In diesem Dokument werden die Ereignistypen beschrieben, die in Diagrammen als Anmerkungen angezeigt werden können. Ein Ereignis ist eine Aktivität wie ein Neustart oder ein Absturz, die sich auf den Betrieb eines Systems auswirkt. Wenn Sie Ereignisse anzeigen, können Sie bei der Fehlerbehebung Daten aus verschiedenen Quellen leichter in Beziehung setzen.
Für jedes Ereignis werden Links zu Referenzen oder Dokumentationen zur Fehlerbehebung sowie Informationen zur Abfrage des Ereignisses bereitgestellt. Wenn beispielsweise Ereignisse durch die Analyse Ihrer Protokolle erkannt werden, wird eine Abfrage bereitgestellt, die für den Log-Explorer oder für eine protokollbasierte Benachrichtigungsrichtlinie geeignet ist.
Wenn Sie Ihren Diagrammen Anmerkungen hinzufügen möchten, konfigurieren Sie das Dashboard oder den Tab, auf dem das Diagramm angezeigt wird. So können Sie beispielsweise die meisten Dashboards, die auf der Seite Dashboards der Google Cloud Console aufgeführt sind, so konfigurieren, dass Ereignisse angezeigt werden. Ebenso können Sie einige dienstspezifische Beobachtbarkeits-Tabs wie die für die Compute Engine und die Google Kubernetes Engine so konfigurieren, dass Ereignisse angezeigt werden. Informationen zur Konfiguration finden Sie unter Ereignisse in einem Dashboard anzeigen.
Der folgende Screenshot zeigt ein Diagramm mit mehreren Ereignissen, die durch die Analyse von Protokolleinträgen ermittelt wurden, und einem Ereignis zur Dienstgesundheit:
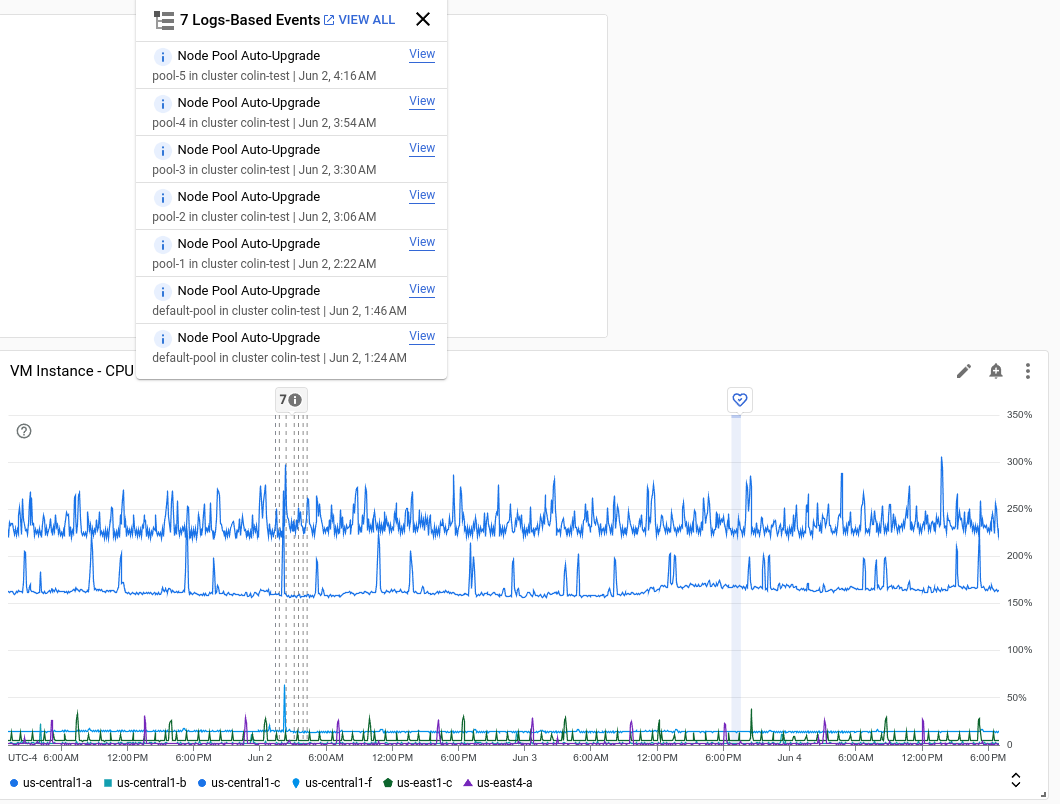
Jede Anmerkung kann mehrere Ereignisse enthalten. Im vorherigen Screenshot ist ein Ereignis für eine GKE-Bereitstellung aufgeführt.
