Por predefinição, o agente Ops e o agente Monitoring antigo estão configurados para recolher métricas que captam informações sobre os processos em execução nas suas máquinas virtuais (VMs) do Compute Engine. Também pode recolher estas métricas em VMs do Amazon Elastic Compute Cloud (EC2) através do agente de monitorização.
Este conjunto de métricas, denominado métricas de processo, é identificável pelo prefixo agent.googleapis.com/processes. Estas métricas não são recolhidas no Google Kubernetes Engine (GKE).
A partir de 6 de agosto de 2021, vão ser introduzidas cobranças para estas métricas, conforme descrito na secção de métricas cobráveis da página de preços do Google Cloud Observability. O conjunto de métricas de processo é classificado como cobrável, mas as cobranças nunca foram implementadas.
Este documento descreve as ferramentas para visualizar as métricas de processos, como determinar a quantidade de dados que está a carregar a partir destas métricas e como minimizar os encargos relacionados.
Trabalhar com métricas de processo
Pode visualizar os dados das métricas de processo com gráficos criados através do Explorador de métricas ou de painéis de controlo personalizados. Para mais informações, consulte o artigo Usar painéis de controlo e gráficos. Além disso, o Cloud Monitoring inclui dados de métricas de processos em dois painéis de controlo predefinidos:
- Painel de controlo Instâncias de VM na Monitorização
- Painel de controlo Detalhes da instância de VM no Compute Engine
