En este documento, se presenta el lenguaje de consulta de Monitoring (MQL) a través de ejemplos. Sin embargo, no abarca todos los aspectos del lenguaje. El MQL es está completamente documentada en la referencia del Lenguaje de consulta de Monitoring.
Para obtener información sobre las políticas de alertas basadas en MQL, consulta Políticas de alertas con MQL.
Puedes escribir una consulta específica de muchas formas: el idioma es flexible y hay muchos atajos que puedes usar después de familiarizado con la sintaxis. Para obtener más información, lee Consultas estrictas.
Antes de comenzar
Para acceder al editor de código cuando usas el Explorador de métricas, sigue estos pasos: lo siguiente:
-
En la consola de Google Cloud, ve a la página leaderboardExplorador de métricas:
Dirígete al Explorador de métricas
Si usas la barra de búsqueda para encontrar esta página, selecciona el resultado cuyo subtítulo es Monitoring.
- En la barra de herramientas del panel del compilador de consultas, selecciona el botón cuyo nombre sea codeMQL o codePromQL.
- Verifica que MQL esté seleccionado en el botón de activación Lenguaje. El botón de activación de lenguaje se encuentra en la misma barra de herramientas que te permite dar formato a tu consulta.
Para ejecutar una consulta, pégala en el editor y haz clic en Ejecutar consulta. Para ver una introducción a este editor, consulta Usa el editor de código para MQL.
Es útil si estás familiarizado con algunos conceptos de Cloud Monitoring, incluidos los tipos de métricas, los tipos de recursos supervisados y las series temporales. Para obtener una introducción a estos conceptos, consulta Métricas, series temporales y recursos.
Modelo de datos
Las consultas de MQL recuperan y manipulan datos en la base de datos de series temporales de Cloud Monitoring. En esta sección, se presentan algunos de los conceptos y la terminología que están relacionados con esa base de datos. Para obtener información detallada, consulta el tema de referencia Modelo de datos.
Cada serie temporal se origina a partir de un solo tipo de recurso supervisado y recopila datos de un tipo de métrica.
Un descriptor de recursos supervisados define un tipo de recurso supervisado. De la misma manera, un descriptor de métrica define un tipo de métrica.
Por ejemplo, el tipo de recurso podría ser gce_instance, una máquina virtual (VM) de Compute Engine, y el tipo de métrica podría ser compute.googleapis.com/instance/cpu/utilization, el uso de CPU de la VM de Compute Engine.
Estos descriptores también especifican un conjunto de etiquetas que se usan para recopilar información sobre otros atributos de la métrica o el tipo de recurso. Por ejemplo, los recursos suelen tener una etiqueta zone, que se usa para registrar la ubicación geográfica del recurso.
Se crea una serie temporal por cada combinación de valores de las etiquetas del par que consta de un descriptor de métricas y un descriptor de recursos supervisados.
Puedes encontrar las etiquetas disponibles para los tipos de recursos en la lista de recursos supervisados, por ejemplo, gce_instance.
Para encontrar las etiquetas de los tipos de métricas, consulta la Lista de métricas. Por ejemplo, consulta Métricas de Compute Engine.
En la base de datos de Cloud Monitoring, se almacenan las series temporales de un tipo de recursos y métricas en particular en una tabla. El tipo de recurso y métrica actúa como el identificador de la tabla. Mediante esta consulta de MQL, se recupera la tabla de las series temporales en la que se registra el uso de CPU de las instancias de Compute Engine:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
Hay una serie temporal en la tabla para cada combinación única de valores de etiqueta de métrica y recursos.
Las consultas de MQL recuperan datos de series temporales de estas tablas y los transforman en tablas de resultados. Estas tablas de resultados se pueden pasar a otras operaciones. Por ejemplo, puedes aislar las series temporales escritas mediante recursos en una zona o un conjunto de zonas en particular si pasas la tabla recuperada como una entrada a una operación filter:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
La consulta anterior da como resultado una tabla que contiene solo las series temporales de los recursos de una zona que comienza con us-central.
Las consultas de MQL están estructuradas para pasar el resultado de una operación como entrada a la siguiente operación. Este enfoque basado en tablas te permite vincular operaciones para manipular estos datos mediante el filtrado, la selección y otras operaciones conocidas de las bases de datos, como las uniones internas y externas. También puedes ejecutar una variedad de funciones en los datos de la serie temporal, ya que se pasan de una operación a otra.
Las operaciones y las funciones disponibles en MQL están documentadas por completo en la referencia del lenguaje de consulta de Monitoring.
Estructura de la consulta
Una consulta se compone de una o más operaciones. Las operaciones están vinculadas o canalizadas entre sí, de modo que el resultado de una operación sea la entrada de la siguiente. Por lo tanto, el resultado de una consulta depende del orden de las operaciones. Las siguientes son algunas de las acciones que puedes realizar:
- Iniciar una consulta con
fetcho con alguna otra operación de selección - Crear una consulta con varias operaciones canalizadas entre sí
- Selecciona un subconjunto de información con operaciones de
filter. - Agregar información relacionada con las operaciones
group_by - Observar los valores atípicos con las operaciones
topybottom - Combinar varias consultas con las operaciones
{ ; }yjoin - Usar las funciones y la operación
valuepara procesar las proporciones y otros valores
No todas las consultas usan todas estas opciones.
En estos ejemplos, solo se presentan algunas de las operaciones y las funciones disponibles. Para obtener información detallada sobre la estructura de las consultas de MQL, consulta el tema de referencia de la Estructura de consulta.
En estos ejemplos, no se especifican dos aspectos que podrías esperar: los intervalos de tiempo y la alineación. En las siguientes secciones, se explica por qué.
Intervalos de tiempo
Cuando usas el editor de código, la configuración del gráfico define la para las consultas. De forma predeterminada, el intervalo de tiempo del gráfico está establecido en una hora.
Para cambiar el intervalo de tiempo del gráfico, usa el selector de intervalo de tiempo. Para Por ejemplo, si quieres ver los datos de la semana pasada, selecciona Última 1 semana en el selector de intervalo de tiempo. También puedes especificar una hora de inicio y de finalización, o especificar una hora para ver los alrededores.
Para obtener más información sobre los intervalos de tiempo en el editor de código, consulta Intervalos de tiempo, gráficos y el editor de código
Alineación
Muchas de las operaciones que se usan en estos ejemplos, como las operaciones join y group_by, dependen de todos los puntos de serie temporal de una tabla que ocurren en intervalos regulares. La acción de hacer que todos los puntos estén alineados en marcas de tiempo regulares se denomina alineación. Por lo general, la alineación se realiza de forma implícita y no se ve en ninguno de los ejemplos.
MQL alinea automáticamente las tablas de las operaciones join y group_by, cuando es necesario, pero también te permite realizar la alineación de manera explícita.
Para obtener información general sobre el concepto de alineación, consulta Alineación: agregación dentro de series.
Para obtener información sobre la alineación en MQL, consulta el tema de referencia de la Alineación. La alineación se puede controlar de forma explícita mediante las operaciones
alignyevery.
Cómo obtener y filtrar datos
Las consultas de MQL comienzan con la recuperación y la selección o el filtrado de los datos. En esta sección, se ilustran algunas capacidades básicas de recuperación el filtrado con MQL.
Recupera datos de series temporales
Una consulta siempre comienza con una operación fetch, que recupera series temporales de Cloud Monitoring.
La consulta más simple consiste en una sola operación fetch y un argumento que identifica la serie temporal que se debe obtener, como la siguiente:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
El argumento consta de un tipo de recursos supervisados, gce_instance, un par de caracteres de dos puntos, ::, y un tipo de métricas, compute.googleapis.com/instance/cpu/utilization.
