Questo documento descrive come ricevere una notifica quando l'applicazione non funziona o quando le prestazioni di un'applicazione non soddisfano i criteri definiti.
Come funzionano gli avvisi
La procedura di avviso di Cloud Monitoring è composta da tre parti:
Un criterio di avviso, che descrive le circostanze in cui vuoi ricevere un avviso e come vuoi ricevere una notifica relativa a un incidente. La criterio di avviso può monitorare i dati delle serie temporali archiviati da Monitoring o i log archiviati da Cloud Logging. Quando i dati soddisfano la condizione criterio di avviso, Monitoring crea un incidente e invia le notifiche.
Ogni incidente è un record del tipo di dati monitorati e del momento in cui sono state soddisfatte le condizioni. Queste informazioni possono aiutarti a risolvere i problemi che hanno causato l'incidente.
Un canale di notifica definisce come ricevi le notifiche quando Monitoring crea un incidente. Ad esempio, puoi configurare una criterio di avviso per inviare un'email a
my-support-team@example.come pubblicare un messaggio Slack sul canale#my-support-team. Un criterio di avviso può contenere uno o più canali di notifica.
I criteri di avviso possono valutare tre tipi di dati:
Dati delle serie temporali, chiamati anche dati delle metriche, archiviati da Monitoring. Questi tipi di criteri sono chiamati criteri di avviso basati su metriche.
Per scoprire come configurare una criterio di avviso basata su metriche, prova la guida rapida per Compute Engine.
Dati delle voci di log archiviati da Cloud Logging. I criteri di avviso che valutano le singole voci di log sono chiamati criteri di avviso basati su log. I criteri di avviso basati su log ti avvisano quando nei log viene visualizzato un messaggio specifico. Per ulteriori informazioni, consulta Monitorare i log.
I risultati di una query SQL eseguita in Analisi dei log sui dati voce di log archiviati in Logging. Le policy di avviso che monitorano i risultati di una query SQL sono chiamate policy di avviso basate su SQL. Per saperne di più, consulta Monitorare i risultati delle query SQL con una policy di avviso.
Le policy di avviso basate su SQL sono in anteprima pubblica.
La procedura di avviso ti aiuta a rispondere ai problemi quando il rendimento di un'applicazione non soddisfa i valori accettabili. Ad esempio, esegui il deployment di un'applicazione web su un'istanza di macchina virtuale (VM) Compute Engine. Sebbene ti aspetti che la latenza della risposta HTTP fluttui, vuoi che il tuo team di assistenza risponda quando l'applicazione ha una latenza elevata per un periodo di tempo significativo. Puoi creare un criterio di avviso basato su metriche che monitora la metrica della latenza della risposta HTTP dell'applicazione. Se la latenza della risposta è superiore a due secondi per almeno cinque minuti, Monitoring crea un incidente e invia notifiche via email al tuo team di assistenza.
Come creare un criterio di avviso
Esistono diversi modi per creare un criterio di avviso. Ad esempio, puoi utilizzare criteri di avviso preconfigurati attivando gli avvisi consigliati dalle integrazioni o da determinate pagine della console Google Cloud . Puoi anche configurare una nuova criterio di avviso utilizzando la consoleGoogle Cloud , l'API Cloud Monitoring, Google Cloud CLI e Terraform.
Utilizzare le integrazioni e le policy di avviso consigliate
Monitoring fornisce pacchetti predefiniti per creare criteri di avviso per i tuoi Google Cloud servizi e integrazioni di terze parti. I pacchetti includono criteri di avviso consigliati, dashboard di esempio e metriche chiave per il servizio. Questi pacchetti sono disponibili per Google Cloud servizi come Google Kubernetes Engine, Compute Engine e Cloud SQL e integrazioni comuni di terze parti come MongoDB, Kafka ed Elasticsearch.
Quando installi un pacchetto, puoi attivare i criteri di avviso consigliati del pacchetto. Quando attivi un criterio di avviso consigliato, configuri il relativo canale di notifica e, facoltativamente, modifichi altri valori. Dopo la configurazione, la criterio di avviso inizia immediatamente a monitorare il target, senza richiedere ulteriori input utente'utente.