As secções seguintes descrevem estes painéis de controlo.
Monitorização: veja métricas de processos agregadas
Para ver as métricas de processos agregadas num âmbito de métricas, aceda ao separador Processos no painel de controlo Instâncias de VM:
-
Na Google Cloud consola, aceda à página
 Painéis de controlo:
Painéis de controlo:
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Monitorização.
Selecione o painel de controlo Instâncias de VM na lista.
Clique em Processos.
A captura de ecrã seguinte mostra um exemplo da página Monitorização Processos:
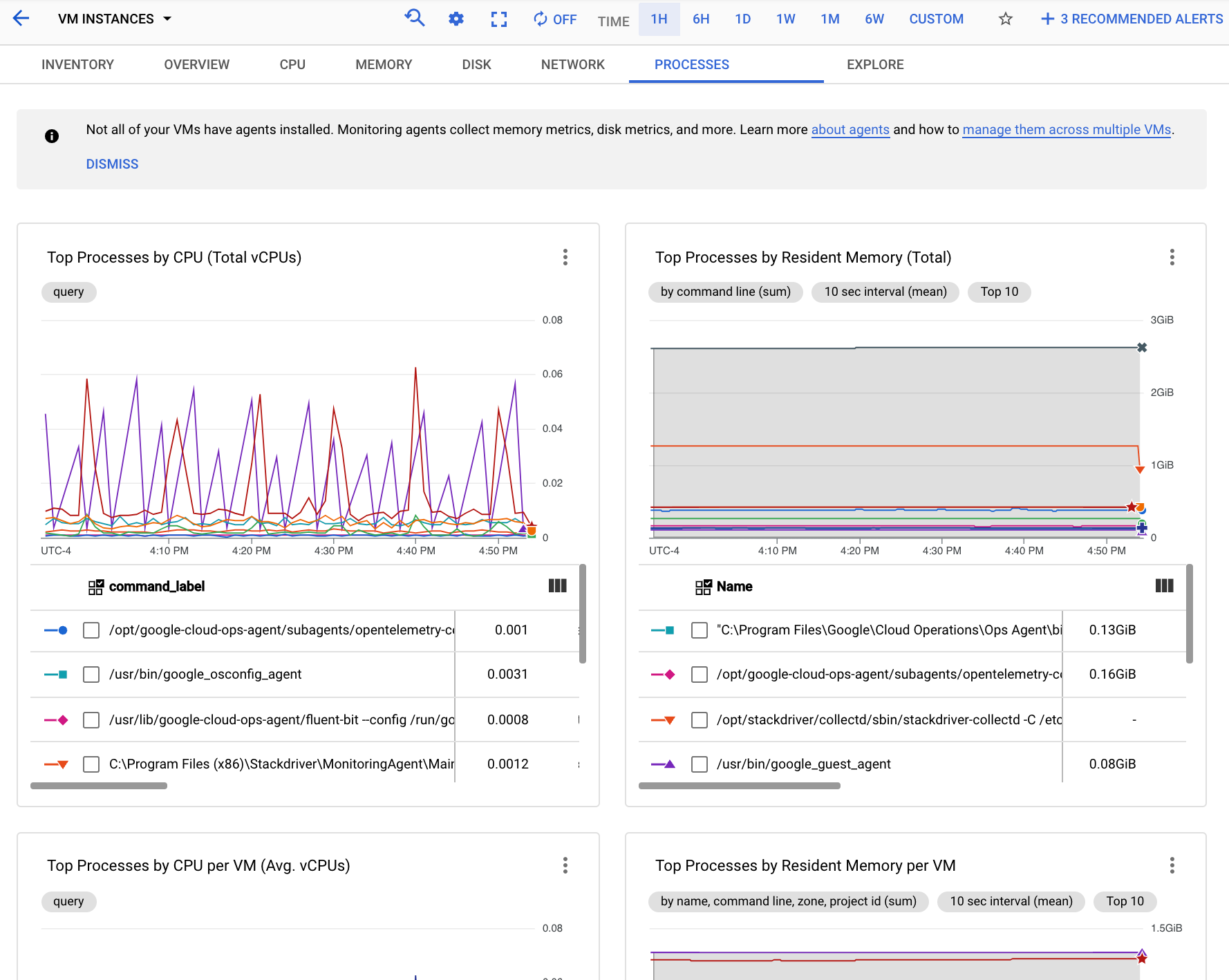
Pode usar os gráficos no separador Processos para identificar os processos no âmbito das suas métricas que estão a consumir mais CPU e memória, e que têm a utilização de disco mais elevada.
Compute Engine: veja as métricas de desempenho das VMs que consomem mais recursos
Para ver os gráficos de desempenho que mostram as cinco VMs que consomem mais recursos no seu Google Cloud projeto, aceda ao separador Observabilidade das suas instâncias de VM:
-
Na Google Cloud consola, aceda à página Instâncias de VM:
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cuja legenda seja Compute Engine.
- Clique em Observabilidade.
A captura de ecrã seguinte mostra um exemplo da página Observability do Compute Engine.
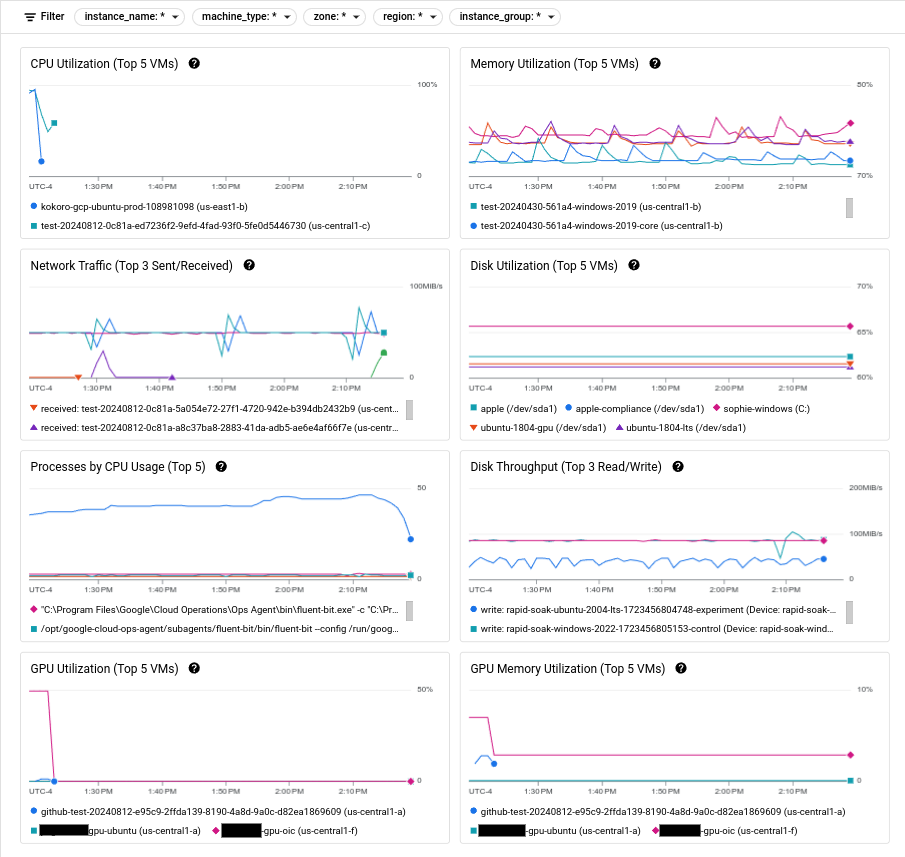
Para obter informações sobre a utilização destas métricas para diagnosticar problemas com as suas VMs, consulte o artigo Resolução de problemas de desempenho da VM.
