Dokumen ini menjelaskan jenis peristiwa yang dapat ditampilkan sebagai anotasi pada diagram. Peristiwa adalah aktivitas, seperti mulai ulang atau error, yang memengaruhi operasi sistem. Menampilkan peristiwa dapat membantu Anda mengaitkan data dari berbagai sumber saat memecahkan masalah.
Untuk setiap peristiwa, link ke referensi atau dokumentasi pemecahan masalah disediakan beserta informasi tentang cara membuat kueri untuk peristiwa tersebut. Misalnya, saat peristiwa diidentifikasi dengan menganalisis log Anda, kueri yang sesuai untuk digunakan dengan Logs Explorer atau dengan kebijakan pemberitahuan berbasis log akan disediakan.
Untuk menambahkan anotasi ke diagram, Anda harus mengonfigurasi dasbor atau tab yang menampilkan diagram. Misalnya, Anda dapat mengonfigurasi sebagian besar dasbor yang tercantum di halaman Dasbor di Google Cloud konsol untuk menampilkan peristiwa. Demikian pula, Anda dapat mengonfigurasi beberapa tab Observabilitas khusus layanan, seperti tab untuk Compute Engine dan Google Kubernetes Engine, untuk menampilkan peristiwa. Untuk informasi konfigurasi, lihat artikel Menampilkan peristiwa di dasbor.
Screenshot berikut mengilustrasikan diagram yang menampilkan beberapa peristiwa yang diidentifikasi dengan menganalisis entri log, dan satu peristiwa Kesehatan Layanan:
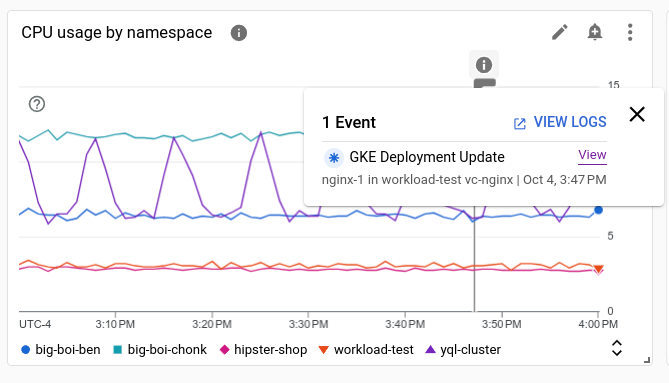
Setiap anotasi dapat mencantumkan beberapa peristiwa. Pada screenshot sebelumnya, peristiwa untuk deployment GKE dicantumkan.
Jenis peristiwa pemberitahuan
Bagian ini menjelaskan jenis peristiwa pemberitahuan yang dapat ditampilkan di dasbor.
Notifikasi dibuka
Peristiwa yang dibuka pemberitahuan membantu Anda mengaitkan data yang dipetakan dengan waktu insiden dibuka. Peristiwa pembukaan pemberitahuan ditampilkan jika hal berikut berlaku:
- Insiden yang sesuai dibuka selama rentang waktu yang ditentukan oleh dasbor.
- Insiden yang sesuai tidak ditutup.
Tidak ada anotasi yang dibuat untuk insiden yang dibuka di luar rentang waktu yang ditentukan oleh dasbor tidak ditampilkan. Demikian pula, peristiwa pemberitahuan yang dibuka tidak ditampilkan saat insiden yang sesuai dibuka, lalu ditutup dalam rentang waktu yang ditentukan oleh dasbor.
Tooltip untuk peristiwa pembukaan pemberitahuan mencakup hal berikut:
- Nama kebijakan pemberitahuan.
- Informasi ringkasan, jika informasi ini tersedia. Misalnya, informasi ini dapat mencakup nilai minimum dan nilai yang diukur.
- Durasi insiden, serta tanggal dan waktu saat insiden dibuka.
- Label metrik dan resource. Alat tooltip mungkin tidak menampilkan semua label.
- Tombol Lihat, yang membuka halaman Detail untuk insiden.
Jenis peristiwa Google Kubernetes Engine
Bagian ini menjelaskan jenis peristiwa Google Kubernetes Engine yang dapat ditampilkan di dasbor.
