이 문서에서는 차트에 주석으로 표시할 수 있는 이벤트 유형을 설명합니다. 이벤트는 재부팅 또는 비정상 종료와 같이 시스템 작업에 영향을 주는 활동입니다. 이벤트를 표시하면 다양한 소스의 데이터를 연결하여 문제를 해결하는 데 도움이 될 수 있습니다.
각 이벤트에는 이벤트를 쿼리하는 방법에 관한 정보와 함께 참조 또는 문제 해결 문서 링크가 제공됩니다. 예를 들어 로그를 분석하여 이벤트가 식별되면 로그 탐색기 또는 로그 기반 알림 정책에 사용할 수 있는 쿼리가 제공됩니다.
차트에 주석을 추가하려면 차트를 표시하는 대시보드 또는 탭을 구성합니다. 예를 들어 Google Cloud 콘솔의 대시보드 페이지에 나열된 대부분의 대시보드를 구성하여 이벤트를 표시할 수 있습니다. 마찬가지로 Compute Engine 및 Google Kubernetes Engine 등의 서비스 관련 이벤트를 표시하도록 일부 서비스별로 모니터링 가능성 탭을 구성할 수 있습니다. 구성 정보는 대시보드에 이벤트 표시를 참조하세요.
다음 스크린샷에서는 로그 항목을 분석하여 식별된 여러 이벤트와 하나의 Service Health 이벤트를 보여주는 차트입니다.
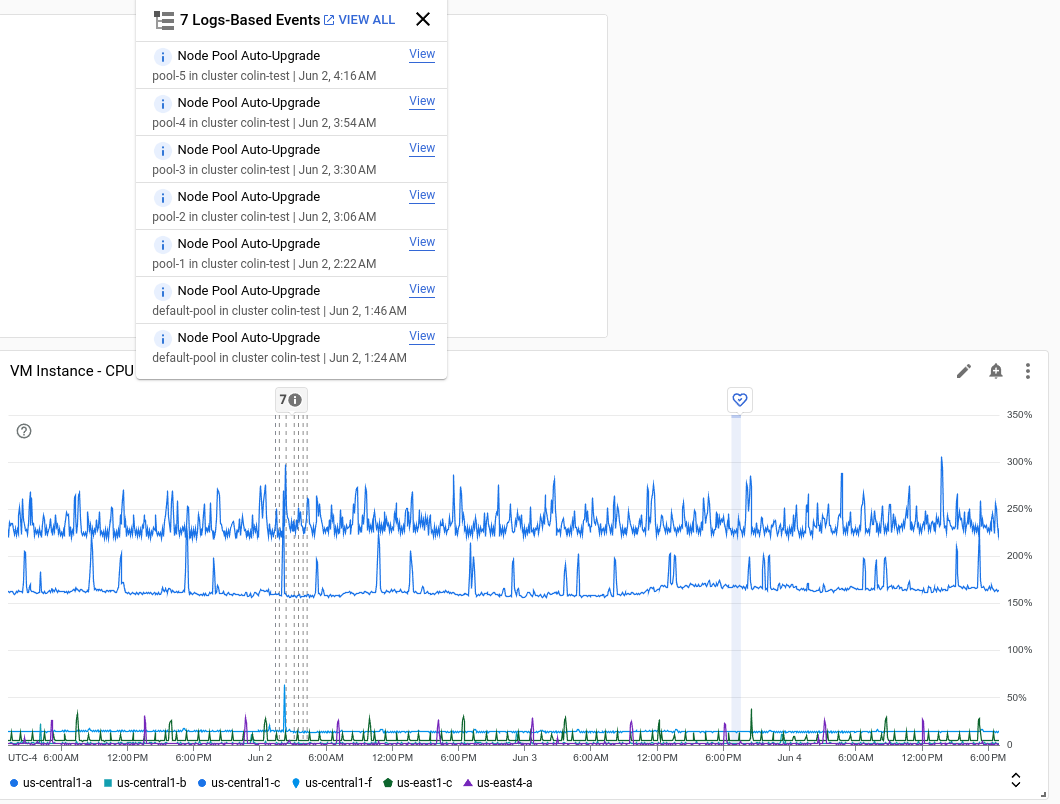
각 주석에는 여러 이벤트가 나열될 수 있습니다. 이전 스크린샷에는 GKE 배포 이벤트가 나열되어 있습니다.
알림 이벤트 유형
이 섹션에서는 대시보드에 표시할 수 있는 알림 이벤트 유형을 설명합니다.
알림 열린 시간
알림 열린 시간 이벤트를 사용하면 차트 데이터를 이슈가 열렸을 때와 연관시킬 수 있습니다. 알림 열린 시간 이벤트는 다음이 참인 경우 표시됩니다.