Compute Engine: veja métricas de processos por VM
Para ver uma lista dos processos em execução numa única máquina virtual (VM) do Compute Engine e gráficos dos processos com o consumo de recursos mais elevado, aceda ao separador Observabilidade da VM:
-
Na Google Cloud consola, aceda à página Instâncias de VM:
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cuja legenda seja Compute Engine.
No separador Instâncias, clique no nome de uma VM para inspecionar.
Clique em Observabilidade para ver as métricas desta VM.
No painel de navegação do separador Observabilidade, selecione Processos.
A captura de ecrã seguinte mostra um exemplo da página Processos do Compute Engine:
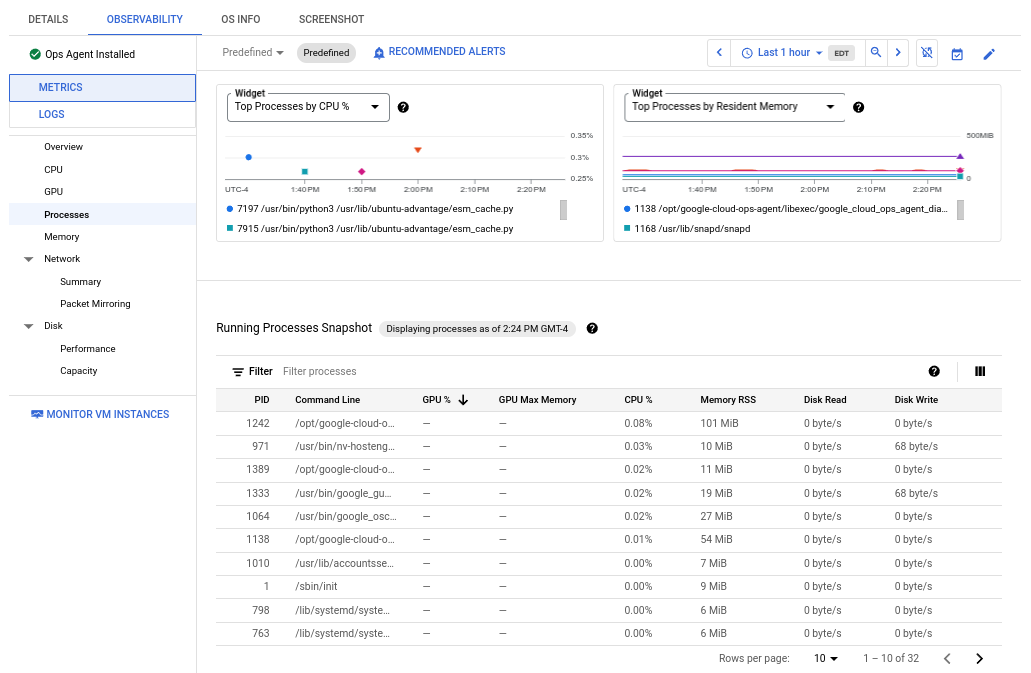
As métricas de processo são retidas durante um período máximo de 24 horas, pelo que pode usá-las para analisar dados anteriores e atribuir anomalias no consumo de recursos a processos específicos ou identificar os consumidores de recursos mais caros. Por exemplo, o gráfico seguinte mostra os processos que consomem as percentagens mais elevadas de recursos da CPU. Pode usar o seletor de intervalo de tempo para alterar o intervalo de tempo do gráfico. O seletor de intervalo de tempo oferece valores predefinidos, como a hora mais recente, e também permite introduzir um intervalo de tempo personalizado.