Benachrichtigungsereignistypen
In diesem Abschnitt werden die Benachrichtigungsereignistypen beschrieben, die in einem Dashboard angezeigt werden können.
Benachrichtigung geöffnet
Mithilfe von Ereignissen für geöffnete Benachrichtigungen können Sie Ihre Diagrammdaten mit dem Zeitpunkt der Eröffnung von Vorfällen in Beziehung setzen. Ein Ereignis vom Typ „Benachrichtigung geöffnet“ wird angezeigt, wenn Folgendes zutrifft:
- Der entsprechende Fall wurde im im Dashboard angegebenen Zeitraum geöffnet.
- Der entsprechende Fall ist nicht geschlossen.
Für Vorfälle, die außerhalb des im Dashboard angegebenen Zeitraums geöffnet wurden, werden keine Anmerkungen gemacht und sie werden nicht angezeigt. Ebenso wird kein Ereignis vom Typ „Benachrichtigung geöffnet“ angezeigt, wenn der entsprechende Vorfall innerhalb des im Dashboard angegebenen Zeitraums geöffnet und dann geschlossen wurde.
Die Kurzinfo zu einem Ereignis vom Typ „Geöffnete Benachrichtigung“ enthält Folgendes:
- Name der Benachrichtigungsrichtlinie.
- Zusammenfassungsinformationen, sofern verfügbar. Dazu gehören beispielsweise der Grenzwert und der Messwert.
- Dauer des Vorfalls sowie Datum und Uhrzeit, zu der der Vorfall geöffnet wurde.
- Messwert- und Ressourcenlabels In der Kurzinfo werden möglicherweise nicht alle Labels angezeigt.
- Eine Schaltfläche Anzeigen, über die die Seite Details für den Vorfall geöffnet wird.
Google Kubernetes Engine-Ereignistypen
In diesem Abschnitt werden die Google Kubernetes Engine-Ereignistypen beschrieben, die in einem Dashboard angezeigt werden können.
Gepatchte oder aktualisierte GKE-Arbeitslast
Dieser Ereignistyp hilft Ihnen bei der Behebung von Problemen mit GKE-Arbeitslast-Deployments oder StatefulSet-Änderungen, da diese Ereignisse mit Leistungsregressionen oder anderen Leistungsproblemen in Verbindung stehen können. Dieser Ereignistyp wird angezeigt, wenn eine Arbeitslast erstellt, aktualisiert oder gelöscht wird.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
Weitere Informationen finden Sie unter Übersicht über die Bereitstellung von Arbeitslasten und Beobachtbarkeitsmesswerte aufrufen.
Absturz eines GKE-Pods
Mit diesem Ereignistyp können Sie GKE-Pod-Abstürze ermitteln und beheben. Pod-Abstürze können durch erschöpften Arbeitsspeicher oder einen Anwendungsfehler verursacht werden. Dieser Ereignistyp wird angezeigt, wenn eines der folgenden Ereignisse eintritt:
- Pod-Status ist
CrashLoopBackoff - Der Pod wird mit einem Exit-Code ungleich null beendet.
- Der Pod wird aufgrund von fehlendem Arbeitsspeicher beendet.
- Der Pod wird entfernt.
- Die Bereitschafts-/Aktivitätsprüfung schlägt fehl.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
Informationen zur Fehlerbehebung finden Sie unter Fehlerbehebung: CrashLoopBackOff.
GKE-Pod konnte nicht geplant werden
Mit diesem Ereignistyp können Sie Pods identifizieren, die nicht auf einem Knoten geplant werden können, und Probleme beheben. Dieser Ereignistyp wird angezeigt, wenn die Pod-Planung aus einem der folgenden Gründe fehlschlägt:
- Unzureichende CPU des Knotens.
- Unzureichender Knotenspeicher.
- Keine Knoten für Markierungen oder Toleranzen.
- Knoten, bei denen das maximale Pod-Limit erreicht ist.