Workload GKE yang di-patch atau diupdate
Jenis peristiwa ini membantu Anda memecahkan masalah deployment beban kerja GKE atau perubahan statefulset, karena peristiwa ini dapat berkorelasi dengan regresi performa atau masalah performa lainnya. Jenis peristiwa ini ditampilkan saat beban kerja dibuat, diperbarui, atau dihapus.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
log_id(cloudaudit.googleapis.com%2Factivity)
resource.type=k8s_cluster protoPayload.methodName=(
io.k8s.apps.v1.deployments.create OR io.k8s.apps.v1.deployments.patch OR
io.k8s.apps.v1.deployments.update OR io.k8s.apps.v1.deployments.delete OR
io.k8s.apps.v1.statefulsets.create OR io.k8s.apps.v1.statefulsets.patch OR
io.k8s.apps.v1.statefulsets.update OR io.k8s.apps.v1.statefulsets.delete OR
io.k8s.apps.v1.daemonsets.create OR io.k8s.apps.v1.daemonsets.patch OR
io.k8s.apps.v1.daemonsets.update OR io.k8s.apps.v1.daemonsets.delete
)
-protoPayload.authenticationInfo.principalEmail=("system:addon-manager" OR "system:serviceaccount:kube-system:namespace-controller")
-protoPayload.request.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.response.metadata.namespace=(kube-system OR gmp-system OR gmp-public OR gke-gmp-system OR istio-system)
-protoPayload.resourceName=~"namespaces/(kube-system|gmp-system|gmp-public|gke-gmp-system|istio-system)"
Untuk informasi tambahan, lihat Ringkasan deployment workload dan Melihat metrik kemampuan observasi.
Error pod GKE
Jenis peristiwa ini membantu Anda mengidentifikasi dan memecahkan masalah error pod GKE. Error Pod dapat disebabkan oleh kehabisan memori atau error aplikasi. Jenis peristiwa ini ditampilkan saat salah satu hal berikut terjadi:
- Status pod adalah
CrashLoopBackoff - Pod dihentikan dengan kode keluar bukan nol.
- Pod dihentikan dengan kondisi kehabisan memori.
- Pod dihapus.
- Pemeriksaan Kesiapan/Keaktifan gagal.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
(
log_id(events)
(
(resource.type=k8s_pod jsonPayload.reason=(BackOff OR Unhealthy OR Killing OR Evicted)) OR
(resource.type=k8s_node jsonPayload.reason=OOMKilling)
)
severity=WARNING
) OR (
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=k8s_cluster
(protoPayload.methodName=io.k8s.core.v1.pods.eviction.create OR
(protoPayload.methodName=io.k8s.core.v1.pods.delete
protoPayload.response.status.containerStatuses.state.terminated.exitCode:*
-protoPayload.response.status.containerStatuses.state.terminated.exitCode=0
)
)
)
Untuk mengetahui informasi pemecahan masalah, lihat Memecahkan masalah: CrashLoopBackOff.
Kegagalan untuk menjadwalkan pod GKE
Jenis peristiwa ini membantu Anda mengidentifikasi dan memecahkan masalah saat pod tidak dapat dijadwalkan di node. Jenis peristiwa ini ditampilkan saat penjadwalan pod gagal karena salah satu alasan berikut:
- CPU node tidak mencukupi.
- Memori node tidak cukup.
- Tidak ada node untuk taint atau toleransi.
- Node pada batas pod maksimum.
- Node pool pada ukuran maksimum.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
(
log_id(events) resource.type=k8s_pod jsonPayload.reason=(NotTriggerScaleUp OR FailedScheduling)
) OR (
log_id(container.googleapis.com/cluster-autoscaler-visibility)
resource.type=k8s_cluster jsonPayload.noDecisionStatus.noScaleUp:*
)
Untuk mengetahui informasi pemecahan masalah, lihat Memecahkan masalah: Pod tidak dapat dijadwalkan.
