Per impostazione predefinita, Ops Agent e l'agente Monitoring legacy sono configurati per
raccogliere metriche che acquisiscono informazioni sui processi in esecuzione sulle
macchine virtuali (VM) Compute Engine. Puoi anche raccogliere queste metriche
sulle VM Amazon Elastic Compute Cloud (EC2) utilizzando l'agente Monitoring.
Questo insieme di metriche, chiamate metriche di processo, è identificabile dal prefisso agent.googleapis.com/processes. Queste metriche
non vengono raccolte su Google Kubernetes Engine (GKE).
A partire dal 6 agosto 2021, verranno introdotti addebiti per queste metriche, come descritto nella sezione delle metriche addebitabili della pagina Prezzi di Google Cloud Observability. Il set di metriche di processo è classificato come addebitabile, ma gli addebiti non sono mai stati implementati.
Questo documento descrive gli strumenti per visualizzare le metriche di processo, come determinare la quantità di dati che stai importando da queste metriche e come ridurre al minimo gli addebiti correlati.
Utilizzo delle metriche di processo
Puoi visualizzare i dati delle metriche di processo con grafici creati utilizzando Metrics Explorere o dashboard personalizzate. Per ulteriori informazioni, vedi Utilizzare dashboard e grafici. Inoltre, Cloud Monitoring include i dati delle metriche di processo in due dashboard predefinite:
- Dashboard Istanze VM in Monitoring
- Dashboard Dettagli dell'istanza VM in Compute Engine