- 대시보드에서 지정한 기간 동안 해당 이슈가 열렸습니다.
- 해당 이슈가 종료되지 않았습니다.
대시보드에서 지정한 기간 외부에 열려 있는 이슈에 대한 주석은 표시되지 않습니다. 마찬가지로 대시보드에서 지정한 기간 내에 상응하는 이슈가 열렸다가 종료된 경우 알림 열린 시간 이벤트가 표시되지 않습니다.
알림 열린 시간 이벤트의 도움말에는 다음이 포함됩니다.
- 알림 정책 이름
- 요약 정보(이 정보가 제공되는 경우)입니다. 예를 들어 이 정보에는 기준점과 측정값이 포함될 수 있습니다.
- 이슈의 기간 및 이슈가 열렸던 날짜와 시간입니다.
- 측정항목 및 리소스 라벨입니다. 도움말에는 일부 라벨만 표시될 수 있습니다.
- 보기 버튼: 이 버튼을 클릭하면 이슈의 세부정보 페이지가 열립니다.
Google Kubernetes Engine 이벤트 유형
이 섹션에서는 대시보드에 표시될 수 있는 Google Kubernetes Engine 이벤트 유형에 대해 설명합니다.
패치되거나 업데이트된 GKE 워크로드
이 이벤트 유형은 해당 이벤트가 성능 저하 또는 기타 성능 문제와 동시에 발생할 수 있기 때문에 GKE 워크로드 배포 또는 statefulset 변경과 관련된 문제를 해결하는 데 도움이 됩니다. 이 이벤트 유형은 워크로드가 생성, 업데이트, 삭제될 때 표시됩니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
자세한 내용은 워크로드 배포 개요 및 관측 가능성 측정항목 보기를 참조하세요.
GKE 포드 비정상 종료
이 이벤트 유형은 GKE 포드 비정상 종료를 식별하고 문제 해결하는 데 도움이 됩니다. 포드 비정상 종료는 메모리 소진 또는 애플리케이션 오류로 인해 발생할 수 있습니다. 이 이벤트 유형은 다음 중 하나에 해당할 때 표시됩니다.
- 포드 상태가
CrashLoopBackoff - 포드가 0이 아닌 종료 코드로 종료됨
- 메모리 부족 조건으로 포드가 종료됨
- 포드가 제거됨
- 준비/활성 프로브가 실패함
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
문제 해결 정보는 문제 해결: CrashLoopBackOff를 참조하세요.
GKE 포드 예약 실패
이 이벤트 유형은 노드에서 예약할 수 없는 포드가 있는 경우 이를 식별하고 문제를 해결하는 데 도움이 됩니다. 이 이벤트 유형은 다음과 같은 이유로 포드 예약에 실패할 때 표시됩니다.
- 노드 CPU가 부족함
- 노드 메모리가 부족함
- taint 또는 톨러레이션에 대한 노드가 없음
- 노드가 최대 포드 한도에 도달함
- 노드 풀이 최대 크기임
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
문제 해결 정보는 문제 해결: 포드 예약 불가를 참조하세요.
GKE 컨테이너 생성 실패
이 이벤트 유형은 GKE 컨테이너 생성 실패를 식별하고 문제를 해결하는 데 도움이 됩니다. 볼륨 마운트 실패 또는 이미지 가져오기 실패와 같은 이유로 컨테이너 만들기가 실패할 수 있습니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
이미지 가져오기에 대한 문제 해결 정보는 이미지 가져오기 문제 해결을 참조하세요.
포드 자동 확장 처리 수직 확장 및 축소
이 이벤트를 통해 워크로드의 실행 중인 포드 수를 늘리거나 줄이는 수평형 포드 자동 확장 처리 재조정을 확인할 수 있습니다. 자세한 내용은 수평형 포드 자동 확장을 참조하세요.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
클러스터 자동 확장 처리 수직 확장 및 축소
이 이벤트를 통해 클러스터 자동 확장 처리가 클러스터의 노드 풀에서 노드 수를 확장하거나 축소하는 시점을 확인할 수 있습니다. 자세한 내용은 클러스터 자동 확장 정보 및 클러스터 자동 확장 처리 이벤트 보기를 참조하세요.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
클러스터 만들기 및 삭제
이 이벤트는 GKE 클러스터 만들기 및 삭제 작업을 추적합니다. 자세한 내용은 Autopilot 클러스터 만들기, 영역 클러스터 만들기, 클러스터 삭제를 참조하세요.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
클러스터 업데이트
이 이벤트는 GKE 클러스터 업데이트를 추적합니다. 업데이트에는 자동 컨트롤 플레인 버전 업그레이드 및 수동 업그레이드, 클러스터 구성 변경이 포함됩니다. 자세한 내용은 클러스터 또는 노드 풀 수동 업그레이드 및 표준 클러스터 업그레이드를 참조하세요.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
노드 풀 업데이트
이 이벤트는 GKE 노드 풀 업데이트를 추적합니다. 업데이트에는 자동 노드 풀 버전 업그레이드 및 수동 업그레이드, 구성 변경, 크기 조절이 포함됩니다. 자세한 내용은 클러스터 또는 노드 풀 수동 업그레이드 및 표준 클러스터 업그레이드를 참조하세요.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Cloud Run 이벤트 유형
이 섹션에서는 대시보드에 표시할 수 있는 Cloud Run 이벤트 유형에 대해 설명합니다.
