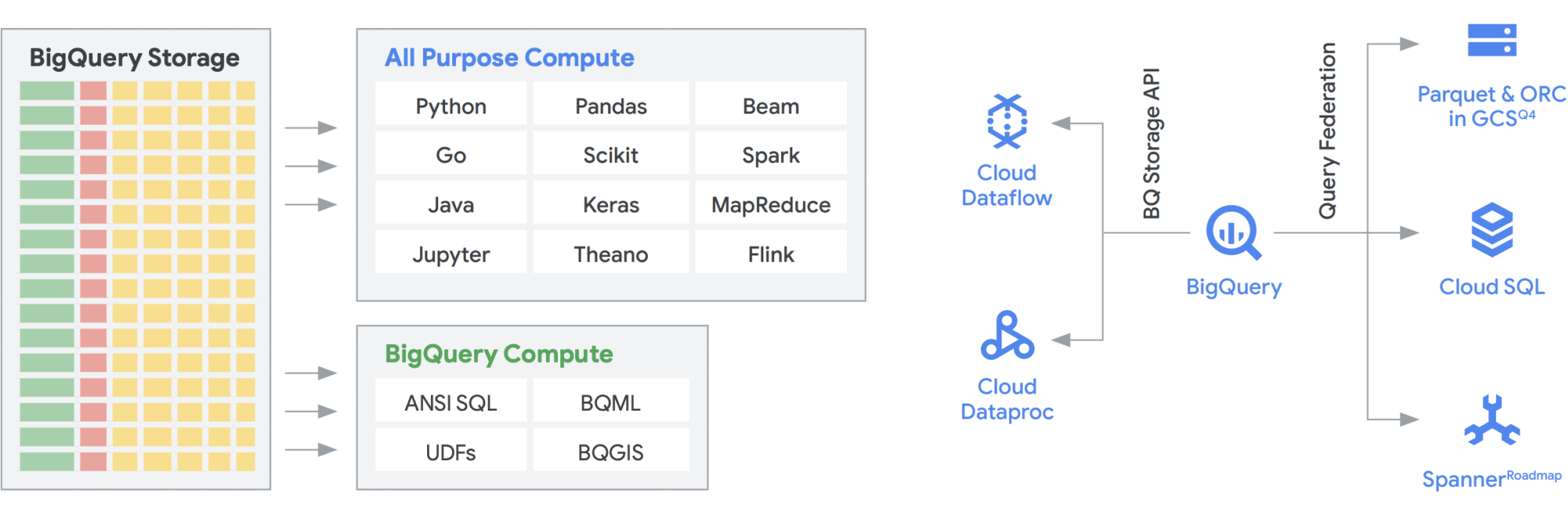
BigQuery Storage API は、Dataflow や Managed Service for Apache Spark など、他の多くのシステムで Cloud Storage のように BigQuery ストレージを使用することができる機能を提供します。これにより、データ ウェアハウスのストレージの壁を取り払い、BigQuery 上で高性能なデータフレームを実行することが可能になります。つまり、BigQuery Storage API を使用すると、BigQuery データ ウェアハウスをデータレイクのように運用できるのです。 では、実際にどのような使い方があるのでしょうか? まず、MapReduce、Hive、Spark などの一連のコネクタを構築しました。これにより、Hadoop や Spark のワークロードを BigQuery 内のデータに対して直接実行できるようになります。データ ウェアハウスとは別個のデータレイクが必要なくなります。 Dataflow は、バッチ処理やストリーム処理において非常に効果的です。 現在では、BigQuery データ上で Dataflow ジョブを実行し、PubSub や Spanner などのデータソースからデータを拡充できます。
BigQuery は、ストレージとコンピューティングの両方を独立してスケーリングでき、サーバーレスであるため、さまざまなチーム、ツール、アクセス パターンによる使用量に関係なく、需要に合わせて無制限にスケーリングできます。上述の用途はすべて、BigQuery に同時にアクセスするほかのジョブのパフォーマンスに影響を及ぼすことなく実行できます。また、BigQuery Storage API はペタビット レベルのネットワークを提供し、ノード間でデータを移動させながら効率的にクエリ リクエストを満たすため、インメモリ オペレーションと同様の性能を発揮します。また、NoSQL や OLTP データベースだけでなく、Parquet や ORC などの一般的な Hadoop データ形式と直接連携することも可能です。BigQuery に組み込まれた Dataflow SQL が提供する機能を使えば、さらに一歩踏み込むことができます。 ストリームを BigQuery テーブルやファイル内のデータを結合して効果的にラムダ アーキテクチャを構築し、大量のバッチデータやストリーミング データを取り込めるようになると同時に、クエリに応答するサービスレイヤを提供できます。 さらに BigQuery BI Engine とマテリアライズド ビューにより、この多目的のアーキテクチャの効率とパフォーマンスをさらに簡単に向上できます。
