Este documento descreve os tipos de eventos que podem ser apresentados como anotações em gráficos. Um evento é uma atividade, como um reinício ou uma falha de sistema, que afeta o funcionamento de um sistema. A apresentação de eventos pode ajudar a correlacionar dados de diferentes origens quando estiver a resolver um problema.
Para cada evento, são fornecidos links para referências ou documentação de resolução de problemas, juntamente com informações sobre como consultar o evento. Por exemplo, quando os eventos são identificados através da análise dos seus registos, é fornecida uma consulta adequada para utilização com o Explorador de registos ou com uma política de alertas baseada em registos.
Para adicionar anotações aos gráficos, configure o painel de controlo ou o separador que apresenta o gráfico. Por exemplo, pode configurar a maioria dos painéis de controlo apresentados na página Painéis de controlo da consola Google Cloud para mostrar eventos. Da mesma forma, pode configurar alguns separadores de Observabilidade específicos do serviço, como os do Compute Engine e do Google Kubernetes Engine, para mostrar eventos. Para informações de configuração, consulte o artigo Mostrar eventos num painel de controlo.
A captura de ecrã seguinte ilustra um gráfico que mostra vários eventos que foram identificados através da análise de entradas do registo e um evento de estado de funcionamento do serviço:
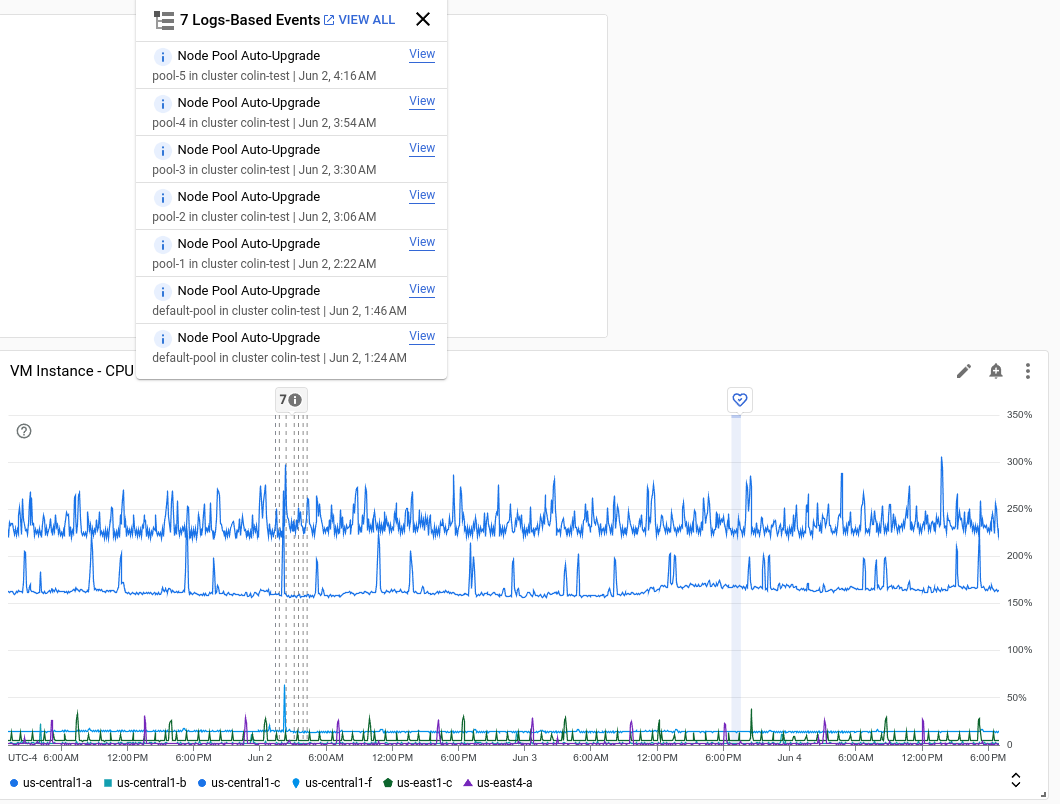
Cada anotação pode apresentar vários eventos. Na captura de ecrã anterior, é apresentado um evento para uma implementação do GKE.
Tipos de eventos de alerta
Esta secção descreve os tipos de eventos de alerta que podem ser apresentados num painel de controlo.