Mediante esta consulta, se recuperan las series temporales escritas por instancias de Compute Engine para el tipo de métricas compute.googleapis.com/instance/cpu/utilization, que registra el uso de CPU de esas instancias.
Si ejecutas la consulta desde el editor de código en el Explorador de métricas, Obtendrás un gráfico que muestra cada una de las series temporales solicitadas:
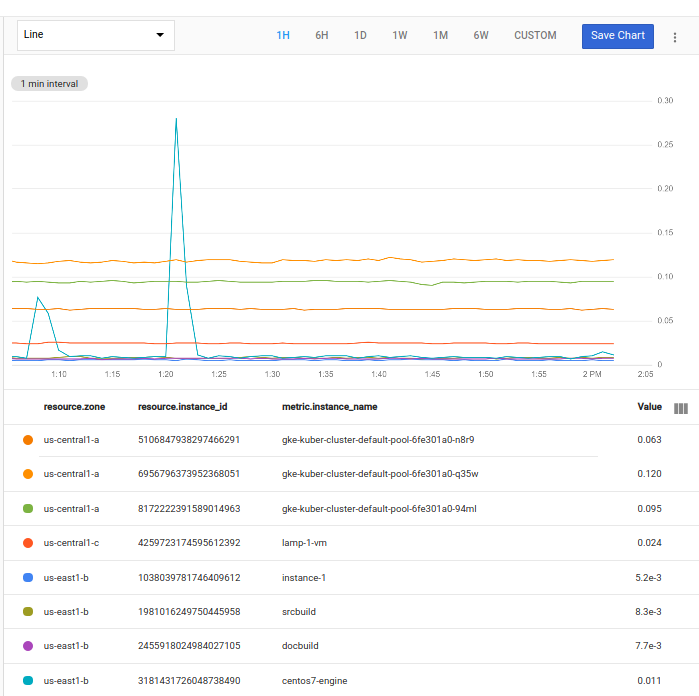
Cada una de las series temporales solicitadas se muestra como una línea en el gráfico. En cada serie temporal, se incluye una lista de valores con marcas de tiempo de la métrica de uso de CPU de una instancia de VM en este proyecto.
En el almacenamiento de backend que usa Cloud Monitoring, las series temporales se almacenan en tablas. La operación fetch organiza las series temporales de los tipos de métricas y recursos supervisados especificados en una tabla y, luego, muestra la tabla.
Los datos que se muestran figuran en el gráfico.
La operación fetch se describe, junto con sus argumentos, en la página de referencia de fetch. Para obtener más información sobre los datos producidos por las operaciones, consulta las páginas de referencia de las series temporales y las tablas.
Filtrar operaciones
Por lo general, las consultas constan de una combinación de varias operaciones. La combinación más simple consiste en la canalización del resultado de una operación en la entrada de la siguiente mediante el operador de canalización, |. En el siguiente ejemplo, se ilustra el uso de una canalización destinada a ingresar la tabla en una operación de filtrado:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter instance_name =~ 'gke.*'
Esta consulta canaliza la tabla, que muestra la operación fetch en el ejemplo anterior, en una operación filter, que toma como una expresión que se evalúa como un valor booleano. En este ejemplo, la expresión significa “instance_name comienza con gke”.
La operación filter toma la tabla de entrada, quita la serie temporal para la que el filtro es falso y muestra la tabla resultante. En la siguiente captura de pantalla, se muestra el gráfico resultante:
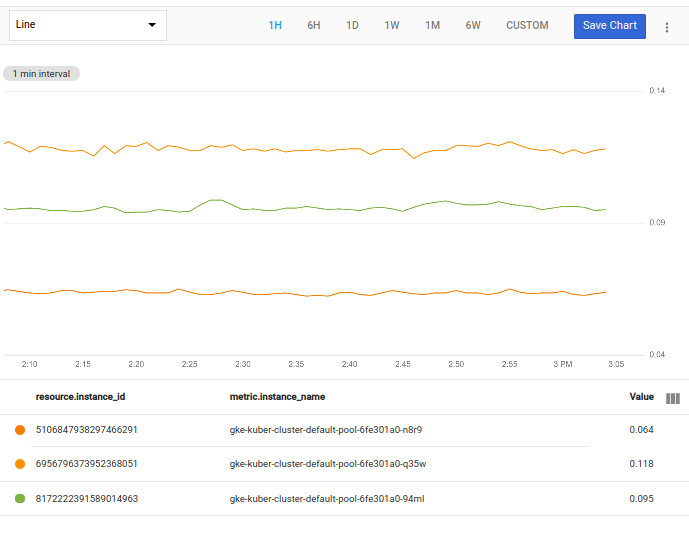
Si no tienes ningún nombre de instancia que comience con gke, cambia el filtro antes de probar esta consulta. Por ejemplo, si tienes instancias de VM con apache al comienzo de sus nombres, usa el siguiente filtro:
| filter instance_name =~ 'apache.*'
La expresión filter se evalúa una vez en cada serie temporal de entrada.
Si la expresión se evalúa como true, esa serie temporal se incluirá en el resultado. En este ejemplo, la expresión de filtrado hace coincidir una expresión regular, =~, en la etiqueta instance_name de cada serie temporal. Si el valor de la etiqueta coincide con la expresión regular 'gke.*', la serie temporal se incluirá en el resultado. De lo contrario, la serie temporal se descartará del resultado.
Para obtener más información sobre los filtros, consulta la página de referencia de filter.
El predicado filter puede ser cualquier expresión arbitraria que muestre un valor booleano. Para obtener más información, consulta Expresiones.
Agrupar y agregar
La agrupación te permite agrupar series temporales en dimensiones específicas. Mediante la agregación, se combinan todas las series temporales de un grupo en una serie temporal de salida.
Mediante la siguiente consulta, se filtra el resultado de la operación inicial fetch con el fin de retener solo esas series temporales de los recursos en una zona que comienza con us-central. Luego, se agrupan las series temporales por zona y las combina mediante la agregación mean.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| filter zone =~ 'us-central.*'
| group_by [zone], mean(val())
En la tabla resultante de la operación group_by, hay una serie temporal por zona.