Cloud Run 배포
이 이벤트 유형은 Cloud Run 배포 장애를 식별하고 문제 해결하는 데 도움이 됩니다. 삭제된 서비스 계정, 잘못된 권한, 컨테이너 가져오기 실패, 컨테이너 시작 실패와 같은 이유로 인해 배포가 실패할 수 있습니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
문제 해결 정보는 문제 해결: Cloud Run 문제를 참조하세요.
Cloud SQL 이벤트 유형
이 섹션에서는 대시보드에 표시할 수 있는 Cloud SQL 이벤트 유형에 대해 설명합니다.
Cloud SQL 장애 조치
이 이벤트 유형은 수동 또는 자동 장애 조치가 발생할 때 이를 식별할 수 있게 도와줍니다. 장애 조치는 인스턴스 또는 영역 장애가 있고 대기 인스턴스가 새 기본 인스턴스가 될 때 발생합니다. 장애 조치 중에 Cloud SQL은 대기 인스턴스에서 데이터를 제공하도록 자동으로 전환됩니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
자세한 내용은 고가용성 정보를 참조하세요.
Cloud SQL 시작 또는 중지
이 이벤트 유형은 Cloud SQL 인스턴스가 수동으로 시작, 중지, 재시작되었을 때 이를 식별할 수 있게 도와줍니다. 인스턴스가 중지되면 모든 연결, 열려 있는 파일, 실행 중인 작업도 중지됩니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
자세한 내용은 고가용성 정보 및 인스턴스 시작, 중지, 다시 시작을 참조하세요.
Cloud SQL 스토리지
이 이벤트 유형은 데이터베이스 스토리지가 가득 찼을 때, 스토리지 용량에 도달하여 데이터베이스가 종료될 때를 포함하여 Cloud SQL 스토리지와 관련된 이벤트를 식별하는 데 도움이 됩니다. 스토리지 용량에 도달했고 자동 스토리지를 사용 설정하지 않은 데이터베이스는 데이터 손상 방지를 위해 종료될 수 있습니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Compute Engine 이벤트 유형
이 섹션에서는 대시보드에 표시될 수 있는 Compute Engine 이벤트 유형에 대해 설명합니다.
가상 머신 종료
이 이벤트 유형은 수동으로 트리거된 재설정과 중지, 게스트 OS 종료, 유지보수 종료, 호스트 오류를 포함하여 가상 머신(VM) 종료를 식별하는 데 도움이 됩니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
자세한 내용은 VM 시작 및 중지와 VM 종료 및 재부팅 문제 해결을 참조하세요.
VM 인스턴스 시작 실패
이 이벤트는 Compute Engine VM 시작 실패를 추적합니다. 이벤트가 소진, IP 공간 고갈, 할당량 초과, 보안 VM 무결성 오류로 인한 시작 실패를 표시합니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
VM 인스턴스 게스트 OS 오류
이 이벤트는 직렬 콘솔 로그에 기록된 특정 Compute Engine VM 인스턴스 게스트 OS 오류를 추적합니다. 추적되는 오류는 Linux 비상 모드를 활성화하는 디스크 꽉 참, 파일 시스템 마운트 실패, 부팅 실패입니다.
이러한 이벤트를 보려면 VM 또는 프로젝트 메타데이터에서 serial-port-logging-enable=true를 설정하여 Cloud Logging에 직렬 포트 출력 로깅을 사용 설정해야 합니다. 자세한 내용은 직렬 포트 출력 로깅 사용 설정 및 사용 중지를 참조하세요.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
관리형 인스턴스 그룹 업데이트
이 이벤트 유형은 관리형 인스턴스 그룹(MIG)이 업데이트되었을 때 이를 식별하는 데 도움이 됩니다. 예를 들어 VM이 추가 또는 삭제되거나 크기 한도가 업데이트되었을 수 있습니다. 자세한 내용은 MIG에서 VM 구성 업데이트 자동 적용을 참조하세요.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
자세한 내용은 관리형 인스턴스 작업 및 관리형 인스턴스 그룹 문제 해결을 참조하세요.