Gagal membuat penampung GKE
Jenis peristiwa ini membantu Anda mengidentifikasi dan memecahkan masalah kegagalan untuk membuat penampung GKE. Pembuatan penampung mungkin gagal karena alasan seperti pemasangan volume yang gagal atau penarikan image yang gagal.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
log_id(events) resource.type=k8s_pod jsonPayload.reason=(Failed OR FailedMount) severity=WARNING
Untuk mengetahui informasi pemecahan masalah terkait pengambilan image, lihat Memecahkan masalah pengambilan image.
Peningkatan dan penurunan skala autoscaler pod
Peristiwa ini memberi Anda visibilitas ke penskalaan ulang Horizontal Pod Autoscaler, yang meningkatkan atau mengurangi jumlah pod yang berjalan untuk beban kerja. Untuk informasi selengkapnya, lihat Penskalaan otomatis Pod horizontal.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=k8s_cluster log_id(events) jsonPayload.involvedObject.kind=HorizontalPodAutoscaler jsonPayload.reason=SuccessfulRescale
Autoscaler cluster menaikkan dan menurunkan skala
Peristiwa ini memberi Anda visibilitas tentang kapan autoscaler cluster menskalakan jumlah node di node pool cluster Anda ke atas atau ke bawah. Untuk informasi selengkapnya, lihat Tentang penskalaan otomatis cluster dan Melihat peristiwa autoscaler cluster.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
(resource.type=k8s_cluster log_id(container.googleapis.com%2Fcluster-autoscaler-visibility) jsonPayload.decision:*)
Pembuatan dan penghapusan cluster
Peristiwa ini melacak tindakan pembuatan dan penghapusan cluster GKE. Untuk informasi selengkapnya, lihat Membuat cluster Autopilot, Membuat cluster zona, dan Menghapus cluster.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
google.container.v1alpha1.ClusterManager.CreateCluster OR
google.container.v1beta1.ClusterManager.CreateCluster OR
google.container.v1.ClusterManager.CreateCluster OR
google.container.v1alpha1.ClusterManager.DeleteCluster OR
google.container.v1beta1.ClusterManager.DeleteCluster OR
google.container.v1.ClusterManager.DeleteCluster
)
operation.first=true
Update cluster
Peristiwa ini melacak update cluster GKE. Update mencakup upgrade versi bidang kontrol otomatis serta upgrade manual dan perubahan konfigurasi cluster. Untuk mengetahui informasi selengkapnya, lihat Mengupgrade cluster atau node pool secara manual dan Upgrade cluster standar.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=gke_cluster log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.PatchCluster OR
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.UpdateCluster
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateCluster OR
google.container.v1.ClusterManager.UpdateCluster
)
operation.first=true
)
protoPayload.metadata.operationType=(UPGRADE_MASTER OR REPAIR_CLUSTER OR UPDATE_CLUSTER)
Update node pool
Peristiwa ini melacak update node pool GKE. Update mencakup upgrade versi kumpulan node otomatis serta upgrade manual, perubahan konfigurasi, dan pengubahan ukuran. Untuk mengetahui informasi selengkapnya, lihat Mengupgrade cluster atau node pool secara manual dan Upgrade cluster standar.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=gke_nodepool log_id(cloudaudit.googleapis.com%2Factivity)
(
protoPayload.methodName=(
google.container.internal.ClusterManagerInternal.UpdateClusterInternal OR
google.container.internal.ClusterManagerInternal.RepairNodePool
)
) OR (
protoPayload.methodName=(
google.container.v1beta1.ClusterManager.UpdateNodePool OR
google.container.v1.ClusterManager.UpdateNodePool OR
google.container.v1beta1.ClusterManager.SetNodePoolSize OR
google.container.v1.ClusterManager.SetNodePoolSize OR
google.container.v1beta1.ClusterManager.SetNodePoolManagement OR
google.container.v1.ClusterManager.SetNodePoolManagement OR
google.container.v1beta1.ClusterManager.SetNodePoolAutoscaling OR
google.container.v1.ClusterManager.SetNodePoolAutoscaling
)
operation.first=true
)
Jenis peristiwa Cloud Run
Bagian ini menjelaskan jenis peristiwa Cloud Run yang dapat ditampilkan di dasbor.