BigQuery を活用した Google のスマート アナリティクス プラットフォーム
サーバーレスのデータ ソリューションは、組織がデータサイロを越えて分析と対応の領域に移行するためには必要不可欠です。 Google Cloud のコアとなるデータ分析サービスはすべてサーバーレスであり、緊密に統合されています。

チェンジ マネジメントは、多くの場合、新しいテクノロジーを組織に取り入れるうえで最も困難を伴う分野の一つです。 Google Cloud は、開発者とビジネス ユーザーの両方に使い慣れたツール、プラットフォーム、統合を提供することで、お客様が置かれている状況に対応することに努めています。Google Cloud のミッションは、データに基づいたイノベーションを通じて、組織がビジネスをデジタル変革して再定義できる可能性を共に高めることです。Google Cloud は、ベンダー ロックインを作り出すのではなく、オンプレミス環境や他のクラウド サービスのプロダクト、さらにはエッジをも取り込むことができる、シンプルで合理化されたインテグレーションを組織に提供し、真のハイブリッドなクラウドを形成します。
- BigQuery Omni は、データを環境間で移行する手間を省き、環境に関係なくデータが存在する場所で分析を行うことを可能にします。
- Dataflow を活用する SDK である Apache Beam は、Apache Spark や Apache Flink のようなランナーへの移行性とポータビリティを提供します。
- Apache Spark や Apache Hadoop の運用を検討している組織向けには、Google Cloud はManaged Service for Apache Spark を提供しています。
ほとんどのデータユーザーの関心事は、どのようなデータがあるかであり、データが存在するシステムではありません。必要なときに必要なデータにアクセスできることが最も重要です。 したがって、使用目的がデータセットの探索、データストアのソース管理、アドホック クエリの実行、エグゼクティブ関係者向けの社内ビジネス インテリジェンス ツールの開発であっても、ユーザーにとっては、使い慣れたツールで更新頻度が高く有用なデータにアクセスできるのであれば、プラットフォームの種類はほとんど問題ではありません。
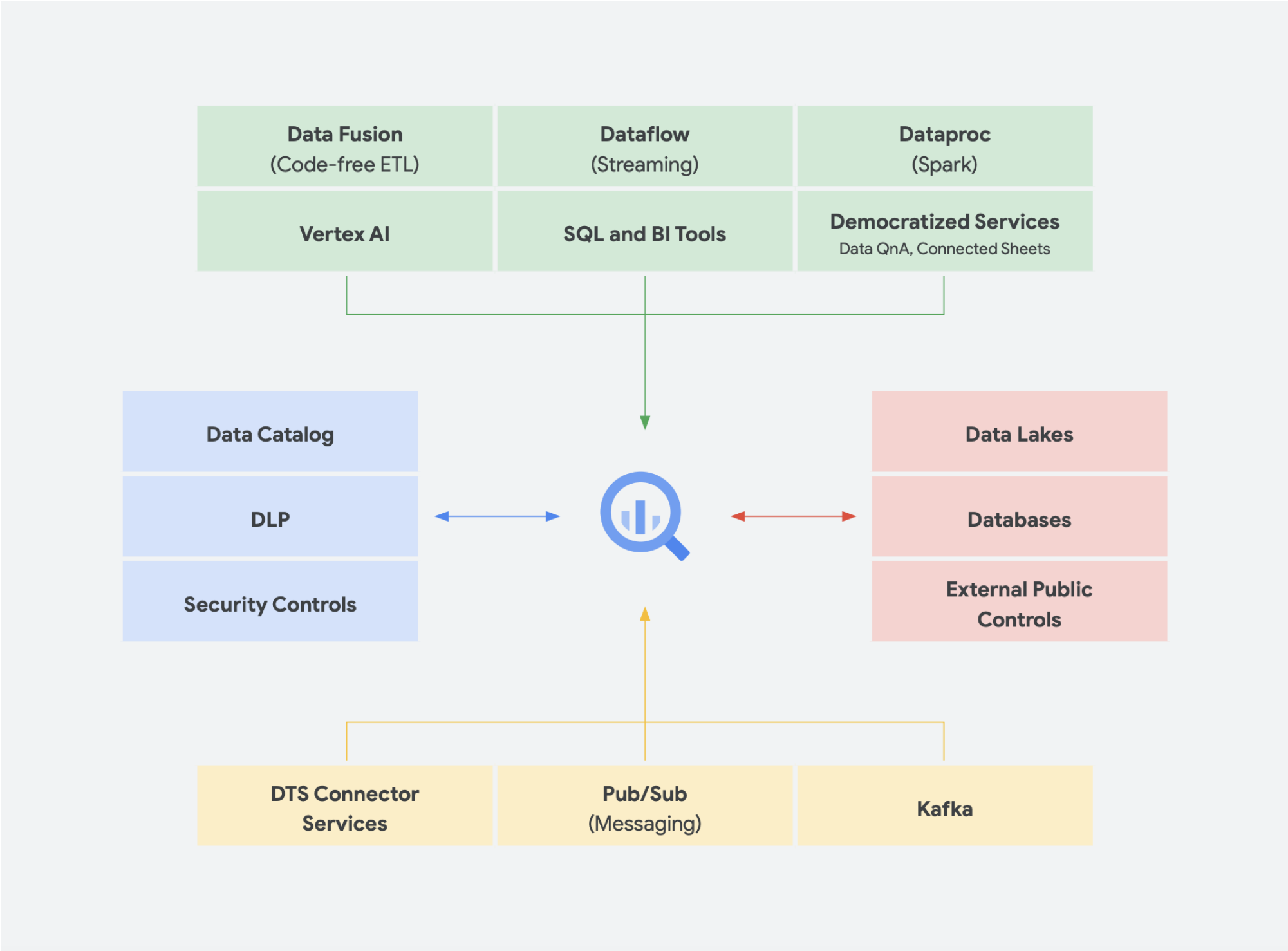
新たな傾向