관리형 인스턴스 그룹 자동 확장 처리
이 이벤트는 MIG의 자동 확장 처리에서 내린 확장 결정을 추적합니다. 이러한 결정에는 MIG의 권장 크기 변경사항 또는 자동 확장 처리 자체의 상태 변경사항이 포함될 수 있습니다. 자세한 내용은 인스턴스 그룹 자동 확장을 참조하세요.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Personalized Service Health 이벤트 유형
이 섹션에서는 대시보드에 표시할 수 있는 Personalized Service Health 유형을 설명합니다.
Google Cloud 이슈
문제 해결 시 소유한 서비스로 인한 오류와 사용하는Google Cloud 서비스로 인한 오류를 구분하는 것이 좋습니다. 대시보드에서 Personalized Service Health 주석을 사용 설정하면 Google Cloud 서비스의 중단 또는 서비스 상태 이벤트를 볼 수 있습니다. Service Health와 통합된 서비스 목록은 지원되는 Google 제품을 참조하세요.
다른 이벤트 유형과 달리 Google Cloud 이슈는 로그 항목을 분석하여 식별되지 않습니다. 이러한 이벤트가 발생할 때 알림을 받으려면 알림 정책을 만드세요. Service Health 대시보드 페이지의 옵션을 사용하여 사전 구성된 알림 정책을 선택할 수 있습니다. 자세한 내용은 빠른 시작: 알림 설정을 참조하세요.
Monitoring은 Service Health API에 요청을 전송한 후 보고 있는 데이터와 관련된 이슈에 대한 응답을 필터링하여 Google Cloud 이슈를 식별합니다. 요청의 구성은 다음과 같습니다.
Relevance열거가RELATED,IMPACTED또는PARTIALLY_RELATED로 설정됩니다. 이 제한사항을 적용하면 대시보드에Google Cloud 프로젝트에서 사용 중인 Google Cloud 서비스의 이벤트만 표시됩니다.DetailedState열거가FALSE_POSITIVE로 설정되지 않았습니다.
Service Health 주석은 시작 시간 및 기간과 함께 표시됩니다. 차트의 배경 색상을 변경하여 재생 시간을 표시합니다. Google Cloud 이슈의 도움말에는 다음이 표시됩니다.
- Google Cloud 서비스
- 이슈가 미해결 상태인지 해결된 상태인지 여부입니다.
- 이벤트의 날짜 및 시작 시간
- 영향을 받는 제품 및 위치 수를 표시하는 칩입니다. 영향을 받는 제품이나 위치를 나열하려면 해당 칩에 포인터를 놓습니다.
- 보기 버튼: 선택하면 이슈의 세부정보 페이지가 열립니다.
Service Health API에 요청을 보내는 방법에 관한 자세한 내용은 Service Health 중단 확인을 참조하세요.
문제 해결 정보는 Service Health의 일반적인 문제 해결을 참조하세요.
업타임 체크 이벤트 유형
이 섹션에서는 대시보드에 표시할 수 있는 업타임 체크 이벤트 유형을 설명합니다.
업타임 체크 실패
이 이벤트 유형은 구성된 리전에서 업타임 체크 실패를 식별하는 데 도움이 됩니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
문제 해결 정보는 합성 모니터 및 업타임 체크 문제 해결을 참조하세요.
SAP용 에이전트 이벤트 유형
이 섹션에서는 대시보드에 표시할 수 있는 SAP용 에이전트 이벤트 유형을 설명합니다.
SAP 가용성
이 이벤트 유형은 SAP용 에이전트 가용성과 관련된 이벤트를 식별하는 데 도움이 됩니다. 이러한 이벤트는 SAP HANA, SAP NetWeaver 또는 Pacemaker 클러스터 가용성이 변경되면 트리거됩니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
SAP Backint
이 이벤트 유형은 SAP Backint용 에이전트와 관련된 이벤트를 식별하는 데 도움이 됩니다. Backint 백업 또는 복구 시 전송 통계와 함께 성공 또는 실패를 자세히 설명하는 이벤트가 작성됩니다. 로그 백업 및 복구는 실패 시만 표시되고 데이터 백업 및 복구는 성공 및 실패 시 모두 표시됩니다.
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
SAP 운영
이 이벤트 유형은 SAP용 에이전트 운영과 관련된 이벤트를 식별하는 데 도움이 됩니다. 이러한 이벤트는 SAP HANA 복제 상태가 변경되면 트리거됩니다.
이 이벤트 유형에 대해 로그 기반 알림 정책 만들기를 수행하려면 다음 쿼리를 사용합니다.
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
다음 단계
대시보드에 이벤트를 표시하는 방법은 대시보드에 이벤트 표시를 참조하세요.