En la siguiente captura de pantalla, se muestra el gráfico resultante:
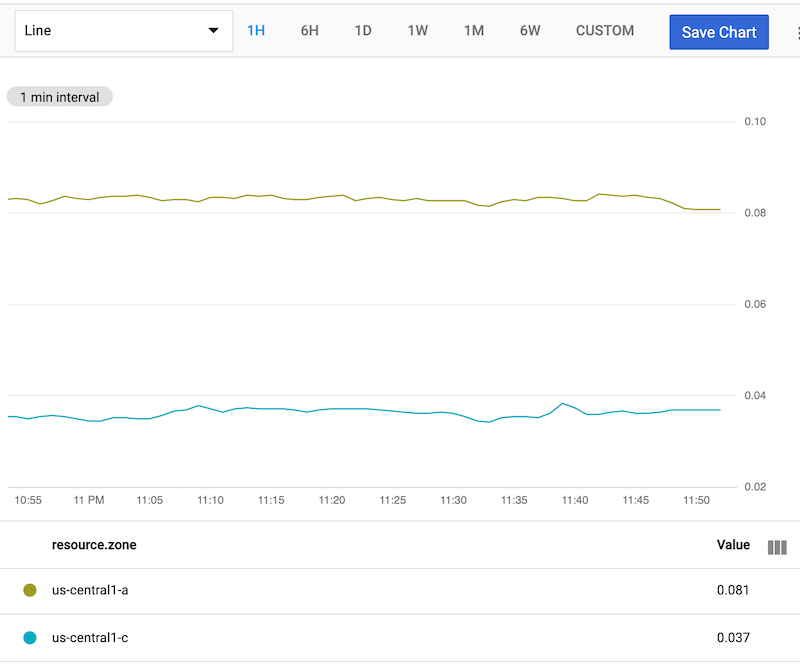
La operación group_by toma dos argumentos, separados por una coma (,). Estos argumentos determinan el comportamiento preciso de la agrupación. En este ejemplo, group_by [zone], mean(val()), los argumentos actúan de la siguiente manera:
El primer argumento,
[zone], es una expresión de mapa que determina la agrupación de las series temporales. En este ejemplo, se especifican las etiquetas que se usarán para la agrupación. El paso de agrupación recopila todas las series temporales de entrada que tienen los mismos valoreszonede salida en un grupo. En este ejemplo, la expresión recopila las series temporales de las VM de Compute Engine en una zona.La serie temporal de salida solo tiene una etiqueta
zone, con el valor de copiado de la serie temporal de entrada en el grupo. Las otras etiquetas de la serie temporal de entrada se descartan de la serie temporal de salida.La expresión del mapa puede hacer mucho más que enumerar etiquetas. Para obtener más información, consulta la página de referencia de
map.El segundo argumento,
mean(val()), controla cómo se combinan las series temporales de cada grupo o cómo se agregan en una serie temporal de salida. Cada punto en la serie temporal de salida de un grupo es el resultado del agregado de los puntos con la misma marca de tiempo de todas las series temporales de entrada en el grupo.La función de agregación
meanen este ejemplo determina el valor agregado. La funciónval()muestra los puntos que se agregarán, y la función de agregación se aplica a esos puntos. En este ejemplo, obtienes la media del uso de CPU de las máquinas virtuales de la zona en cada punto de salida.La expresión
mean(val())es un ejemplo de una expresión de agregación.
Mediante la operación group_by, siempre se combina la agrupación y la agregación.
Si especificas una agrupación, pero omites el argumento de agregación, group_by usa una agregación predeterminada, aggregate(val()), que selecciona una función adecuada para el tipo de datos. Consulta aggregate para ver la lista de las funciones de agregación predeterminadas.
Usa group_by con una métrica basada en registros
Supongamos que creaste una métrica de distribución basada en registros para extraer la cantidad de datos procesados a partir de un conjunto de entradas largas, incluidas cadenas como lo siguiente:
... entry ID 1 ... Processed data points 1000 ... ... entry ID 2 ... Processed data points 1500 ... ... entry ID 3 ... Processed data points 1000 ... ... entry ID 4 ... Processed data points 500 ...
Para crear una serie temporal que muestre el recuento de todos los datos procesados, sigue estos pasos: usa un MQL como el siguiente:
fetch global
| metric 'logging.googleapis.com/user/metric_name'
| group_by [], sum(sum_from(value))
Para crear una métrica de distribución basada en registros, consulta Configura métricas de distribución.
Excluir columnas de un grupo
Puedes usar el modificador drop en una asignación para excluir columnas de una
grupo.
Por ejemplo, la métrica core_usage_time de Kubernetes tiene seis columnas:
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by [project_id, location, cluster_name, namespace_name, container_name]
Si no necesitas agrupar pod_name, puedes excluirlo con drop:
fetch k8s_container :: kubernetes.io/container/cpu/core_usage_time | group_by drop [pod_name]
Seleccionar serie temporal
En los ejemplos de esta sección, se ilustran formas de seleccionar series temporales específicas de una tabla de entrada.
Selecciona la serie temporal superior o inferior
Para ver los datos de las series temporales de las tres instancias de Compute Engine con el uso de CPU más alto dentro de tu proyecto, ingresa la siguiente consulta:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3
En la siguiente captura de pantalla, se muestra el resultado de un proyecto:
Puedes recuperar las series temporales con el menor uso de CPU si reemplazas top por bottom.
La operación top genera una tabla con una cantidad específica de series temporales seleccionadas de su tabla de entrada. Las series temporales incluidas en el resultado tienen el valor más alto en algún aspecto de la serie temporal.
Como esta consulta no especifica una forma de ordenar las series temporales, las muestra con el valor más grande en el punto más reciente.
Para especificar cómo determinar qué series temporales tienen el valor más grande, puedes proporcionar un argumento a la operación top. Por ejemplo, la consulta anterior es equivalente a la siguiente consulta:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, val()
Mediante la expresión val(), se selecciona el valor del punto más reciente en cada serie temporal en la que se aplica, por lo que la consulta muestra las que tienen el valor más grande en el punto más reciente.
Puedes proporcionar una expresión que realice la agregación en algunos o en todos los puntos de una serie temporal para proporcionar el valor de ordenamiento. A continuación, se muestra la media de todos los puntos en los últimos 10 minutos:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top 3, mean(val()).within(10m)
Si no se usa la función within, la función mean se aplica a los valores de todos los puntos que se muestran en la serie temporal.
La operación bottom funciona de manera similar.
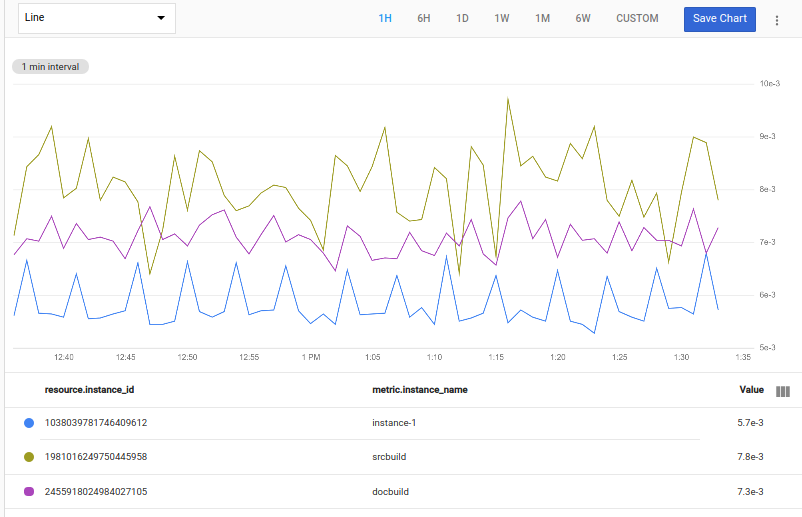
Mediante la siguiente consulta, se encuentra el valor del punto más grande de cada serie temporal con max(val()) y, luego, se seleccionan las tres series temporales en las que ese valor es el menor:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| bottom 3, max(val())
En la siguiente captura de pantalla, se muestra un gráfico en el que se ven las transmisiones con los aumentos más pequeños:
Excluye los n resultados superiores o inferiores de la serie temporal.