Alerta aberto
Os eventos de alerta aberto ajudam a correlacionar os dados representados em gráficos com o momento em que os incidentes foram abertos. Um evento de alerta aberto é apresentado quando as seguintes condições são verdadeiras:
- O incidente correspondente foi aberto durante o intervalo de tempo especificado pelo painel de controlo.
- O incidente correspondente não está fechado.
Não são apresentadas anotações feitas para incidentes que foram abertos fora do intervalo de tempo especificado pelo painel de controlo. Da mesma forma, um evento de alerta aberto não é apresentado quando o incidente correspondente foi aberto e, em seguida, fechado no intervalo de tempo especificado pelo painel de controlo.
A sugestão de um evento de alerta aberto inclui o seguinte:
- Nome da política de alerta.
- Informações de resumo, quando estas informações estão disponíveis. Por exemplo, estas informações podem incluir o limite e o valor medido.
- A duração do incidente e a data e a hora em que o incidente foi aberto.
- Etiquetas de métricas e recursos. A sugestão pode não apresentar todas as etiquetas.
- Um botão Ver, que abre a página Detalhes do incidente.
Tipos de eventos do Google Kubernetes Engine
Esta secção descreve os tipos de eventos do Google Kubernetes Engine que podem ser apresentados num painel de controlo.
Carga de trabalho do GKE corrigida ou atualizada
Este tipo de evento ajuda a resolver problemas de implementação de cargas de trabalho do GKE ou alterações de conjuntos com estado, uma vez que estes eventos podem estar correlacionados com regressões de desempenho ou outros problemas de desempenho. Este tipo de evento é apresentado quando uma carga de trabalho é criada, atualizada ou eliminada.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
Para mais informações, consulte os artigos Vista geral da implementação de cargas de trabalho e Ver métricas de observabilidade.
Falha de um pod do GKE
Este tipo de evento ajuda a identificar e resolver problemas de falhas de pods do GKE. As falhas de pods podem ser causadas por esgotamento da memória ou por um erro da aplicação. Este tipo de evento é apresentado quando ocorre qualquer uma das seguintes situações:
- O estado do agrupamento é
CrashLoopBackoff - O agrupamento termina com um código de saída diferente de zero.
- O agrupamento termina com uma condição de falta de memória.
- O pod é removido.
- As sondas de disponibilidade/atividade falham.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
Para obter informações de resolução de problemas, consulte o artigo Resolução de problemas: CrashLoopBackOff.
Falha ao agendar um pod do GKE
Este tipo de evento ajuda a identificar e resolver problemas quando não é possível agendar pods num nó. Este tipo de evento é apresentado quando o agendamento de pods falha por qualquer um dos seguintes motivos:
- CPU do nó insuficiente.
- Memória do nó insuficiente.
- Nenhum nó para taints ou tolerations.
- Nós no limite máximo de agrupamentos.
- O conjunto de nós está no tamanho máximo.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
Para obter informações de resolução de problemas, consulte o artigo Resolução de problemas: não é possível agendar o pod.
Falha ao criar um contentor do GKE
Este tipo de evento ajuda a identificar e resolver problemas de falhas na criação de um contentor do GKE. A criação do contentor pode falhar devido a motivos como montagens de volume ou obtenções de imagens falhadas.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
Para informações de resolução de problemas sobre a obtenção de imagens, consulte o artigo Resolva problemas de obtenção de imagens.
Aumente e diminua a escala do redimensionador automático de pods
Este evento dá-lhe visibilidade sobre os redimensionamentos da escala automática horizontal de pods, que aumentam ou diminuem o número de pods em execução para uma carga de trabalho. Para mais informações, consulte o artigo Escala automática horizontal de pods.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
Aumente e diminua a escala do redimensionador automático de clusters
Este evento dá-lhe visibilidade sobre quando o redimensionador automático de clusters aumenta ou diminui o número de nós num conjunto de nós do seu cluster. Para mais informações, consulte o artigo Acerca do redimensionamento automático de clusters e o artigo Ver eventos do redimensionador automático de clusters.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
Criação e eliminação de clusters
Este evento acompanha as ações de criação e eliminação de clusters do GKE. Para mais informações, consulte os artigos Crie um cluster do Autopilot, Crie um cluster zonal e Elimine um cluster.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
Atualização do cluster
Este evento acompanha as atualizações do cluster do GKE. As atualizações incluem atualizações automáticas da versão do plano de controlo, bem como atualizações manuais e alterações à configuração do cluster. Para mais informações, consulte os artigos Atualizar manualmente um cluster ou um conjunto de nós e Atualizações de clusters padrão.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
Atualização do node pool
Este evento acompanha as atualizações do node pool do GKE. As atualizações incluem atualizações automáticas da versão do node pool, bem como atualizações manuais, alterações de configuração e redimensionamentos. Para mais informações, consulte os artigos Atualizar manualmente um cluster ou um conjunto de nós e Atualizações de clusters padrão.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Tipos de eventos do Cloud Run
Esta secção descreve os tipos de eventos do Cloud Run que podem ser apresentados num painel de controlo.