Deployment Cloud Run
Jenis peristiwa ini membantu Anda mengidentifikasi dan memecahkan masalah kegagalan deployment Cloud Run. Deployment mungkin gagal karena alasan seperti akun layanan yang dihapus, izin yang salah, impor penampung gagal, atau penampung gagal dimulai.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloud_run_revision protoPayload.methodName=google.cloud.run.v1.Services.ReplaceService
Untuk mengetahui informasi pemecahan masalah, lihat Memecahkan masalah: Masalah Cloud Run.
Jenis peristiwa Cloud SQL
Bagian ini menjelaskan jenis peristiwa Cloud SQL yang dapat ditampilkan di dasbor.
Failover Cloud SQL
Jenis peristiwa ini membantu Anda mengidentifikasi kapan failover manual atau otomatis terjadi. Failover terjadi saat terjadi kegagalan instance atau zona dan instance standby menjadi instance utama baru. Selama failover, Cloud SQL akan otomatis beralih ke sajian data dari instance standby.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=cloudsql_database
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=cloudsql.instances.failover
operation.last=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.autoFailover
)
)
Untuk informasi tambahan, lihat Tentang ketersediaan tinggi.
Memulai atau menghentikan Cloud SQL
Jenis peristiwa ini membantu Anda mengidentifikasi instance Cloud SQL yang telah dimulai, dihentikan, atau dimulai ulang secara manual. Saat instance dihentikan, semua koneksi, file yang terbuka, dan operasi yang berjalan juga akan dihentikan.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
log_id(cloudaudit.googleapis.com%2Factivity) resource.type=cloudsql_database protoPayload.methodName=cloudsql.instances.update operation.last=true protoPayload.metadata.intents.intent=(START_INSTANCE OR STOP_INSTANCE)
Untuk informasi tambahan, lihat Tentang ketersediaan tinggi dan Memulai, menghentikan, dan memulai ulang instance.
Penyimpanan Cloud SQL
Jenis peristiwa ini membantu Anda mengidentifikasi peristiwa yang terkait dengan penyimpanan Cloud SQL, termasuk saat penyimpanan database penuh, dan saat database dinonaktifkan karena mencapai kapasitas penyimpanan. Database dengan kapasitas penyimpanan dan tanpa penyimpanan otomatis yang diaktifkan dapat dinonaktifkan untuk mencegah kerusakan data.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=cloudsql_database
(
(
(log_id(cloudsql.googleapis.com%2Fpostgres.log) OR log_id(cloudsql.googleapis.com%2Fmysql.err))
textPayload=~"No space left on device"
severity=(ERROR OR EMERGENCY)
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=cloudsql.instances.databaseShutdownOutOfStorage
)
)
Jenis peristiwa Compute Engine
Bagian ini menjelaskan jenis peristiwa Compute Engine yang dapat ditampilkan di dasbor.
Penghentian virtual machine
Jenis peristiwa ini membantu Anda mengidentifikasi penghentian virtual machine (VM), termasuk reset dan penghentian yang dipicu secara manual, penghentian OS tamu, penghentian pemeliharaan, dan error host.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(
beta.compute.instances.reset OR v1.compute.instances.reset OR
beta.compute.instances.stop OR v1.compute.instances.stop
)
operation.first=true
) OR (
log_id(cloudaudit.googleapis.com%2Fsystem_event)
protoPayload.methodName=(
compute.instances.hostError OR
compute.instances.guestTerminate OR
compute.instances.terminateOnHostMaintenance
)
)
)
Untuk informasi tambahan, lihat artikel Menghentikan dan memulai VM dan Memecahkan masalah penonaktifan dan mulai ulang VM.
Kegagalan memulai instance VM
Peristiwa ini melacak kegagalan mulai instance VM Compute Engine. Peristiwa ini menunjukkan kegagalan mulai karena kehabisan stok, ruang IP habis, kuota terlampaui, atau error integritas VM yang dilindungi.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=gce_instance
(
(
log_id(cloudaudit.googleapis.com%2Factivity)
protoPayload.methodName=(beta.compute.instances.insert OR v1.compute.instances.insert)
protoPayload.status.message=(ZONE_RESOURCE_POOL_EXHAUSTED OR IP_SPACE_EXHAUSTED OR QUOTA_EXCEEDED)
) OR (
log_id(compute.googleapis.com%2Fshielded_vm_integrity)
severity="ERROR"
)
)
Error OS tamu instance VM
Peristiwa ini melacak error OS Tamu instance VM Compute Engine tertentu seperti yang dicatat oleh log konsol serial. Error yang dilacak adalah disk penuh, pemasangan sistem file gagal, dan kegagalan booting yang mengaktifkan mode darurat Linux.