- Der Knotenpool hat die maximale Größe erreicht.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
Informationen zur Fehlerbehebung finden Sie unter Fehlerbehebung: Pod kann nicht geplant werden.
Fehler beim Erstellen eines GKE-Containers
Mit diesem Ereignistyp können Sie Fehler beim Erstellen eines GKE-Containers ermitteln und beheben. Gründe hierfür können fehlgeschlagene Volume-Bereitstellungen oder Fehler beim Abrufen von Images sein.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
Informationen zur Fehlerbehebung bei Image-Pulls finden Sie unter Fehlerbehebung bei Image-Pulls.
Pod-Autoscaling – Hoch- und Herunterskalieren
Dieses Ereignis gibt Aufschluss über Neuanpassungen des horizontalen Pod-Autoscalings, bei denen die Anzahl der laufenden Pods für eine Arbeitslast erhöht oder verringert wird. Weitere Informationen finden Sie unter Horizontales Pod-Autoscaling.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
Cluster Autoscaler hoch- und herunterskalieren
Anhand dieses Ereignisses können Sie nachvollziehen, wann die Anzahl der Knoten in einem Knotenpool Ihres Clusters von Cluster Autoscaler hoch- oder herunterskaliert wird. Weitere Informationen finden Sie unter Cluster-Autoscaling und Cluster-Autoscaling-Ereignisse ansehen.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
Cluster erstellen und löschen
Dieses Ereignis verfolgt das Erstellen und Löschen von GKE-Clustern. Weitere Informationen finden Sie unter Autopilot-Cluster erstellen, Zonalen Cluster erstellen und Cluster löschen.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
Clusterupdate
Dieses Ereignis verfolgt GKE-Clusterupdates. Zu Aktualisierungen gehören automatische und manuelle Versionsupgrades der Steuerungsebene sowie Änderungen der Clusterkonfiguration. Weitere Informationen finden Sie unter Manuelles Upgrade eines Clusters oder Knotenpools und Standardcluster-Upgrades.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
Knotenpoolupdate
Dieses Ereignis verfolgt Updates von GKE-Knotenpools. Zu Aktualisierungen gehören automatische und manuelle Versionsupgrades von Knotenpools sowie Konfigurationsänderungen und Größenanpassungen. Weitere Informationen finden Sie unter Manuelles Upgrade eines Clusters oder Knotenpools und Standardcluster-Upgrades.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Cloud Run-Ereignistypen
In diesem Abschnitt werden die Cloud Run-Ereignistypen beschrieben, die in einem Dashboard angezeigt werden können.
Cloud Run-Bereitstellung
Mit diesem Ereignistyp können Sie Cloud Run-Bereitstellungsfehler erkennen und beheben. Die Bereitstellung kann aus verschiedenen Gründen fehlschlagen, z. B. aufgrund eines gelöschten Dienstkontos, falscher Berechtigungen, eines fehlgeschlagenen Containers oder eines fehlgeschlagenen Containers.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
Informationen zur Fehlerbehebung finden Sie unter Fehlerbehebung: Probleme mit Cloud Run.
Cloud SQL-Ereignistypen
In diesem Abschnitt werden die Cloud SQL-Ereignistypen beschrieben, die in einem Dashboard angezeigt werden können.
Cloud SQL-Failover
Mit diesem Ereignistyp können Sie erkennen, wann manuelle oder automatische Failover auftreten. Ein Failover tritt auf, wenn eine Instanz oder Zone ausfällt und die Standby-Instanz zur neuen primären Instanz wird. Während eines Failovers schaltet Cloud SQL automatisch auf die Bereitstellung von Daten aus der Standby-Instanz um.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
Weitere Informationen finden Sie unter Hochverfügbarkeit.
Cloud SQL starten oder beenden
Mit diesem Ereignistyp können Sie feststellen, ob eine Cloud SQL-Instanz manuell gestartet, beendet oder neu gestartet wurde. Wenn eine Instanz beendet wird, werden auch alle Verbindungen, geöffneten Dateien und laufenden Vorgänge beendet.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
Weitere Informationen finden Sie unter Hochverfügbarkeit und Instanzen starten, beenden und neu starten.