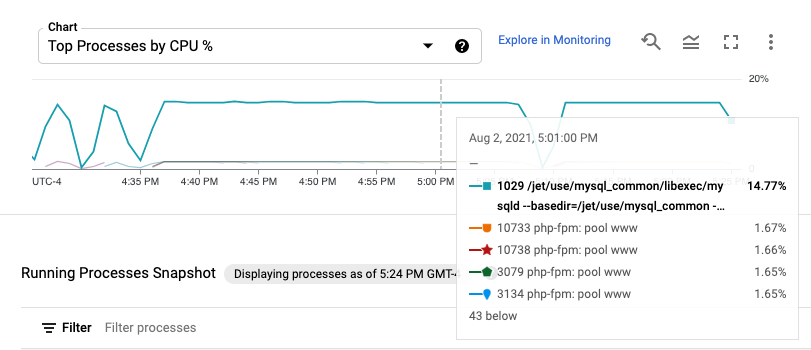
A tabela Processos em execução apresenta uma lista do consumo de recursos
análoga à saída do comando top do Linux.
Por predefinição, a tabela mostra uma vista geral dos dados mais recentes.
No entanto, se selecionar um intervalo de tempo num gráfico que termine no passado, a tabela mostra os processos em execução no final desse intervalo.
Para obter informações sobre a utilização destas métricas para diagnosticar problemas com as suas VMs, consulte o artigo Resolução de problemas de desempenho da VM.
Métricas de processos recolhidas pelo agente
Os agentes Linux recolhem todas as métricas indicadas na tabela seguinte de processos em execução em VMs do Compute Engine e, através do agente de monitorização, VMs do Amazon Elastic Compute Cloud (EC2). Pode desativar a respetiva recolha pelo agente de operações (versões 2.0.0 e superiores) e pelo agente de monitorização antigo.
Também pode desativar a recolha de métricas de processos para o agente Ops (versões 2.0.0 e superiores) executado em VMs do Windows.
Para mais informações, consulte o artigo Desativar métricas de processos.
Se quiser desativar a recolha destas métricas no Windows, recomendamos que atualize para a versão 2.0.0 ou superior do agente de operações. Para mais informações, consulte o artigo Instalar o agente de operações.
Tabela de métricas de processos
As strings "metric type" nesta tabela têm de ter o prefixo
agent.googleapis.com/processes/. Esse prefixo foi omitido das entradas na tabela.
Ao consultar uma etiqueta, use o prefixo metric.labels.; por exemplo, metric.labels.LABEL="VALUE".
| Tipo de métrica Fase de lançamento (Níveis da hierarquia de recursos) Nome a apresentar |
|
|---|---|
| Kind, Type, Unit Recursos monitorizados |
Descrição Etiquetas |
count_by_state
GA
(projeto)
Processos |
|
GAUGE, DOUBLE, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Contagem de processos no estado especificado. Apenas no Linux. Amostrada a cada 60 segundos.
state:
Correr, dormir, zombie, etc.
|
cpu_time
GA
(project)
Process CPU |
|
CUMULATIVE, INT64, us{CPU}
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Tempo da CPU do processo fornecido. Amostrada a cada 60 segundos.
process:
Nome do processo.
user_or_syst:
Se é um utilizador ou um processo do sistema.
command:
Process command.