Supongamos que tienes muchas instancias de VM de Compute Engine. Algunas de estas instancias consumen mucha más memoria que la mayoría. y estos valores atípicos hacen que sea más difícil ver los patrones de uso en la un grupo más grande. Los gráficos de uso de CPU se ven de la siguiente manera:
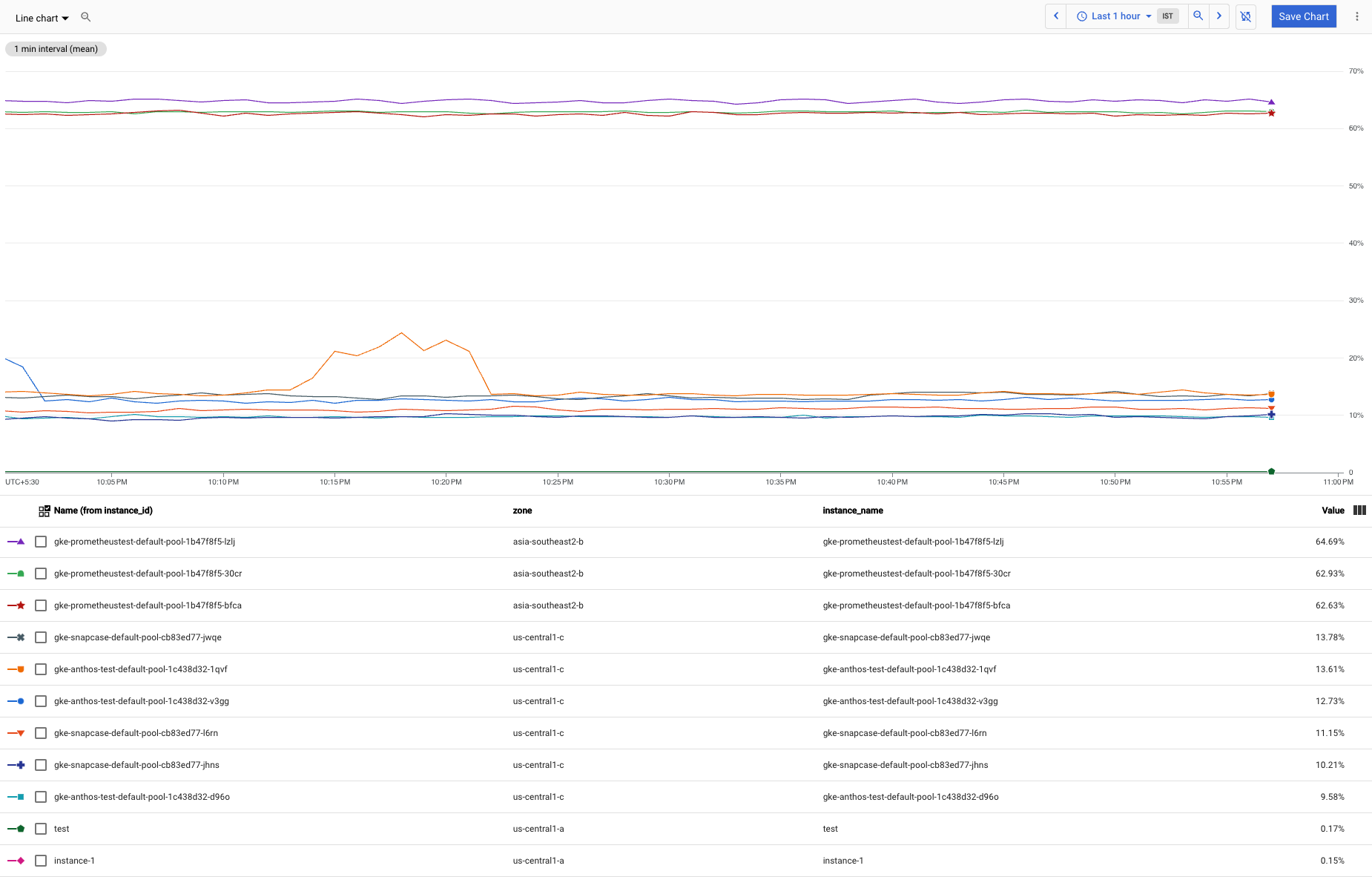
Quieres excluir los tres valores atípicos del gráfico para ver los patrones del grupo más grande con mayor claridad.
Excluir las tres series temporales principales en una consulta que recupere las series temporales
Para el uso de CPU de Compute Engine, usa la operación de tabla top.
para identificar las series temporales y la operación de la tabla outer_join
para excluir las series temporales identificadas de los resultados. Puedes usar la
siguiente consulta:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 3 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
La operación fetch muestra una tabla de series temporales para el uso de CPU de
todas las instancias. Esta tabla luego se procesa en dos tablas resultantes:
La operación de tabla
top ngenera una tabla que Contiene el tiempo n una serie con los valores más altos. En este caso, n = 3. El resultado contiene las tres series temporales que se excluirán.La tabla que contiene las tres series temporales principales se canaliza en una Operación de tabla
value. Esta operación agrega otra columna a cada una de las series temporales de la tabla de las tres primeras. Esta columna,is_default_value, recibe el valor booleanofalsepara todos series temporales en la tabla de las tres primeras.La operación
identmuestra la misma tabla que se canalizó a ella: de la tabla original de series temporales de uso de CPU. Ninguna vez series de esta tabla tienen la columnais_default_value.
La tabla de las tres primeras y la original se canalizan a la tabla
Operación de tabla outer_join. La tabla de las tres superiores es la de la izquierda
en la unión, la tabla recuperada es la tabla correcta en la unión.
La unión externa está configurada para proporcionar el valor true como el valor de
si hay un campo que no existe
en la fila que se está uniendo. El resultado de la
OUTER JOIN es una tabla combinada, en la que las filas de las tres primeras tablas mantienen
la columna is_default_value con el valor false y todas las filas de
de la tabla original que no estaban también en las tres primeras tablas y obtuvo la
La columna is_default_value con el valor true.
La tabla resultante de la unión se pasa a filter.
una operación de tabla, que filtra las filas que tienen un
valor de false en la columna is_default_value. La tabla resultante
contiene las filas de la tabla recuperada originalmente sin las filas
de la tabla de los tres primeros. Esta tabla contiene el conjunto previsto
de series temporales,
con el is_default_column agregado.
El último paso es descartar la columna is_default_column que agregó
la unión, por lo que la tabla de salida tiene las mismas columnas que la que se recuperó originalmente
desde una tabla de particiones.
En la siguiente captura de pantalla, se muestra el gráfico de la consulta anterior:
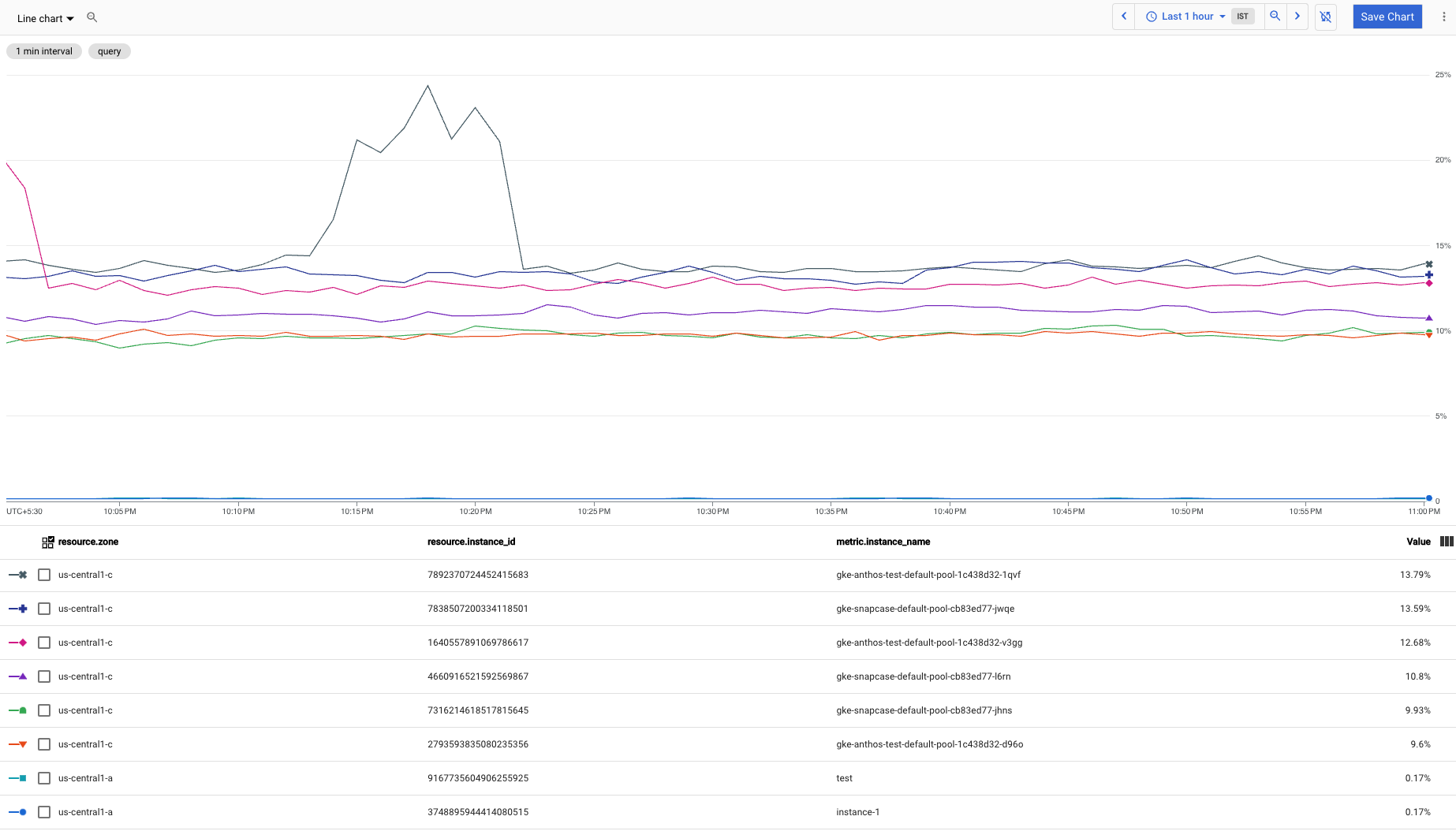
Puedes crear una consulta para excluir las series temporales con la menor
Reemplaza top n por bottom
n para el uso de CPU.