Cloud SQL-Speicher
Mit diesem Ereignistyp können Sie Ereignisse im Zusammenhang mit dem Cloud SQL-Speicher identifizieren, z. B. wenn der Datenbankspeicher voll ist und wenn eine Datenbank aufgrund ausgeschöpfter Speicherkapazität heruntergefahren wird. Datenbanken mit ausgeschöpfter Speicherkapazität und ohne aktivierte automatische Speichererhöhung werden möglicherweise heruntergefahren, um Datenbeschädigungen zu vermeiden.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Compute Engine-Ereignistypen
In diesem Abschnitt werden die Compute Engine-Ereignistypen beschrieben, die in einem Dashboard angezeigt werden können.
Beendigung von virtuellen Maschinen
Mit diesem Ereignistyp können Sie Beendigungen von virtuellen Maschinen (VMs) identifizieren, einschließlich manuell ausgelöster Zurücksetzungen und Stopps, Beendigungen von Gastbetriebssystemen, Wartungsbeendigungen und Hostfehlern.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
Weitere Informationen finden Sie unter VM beenden und starten und Fehler beim Herunterfahren und Neustarten von VMs beheben.
Start der VM-Instanz fehlgeschlagen
Dieses Ereignis verfolgt Fehler beim Starten von Compute Engine-VM-Instanzen. Es zeigt fehlgeschlagene Starts an, die auf Ressourcenmangel, aufgebrauchte IP-Bereiche, überschrittene Kontingente oder Shielded VM-Integritätsfehler zurückgehen.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
Fehler beim Gastbetriebssystem der VM-Instanz
Mit diesem Ereignis werden bestimmte Gastbetriebssystemfehler der Compute Engine-VM-Instanz erfasst, wie in den Logs der seriellen Konsole aufgezeichnet. Zu den erfassten Fehlern gehören volles Laufwerk, fehlerhafte Dateisystembereitstellung sowie Startfehler, durch die der Linux-Notfallmodus aktiviert wird.
Damit diese Ereignisse sichtbar sind, müssen Sie das Logging für die Ausgabe des seriellen Ports in Cloud Logging aktivieren. Dazu legen Sie in den VM- oder Projektmetadaten serial-port-logging-enable=true fest. Weitere Informationen finden Sie unter Protokollierung der seriellen Portausgabe aktivieren und deaktivieren.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
Aktualisierung einer verwalteten Instanzgruppe
Anhand dieses Ereignistyps können Sie feststellen, wann Ihre verwaltete Instanzgruppe aktualisiert wurde. Beispielsweise wurden VMs hinzugefügt oder entfernt oder die Größe wurde aktualisiert. Weitere Informationen finden Sie unter Aktualisierungen der VM-Konfiguration in einer MIG automatisch anwenden.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
Weitere Informationen finden Sie unter Mit verwalteten Instanzen arbeiten und Fehlerbehebung bei verwalteten Instanzgruppen.
Autoscaling für verwaltete Instanzgruppen
Dieses Ereignis verfolgt Skalierungsentscheidungen des Autoscalings einer verwalteten Instanzgruppe. Dazu können Änderungen an der empfohlenen Größe einer verwalteten Instanzgruppe oder eine Statusänderung des Autoscalings selbst gehören. Weitere Informationen finden Sie unter Autoscaling von Instanzgruppen.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Ereignistypen für Personalized Service Health
In diesem Abschnitt werden die Typen der personalisierten Dienststatusinformationen beschrieben, die in einem Dashboard angezeigt werden können.
Google Cloud Vorfall
Bei der Fehlerbehebung sollten Sie zwischen Fehlern unterscheiden, die durch einen von Ihnen genutzten Dienst verursacht werden, und solchen, die durch einen von Ihnen genutztenGoogle Cloud Dienst verursacht werden. Wenn Sie Anmerkungen zu Personalized Service Health in einem Dashboard aktivieren, können Sie sich Störungen oder Dienststatusereignisse für Google Cloud -Dienste ansehen. Eine Liste der Dienste, die in den Dienststatus eingebunden sind, finden Sie unter Unterstützte Google-Produkte.
Im Gegensatz zu anderen Ereignistypen werden Google Cloud Vorfälle nicht durch die Analyse Ihrer Protokolleinträge erkannt. Wenn Sie benachrichtigt werden möchten, wenn diese Ereignisse eintreten, erstellen Sie eine Benachrichtigungsrichtlinie. Sie können eine vorkonfigurierte Benachrichtigungsrichtlinie auswählen, indem Sie die Optionen auf der Seite Dashboard zur Dienstbereitschaft verwenden. Weitere Informationen finden Sie unter Kurzanleitung: Benachrichtigung einrichten.