command_line:
Process command line, 1024 characters maximum.
owner:
Proprietário do processo.
pid:
ID do processo.
|
disk/read_bytes_count
GA
(project)
Process disk read I/O |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Processar I/O de leitura do disco. Apenas no Linux. Amostrada a cada 60 segundos.
process:
Nome do processo.
command:
Process command.
command_line:
Process command line, 1024 characters maximum.
owner:
Proprietário do processo.
pid:
ID do processo.
|
disk/write_bytes_count
GA
(project)
Process disk write I/O |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Processar E/S de escrita no disco. Apenas no Linux. Amostrada a cada 60 segundos.
process:
Nome do processo.
command:
Process command.
command_line:
Process command line, 1024 characters maximum.
owner:
Proprietário do processo.
pid:
ID do processo.
|
fork_count
GA
(project)
Contagem de divisões |
|
CUMULATIVE, INT64, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Número total de processos ramificados. Apenas no Linux. Amostrada a cada 60 segundos. |
rss_usage
GA
(project)
Process resident memory |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Utilização de memória residente do processo especificado. Apenas no Linux. Amostrada a cada 60 segundos.
process:
Nome do processo.
command:
Process command.
command_line:
Process command line, 1024 characters maximum.
owner:
Proprietário do processo.
pid:
ID do processo.
|
vm_usage
GA
(projeto)
Process virtual memory |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Utilização da VM do processo especificado. Amostrada a cada 60 segundos.
process:
Nome do processo.
command:
Process command.
command_line:
Process command line, 1024 characters maximum.
owner:
Proprietário do processo.
pid:
ID do processo.
|
Tabela gerada a 05/09/2025 às 02:07:49 UTC.
Determinar a carregamento atual
Pode usar o Explorador de métricas para ver a quantidade de dados que está a carregar para métricas de processo. Use o seguinte procedimento:
-
Na Google Cloud consola, aceda à página leaderboard Explorador de métricas:
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Monitorização.
Na barra de ferramentas do painel do criador de consultas, selecione o botão cujo nome é code MQL ou code PromQL.
Verifique se a opção PromQL está selecionada no botão Idioma. O botão para alternar o idioma encontra-se na mesma barra de ferramentas que lhe permite formatar a consulta.
Para ver o número total de pontos de métricas de processos para os recursos
gce_instanceeaws_ec2_instance, faça o seguinte:Introduza a seguinte consulta:
sum_over_time( sum by (resource_type) ( label_replace( label_replace( sum(count_over_time({"agent.googleapis.com/processes/cpu_time", monitored_resource="gce_instance"}[1m])), "metric_suffix", "cpu_time", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/read_bytes_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "disk_read_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/write_bytes_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "disk_write_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/rss_usage", monitored_resource="gce_instance"}[1m])), "metric_suffix", "rss_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/vm_usage", monitored_resource="gce_instance"}[1m])), "metric_suffix", "vm_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/count_by_state", monitored_resource="gce_instance"}[1m])), "metric_suffix", "count_by_state", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/fork_count", monitored_resource="gce_instance"}[1m])), "metric_suffix", "fork_count", "", "" ), "resource_type", "gce_instance", "", "" ) or label_replace( label_replace( sum(count_over_time({"agent.googleapis.com/processes/cpu_time", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "cpu_time", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/read_bytes_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "disk_read_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/disk/write_bytes_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "disk_write_bytes_count", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/rss_usage", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "rss_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/vm_usage", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "vm_usage", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/count_by_state", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "count_by_state", "", "" ) or label_replace( sum(count_over_time({"agent.googleapis.com/processes/fork_count", monitored_resource="aws_ec2_instance"}[1m])), "metric_suffix", "fork_count", "", "" ), "resource_type", "aws_ec2_instance", "", "" ) )[1d:] )Clique em Executar consulta. O gráfico resultante mostra os valores de cada tipo de recurso.
Estimar o custo das métricas
Os exemplos de preços de monitorização ilustram como pode estimar o custo do carregamento de métricas. Estes exemplos podem ser aplicados às métricas de processo.