Implementação do Cloud Run
Este tipo de evento ajuda a identificar e resolver problemas de falhas de implementação do Cloud Run. A implementação pode falhar devido a motivos como a eliminação da conta de serviço, autorizações incorretas, falha na importação de um contentor ou falha no início de um contentor.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
Para ver informações de resolução de problemas, consulte o artigo Resolução de problemas: problemas do Cloud Run.
Tipos de eventos do Cloud SQL
Esta secção descreve os tipos de eventos do Cloud SQL que podem ser apresentados num painel de controlo.
Comutação por falha do Cloud SQL
Este tipo de evento ajuda a identificar quando ocorrem failovers manuais ou automáticos. Uma alternativa ocorre quando existe uma falha de instância ou zona e a instância de reserva torna-se a nova instância principal. Durante uma comutação por falha, o Cloud SQL muda automaticamente para o fornecimento de dados a partir da instância de reserva.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
Para mais informações, consulte o artigo Acerca da elevada disponibilidade.
Início ou paragem do Cloud SQL
Este tipo de evento ajuda a identificar se uma instância do Cloud SQL foi iniciada, parada ou reiniciada manualmente. Quando uma instância é parada, todas as ligações, os ficheiros abertos e as operações em execução também são parados.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
Para mais informações, consulte os artigos Acerca da elevada disponibilidade e Inicie, pare e reinicie instâncias.
Armazenamento do Cloud SQL
Este tipo de evento ajuda a identificar eventos relacionados com o armazenamento do Cloud SQL, incluindo quando o armazenamento da base de dados está cheio e quando uma base de dados é encerrada devido ao facto de ter atingido a capacidade de armazenamento. As bases de dados com capacidade de armazenamento total e sem o armazenamento automático ativado podem ser encerradas para evitar a corrupção de dados.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Tipos de eventos do Compute Engine
Esta secção descreve os tipos de eventos do Compute Engine que podem ser apresentados num painel de controlo.
Encerramentos de máquinas virtuais
Este tipo de evento ajuda a identificar encerramentos de máquinas virtuais (VM), incluindo repetições e paragens acionadas manualmente, encerramentos do SO convidado, encerramento de manutenção e erros do anfitrião.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
Para mais informações, consulte os artigos Pare e inicie uma VM e Resolução de problemas de encerramentos e reinícios de VMs.
Falha ao iniciar a instância de VM
Este evento monitoriza as falhas de início de instâncias de VM do Compute Engine. O evento mostra falhas de início devido a ruturas de stock, esgotamento do espaço de IP, quota excedida ou erros de integridade da VM protegida.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
Erro do SO convidado da instância de VM
Este evento acompanha erros específicos do SO convidado da instância de VM do Compute Engine, conforme registados nos registos da consola série. Os erros monitorizados são disco cheio, falha na montagem do sistema de ficheiros e falhas de arranque que ativam o modo de emergência do Linux.
Para que estes eventos sejam visíveis, tem de ativar o registo de saída da porta série no Cloud Logging definindo serial-port-logging-enable=true na VM ou nos metadados do projeto. Para mais informações, consulte o artigo
Ativar e desativar o registo de saída da porta série.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
Atualização do grupo de instâncias geridas
Este tipo de evento ajuda a identificar quando o seu grupo de instâncias geridas (MIG) foi atualizado. Por exemplo, foram adicionadas ou removidas VMs, ou o limite de tamanho foi atualizado. Para mais informações, consulte o artigo Aplique automaticamente atualizações de configuração de VMs num MIG.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
Para mais informações, consulte os artigos Trabalhe com instâncias geridas e Resolução de problemas de grupos de instâncias geridas.