Le policy di avviso consigliate sono utili quando hai implementato un nuovo servizio e vuoi ricevere avvisi su metriche importanti. Ad esempio, il pacchetto di integrazione Cloud SQL include policy di avviso consigliate per istanze non riuscite e transazioni lente:
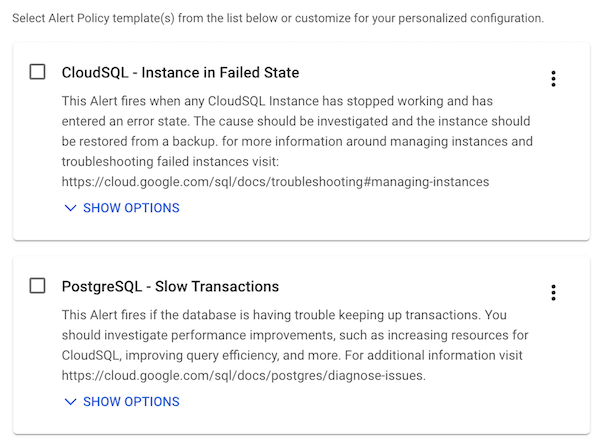
Per ulteriori informazioni sulle integrazioni degli avvisi, vedi Monitoraggio delle applicazioni di terze parti.
Crea nuovi criteri di avviso
Puoi creare criteri di avviso per monitorare diversi tipi di dati a seconda delle tue esigenze di avviso. Le sezioni seguenti elencano i diversi tipi di dati che puoi monitorare con i criteri di avviso.
Monitorare i dati delle serie temporali
| Tipo di condizione | Descrizione | Esempio |
|---|---|---|
| Condizione di soglia metrica | Le condizioni di soglia metrica vengono soddisfatte quando i valori di una metrica sono superiori o inferiori a una soglia per una finestra di ritest specifica. Per saperne di più, consulta Creare policy di avviso basate su soglie delle metriche e Creare policy di avviso utilizzando l'API. |
Vuoi un criterio di avviso che invii una notifica quando la latenza di risposta è pari o superiore a 500 ms per cinque controlli di uptime consecutivi in 10 minuti. |
| Condizione di assenza metrica | Le condizioni di assenza metrica vengono soddisfatte quando una serie temporale monitorata non ha dati per una specifica finestra di ritest. La durata massima della finestra di ritest è 23,5 ore. Per saperne di più, consulta Creare policy di avviso per l'assenza di metriche e Creare policy di avviso utilizzando l'API. | Vuoi una criterio di avviso che apra un incidente con il tuo team di assistenza quando una risorsa non risponde a nessuna richiesta HTTP nell'arco di cinque minuti. |
| Condizione di valore della metrica previsto | Le condizioni relative al valore della metrica previsto vengono soddisfatte quando il criterio di avviso prevede che la soglia verrà violata entro la finestra di previsione imminente. La finestra di previsione può variare da 1 ora a 7 giorni. Per saperne di più, consulta Creare policy di avviso basate sul valore delle metriche previsto e Creare policy di avviso utilizzando l'API. |
Vuoi un criterio di avviso che apra un incidente con il tuo team di assistenza quando è probabile che una risorsa raggiunga l'80% di utilizzo dello spazio su disco entro le prossime 24 ore. |
Monitorare i dati voce di log
Per monitorare le singole voci di log, utilizza un criterio di avviso basato su log.
Una condizione di un criterio di avviso basato su log viene soddisfatta quando il criterio di avviso rileva che una frase di una voce di log corrisponde ai criteri del criterio di avviso. Ad esempio, vuoi una criterio di avviso
che apra un incidente con il tuo team
di assistenza quando message di una voce di log
contiene product_ids=['tier_1_support', 'tier_2_support'].
Per ulteriori informazioni, consulta la sezione Configura i criteri di avviso basati su log nella documentazione di Logging.
Monitorare i risultati delle query SQL
Per monitorare i risultati delle query SQL, utilizza una criterio di avviso basata su SQL.
La condizione di una criterio di avviso basata su SQL analizza periodicamente
i dati voce di log e poi crea incident quando la tabella dei risultati
della query soddisfa determinati criteri. Questo tipo di criterio di avviso è utile quando
hai bisogno di unacriterio di avvisoo che monitori aggregazioni di dati o pattern complessi
in più voci di log. Ad esempio, vuoi ricevere una notifica quando più di 50 voci di log negli ultimi 60 minuti hanno una gravità pari a WARNING.
Per saperne di più, consulta Monitorare i risultati delle query SQL con una policy di avviso nella documentazione di Logging.