このデータレイクとデータ ウェアハウスの統合分析データ プラットフォームへの集約化という考え方の延長線上に、いくつかの注目されているデータ ソリューションがあります。 たとえば、レイクハウスやデータメッシュに関する多くのコンセプトが出現しています。これらの用語のいくつかを耳にしたことがある方もいらっしゃると思います。 中には、さまざまな形やフォーマットで何年も存在していたものもありますが、 いずれも Google Cloud 環境内で円滑に機能しています。 Google Cloud におけるデータメッシュとレイクハウスがどのようなものか、またそれらが組織内のデータ共有においてどのような意義を持つのかを詳しく見ていきましょう。データメッシュとレイクハウスは、相互に排他的ではなく、組織内の異なる課題の解決を支援します。しかし、一方はデータの有効化を優先し、他方はチームの作業を優先します。 データメッシュは、1 つのチームによってボトルネックになることを避けるため、データスタック全体を有効化します。データへのアクセスを連携アプローチで提供するアーキテクチャにより、サイロをより小さな組織部門単位に分割します。 レイクハウスはデータ ウェアハウスとデータレイクを組み合わせたもので、異なる種類のデータやより大量のデータを処理できます。 これにより、エンタープライズ データ ウェアハウスのパフォーマンスのギャップの一部を解消すると考えられていたデータレイク機能であるスキーマオンライト モデルではなく、スキーマオンリードが可能になります。 さらなるメリットとして、このアーキテクチャでは、データレイクに通常欠けている、より厳密なデータ ガバナンスを取り入れることもできます。

Lakehouse
前述のように、BigQuery の Storage API を使用すると、データ ウェアハウスをデータレイクのように扱うことができます。Managed Service for Apache Spark などの Hadoop 環境で実行される Spark ジョブでは、データ ウェアハウスからストレージを取り出すことで、別のストレージ メディアを必要とせず、BigQuery に保存されているデータを使用できます。BigQuery のストレージから切り離された圧倒的なコンピューティング能力により SQL ベースの変換が可能になり、これらの変換の異なるレイヤ間でビューを利用できます。 これはその後 ELT 型のアプローチにつながり、よりアジャイルなデータ処理プラットフォームを可能にします。 ETL ではなく ELT を活用することで、BigQuery は SQL ベースの変換を論理ビューとして格納することを可能にします。 従来のデータ ウェアハウスでは、元データをすべてデータ ウェアハウスのストレージにダンプすると費用がかかる場合がありますが、BigQuery ストレージには割増料金が発生することはありません。 その費用は、Google Cloud Storage の blob ストレージとほぼ同等です。