Beim Monitoring werden Google Cloud Vorfälle identifiziert, indem eine Anfrage an die Service Health API gesendet und die Antwort dann auf Vorfälle gefiltert wird, die für die Daten relevant sind, die Sie sich ansehen. Die Anfrage hat folgende Konfiguration:
Die Aufzählung
Relevanceist aufRELATED,IMPACTEDoderPARTIALLY_RELATEDfestgelegt. Durch diese Einschränkung werden in Ihrem Dashboard nur Ereignisse für die Google Cloud Dienste angezeigt, die in IhremGoogle Cloud Projekt verwendet werden.Die Aufzählung
DetailedStateist nicht aufFALSE_POSITIVEfestgelegt.
Anmerkungen zur Dienstbereitschaft werden mit einem Startzeitpunkt und einer Dauer angezeigt. Die Dauer wird durch Ändern der Hintergrundfarbe des Diagramms angezeigt. In der Kurzinfo zu einem Google Cloud -Vorfall werden folgende Informationen angezeigt:
- Der Google Cloud -Dienst.
- Ob der Vorfall offen oder geschlossen ist.
- Datum und Startzeit der Veranstaltung.
- Chips, die die Anzahl der betroffenen Produkte und Standorte anzeigen. Wenn Sie die betroffenen Produkte oder Standorte auflisten möchten, bewegen Sie den Mauszeiger auf den entsprechenden Chip.
- Die Schaltfläche Anzeigen, über die die Detailseite für den Vorfall geöffnet wird.
Informationen zum Senden einer Anfrage an die Service Health API finden Sie unter Mit der Service Health API auf Unterbrechungen prüfen.
Informationen zur Fehlerbehebung finden Sie unter Häufige Probleme im Bereich „Dienststatus“ beheben.
Ereignistypen der Verfügbarkeitsdiagnose
In diesem Abschnitt werden die Ereignistypen für die Verfügbarkeitsdiagnose beschrieben, die in einem Dashboard angezeigt werden können.
Fehler bei Verfügbarkeitsdiagnose
Mit diesem Ereignistyp können Sie Fehler bei Verfügbarkeitsdiagnosen für konfigurierte Regionen ermitteln.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
Informationen zur Fehlerbehebung finden Sie unter Fehlerbehebung bei synthetischen Monitoren und Verfügbarkeitsdiagnosen.
Ereignistypen für Agent für SAP
In diesem Abschnitt werden die Agent for SAP-Ereignistypen beschrieben, die in einem Dashboard angezeigt werden können.
SAP-Verfügbarkeit
Mit diesem Ereignistyp können Sie Ereignisse im Zusammenhang mit der Verfügbarkeit von Agent for SAP erkennen. Diese Ereignisse werden ausgelöst, wenn sich die Verfügbarkeit von SAP HANA, SAP NetWeaver oder Pacemaker-Clustern ändert.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
SAP Backint
Mit diesem Ereignistyp können Sie Ereignisse im Zusammenhang mit Agent for SAP-Backint identifizieren. Bei jeder Backint-Sicherung oder ‑Wiederherstellung wird ein Ereignis mit Details zur erfolgreichen oder fehlgeschlagenen Ausführung und den Übertragungsstatistiken geschrieben. Logsicherungen und ‑wiederherstellungen werden nur im Fehlerfall angezeigt, während Datensicherungen und ‑wiederherstellungen sowohl bei erfolgreicher als auch fehlgeschlagener Ausführung zu sehen sind.
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
SAP-Betrieb
Mit diesem Ereignistyp können Sie Ereignisse im Zusammenhang mit Agent for SAP-Vorgängen identifizieren. Diese Ereignisse werden ausgelöst, wenn sich der Status der SAP HANA-Replikation ändert.
Wenn Sie für diesen Ereignistyp eine logbasierte Benachrichtigungsrichtlinie erstellen möchten, verwenden Sie die folgende Abfrage:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
Nächste Schritte
Informationen dazu, wie Sie Ereignisse in Ihren Dashboards anzeigen, finden Sie unter Ereignisse in einem Dashboard anzeigen.