本文档简要介绍了 Cloud Monitoring 提供的服务。这些服务可帮助您了解您的应用和其他 Google Cloud 服务的行为、健康状况和性能。Cloud Monitoring 会自动收集并存储大多数 Google Cloud 服务的性能信息。 您可以使用 Google Cloud Managed Service for Prometheus 收集 Prometheus 指标。如果您在 Compute Engine 虚拟机 (VM) 上安装 Ops Agent,则可以从应用和第三方应用收集指标和日志。
Cloud Monitoring 提供的提醒、测试和可视化服务可帮助您回答如下重要问题:
- 我的服务的负载情况如何?
- 我的网站是否正常响应?
- 我的服务是否表现良好?
- 我的 App Hub 应用的健康状况如何?
Cloud Monitoring 为其大多数服务提供 Google Cloud 控制台和 API 支持。某些服务还支持 Google Cloud CLI 或 Terraform。通过 Cloud Monitoring API 参考文档页面(例如,页面 alertPolicies.list),您可以试验直接从参考页面进行 API 调用。
Cloud Monitoring 服务
Cloud Monitoring 提供了不同服务,可帮助您了解您的应用以及您使用的其他 Google Cloud 服务的健康状况和性能。
突发事件和通知
如需在性能指标的值符合您定义的条件时接收通知,请创建提醒政策。提醒政策包含接收通知的人员或群组的列表。Monitoring 支持常见的通知渠道,包括邮件、Cloud Mobile App 以及 PagerDuty 或 Slack 等服务。例如,您可以创建一项提醒政策,以便在虚拟机的 CPU 利用率超过 80% 时收到通知。
每个通知都包含失败的相关信息,并包含指向突发事件的链接。突发事件是一种持久性记录,其中存储的信息可用于排查失败问题。通常,记录会列出突发事件的状态、日志链接、记录的指标数据图表、标签和时长。
提醒服务与许多 Google Cloud 服务集成。如果存在这些集成,您可能会看到一个列出建议提醒的面板,或者看到图表上有一个按钮,可让您创建提醒政策。在这两种情况下,提醒政策都是预先配置的,您只需指定要通知的人员或群组列表。
您可以使用 Google Cloud 控制台、Cloud Monitoring API、Google Cloud CLI 或 Terraform 创建和管理提醒政策。
主动监控和验证
如需测试服务、应用、网页和 API 的可用性、一致性和性能,请创建合成监控工具。例如,您可以使用拨测来探测 HTTP、HTTPS 和 TCP 端点的响应能力,然后在端点无法响应时收到通知。您还可以创建损坏的链接检查工具,以抓取网页,然后在检测到损坏的链接时通知您。
您可以使用 Google Cloud 控制台、Cloud Monitoring API、Google Cloud CLI 或 Terraform 创建和管理合成监控工具。
直观呈现数据
当您实例化 Google Cloud 资源或向 App Hub 注册应用时,信息中心服务会自动创建Google Cloud管理的信息中心。这些信息中心会显示精选信息,帮助您了解资源和应用的健康状况。例如,对于 App Hub 应用,系统会为该应用及其每项服务和工作负载创建信息中心。这些信息中心会显示应用的日志或指标数据,以及待处理提醒的数量等信息。
Google Cloud 创建的信息中心可为您提供足够的信息来完成调查。不过,这些信息中心可能无法提供查看趋势、识别离群值或查看数据的其他详细信息所需的确切数据。如需完成这些任务,您可以使用信息中心和图表服务:
如需控制要查看的数据以及这些数据的显示格式,请创建自定义信息中心。例如,您可以导入 Grafana 信息中心,也可以从模板安装信息中心。
您的自定义信息中心可以显示以下内容。
- 显示指标数据的图表和表
- 日志数据和错误组
- 提醒政策图表
- 有关提醒的信息
- 文本
- 影响系统运行的事件,例如重启或崩溃。
您可以使用Google Cloud 控制台或 API 创建和管理信息中心。