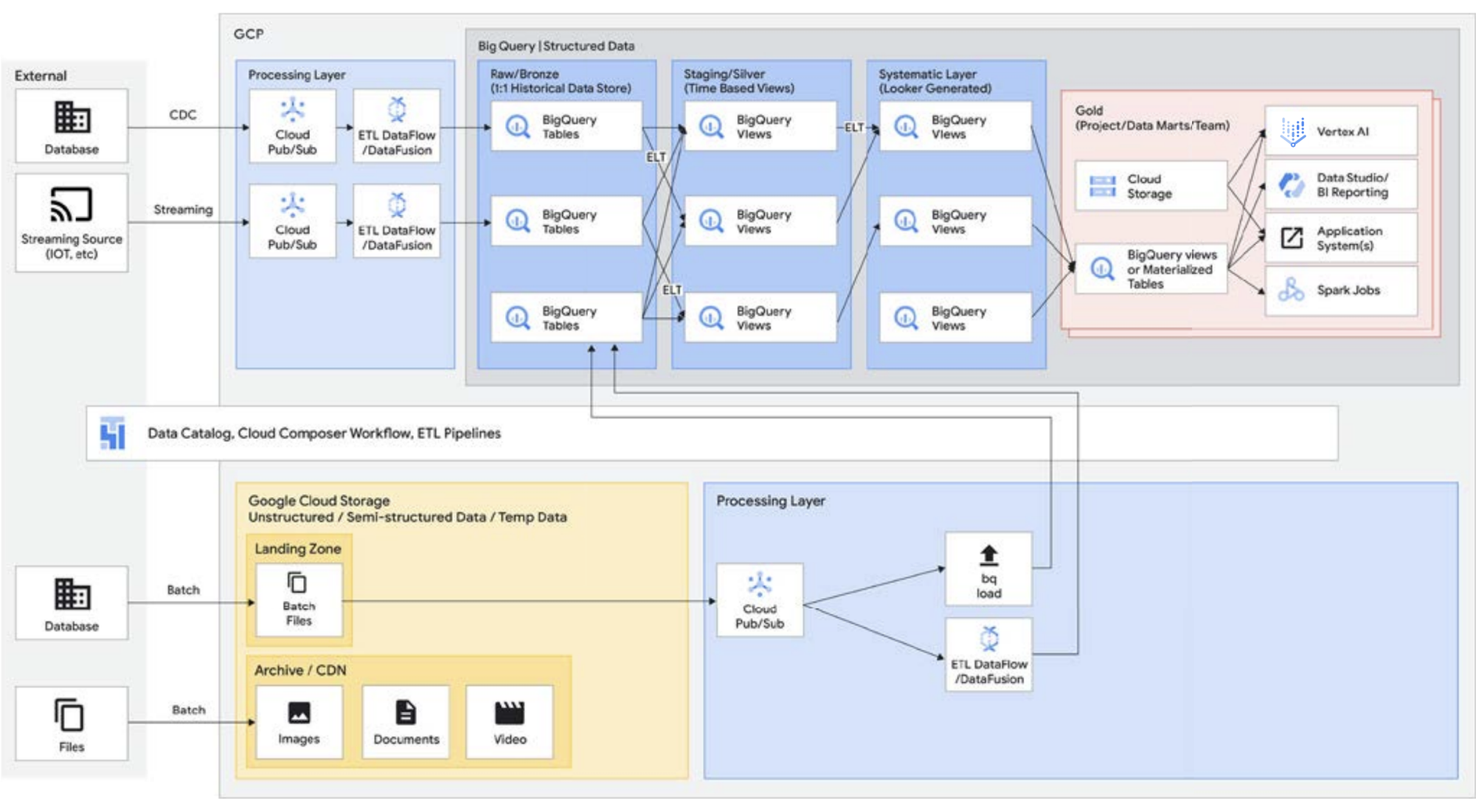
ETL を実行する場合、変換は BigQuery の外部で行われるばかりか、スケーリングできないツールで行われる可能性もあります。 クエリの並列化ではなく、データを 1 行ずつ変換することになるかもしれません。Spark やその他の ETL プロセスはすでにコード化されており、新しいテクノロジーのために変更することは意味がない場合もあるでしょう。 しかし、SQL で記述できる変換がある場合、BigQuery はその変換場所として最適です。
さらに、このアーキテクチャは、Managed Service for Apache Airflow、Data Catalog、Data Fusion などのすべての Google Cloud コンポーネントでサポートされています。さまざまなユーザー ペルソナにエンドツーエンドのレイヤを提供します。 運用上のオーバーヘッドを削減するもう一つの重要な側面は、基盤となるインフラストラクチャの機能を活用することで実現できます。 Dataflow や BigQuery を検討してください。すべてコンテナ上で動作し、稼働時間や仕組みをバックグラウンドで管理します。 これがサードパーティやパートナーのツールにも拡張され、Kubernetes のような同様の機能を利用し始めると、管理がよりシンプルでポータブルになります。そして、これによりリソースや運用上のオーバーヘッドを削減できます。 さらに、Managed Service for Apache Airflow を使用したモニタリング ダッシュボードを利用することで、オブザーバビリティを高め、効果的な運用がもたらされます。Cloud Storage と BigQuery に保存されたデータをまとめることで、データの移動や複製なしでデータレイクを構築できるだけでなく、データソースを管理するための追加の管理機能も提供されます。Knowledge Catalog(旧称 Dataplex)は、Cloud Storage と BigQuery のデータを調整する一元化された管理レイヤを提供することでレイクハウスを可能にします。そうすることで、ビジネスのニーズに応じてデータを整理でき、データの保存方法や保存場所に制約されることがなくなります。
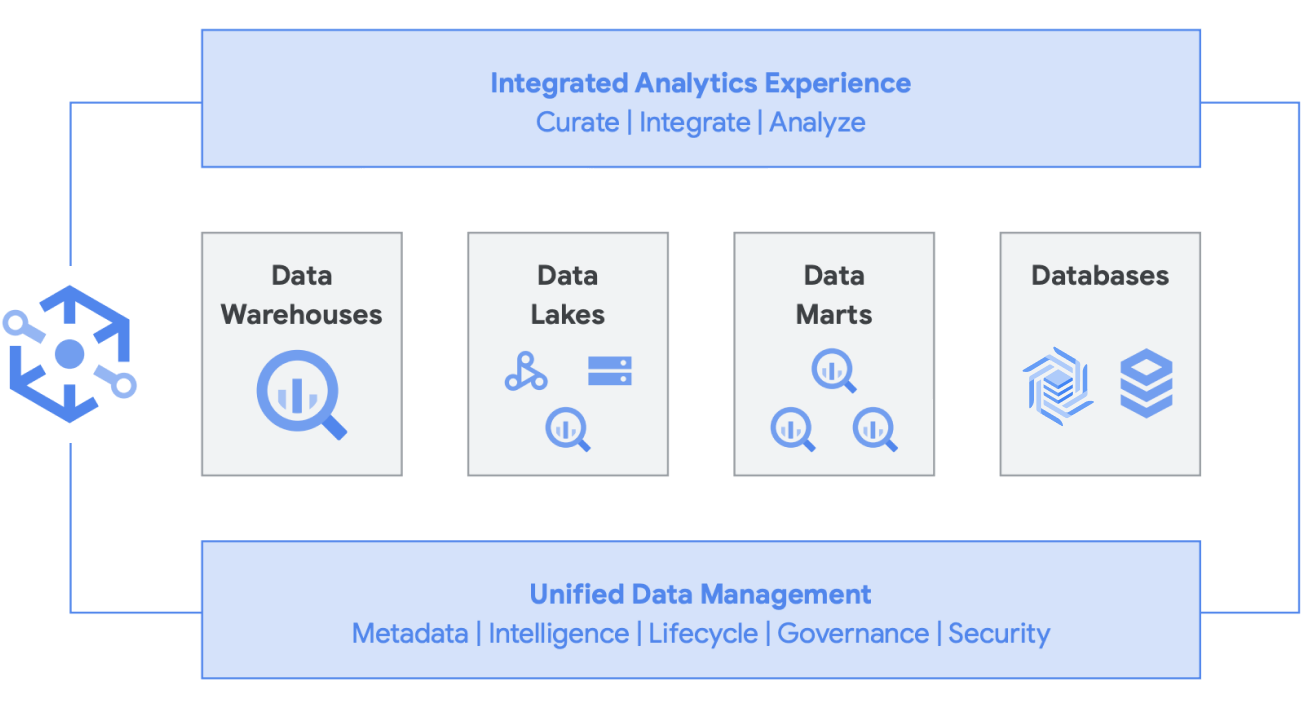