Redimensionador automático de grupos de instâncias geridas
Este evento acompanha as decisões de escalabilidade tomadas pelo escalador automático de um MIG. Estas decisões podem incluir alterações no tamanho recomendado para um MIG ou uma alteração no estado do escalador automático. Para mais informações, consulte o artigo Grupos de escalamento automático de instâncias.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Tipos de eventos do Personalized Service Health
Esta secção descreve os tipos de Personalized Service Health que podem ser apresentados num painel de controlo.
Google Cloud incident
Quando estiver a resolver problemas, pode querer distinguir entre falhas causadas por um serviço que lhe pertence e falhas causadas por umGoogle Cloud serviço que usa. Quando ativa as anotações do Personalized Service Health num painel de controlo, pode ver interrupções ou eventos de estado do serviço para os serviços do Google Cloud. Google Cloud Para ver uma lista de serviços integrados com o estado do serviço, consulte os produtos Google suportados.
Ao contrário de outros tipos de eventos,os Google Cloud incidentes não são identificados através da análise das entradas de registo. Se quiser receber uma notificação quando estes eventos ocorrerem, crie uma política de alerta. Pode selecionar uma política de alertas pré-configurada usando as opções na página Painel de controlo do estado do serviço. Para mais informações, consulte o artigo Início rápido: configure um alerta.
A monitorização identifica Google Cloud incidentes através da emissão de um pedido à API Service Health e, em seguida, filtra a resposta para os incidentes relevantes para os dados que está a ver. O pedido tem a seguinte configuração:
A enumeração
Relevanceestá definida comoRELATED,IMPACTEDouPARTIALLY_RELATED. Esta restrição garante que o seu painel de controlo apenas apresenta eventos para os serviços que o seu projeto está a usar. Google Cloud Google CloudA enumeração
DetailedStatenão está definida comoFALSE_POSITIVE.
As anotações do Service Health são apresentadas com uma hora de início e uma duração. A duração é apresentada alterando a cor de fundo do gráfico. A sugestão de ajuda de um Google Cloud incidente identifica o seguinte:
- O Google Cloud serviço.
- Se o incidente está aberto ou resolvido.
- Data e hora de início do evento.
- Chips que apresentam o número de produtos e localizações afetados. Para ver uma lista dos produtos ou localizações afetados, posicione o ponteiro sobre o chip correspondente.
- Um botão Ver que, quando selecionado, abre a página de detalhes do incidente.
Para ver informações sobre como emitir um pedido para a API Service Health, consulte o artigo Verifique se existem interrupções com o Service Health.
Para informações de resolução de problemas, consulte o artigo Resolva problemas comuns no estado do serviço.
Tipos de eventos de verificação de tempo de atividade
Esta secção descreve os tipos de eventos de verificação de tempo de atividade que podem ser apresentados num painel de controlo.
Falha na verificação de tempo de atividade
Este tipo de evento ajuda a identificar falhas de verificação de tempo de atividade de regiões configuradas.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
Para ver informações de resolução de problemas, consulte o artigo Resolva problemas de monitorizações sintéticas e verificações de tempo de atividade.
Agente para tipos de eventos SAP
Esta secção descreve os tipos de eventos do agente para SAP que podem ser apresentados num painel de controlo.
Disponibilidade do SAP
Este tipo de evento ajuda a identificar eventos relacionados com a disponibilidade do agente para SAP. Estes eventos são acionados quando a disponibilidade do SAP HANA, SAP NetWeaver ou Pacemaker Cluster é alterada.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
SAP Backint
Este tipo de evento ajuda a identificar eventos relacionados com o agente para SAP Backint. Qualquer gravação de cópia de segurança ou recuperação do Backint escreve um evento que detalha o êxito ou a falha, juntamente com as estatísticas de transferência. As cópias de segurança e as recuperações de registos só são apresentadas em caso de falha, enquanto as cópias de segurança e as recuperações de dados são apresentadas em caso de êxito e falha.
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
Operações SAP
Este tipo de evento ajuda a identificar eventos relacionados com o agente para operações SAP. Estes eventos são acionados quando o estado de replicação do SAP HANA muda.
Se quiser criar uma política de alertas baseada em registos para este tipo de evento, use a seguinte consulta:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
O que se segue?
Para saber como mostrar eventos nos painéis de controlo, consulte o artigo Mostrar eventos num painel de controlo.