借助图表服务 Metrics Explorer,您可以快速直观地呈现和探索时序数据。通过图表设置,您可以将当前数据与之前的数据进行比较,显示离群值和百分位数,以及显示多个指标。您可以将图表保存到自定义信息中心。
数据收集和存储
Cloud Monitoring 会收集并存储以下类型的指标数据:
- 由 Google Cloud 服务生成的系统指标。这些指标提供有关服务如何运行的信息。
- Ops Agent 收集的有关在 Compute Engine 实例上运行的系统资源和应用的系统和应用指标。您可以配置 Ops Agent 以从第三方插件(例如 Apache 或 Nginx Web 服务器,或者 MongoDB 或 PostgreSQL 数据库)收集指标。
使用 Cloud Monitoring API 或使用 OpenTelemetry 等库创建的用户定义指标。
由某些开源库或第三方提供商定义的外部指标。
由 Google Cloud Managed Service for Prometheus 或使用 Ops Agent 和 Prometheus 接收器或 OTLP 接收器收集的 Prometheus 指标。
- 基于日志的指标,用于记录写入 Cloud Logging 的日志的相关数字信息。Google 定义的基于日志的指标包括服务检测到的错误数和 Google Cloud 项目接收的日志条目总数。您还可以定义基于日志的指标。
查询语言
创建提醒政策或图表时,您必须提供一个查询来描述要监控或绘制图表的数据:
Google Cloud 控制台:您可以通过从菜单中进行选择来构建查询,也可以编写查询。查询编辑器适用于 Prometheus Query Language (PromQL)。查询编辑器提供语法检查和建议。您还可以编写 Monitoring 过滤条件表达式。
Cloud Monitoring API:此 API 支持 Prometheus Query Language (PromQL) 和 Monitoring 过滤条件表达式。
监控大型系统
本部分介绍了如何以集合形式管理资源,以及如何监控存储在多个 Google Cloud 项目中的指标。
以集合的形式管理资源
如需以集合形式管理资源,而不是分别管理,请创建资源组。资源组是资源的动态集合,满足您提供的部分条件。在添加和移除资源时(例如,通过将 Compute Engine 虚拟机实例添加到Google Cloud 项目),资源组中的成员资格会自动更改。以下是资源组的示例:
- 名称以字符串
prod-开头的 Compute Engine 实例。 - 带有
test-cluster标记的资源。 - 区域 A 或区域 B 中的 Amazon EC2 实例。
定义资源组后,您可以将组当作单个资源进行监控。例如,您可以配置拨测来监控资源组。对于图表和提醒政策,您还可以根据群组名称进行过滤。
如需了解详情,请参阅配置资源组。
监控多个 Google Cloud 项目的指标
如需通过一个界面查看和监控多个Google Cloud 项目和 AWS 账号的时序数据,请配置多项目指标范围。
默认情况下, Google Cloud 控制台中的 Cloud Monitoring 页面仅提供对存储在范围限定项目中的时序的访问权限。范围限定项目是您使用Google Cloud 控制台项目选择器选择的项目。范围限定项目用于存储您配置的提醒、合成监控工具、信息中心和监控组。
范围界定项目还托管一个指标范围。指标范围定义了其指标对于范围界定项目可见的项目和账号。您可以将指标范围配置为包含来自其他 Google Cloud 项目和来自 AWS 账号的时序数据。如需了解如何修改指标范围,请参阅为多个项目配置指标范围。
Cloud Monitoring 数据模型
本部分介绍 Cloud Monitoring 数据模型:
指标类型用于描述测量的内容。指标类型示例包括虚拟机的 CPU 利用率和已使用的磁盘百分比。
时间序列是一种数据结构,包含指标的带时间戳的测量结果以及关于这些测量结果的来源和含义的信息。
以下是有关时间序列所含内容的一些详细信息:
points数组包含带有时间戳的测量结果。以下是包含两个值的