Knowledge Catalog は、適切な価格性能比でデータを分散させるとともに、このデータをすべての分析ツールから安全にアクセスできるようにする、インテリジェント データ ファブリックです。データ品質とガバナンスが組み込まれたメタデータ主導のデータ マネジメントが提供されるため、インフラストラクチャの境界や非効率性に対処する時間を減らすとともに、今あるデータを信頼し、そのデータから価値を引き出すことに時間を費やすことができるようになります。さらに、Google Cloud とオープンソースの長所を組み合わせることで、データを大規模に迅速にキュレート、保護、統合、分析できるようになり、統合された分析エクスペリエンスが提供されます。最終的には、既存のアーキテクチャを増強し、財務ガバナンスの目標を達成するための分析戦略を構築できます。
データメッシュ
データメッシュは、比類ないスケーラビリティによるパフォーマンスの支払いモデル、API、DevOps、Google Cloud プロダクトの密接なインテグレーションと組み合わされた、データ ウェアハウスやデータレイクにおける長いイノベーションの歴史を基盤として構築されています。この方法により、オンデマンド データ ソリューションを効果的に構築できます。データメッシュはデータのオーナーシップをドメインのデータオーナーに分散させ、各データオーナーは、標準的な方法でデータをプロダクトとして提供する責任を負います。また、データメッシュは、部署間のコミュニケーションを促進し、データセットを異なる場所に分散させることを可能にします。データメッシュでは、データから価値を生成する責任は、データを最もよく理解する人に結びつけられます。言い換えれば、データを作成した人やデータを組織に持ち込んだ人は、自身が作成したデータからプロダクトとして消費可能なデータアセットを作成する責任も負う必要があります。多くの組織では、新しく作成されたデータに対する明確なオーナーシップの責任を持たずに、組織のあちこちでデータの抽出と変換を繰り返すため、「信頼できる唯一の情報源」または「信頼できるデータソース」を確立することは困難です。データメッシュにおいて信頼できるデータソースはソースドメインが公開するデータ プロダクトであり、そのデータに責任を持つデータ オーナーと管理担当者が明確に割り当てられています。
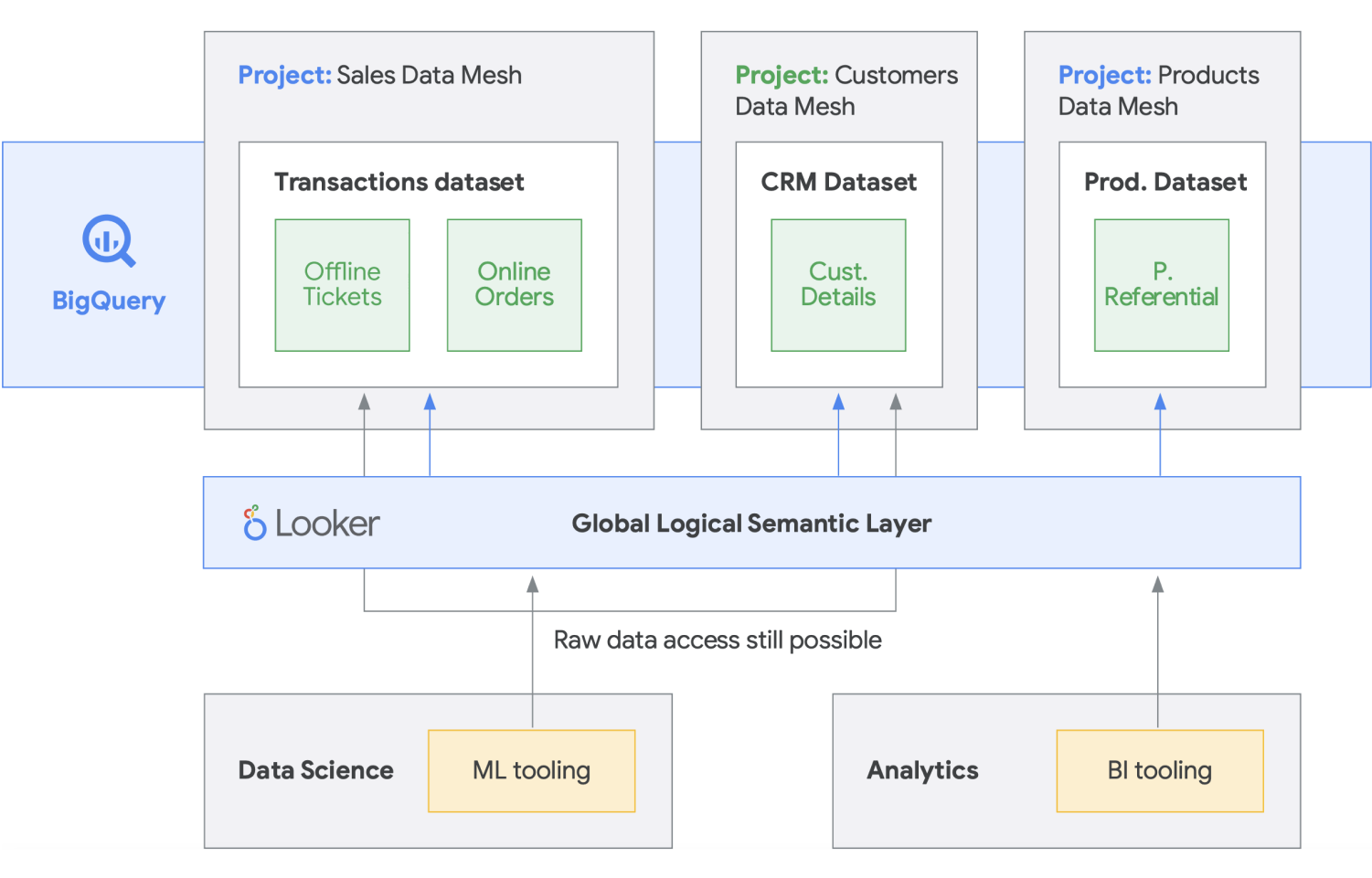
要約すると、データメッシュはドメイン指向で分散型のデータ オーナーシップとアーキテクチャを保証します。これは、Google Cloud で提供しているのと同じように、連携したコンピューティングとアクセスのレイヤを持つことで可能になります。さらに、より充実した機能を求める組織の場合、データのモデリングとアクセスのための統一レイヤを提供できる Looker のようなものを利用することも可能です。 Looker のプラットフォームでは、1 つの画面の UI で企業のデータとビジネス定義の信頼性の高い、最新のバージョンにアクセスすることができます。