Componenti dei criteri di avviso
Ogni criterio di avviso è composto dai seguenti componenti:
Una condizione che descrive quando una risorsa o un gruppo di risorse si trova in uno stato che richiede una tua risposta. La condizione include l'origine dati, una soglia statica o dinamica e metodi di aggregazione dei dati come filtri e raggruppamento. Le condizioni possono monitorare una singola metrica, più metriche o un rapporto tra metriche. Puoi anche utilizzare il linguaggio di query Prometheus (PromQL) per includere espressioni complesse come soglie dinamiche e logica condizionale.
Se utilizzi un'integrazione per attivare un criterio di avviso consigliato, la condizione del criterio di avviso viene precompilata.
Un elenco di canali di notifica che descrivono a chi inviare una notifica quando è richiesta un'azione. Per saperne di più, consulta la pagina Crea e gestisci canali di notifica.
Documentazione visualizzata nelle pagine delle notifiche e degli incidenti. Puoi configurare l'oggetto di una notifica e aggiungere informazioni utili al corpo della notifica. Ad esempio, potresti configurare la notifica in modo che mostri link a playbook interni o a pagine Google Cloud come le dashboard personalizzate. Per saperne di più sulla documentazione, inclusi esempi, vedi Annotare gli incident con la documentazione definita dall'utente.
Linguaggi di query
Utilizza i linguaggi di query e i filtri nelle policy di avviso per avere un maggiore controllo sulla valutazione delle metriche. Il monitoraggio supporta i seguenti tipi di query:
Prometheus Query Language (PromQL) è un linguaggio di query funzionale utilizzato per valutare i dati delle serie temporali in tempo reale. Puoi configurare criteri di avviso in modo che includano una query PromQL nella condizione. Le query PromQL possono utilizzare qualsiasi espressione valida, ad esempio combinazioni di metriche, rapporti e soglie di scalabilità. Se configuri criteri di avviso basati su PromQL in Google Cloud, puoi ridurre le dipendenze dall'infrastruttura di avviso esterna. Per ulteriori informazioni, consulta PromQL in Cloud Monitoring e Panoramica degli avvisi PromQL.
I filtri di monitoraggio ti consentono di configurare criteri di avviso per utilizzare i rapporti tra metriche basati sui filtri. Le norme di avviso basate su filtri non possono essere visualizzate o modificate nella console Google Cloud . Per un esempio di policy che utilizza i filtri di Monitoring, consulta Rapporto tra metriche.
Monitoring Query Language (MQL) è un'interfaccia espressiva basata su testo che consente di recuperare, filtrare e manipolare i dati delle serie temporali. Puoi creare policy di avviso con condizioni che includono un'operazione di avviso Monitoring Query Language. Per saperne di più, consulta Panoramica di Monitoring Query Language e Policy di avviso con MQL.
Gestire le policy di avviso e gli incidenti
Una volta attivata una criterio di avviso, Monitoring monitora continuamente le condizioni della policy. Non puoi configurare i criterio di avviso per monitorare le condizioni solo per determinati periodi di tempo. Se vuoi disattivare il criterio di avviso per un determinato periodo di tempo, crea un posticipo.
Se un incidente è aperto e Monitoring determina che le condizioni della policy basata su metriche non sono più soddisfatte, allora Monitoring chiude automaticamente l'incidente e invia una notifica relativa alla chiusura.
Prezzi
In generale, le metriche di sistema di Cloud Monitoring sono gratuite, mentre le metriche provenienti da sistemi, agenti o applicazioni esterni non lo sono. Le metriche fatturabili vengono fatturate in base al numero di byte o al numero di campioni importati.
Per ulteriori informazioni, consulta le sezioni di Cloud Monitoring della pagina Prezzi di Google Cloud Observability.
Per informazioni su come monitorare il numero di intervalli di traccia o log inseriti o su come ricevere una notifica quando contenuti specifici sono inclusi in una voce di log, consulta i seguenti documenti:
- Avvisi sull'importazione mensile di log
- Avvisi sull'importazione di intervalli di traccia mensili
- Configura gli avvisi basati su log
Passaggi successivi
Per informazioni sulla latenza delle notifiche e su come le scelte per i parametri di una criterio di avviso influiscono sul momento in cui vengono inviate le notifiche, consulta Comportamento delle policy di avviso basate su metriche.
Per un elenco di esempi di criteri basati su metriche, consulta Riepilogo delle policy di avviso di esempio.