Le sezioni seguenti descrivono queste dashboard.
Monitoraggio: visualizza le metriche di processo aggregate
Per visualizzare le metriche di processo aggregate in un ambito delle metriche, vai alla scheda Processi nella dashboard Istanze VM:
-
Nella console Google Cloud , vai alla pagina
 Dashboard:
Dashboard:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
Seleziona la dashboard Istanze VM dall'elenco.
Fai clic su Processi.
Lo screenshot seguente mostra un esempio della pagina Processi di Monitoring:
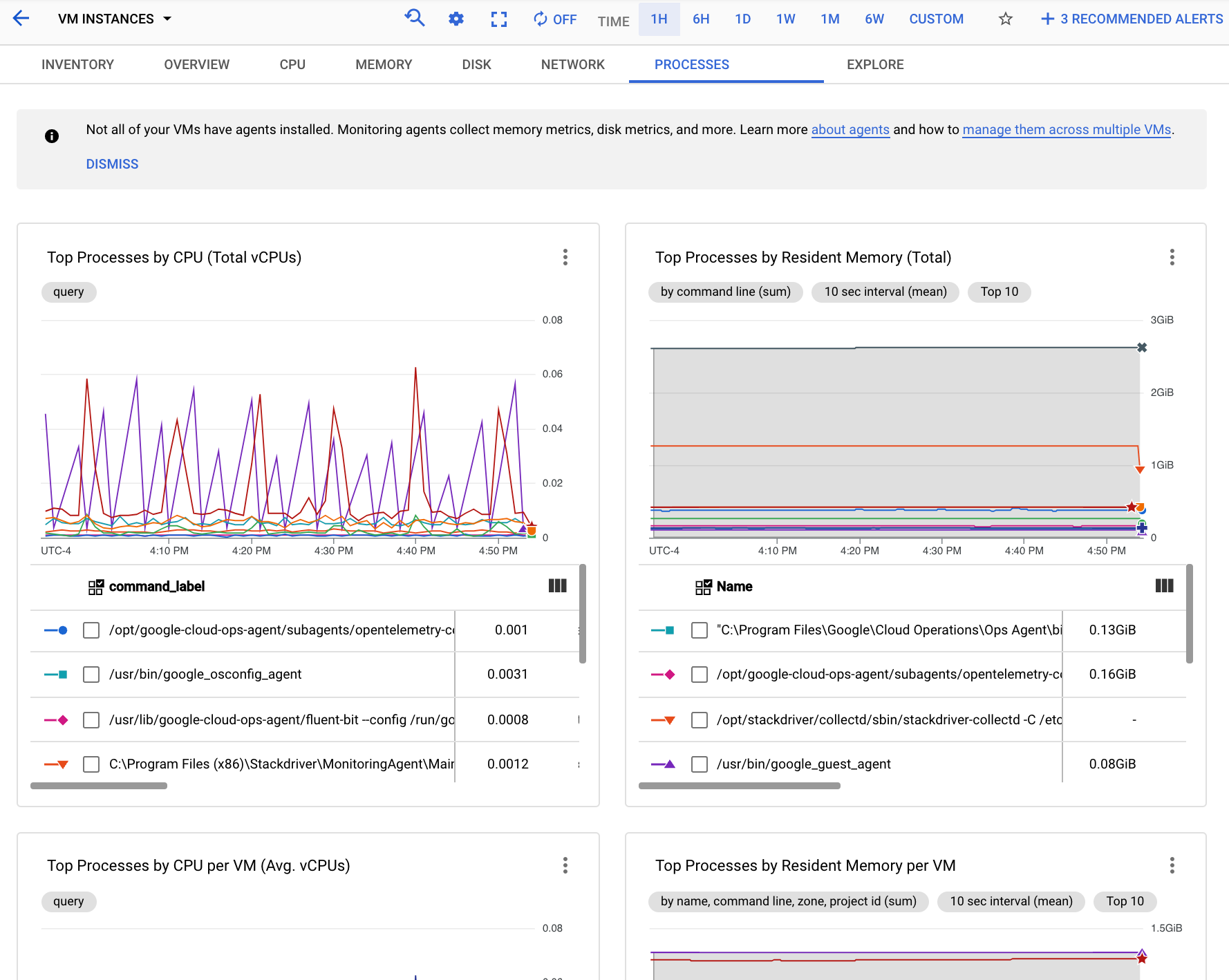
Puoi utilizzare i grafici nella scheda Processi per identificare i processi nell'ambito delle metriche che consumano più CPU e memoria e che hanno l'utilizzo del disco più elevato.
Compute Engine: visualizza le metriche di rendimento per le VM che consumano più risorse
Per visualizzare i grafici delle prestazioni che mostrano le cinque VM che consumano la maggior parte di una risorsa nel tuo progetto Google Cloud , vai alla scheda Osservabilità per le tue istanze VM:
-
Nella Google Cloud console, vai alla pagina Istanze VM.
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Compute Engine.
- Fai clic su Osservabilità.
Lo screenshot seguente mostra un esempio della pagina Osservabilità di Compute Engine.
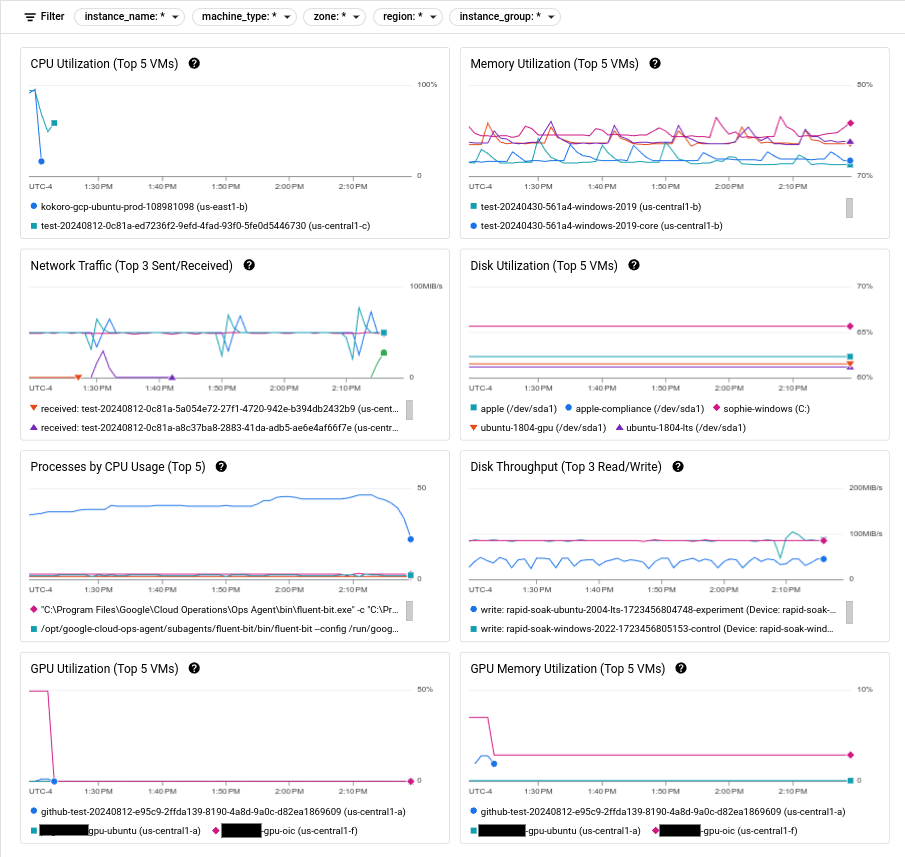
Per informazioni sull'utilizzo di queste metriche per diagnosticare i problemi relativi alle tue VM, consulta la sezione Risoluzione dei problemi di prestazioni delle VM.