ビジネスの統合ビューにより、データ エクスペリエンスを選択または設計し、ニーズに最も適した方法でユーザーとシステムにデータが確実に配信されるようにすることができます。 データ サイエンティスト、アナリスト、そしてビジネス ユーザーまでもが、単一のセマンティック モデルでデータにアクセスできるため、まさにぴったりです。データ サイエンティストは引き続き元データにアクセスしますが、データの移動と複製はありません。
Google Cloud は、BigQuery などの主軸プロダクトに加え、データセットの作成と管理を容易にするための追加機能を構築しています。 Analytics Hub には、限定公開データ エクスチェンジを作成する機能があり、エクスチェンジの管理者(データ キュレーター)は、エクスチェンジ内のデータを社内およびビジネス パートナーやバイヤーなど社外の特定の個人やグループに公開し、登録する権限を与えます。
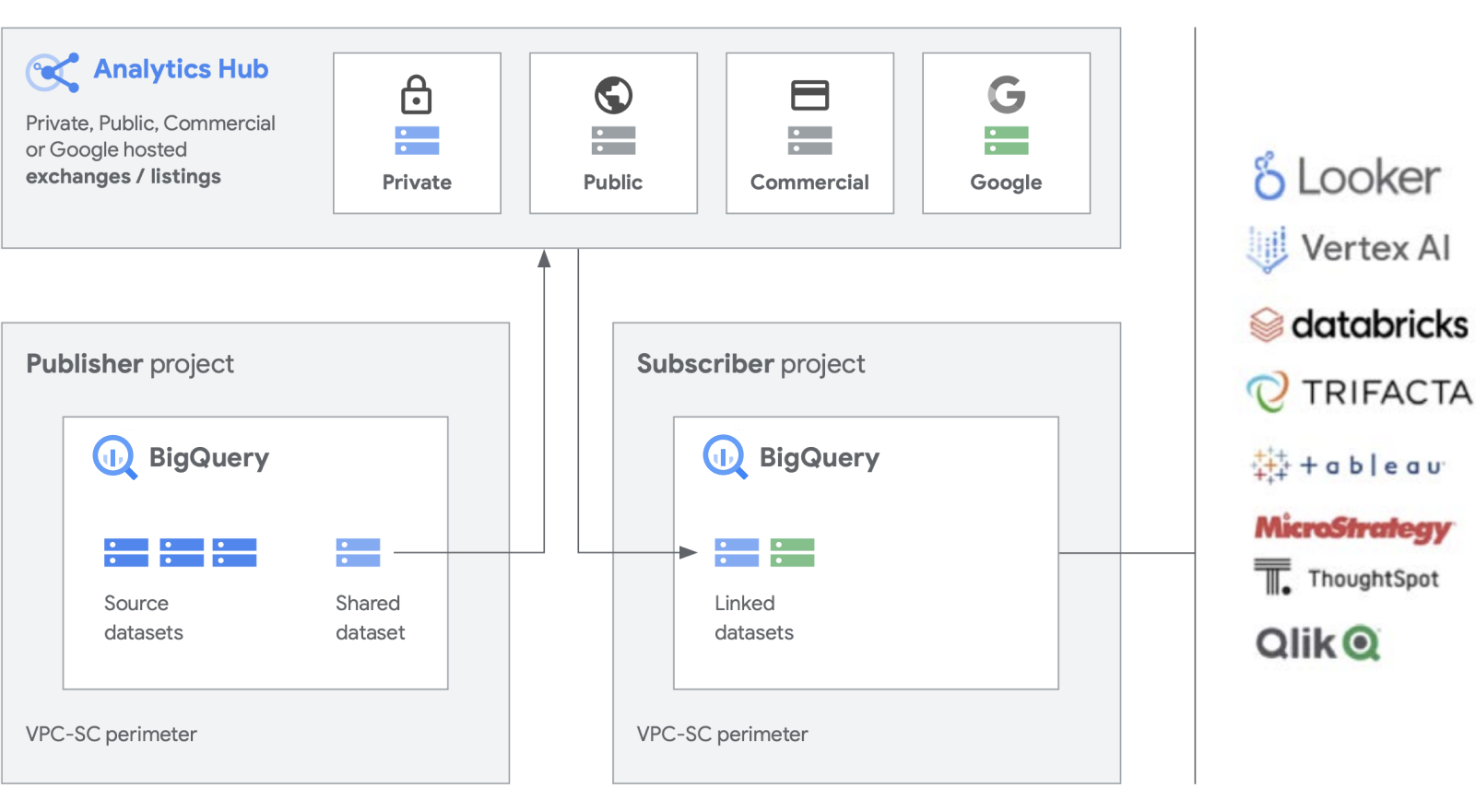
BigQuery のスケーラビリティを活用し、オープンソース形式を含む共有アセットの公開、検出、登録を行うことが可能。パブリッシャーは集計された使用状況の指標を確認することが可能です。 データ プロバイダは、データ、分析情報、ML モデル、ビジュアリゼーションなどを使用して BigQuery を利用する企業のお客様にリーチし、Cloud Marketplace を活用して自社のアプリ、分析情報、モデルを収益化できます。これは、BigQuery の一般公開データセットが、Google が管理するエクスチェンジを通じて管理されている方法とも似ています。 Google 独自のデータセットや商用 / 業界用のデータセット、一般公開データセット、組織やパートナー エコシステムから提供されるキュレートされたデータの交換を利用して、イノベーションを推進。
レガシーに対処する
新しいデータ プラットフォームをゼロから構築することは大変有意義なことですが、すべての企業がそのようなことができる立場にあるわけではありません。 ほとんどの組織は既存のレガシー システムを扱っており、それらを置き換えられるようになるまで移行、移植、またはパッチ適用が必要です。Google は、データ プラットフォームの作業のあらゆるステージでお客様と協力してきており、お客様の状況に応じたソリューションをご用意しています。