points数组的示例:"points": [ { "interval": { "startTime": "2020-07-27T20:20:21.597143Z", "endTime": "2020-07-27T20:20:21.597143Z" }, "value": { "doubleValue": 0.473005 } }, { "interval": { "startTime": "2020-07-27T20:19:21.597239Z", "endTime": "2020-07-27T20:19:21.597239Z" }, "value": { "doubleValue": 0.473025 } }, ],如需了解值的含义,您需要参考时间序列中包含的其他数据以及这些数据的定义。
resource字段描述了受监控的硬件或软件组件。在 Cloud Monitoring 中,硬件或软件组件称为受监控的资源。受监控资源的示例包括 Compute Engine 实例和 App Engine 应用。如需查看受监控的资源列表,请参阅受监控的资源列表。以下是
resource字段的示例:"resource": { "type": "gce_instance", "labels": { "instance_id": "2708613220420473591", "zone": "us-east1-b", "project_id": "sampleproject" } }type字段将受监控的资源列为gce_instance,这表示这些测量是在 Compute Engine 虚拟机实例上进行的。labels字段包含键值对,用于提供受监控的资源的其他信息。对于gce_instance类型,这些标签标识了受监控的虚拟机实例。
metric字段描述了要测量的内容。以下是
metric字段的示例:"metric": { "labels": { "instance_name": "test" }, "type": "compute.googleapis.com/instance/cpu/utilization" },- 对于 Google Cloud 服务,
type字段指定服务和受监控的资源。在此示例中,Compute Engine 服务用于衡量 CPU 利用率。如果type字段以custom或external开头时,则该指标是自定义指标或第三方定义的指标。
labels字段包含键值对,用于提供有关测量的其他信息。这些标签被定义为MetricDescriptor(即用于定义测量数据属性的资料结构)的一部分。指标compute.googleapis.com/instance/cpu/utilization的MetricDescriptor包含标签instance_name。
- 对于 Google Cloud 服务,
metricKind字段描述了时间序列中相邻测量之间的关系:GAUGE指标用于存储在给定时间测量的事物值,例如每小时温度记录。CUMULATIVE指标会存储给定时刻(例如车辆中的里程表)测量的事物累计值。DELTA指标会存储指定时间段内所测量事物值的变化,例如,显示股票收益或损失的股票摘要。
valueType字段描述测量的数据类型:INT64、DOUBLE、BOOL、STRING或DISTRIBUTION。
- 您可以显示每个虚拟机实例的 CPU 利用率。
- 您可以过滤
instance_id标签的单个值的时序,以显示特定虚拟机实例的 CPU 利用率。 您可以按
machine_type标签根据虚拟机实例进行分组,然后显示平均 CPU 利用率。以下屏幕截图显示了采用此配置的图表: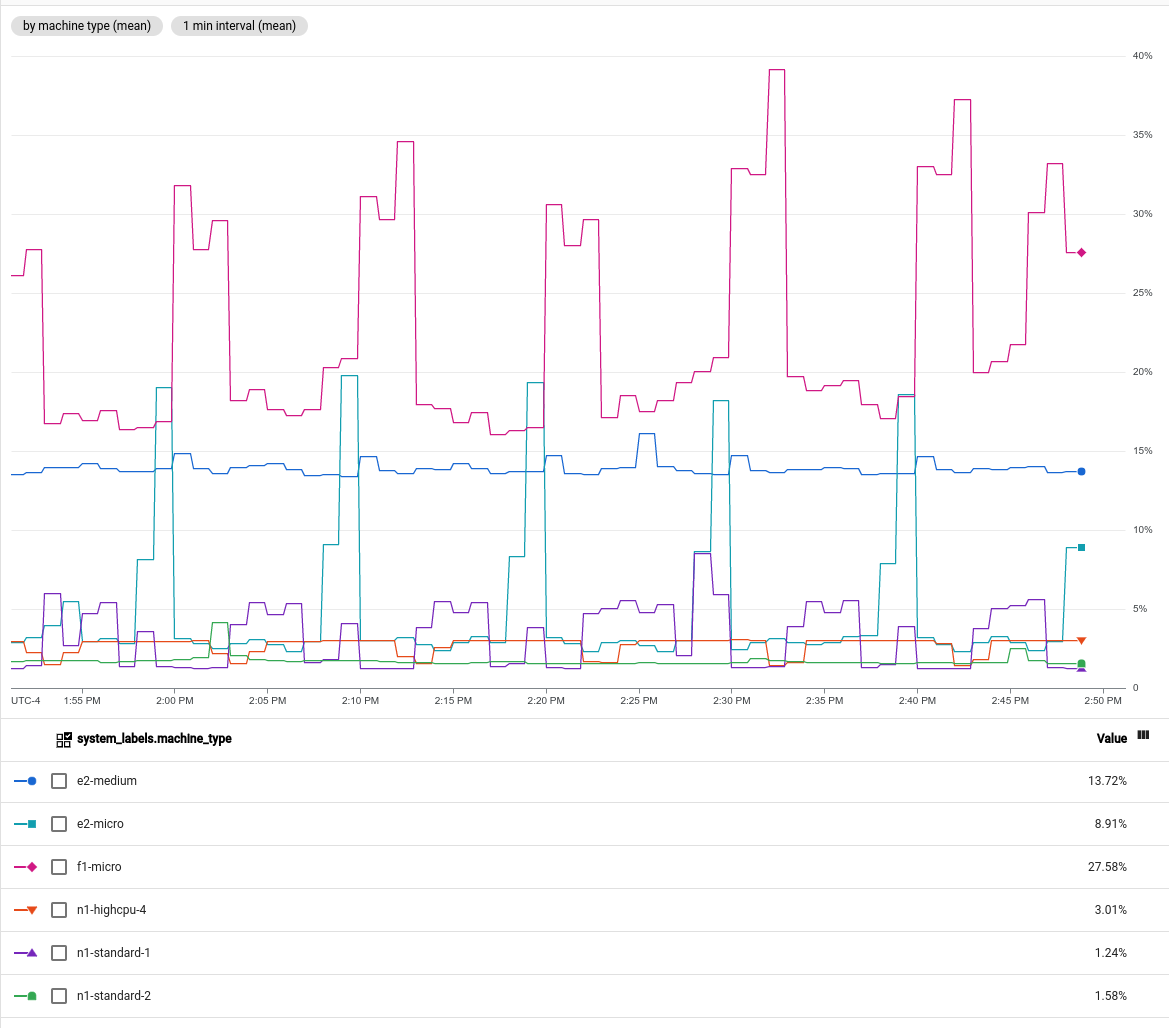
价格
一般而言,Cloud Monitoring 系统指标是免费的,而来自外部系统、代理或应用的指标则需要付费。可结算的指标按注入的字节数或样本数计费。
如需了解详情,请参阅 Google Cloud Observability 价格页面中的 Cloud Monitoring 部分。
后续步骤
- 如需探索 Cloud Monitoring,请参阅监控 Compute Engine 实例的快速入门。
- 如需了解如何配置 Google Cloud 项目以查看多个 Google Cloud 项目和 AWS 账号的指标,请参阅指标范围概览。