La capacidad de excluir valores atípicos puede ser útil en casos en los que desees configurar una alerta, pero no quieres que los valores atípicos la activen constantemente. La siguiente consulta de alerta usa la misma lógica de exclusión que la anterior para supervisar el uso del límite de CPU por parte de un conjunto de Pods de Kubernetes después de excluir los dos Pods superiores:
fetch k8s_container
| metric 'kubernetes.io/container/cpu/limit_utilization'
| filter (resource.cluster_name == 'CLUSTER_NAME' &&
resource.namespace_name == 'NAMESPACE_NAME' &&
resource.pod_name =~ 'POD_NAME')
| group_by 1m, [value_limit_utilization_max: max(value.limit_utilization)]
| {
top 2 | value [is_default_value: false()]
;
ident
}
| outer_join true(), _
| filter is_default_value
| value drop [is_default_value]
| every 1m
| condition val(0) > 0.73 '1'
Selecciona la parte superior o inferior de los grupos
Las operaciones de tabla top y bottom seleccionan series temporales de toda la tabla de entrada. Las operaciones top_by y bottom_by agrupan las series temporales en una tabla y, luego, eligen algunas de ellas.
Mediante la siguiente consulta, se seleccionan las series temporales de cada zona con el valor máximo más alto y lo siguiente:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 1, max(val())
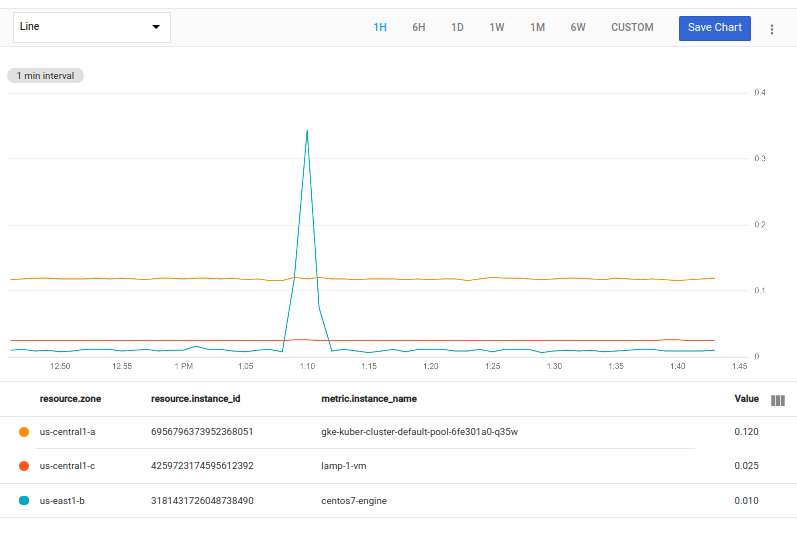
La expresión [zone] indica que un grupo consta de las series temporales con el mismo valor de la columna zone.
El 1 en el top_by indica cuántas series temporales se deben seleccionar del grupo de cada zona. La expresión max(val()) busca el valor más grande en
el intervalo de tiempo del gráfico en cada serie temporal.
Puedes usar cualquier función de agregación en lugar de max.
Por ejemplo, a continuación, se usa el agregador mean y se usa within para especificar el rango de ordenamiento de 20 minutos. Se seleccionan las 2 series temporales principales de cada zona:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| top_by [zone], 2, mean(val()).within(20m)
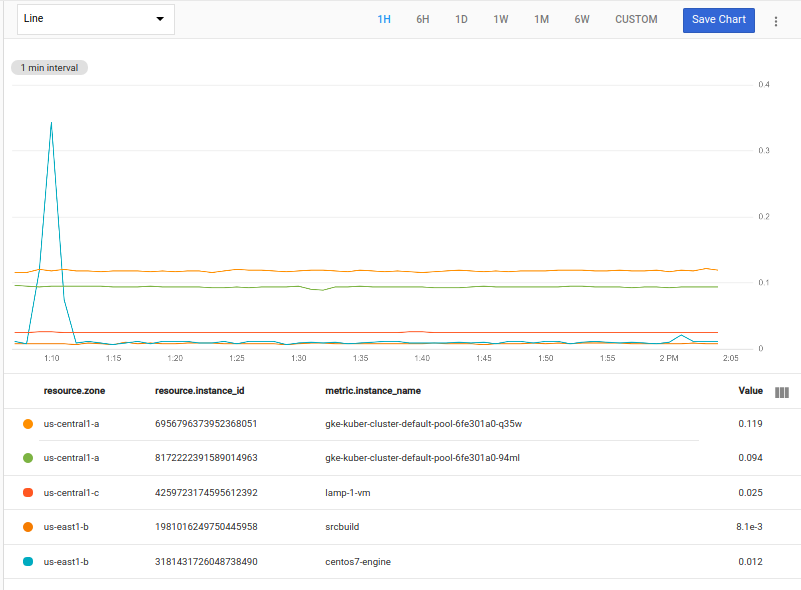
En el ejemplo anterior, solo hay una instancia en la zona us-central-c, por lo que se muestra una sola serie temporal. No hay "2 superiores" en el grupo.