Todas as métricas de processo são amostradas a cada 60 segundos e todas elas escrevem pontos de dados que são contabilizados como oito bytes para fins de preços.
O preço das métricas de processo está a ser definido em 5% do custo de volume padrão usado nos exemplos de preços. Por conseguinte, se assumir que todas as métricas nos cenários descritos nesses exemplos são métricas de processo, pode usar 5% do custo total para cada cenário como uma estimativa do custo das métricas de processo.
Desative a recolha de métricas de processos
Existem várias formas de desativar a recolha destas métricas pelo agente de operações (versões 2.0.0 e superiores) e pelo agente de monitorização antigo no Linux.
Os agentes são executados apenas em VMs do Compute Engine e, para o agente de monitorização, em VMs do Amazon Elastic Compute Cloud (EC2). Estes procedimentos aplicam-se apenas a essas plataformas.
Não pode desativar a recolha pelo agente de operações se estiver a executar versões inferiores a 2.0.0 ou o agente de monitorização antigo no Windows. Se quiser desativar a recolha destas métricas no Windows, recomendamos que atualize para a versão 2.0.0 ou superior do agente de operações. Para mais informações, consulte o artigo Instalar o agente de operações.
O procedimento geral tem o seguinte aspeto:
Estabeleça ligação à VM.
Crie uma cópia do ficheiro de configuração existente como cópia de segurança. Armazene a cópia de segurança fora do diretório de configuração do agente para que o agente não tente carregar ambos os ficheiros. Por exemplo, o seguinte comando faz uma cópia do ficheiro de configuração do agente de monitorização no Linux:
cp /etc/stackdriver/collectd.conf BACKUP_DIR/collectd.conf.bak
Altere a configuração através de uma das opções descritas no seguinte:
Reinicie o agente para aplicar a nova configuração:
- Agente de monitorização:
sudo service stackdriver-agent restart - Ops Agent:
sudo service google-cloud-ops-agent restart
- Agente de monitorização:
Verifique se as métricas de processo já não estão a ser recolhidas para esta VM:
-
Na Google Cloud consola, aceda à página leaderboard Explorador de métricas:
Se usar a barra de pesquisa para encontrar esta página, selecione o resultado cujo subtítulo é Monitorização.
Na barra de ferramentas do painel do criador de consultas, selecione o botão cujo nome é code MQL ou code PromQL.
Verifique se a opção PromQL está selecionada no botão Idioma. O botão para alternar o idioma encontra-se na mesma barra de ferramentas que lhe permite formatar a consulta.
Para um recurso
gce_instance, introduza a seguinte consulta, substituindo VM_NAME pelo nome desta VM:rate({"agent.googleapis.com/processes/cpu_time", monitored_resource="gce_instance", metadata_system_name="VM_NAME"}[1m])Para um recurso
aws_ec2_instance, substituagce_instancena consulta.Clique em Executar consulta.
-
Agente de operações no Linux ou Windows
A localização do ficheiro de configuração do agente de operações depende do sistema operativo:
- Para Linux:
/etc/google-cloud-ops-agent/config.yaml - Para Windows:
C:\Program Files\Google\Cloud Operations\Ops Agent\config\config.yaml
Para desativar a recolha de todas as métricas de processos pelo agente de operações,
adicione o seguinte ao ficheiro config.yaml:
metrics:
processors:
metrics_filter:
type: exclude_metrics
metrics_pattern:
- agent.googleapis.com/processes/*
Isto exclui as métricas de processo da recolha no metrics_filterprocessador que se aplica ao pipeline predefinido no serviço metrics.
Para mais informações sobre as opções de configuração do agente de operações, consulte o artigo Configurar o agente de operações.
Agente de monitorização no Linux
Tem as seguintes opções para desativar a recolha de métricas de processos com o agente de monitorização antigo:
As secções seguintes descrevem cada opção e indicam as vantagens e os riscos associados a essa opção.