お客様の間で見られる移行には、通常、リフト&リプラットフォーム、リフト&リホーム、完全モダナイゼーションという 3 つのカテゴリがあります。ほとんどの企業では、リフト&リプラットフォームから始めることをおすすめします。可能な限り混乱やリスクを排除したインパクトのある移行を行えるからです。この戦略では、レガシーのデータ ウェアハウスと Hadoop クラスタから BigQuery または Managed Service for Apache Spark にデータを移行します。データが移行されると、データ パイプラインとクエリを最適化してパフォーマンスを改善できます。 リフト&リプラットフォームによる移行戦略は、ワークロードの複雑さに応じて、段階的に行うことができます。IT が一元管理され、複数のビジネス ユニットが存在する大企業のお客様には、その複雑さを考慮して、この方法をおすすめします。
移行戦略として 2 番目によく目にするのが、最初のステップとして完全なモダナイゼーションを行うことです。 クラウドネイティブなアプローチで本格的に取り組むため、これまでとは明確に一線を画すことができます。Google Cloud 上でネイティブに構築することになりますが、すべてを一度に変更するため、複数の大規模なレガシー環境がある場合は移行に時間がかかることがあります。

レガシー システムを明確に断ち切るには、ジョブを書き換えたり、さまざまなアプリケーションを変更したりする必要があります。 しかし、これにより、他の方法と比較して、より高いベロシティとアジリティがもたらされ、長期的には最も低い総所有コストが実現されます。 これを実現できるのには主に 2 つの理由があります。アプリケーションがすでに最適化されており改良する必要がなく、データソースを移行後は同時に 2 つの環境を管理する必要がないからです。このアプローチは、デジタル ネイティブの企業や、レガシー環境があまりないエンジニアリング主導の組織に最適です。
最後に、最も保守的なアプローチとして、リフト&リホームがあります。これは、データ資産をクラウドに移行するための短期的な戦術的ソリューションとしておすすめします。既存のプラットフォームをクラウドに移動させたうえでリホーミングを行い、Google Cloud の環境でこれまでと同じように使用できます。これは、たとえば Teradata や Databricks のような環境にも適用でき、初期リスクを軽減してアプリケーションを実行できます。しかし、これは既存のサイロ化した環境を変換するのではなく、クラウドに移動させるものなので、Google Cloud 上にネイティブに構築されたプラットフォームの性能の恩恵を享受できません。ただし、Google は Google Cloud ネイティブなプロダクトへの完全移行をサポートできるため、相互運用性を活用し、Google Cloud 上に完全に最新のデータ分析プラットフォームを作成できます。
戦術的か戦略的か?