Combinar selecciones con union
Puedes combinar operaciones de selección como top y bottom para crear gráficos en los que se muestren ambos. Por ejemplo, mediante la siguiente consulta, se muestra la serie temporal única con el valor máximo y la serie temporal única con el valor mínimo:
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| {
top 1, max(val())
;
bottom 1, min(val())
}
| union
En el gráfico resultante, se muestran dos líneas, la que contiene el valor más alto y la que contiene el valor más bajo:
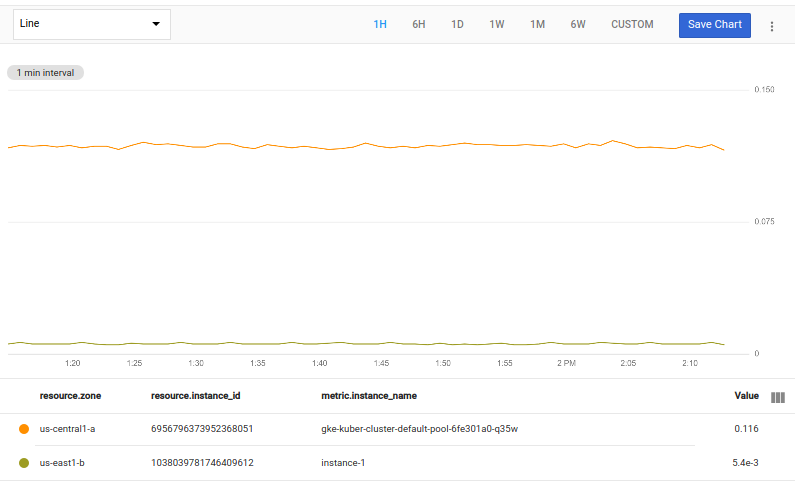
Puedes usar llaves, { }, para especificar secuencias de operaciones, cada una de las cuales produce una tabla de series temporales como resultado. Las operaciones individuales están separadas por dos puntos, ;.
En este ejemplo, la operación fetch muestra una sola tabla, que se canaliza a cada una de las dos operaciones de la secuencia, una operación top y una operación bottom. Cada una de estas operaciones genera una tabla de resultados basada en la misma tabla de entrada. Luego, la operación union combina las dos tablas en una, que se muestra en el gráfico.
Obtén más información sobre las operaciones de secuencia mediante { } en el tema de referencia de la Estructura de consulta.
Combina series temporales con valores diferentes para una etiqueta
Supongamos que tienes varias series temporales para el mismo tipo de métrica y
querrás combinar algunas de ellas. Si quieres seleccionarlos
basados en los valores de una sola etiqueta, no puedes crear la consulta
a través de la interfaz del compilador de consultas en el Explorador de métricas. Debes
filtrar por dos o más valores diferentes de la misma etiqueta, pero el compilador de consultas
interfaz requiere que una serie temporal coincida con todos los filtros que se deben seleccionar:
la coincidencia de etiquetas es una prueba de AND. Ninguna serie temporal puede tener dos
valores para la misma etiqueta, pero no puedes crear una prueba OR para los filtros
en el compilador de consultas.
La siguiente consulta recupera las series temporales para la Compute Engine
La métrica instance/disk/max_read_ops_count para dos instancias específicas de Compute Engine
y alinea el resultado en intervalos de 1 minuto:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| every 1m
En el siguiente gráfico, se muestra un resultado de esta consulta:
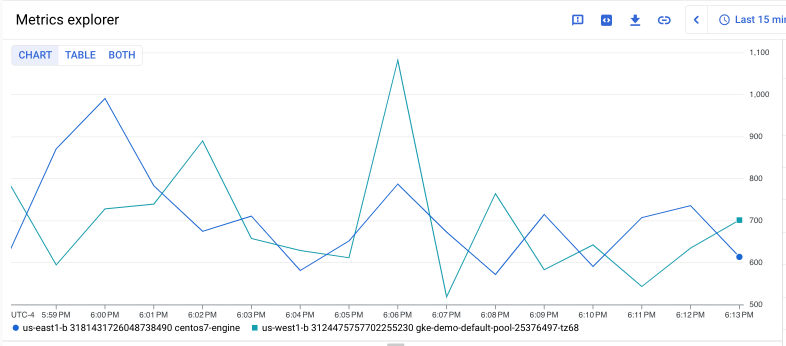
Si quieres encontrar la suma de los valores máximos de max_read_ops_count de estas
dos VMs y las sumas, puedes hacer lo siguiente:
- Encuentra el valor máximo para cada serie temporal con la
Operador de tabla
group_by, que especifica el mismo minuto período de alineación y agregación a lo largo del período con el agregadormaxpara crear una columna llamadamax_val_of_read_ops_count_maxen el resultado desde una tabla de particiones. - Calcula la suma de las series temporales con el operador de tabla
group_byy el agregadorsumen la columnamax_val_of_read_ops_count_max.
A continuación, se muestra la consulta:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/max_read_ops_count'
| filter (resource.instance_id == '1854776029354445619' ||
resource.instance_id == '3124475757702255230')
| group_by 1m, [max_val_of_read_ops_count_max: max(value.max_read_ops_count)]
| every 1m
| group_by [], [summed_value: sum(max_val_of_read_ops_count_max)]
En el siguiente gráfico, se muestra un resultado de esta consulta:
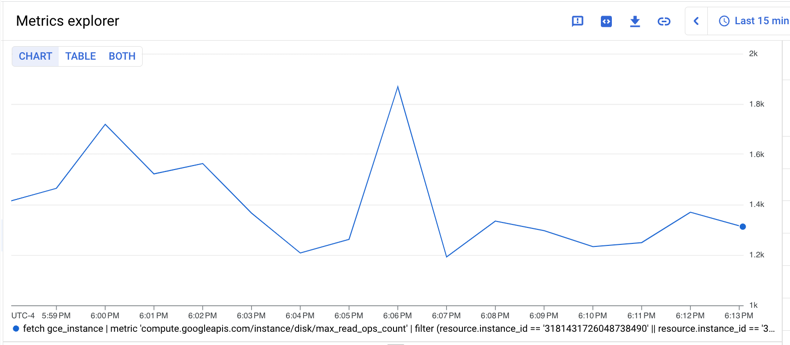
Calcula estadísticas de percentiles en el tiempo y en todas las transmisiones
Calcular un valor de flujo percentil en una ventana deslizante por separado para cada
por flujo, usa una operación group_by temporal. Por ejemplo, el siguiente
la consulta calcula el valor percentil 99 de una transmisión en un período variable de 1 hora
ventana:
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by 1h, percentile(val(), 99) | every 1m
Para calcular la misma estadística de percentil en un momento determinado en las transmisiones,
en lugar de hacerlo a lo largo del tiempo dentro de una transmisión, usa una operación espacial group_by:
fetch gce_instance :: compute.googleapis.com/instance/cpu/utilization | group_by [], percentile(val(), 99)
Calcular proporciones
Supongamos que compilaste un servicio web distribuido que se ejecuta en instancias de VM de Compute Engine y usa Cloud Load Balancing.
Deseas ver un gráfico en el que se muestre la proporción de solicitudes que muestran respuestas 500 HTTP (errores internos) con respecto a la cantidad total de solicitudes, es decir, la proporción entre solicitud y falla. En esta sección, se ilustran varias maneras de calcular la proporción entre las solicitudes y las fallas.
Cloud Load Balancing usa el tipo de recurso supervisado http_lb_rule.
El tipo de recurso supervisado http_lb_rule tiene una etiqueta matched_url_path_rule que registra el prefijo de URL definido en la regla. El valor predeterminado es UNMATCHED.
El tipo de métrica loadbalancing.googleapis.com/https/request_count tiene una etiqueta response_code_class. Esta etiqueta captura la clase de los códigos de respuesta.