Agar peristiwa ini terlihat, Anda harus mengaktifkan logging output port serial ke
Cloud Logging dengan menetapkan serial-port-logging-enable=true di VM atau di
metadata project. Untuk mengetahui informasi selengkapnya, lihat
Mengaktifkan dan menonaktifkan logging output port serial.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=gce_instance
log_id(serialconsole.googleapis.com%2Fserial_port_1_output)
textPayload=~("No space left on device" OR "Failed to mount" OR "You are in emergency mode")
Update grup instance terkelola
Jenis peristiwa ini membantu Anda mengidentifikasi kapan Grup Instance Terkelola (MIG) telah diupdate. Misalnya, VM telah ditambahkan atau dihapus, atau batas ukuran telah diperbarui. Untuk mengetahui informasi selengkapnya, lihat Menerapkan update konfigurasi VM secara otomatis di MIG.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=gce_instance_group_manager log_id(cloudaudit.googleapis.com%2Factivity) operation.first=true protoPayload.methodName=(beta.compute.instanceGroupManagers.patch OR v1.compute.instanceGroupManagers.patch)
Untuk informasi tambahan, lihat Menggunakan instance terkelola dan Memecahkan masalah grup instance terkelola.
Autoscaler grup instance terkelola
Peristiwa ini melacak keputusan penskalaan yang dibuat oleh autoscaler MIG. Keputusan ini dapat mencakup perubahan pada ukuran yang direkomendasikan untuk MIG, atau perubahan pada status autoscaler itu sendiri. Untuk mengetahui informasi selengkapnya, lihat Penskalaan otomatis grup instance.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
resource.type=autoscaler log_id(cloudaudit.googleapis.com%2Fsystem_event) protoPayload.methodName=(compute.autoscalers.resize OR compute.autoscalers.changeStatus)
Jenis peristiwa Personalized Service Health
Bagian ini menjelaskan jenis Personalized Service Health yang dapat ditampilkan di dasbor.
Google Cloud insiden
Saat memecahkan masalah, Anda mungkin ingin membedakan antara kegagalan yang disebabkan oleh layanan yang Anda miliki dan kegagalan yang disebabkan oleh layananGoogle Cloud yang Anda gunakan. Saat mengaktifkan anotasi Personalized Service Health di dasbor, Anda dapat melihat gangguan, atau peristiwa kesehatan layanan, untuk layanan Google Cloud . Untuk mengetahui daftar layanan yang terintegrasi dengan Kualitas Layanan, lihat Produk Google yang didukung.
Tidak seperti jenis peristiwa lainnya, Google Cloud insiden tidak diidentifikasi dengan menganalisis entri log Anda. Jika Anda ingin mendapatkan notifikasi saat peristiwa ini terjadi, buat kebijakan pemberitahuan. Anda dapat memilih kebijakan pemberitahuan yang telah dikonfigurasi sebelumnya menggunakan opsi di halaman Dasbor Kesehatan Layanan. Untuk mengetahui informasi selengkapnya, lihat Panduan memulai: Menyiapkan pemberitahuan.
Pemantauan mengidentifikasi Google Cloud insiden dengan mengeluarkan permintaan ke Service Health API, lalu memfilter respons terhadap insiden tersebut yang relevan dengan data yang Anda lihat. Permintaan memiliki konfigurasi berikut:
Enumerasi
Relevanceditetapkan keRELATED,IMPACTED, atauPARTIALLY_RELATED. Batasan ini memastikan bahwa dasbor Anda hanya menampilkan peristiwa untuk layanan yang digunakan project Anda. Google Cloud Google CloudEnumerasi
DetailedStatetidak disetel keFALSE_POSITIVE.