Compute Engine: visualizza le metriche di processo per VM
Per visualizzare un elenco dei processi in esecuzione su una singola macchina virtuale (VM) Compute Engine e grafici per i processi con il consumo di risorse più elevato, vai alla scheda Osservabilità per la VM:
-
Nella Google Cloud console, vai alla pagina Istanze VM.
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Compute Engine.
Nella scheda Istanze, fai clic sul nome di una VM da ispezionare.
Fai clic su Osservabilità per visualizzare le metriche per questa VM.
Nel riquadro di navigazione della scheda Osservabilità, seleziona Processi.
Lo screenshot seguente mostra un esempio della pagina Processi di Compute Engine:
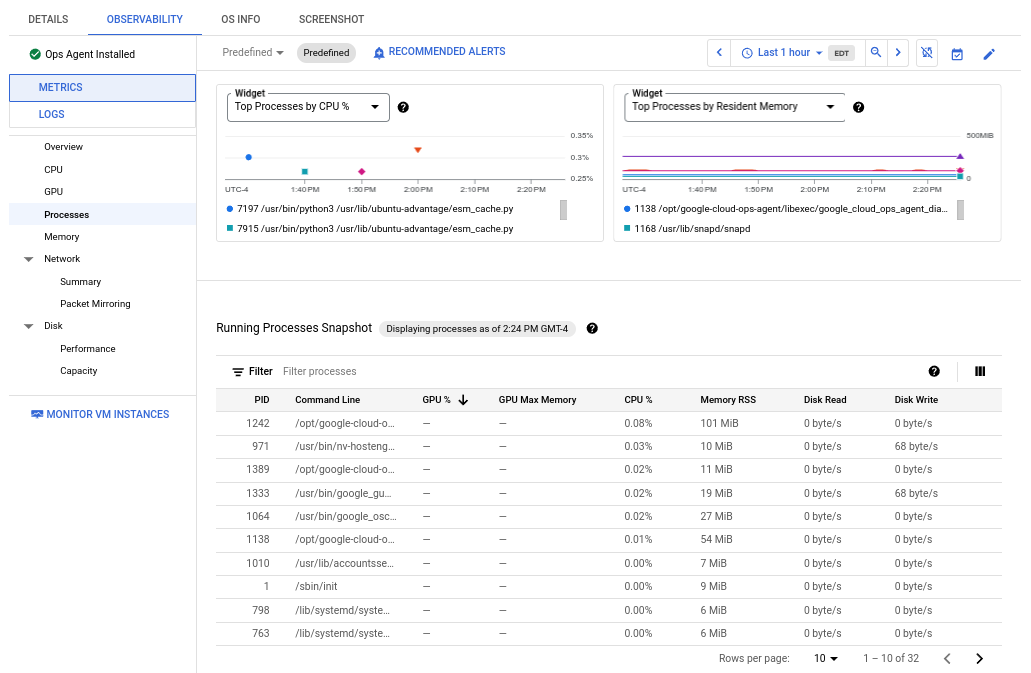
Le metriche di processo vengono conservate per un massimo di 24 ore, quindi puoi utilizzarle per esaminare i dati storici e attribuire anomalie nel consumo di risorse a processi specifici o identificare i consumatori di risorse più costosi. Ad esempio, il seguente grafico mostra i processi che consumano le percentuali più alte di risorse CPU. Puoi utilizzare il selettore dell'intervallo di tempo per modificare l'intervallo di tempo del grafico. Il selettore dell'intervallo di tempo offre valori preimpostati, come l'ora più recente, e ti consente anche di inserire un intervallo di tempo personalizzato.
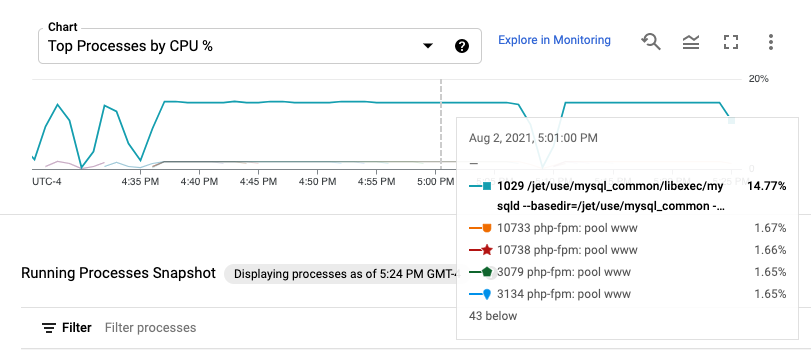
La tabella Processi in esecuzione fornisce un elenco del consumo di risorse
analogo all'output del comando Linux top.