Pueden usar outer_join y div
Mediante la siguiente consulta, se determinan las respuestas 500 para cada valor de la etiqueta matched_url_path_rule en cada recurso supervisado http_lb_rule de tu proyecto. Luego, se une esta tabla de recuento de fallas con la tabla original, que contiene los recuentos de todas las respuestas, y se dividen los valores para mostrar la proporción de las respuestas de falla con el total de respuestas:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| outer_join 0
| div
En el siguiente gráfico, se muestra el resultado de un proyecto:
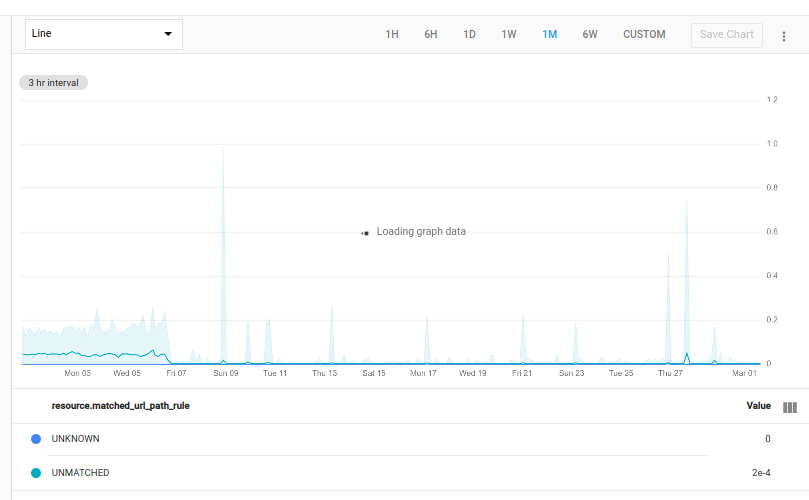
Las áreas sombreadas alrededor de las líneas en el gráfico son bandas min/min. Para obtener más información, consulta Bandas mínimas y máximas.
La operación fetch da como resultado una tabla de series temporales que contiene los recuentos de solicitudes de todas las consultas de balanceo de cargas. Esta tabla se procesa de dos maneras mediante las dos secuencias de operaciones entre llaves.
filter response_code_class = 500muestra solo las series temporales que tienen la etiquetaresponse_code_classcon el valor500. La serie temporal resultante cuenta las solicitudes con códigos de respuesta HTTP 5xx (de error).Esta tabla es el numerador de la proporción.
La operación
ident, o identidad, genera su entrada, por lo que esta operación devuelve la tabla recuperada originalmente. Esa es la tabla que contiene las series temporales con recuentos para cada código de respuesta.Esta tabla es el denominador de la proporción.
Las tablas del numerador y el denominador, producidas por las operaciones filter y ident respectivamente, se procesan por separado mediante la operación group_by.
La operación group_by agrupa las series temporales de cada tabla por el valor de la etiqueta matched_url_path_rule y suma los recuentos de cada valor de la etiqueta. En esta operación group_by, no se indica de manera explícita la función de agregador, por lo que se usa un valor predeterminado sum.
En la tabla filtrada, el resultado
group_byes la cantidad de solicitudes que muestran una respuesta500para cada valormatched_url_path_rule.En la tabla de identidad, el resultado de
group_byson la cantidad total de solicitudes para cada valormatched_url_path_rule.
Estas tablas se canalizan a la operación outer_join, que vincula series temporales con valores de etiquetas coincidentes, una de cada una de las dos tablas de entrada. Las series temporales vinculadas se comprimen mediante la coincidencia de la marca de tiempo de cada punto temporal con la de un punto de la otra serie temporal. Para cada par de puntos coincidentes, outer_join produce un único punto de salida con dos valores, uno de cada una de las tablas de entrada.
La combinación temporal con las mismas etiquetas que las dos series temporales de entrada genera la serie temporal comprimida.
Con una combinación externa, si un punto de la segunda tabla no tiene un punto coincidente en la primera, se debe proporcionar un valor de reemplazo. En este ejemplo, se usa un punto con el valor 0, el argumento de la operación outer_join.
Finalmente, la operación div toma cada punto con dos valores y divide los valores a fin de producir un único punto de salida: la proporción de 500 respuestas a todas las respuestas para cada mapa de URL.
En este caso, la string div es en realidad el nombre de la función div, que divide dos valores numéricos. Pero aquí se usa como una operación. Cuando se usan como operaciones, las funciones como div esperan dos valores en cada punto de entrada (que garantiza este objeto join) y producen un solo valor para el punto de salida correspondiente.
La parte | div de la consulta es un acceso directo para | value val(0) / val(1).
La operación value permite que las expresiones arbitrarias de las columnas de valores de una tabla de entrada produzcan las columnas de valores de la tabla de salida.
Para obtener más información, consulta las páginas de referencia de la operación value y de las expresiones.
Usar ratio
La función div podría reemplazarse por cualquier función en dos valores, pero como las proporciones se usan con frecuencia, MQL proporciona una operación de tabla ratio que calcula las proporciones de forma directa.
La siguiente consulta es equivalente a la versión anterior mediante el uso de outer_join y div:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| {
filter response_code_class = 500
;
ident
}
| group_by [matched_url_path_rule]
| ratio
En esta versión, la operación ratio reemplaza las operaciones outer_join 0 | div de la versión anterior y produce el mismo resultado.
Ten en cuenta que ratio solo usa outer_join a fin de proporcionar un 0 para el numerador si las entradas del numerador y el denominador tienen las mismas etiquetas que identifican cada serie temporal, que MQL outer_join requiere. Si la entrada del numerador
tiene etiquetas adicionales, no habrá resultados para ningún punto que falte en
denominador.
Pueden usar group_by y /
Existe otra forma de calcular la proporción entre las respuestas de error y todas las respuestas. En este caso, debido a que el numerador y denominador de la proporción se derivan de la misma serie temporal, también puedes calcular la proporción mediante solo la agrupación. Mediante la siguiente consulta, se demuestra este enfoque:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| group_by [matched_url_path_rule],
sum(if(response_code_class = 500, val(), 0)) / sum(val())
Esta consulta usa una expresión de agregación basada en la proporción de dos sumas:
El primer elemento
sumusa la funciónifpara contar las etiquetas con valor de 500 y 0 para las demás. La funciónsumcalcula el recuento de las solicitudes que mostraron 500.El segundo elemento
sumsuma los recuentos de todas las solicitudes,val().
Las dos sumas se dividen, lo que da como resultado la proporción de 500 respuestas para todas las respuestas. Esta consulta produce el mismo resultado que las consultas de Usa outer_join y div y Usa ratio.
Usar filter_ratio_by
Debido a que las proporciones se calculan con frecuencia mediante la división de dos sumas derivadas de la misma tabla, MQL proporciona la operación filter_ratio_by para este propósito. La siguiente consulta hace lo mismo que la versión anterior, que divide las sumas de forma explícita:
fetch https_lb_rule::loadbalancing.googleapis.com/https/request_count
| filter_ratio_by [matched_url_path_rule], response_code_class = 500
El primer operando de la operación filter_ratio_by, aquí [matched_url_path_rule], indica cómo agrupar las respuestas. La segunda operación, aquí response_code_class = 500, actúa como una expresión de filtrado para el numerador.
- La tabla del denominador es el resultado de la agrupación de la tabla recuperada por
matched_url_path_ruley agregada mediantesum. - La tabla del numerador es la tabla recuperada, filtrada por series temporales con un código de respuesta HTTP de 5xx y, luego, agrupada por
matched_url_path_ruley agregada mediantesum.
Proporciones y métricas de cuota
Si quieres configurar consultas y alertas sobre métricas de cuota serviceruntime y métricas de cuota específicas de recursos para supervisar el consumo de cuota, puedes usar MQL. Para obtener más información, incluidos ejemplos, consulta Uso de métricas de cuota.
Procesamiento aritmético
Es posible que, en ocasiones, desees realizar una operación aritmética en los datos antes de graficarlos. Por ejemplo, es posible que desees escalar series temporales, convertir los datos a una escala de registro o graficar la suma de dos series temporales. Para obtener una lista de las funciones aritméticas disponibles en MQL, consulta Aritmética.