Anotasi Service Health ditampilkan dengan waktu mulai dan durasi. Durasi ditampilkan dengan mengubah warna latar diagram. Tooltip untuk Google Cloud insiden mengidentifikasi hal berikut:
- Layanan Google Cloud .
- Apakah insiden masih terbuka atau sudah diselesaikan.
- Tanggal dan waktu mulai acara.
- Chip yang menampilkan jumlah produk dan lokasi yang terpengaruh. Untuk mencantumkan produk atau lokasi yang terpengaruh, tempatkan kursor pada chip yang sesuai.
- Tombol Lihat, yang jika dipilih akan membuka halaman detail untuk insiden.
Untuk mengetahui informasi tentang cara membuat permintaan ke Service Health API, lihat Memeriksa gangguan pada Service Health.
Untuk mengetahui informasi pemecahan masalah, lihat Memecahkan masalah umum di Service Health.
Jenis peristiwa pemeriksaan uptime
Bagian ini menjelaskan jenis peristiwa pemeriksaan waktu aktif yang dapat ditampilkan di dasbor.
Kegagalan cek uptime
Jenis peristiwa ini membantu Anda mengidentifikasi kegagalan pemeriksaan waktu aktif dari region yang dikonfigurasi.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
log_id(monitoring.googleapis.com%2Fuptime_checks) ( resource.type=uptime_url OR resource.type=gce_instance OR resource.type=gae_app OR resource.type=k8s_service OR resource.type=servicedirectory_service OR resource.type=cloud_run_revision OR resource.type=aws_ec2_instance OR resource.type=aws_elb_load_balancer ) labels.uptime_result_type=UptimeCheckResult severity=NOTICE
Untuk mengetahui informasi pemecahan masalah, lihat Memecahkan masalah monitor sintetis dan pemeriksaan uptime.
Jenis peristiwa Agen untuk SAP
Bagian ini menjelaskan jenis peristiwa Agen untuk SAP yang dapat ditampilkan di dasbor.
Ketersediaan SAP
Jenis peristiwa ini membantu Anda mengidentifikasi peristiwa yang terkait dengan ketersediaan Agent for SAP. Peristiwa ini dipicu saat ketersediaan SAP HANA, SAP NetWeaver, atau Cluster Pacemaker berubah.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=(workload.googleapis.com/sap/hana/service OR workload.googleapis.com/sap/hana/availability OR workload.googleapis.com/sap/nw/service OR workload.googleapis.com/sap/nw/availability OR workload.googleapis.com/sap/cluster/nodes OR workload.googleapis.com/sap/cluster/resources)
Backint SAP
Jenis peristiwa ini membantu Anda mengidentifikasi peristiwa yang terkait dengan Agen untuk SAP Backint. Setiap pencadangan atau pemulihan Backint akan menulis peristiwa yang menjelaskan keberhasilan atau kegagalan beserta statistik transfer. Pencadangan dan pemulihan log hanya ditampilkan saat terjadi kegagalan, sedangkan pencadangan dan pemulihan data ditampilkan saat berhasil dan gagal.
log_id(google-cloud-sap-agent-backint) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) (jsonPayload.fileType=data OR (jsonPayload.fileType=log AND jsonPayload.success=false)) jsonPayload.message=SAP_BACKINT_FILE_TRANSFER
Operasi SAP
Jenis peristiwa ini membantu Anda mengidentifikasi peristiwa yang terkait dengan operasi Agent for SAP. Peristiwa ini dipicu saat status replikasi SAP HANA berubah.
Jika Anda ingin membuat kebijakan pemberitahuan berbasis log untuk jenis peristiwa ini, gunakan kueri berikut:
log_id(google-cloud-sap-agent) ( resource.type=generic_node OR resource.type=gce_instance OR resource.type=aws_ec2_instance OR resource.type=baremetalsolution.googleapis.com/Instance ) jsonPayload.metricEvent=true jsonPayload.metric=workload.googleapis.com/sap/hana/ha/replication
Langkah berikutnya
Untuk mempelajari cara menampilkan peristiwa di dasbor, lihat artikel Menampilkan peristiwa di dasbor.