Per impostazione predefinita, la tabella mostra uno snapshot dei dati più recenti.
Tuttavia, se selezioni un intervallo di tempo su un grafico che termina nel passato,
la tabella mostra i processi in esecuzione alla fine di quell'intervallo.
Per informazioni sull'utilizzo di queste metriche per diagnosticare i problemi relativi alle tue VM, consulta la sezione Risoluzione dei problemi di prestazioni delle VM.
Metriche di processo raccolte dall'agente
Gli agenti Linux raccolgono tutte le metriche elencate nella tabella seguente dai processi in esecuzione sulle VM Compute Engine e, utilizzando l'agente Monitoring, sulle VM Amazon Elastic Compute Cloud (EC2). Puoi disattivarne la raccolta da parte di Ops Agent (versioni 2.0.0 e successive) e dell'agente Monitoring legacy.
Puoi anche disattivare la raccolta delle metriche di processo per Ops Agent (versioni 2.0.0 e successive) in esecuzione su VM Windows.
Per saperne di più, consulta Disattivazione delle metriche dei processi.
Se vuoi disattivare la raccolta di queste metriche su Windows, ti consigliamo di eseguire l'upgrade a Ops Agent versione 2.0.0 o successiva. Per maggiori informazioni, vedi Installazione di Ops Agent.
Tabella delle metriche di processo
Le stringhe "tipo di metrica" in questa tabella devono essere precedute
dal prefisso agent.googleapis.com/processes/. Questo prefisso è stato
omesso dalle voci della tabella.
Quando esegui una query su un'etichetta, utilizza il prefisso metric.labels.; ad esempio, metric.labels.LABEL="VALUE".
| Tipo di metrica Fase di lancio (Livelli della gerarchia delle risorse) Nome visualizzato |
|
|---|---|
| Tipo, Tipo, Unità Risorse monitorate |
Descrizione Etichette |
count_by_state
GA
(progetto)
Processi |
|
GAUGE, DOUBLE, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Conteggio dei processi nel determinato stato. Solo per Linux. Campionamento eseguito ogni 60 secondi.
state:
Corsa, sonno, zombie e così via.
|
cpu_time
GA
(progetto)
CPU processo |
|
CUMULATIVE, INT64, us{CPU}
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Tempo di CPU del processo specificato. Campionamento eseguito ogni 60 secondi.
process:
Nome del processo.
user_or_syst:
Indica se si tratta di un processo utente o di sistema.
command:
Elabora comando.
command_line:
Riga di comando del processo, massimo 1024 caratteri.
owner:
Proprietario del processo.
pid:
ID processo.
|
disk/read_bytes_count
GA
(project)
Process disk read I/O |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Elabora l'I/O di lettura del disco. Solo per Linux. Campionamento eseguito ogni 60 secondi.
process:
Nome del processo.
command:
Elabora comando.
command_line:
Riga di comando del processo, massimo 1024 caratteri.
owner:
Proprietario del processo.
pid:
ID processo.
|
disk/write_bytes_count
GA
(progetto)
Elabora I/O di scrittura disco |
|
CUMULATIVE, INT64, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Elabora l'I/O di scrittura del disco. Solo per Linux. Campionamento eseguito ogni 60 secondi.
process:
Nome del processo.
command:
Elabora comando.
command_line:
Riga di comando del processo, massimo 1024 caratteri.
owner:
Proprietario del processo.
pid:
ID processo.
|
fork_count
GA
(project)
Numero di fork |
|
CUMULATIVE, INT64, 1
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Numero totale di processi forkati. Solo per Linux. Campionamento eseguito ogni 60 secondi. |
rss_usage
GA
(progetto)
Memoria residente del processo |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Utilizzo della memoria residente del processo specificato. Solo per Linux. Campionamento eseguito ogni 60 secondi.
process:
Nome del processo.
command:
Elabora comando.
command_line:
Riga di comando del processo, massimo 1024 caratteri.
owner:
Proprietario del processo.
pid:
ID processo.
|
vm_usage
GA
(progetto)
Process virtual memory |
|
GAUGE, DOUBLE, By
aws_ec2_instance baremetalsolution.googleapis.com/Instance gce_instance |
Utilizzo della VM del processo specificato. Campionamento eseguito ogni 60 secondi.
process:
Nome del processo.
command:
Elabora comando.
command_line:
Riga di comando del processo, massimo 1024 caratteri.
owner:
Proprietario del processo.
pid:
ID processo.
|
Tabella generata il giorno 2025-08-08 alle ore 23:40:45 UTC.