Google では、Google Cloud 上に構築されたデータ分析プラットフォームの主な差別化要因はオープン性、インテリジェンス、柔軟性、緊密な統合にあると考えています。市場には、快適で親しみやすそうな戦術的ソリューションを提供するソリューションが多数存在します。 しかし、これらが提供するのは一般に短期的な解決策にすぎず、時間の経過とともに組織と技術の問題を複雑にするだけです。
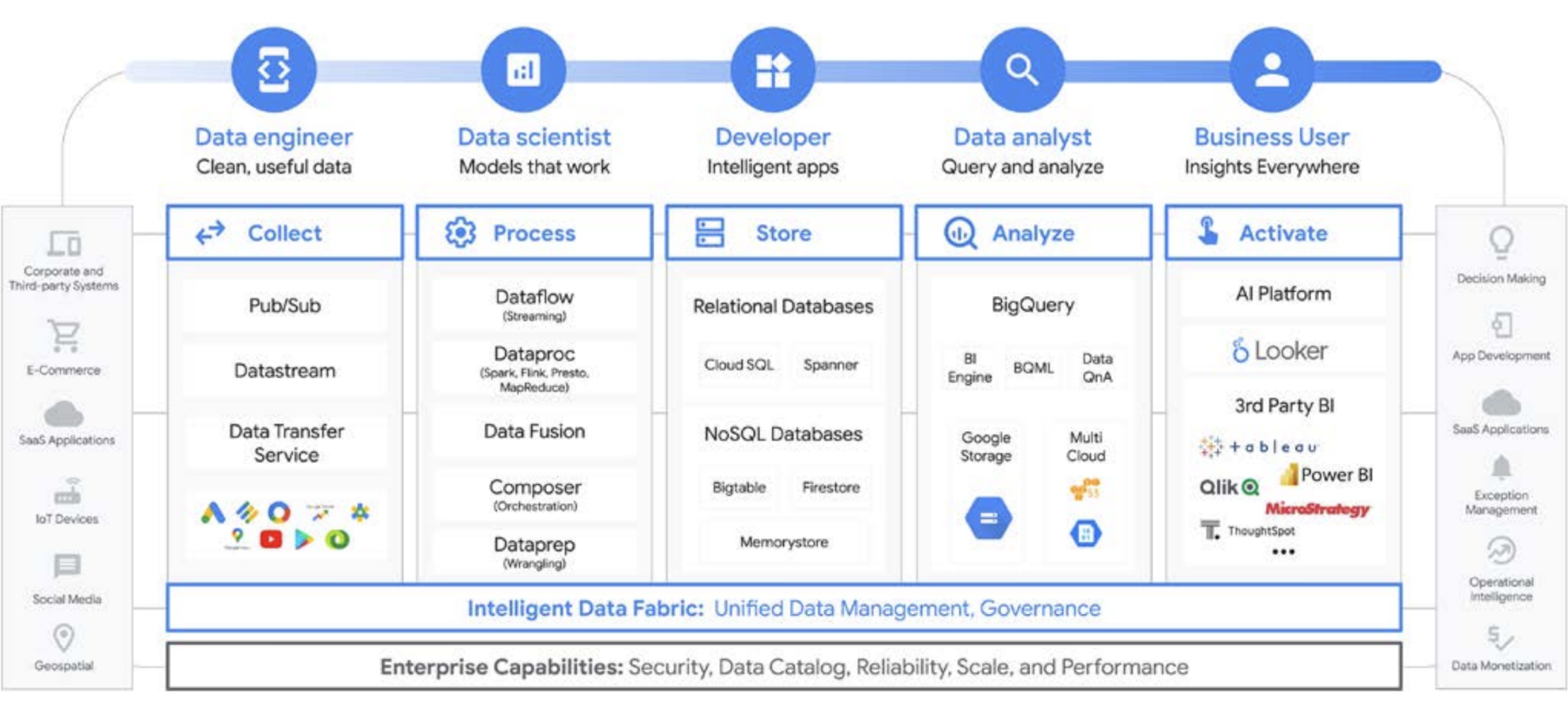
Google Cloud はデータ分析を大幅に簡素化します。 クラウドネイティブのサーバーレス アプローチにより、ストレージとコンピューティングを切り離し、ギガバイトからペタバイトのデータを数分で分析できるようになり、データに秘められた可能性を解き放つことができます。 これにより、スケーリング、パフォーマンス、費用といった従来の制約を取り払い、データに対してあらゆる問いを投げかけ、ビジネス上の問題を解決することを可能にします。その結果、単一の信頼できるデータ ファブリックにより、企業全体の分析情報を簡単に運用化できます。
その利点とは?
- インフラストラクチャではなく分析のみに専念できる
- 取り込みから変換、分析、ビジネス インテリジェンスまで、データ分析のライフサイクルのあらゆるステージを解決
- 機械学習を運用化するための強固なデータ基盤を構築
- 組織に最適なオープンソース テクノロジーの活用を可能にする
- ビジネスの推進やデジタル トランスフォーメーションにおけるデータ使用の拡大に伴い、企業のニーズに合わせた調整を実現
Google Cloud 上に構築された最新の統合分析データ プラットフォームは、データレイクとデータ ウェアハウスの長所を備えているだけでなく、AI Platform とのより緊密な統合を実現します。何十億ものストリーミング イベントからリアルタイムにデータを自動的に処理し、最大数ミリ秒で分析情報を提供することで、変化する顧客ニーズに対応できます。 Google の業界屈指の AI サービスは、組織の意思決定とカスタマー エクスペリエンスを最適化し、新たなチームを編成することなく、記述的分析と処方的分析の間の溝を埋めるために役立ちます。既存のスキルを補強し、自動化された組み込みのインテリジェンスで AI による影響を拡大することが可能になるのです。
次のステップ
Google データ プラットフォームが、お客様のビジネスにおけるデータの扱い方をどのように変えるかについて、もっと詳しく知りたいとお考えの方は、 詳細についてこちらまでお問い合わせください。
開始にあたりサポートが必要な場合
お問い合わせ信頼できるパートナーと連携する
パートナーを探すもっと見る
すべてのプロダクトを見る


