Modifique o ficheiro de configuração do agente
Com esta opção, edita diretamente o ficheiro de configuração principal do agente,
/etc/stackdriver/collectd.conf, para remover as secções
que ativam a recolha das métricas de processos.
Procedimento
Existem três grupos de eliminações que tem de fazer no ficheiro collectd.conf:
Elimine a seguinte diretiva
LoadPlugine configuração do plugin:LoadPlugin processes <Plugin "processes"> ProcessMatch "all" ".*" Detail "ps_cputime" Detail "ps_disk_octets" Detail "ps_rss" Detail "ps_vm" </Plugin>Elimine a seguinte diretiva
PostCacheChaine a configuração da cadeiaPostCache:PostCacheChain "PostCache" <Chain "PostCache"> <Rule "processes"> <Match "regex"> Plugin "^processes$" Type "^(ps_cputime|disk_octets|ps_rss|ps_vm)$" </Match> <Target "jump"> Chain "MaybeThrottleProcesses" </Target> Target "stop" </Rule> <Rule "otherwise"> <Match "throttle_metadata_keys"> OKToThrottle false HighWaterMark 5700000000 # 950M * 6 LowWaterMark 4800000000 # 800M * 6 </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>Elimine a cadeia
MaybeThrottleProcessesusada pela cadeiaPostCache:<Chain "MaybeThrottleProcesses"> <Rule "default"> <Match "throttle_metadata_keys"> OKToThrottle true TrackedMetadata "processes:pid" TrackedMetadata "processes:command" TrackedMetadata "processes:command_line" TrackedMetadata "processes:owner" </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>
Vantagens e riscos
- Vantagens
- Reduz os recursos consumidos pelo agente, porque as métricas nunca são recolhidas.
- Se tiver feito outras alterações ao seu ficheiro
collectd.conf, pode preservar facilmente essas alterações.
- Riscos
- Tem de usar a conta do
rootpara editar este ficheiro de configuração. - Corre o risco de introduzir erros tipográficos no ficheiro.
- Tem de usar a conta do
Substitua o ficheiro de configuração do agente
Com esta opção, substitui o ficheiro de configuração principal do agente por uma versão pré-editada que tem as secções relevantes removidas.
Procedimento
Transfira o ficheiro pré-editado
collectd-no-process-metrics.confdo repositório do GitHub para o diretório/tmpe, em seguida, faça o seguinte:cd /tmp && curl -sSO https://raw.githubusercontent.com/Stackdriver/agent-packaging/master/collectd-no-process-metrics.confSubstitua o ficheiro
collectd.confexistente pelo ficheiro pré-editado:cp /tmp/collectd-no-process-metrics.conf /etc/stackdriver/collectd.conf
Vantagens e riscos
- Vantagens
- Reduz os recursos consumidos pelo agente porque as métricas nunca são recolhidas.
- Não tem de editar manualmente o ficheiro como
root. - As ferramentas de gestão de configurações podem substituir facilmente um ficheiro.
- Riscos
- Se tiver feito outras alterações ao ficheiro
collectd.conf, tem de as unir ao ficheiro de substituição.
- Se tiver feito outras alterações ao ficheiro
Resolução de problemas
Os procedimentos descritos neste documento são alterações à configuração do agente, pelo que os seguintes problemas são mais prováveis:
- Privilégio insuficiente para editar os ficheiros de configuração. Os ficheiros de configuração têm de ser editados a partir da conta
root. - Introdução de erros tipográficos no ficheiro de configuração, se o editar diretamente.
Para informações sobre a resolução de outros problemas, consulte o artigo Resolução de problemas do agente de monitorização.
Agente de monitorização no Windows
Não pode desativar a recolha de métricas de processos pelo agente de monitorização antigo em execução em VMs do Windows. Este agente não é configurável. Se quiser desativar a recolha destas métricas no Windows, recomendamos que atualize para a versão 2.0.0 ou superior do agente de operações. Para mais informações, consulte o artigo Instalar o agente de operações.
Se estiver a executar o agente de operações, consulte o artigo Agente de operações no Linux ou Windows.