Para escalar una serie temporal, usa la función mul. Por ejemplo, la siguiente consulta recupera la serie temporal y, luego, multiplica cada valor por 10:
fetch gce_instance
| metric 'compute.googleapis.com/instance/disk/read_bytes_count'
| mul(10)
Para sumar dos series temporales, configura la consulta a fin de que recupere dos tablas de series temporales, une esos resultados y, luego, llama a la función add. En el siguiente ejemplo, se muestra una consulta que calcula la suma de la cantidad de bytes leídos y escritos en instancias de Compute Engine:
fetch gce_instance
| { metric 'compute.googleapis.com/instance/disk/read_bytes_count'
; metric 'compute.googleapis.com/instance/disk/write_bytes_count' }
| outer_join 0
| add
Para restar los recuentos de bytes escritos proporcionados por el recuento de bytes de lectura, reemplaza add por sub en la expresión anterior.
MQL usa las etiquetas en los conjuntos de tablas que se muestran en la primera y segunda recuperación para determinar cómo unir las tablas:
Si la primera tabla contiene una etiqueta que no se encuentra en la segunda, MQL no puede realizar una operación
outer_joinen las tablas y, por lo tanto, informa un error. Por ejemplo, la siguiente consulta genera un error porque la etiquetametric.instance_nameestá presente en la primera tabla, pero no en la segunda:fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' } | outer_join 0 | addUna forma de resolver este tipo de error es aplicar cláusulas de agrupación para garantizar que las dos tablas tengan las mismas etiquetas. Por ejemplo, puedes agrupar todas las etiquetas de series temporales:
fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/write_bytes_count' | group_by [] ; metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' | group_by [] } | outer_join 0 | addSi las etiquetas de las dos tablas coinciden o si la segunda tabla contiene una etiqueta que no se encuentra en la primera tabla, se permite la combinación externa. Por ejemplo, la siguiente consulta no genera un error aunque la etiqueta
metric.instance_nameesté presente en la segunda tabla y no en la primera:fetch gce_instance | { metric 'compute.googleapis.com/instance/disk/max_write_bytes_count' ; metric 'compute.googleapis.com/instance/disk/write_bytes_count' } | outer_join 0 | subUna serie temporal que se encuentra en la primera tabla puede tener valores de etiqueta que coincidan varias series temporales en la segunda tabla, por lo que MQL realiza la operación de resta para cada vinculación.
Cambio de tiempo
A veces, querrás comparar lo que sucede en el momento con lo que sucedió antes. Para permitirte comparar datos antiguos con datos actuales, MQL proporciona la operación de tabla time_shift a fin de mover datos del pasado al período actual.
Proporciones en el tiempo
La siguiente consulta usa time_shift, join y div para calcular la proporción del uso medio en cada zona entre el momento actual y la semana pasada.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by [zone], mean(val())
| {
ident
;
time_shift 1w
}
| join | div
En el siguiente gráfico, se muestra un resultado posible de esta consulta:
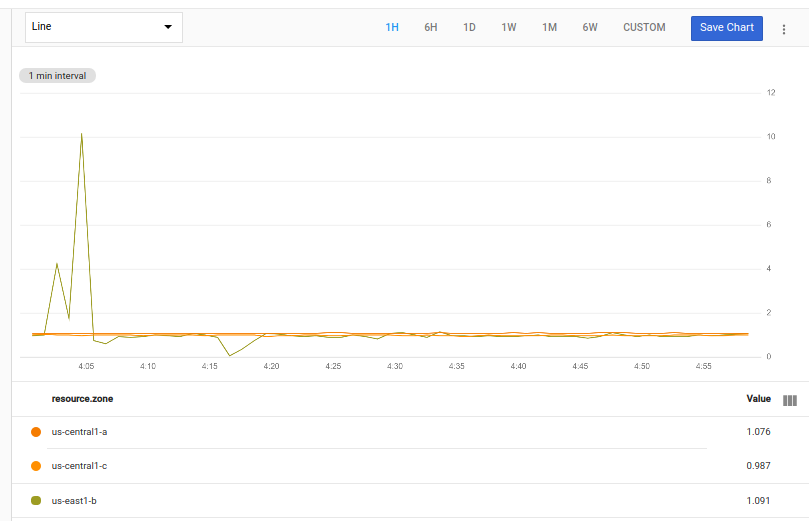
Las primeras dos operaciones recuperan la serie temporal y, luego, agrupan
de ellos, por zona, calcular los valores medios para cada uno. La tabla resultante se pasa a dos operaciones. La primera operación, ident, pasa la tabla sin modificaciones.
La segunda operación, time_shift, agrega el período (1 semana) a las marcas de tiempo de los valores de la tabla, que cambia los datos desde la semana anterior. Este cambio hace que las marcas de tiempo de los datos más antiguos en la segunda tabla se alineen con las marcas de tiempo de los datos actuales en la primera tabla.
La tabla sin cambios y la tabla desplazada en el tiempo se combinan mediante el uso de una join interna. La join produce una tabla de series temporales en la que cada punto tiene dos valores: el uso actual y el uso de hace una semana.
Luego, la consulta usa la operación div para calcular la proporción entre el valor actual y el valor de la semana anterior.
Datos anteriores y actuales
Si combinas time_shift con union, puedes crear un gráfico en el que se muestren los datos anteriores y actuales de forma simultánea. Por ejemplo, la siguiente consulta muestra el uso promedio actual y de la semana anterior. Mediante union, puedes mostrar estos dos resultados en el mismo gráfico.
fetch gce_instance::compute.googleapis.com/instance/cpu/utilization
| group_by []
| {
add [when: "now"]
;
add [when: "then"] | time_shift 1w
}
| union
En el siguiente gráfico, se muestra un resultado posible de esta consulta:
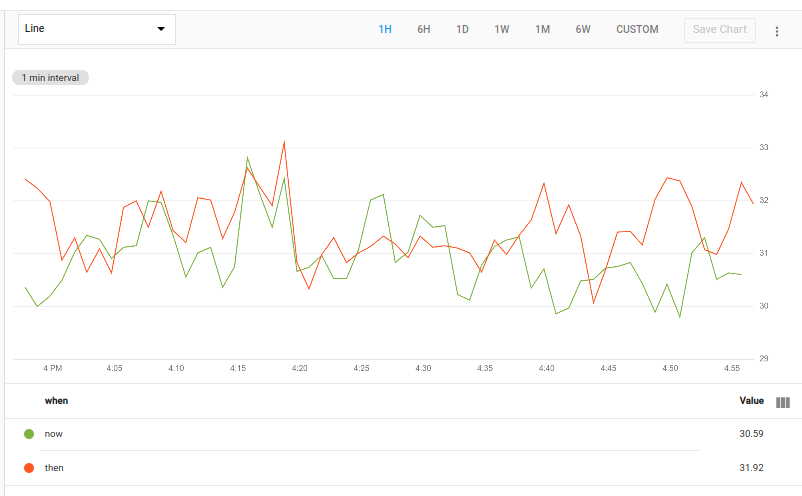
Esta consulta recupera la serie temporal y, luego, usa group_by []
para combinarlos en una sola serie temporal sin etiquetas, lo que deja
Los datos de uso de CPU. Este resultado se pasa a dos operaciones.
La primera agrega una columna para una etiqueta nueva llamada when con el valor now.
La segunda agrega una etiqueta llamada when con el valor then y pasa el resultado a la operación time_shift para cambiar los valores por una semana. Esta consulta usa el modificador del mapa add. Consulta Mapas para obtener más información.
Las dos tablas, que contienen datos para una sola serie temporal, se pasan a union, que produce una tabla que contiene las series temporales de ambas tablas de entrada.
¿Qué sigue?
Para obtener una descripción general de las estructuras del lenguaje de MQL, consulta Acerca del lenguaje de MQL.
Para obtener una descripción completa de MQL, consulta la referencia del lenguaje de consulta de Monitoring.
Para obtener información sobre cómo interactuar con gráficos, consulta Trabajo con gráficos.