Determinazione dell'importazione corrente
Puoi utilizzare Metrics Explorer per visualizzare la quantità di dati che stai importando per le metriche di processo. Utilizza la seguente procedura:
-
Nella console Google Cloud , vai alla pagina leaderboard Esplora metriche:
Se utilizzi la barra di ricerca per trovare questa pagina, seleziona il risultato con il sottotitolo Monitoring.
Nella barra degli strumenti del riquadro del generatore di query, seleziona il pulsante il cui nome è code MQL o code PromQL.
Verifica che MQL sia selezionato nel pulsante di attivazione/disattivazione Lingua. Il pulsante di attivazione/disattivazione della lingua si trova nella stessa barra degli strumenti che ti consente di formattare la query.
Per visualizzare il numero totale di punti delle metriche di processo per le risorse
gce_instanceeaws_ec2_instance:Inserisci la seguente query:
def tagged_process_metric name = metric 'agent.googleapis.com/processes/'$name | add [metric_suffix: $name]; def process_metrics resource_type = fetch $resource_type | { @tagged_process_metric 'cpu_time' ; @tagged_process_metric 'disk/read_bytes_count' ; @tagged_process_metric 'disk/write_bytes_count' ; @tagged_process_metric 'rss_usage' ; @tagged_process_metric 'vm_usage' ; @tagged_process_metric 'count_by_state' ; @tagged_process_metric 'fork_count' } | within 1d | group_by [metric_suffix], 1m, [row_count: row_count()] | union; { @process_metrics 'gce_instance' ; @process_metrics 'aws_ec2_instance' } | outer_join 0, 0 | { rename [], [out: val(0)] | add [resource_type: 'gce_instance'] ; rename [], [out: val(1)] | add [resource_type: 'aws_ec2_instance'] } | union | group_by drop[metric_suffix], 1d, .sumFai clic su Esegui query. Il grafico risultante mostra i valori per ogni tipo di risorsa.
Stima del costo delle metriche
Gli esempi di prezzi di Monitoring mostrano come stimare il costo dell'importazione delle metriche. Questi esempi possono essere applicati alle metriche di processo.
Tutte le metriche di processo vengono campionate ogni 60 secondi e tutte scrivono punti dati conteggiati come 8 byte ai fini della determinazione del prezzo.
Il prezzo delle metriche di processo è stato fissato al 5% del costo del volume standard utilizzato negli esempi di prezzi. Pertanto, se presumi che tutte le metriche negli scenari descritti in questi esempi siano metriche di processo, puoi utilizzare il 5% del costo totale per ogni scenario come stima del costo delle metriche di processo.
Disattivare la raccolta delle metriche dei processi
Esistono diversi modi per disattivare la raccolta di queste metriche da parte di Ops Agent (versioni 2.0.0 e successive) e da parte dell'agente Monitoring legacy su Linux.
Gli agenti vengono eseguiti solo su VM di Compute Engine e, per l'agente Monitoring, su VM Amazon Elastic Compute Cloud (EC2). Queste procedure si applicano solo a queste piattaforme.
Non puoi disattivare la raccolta da parte di Ops Agent se utilizzi versioni inferiori alla 2.0.0 o l'agente Monitoring legacy su Windows. Se vuoi disattivare la raccolta di queste metriche su Windows, ti consigliamo di eseguire l'upgrade a Ops Agent versione 2.0.0 o successiva. Per maggiori informazioni, vedi Installazione di Ops Agent.
La procedura generale è la seguente:
Connettiti alla VM.
Crea una copia del file di configurazione esistente come backup. Memorizza la copia di backup al di fuori della directory di configurazione dell'agente, in modo che l'agente non tenti di caricare entrambi i file. Ad esempio, il seguente comando crea una copia del file di configurazione dell'agente Monitoring su Linux:
cp /etc/stackdriver/collectd.conf BACKUP_DIR/collectd.conf.bak
Modifica la configurazione utilizzando una delle opzioni descritte di seguito:
Riavvia l'agente per applicare la nuova configurazione:
- Agente Monitoring:
sudo service stackdriver-agent restart - Agente operativo:
sudo service google-cloud-ops-agent restart
- Agente Monitoring:
Verifica che le metriche di processo non vengano più raccolte per questa VM:
Seleziona Esplora metriche.
Fai clic su MQL.
Per una risorsa
gce_instance, inserisci la seguente query, sostituendo VM_NAME con il nome di questa VM:fetch gce_instance | metric 'agent.googleapis.com/processes/cpu_time' | filter (metadata.system_labels.name == 'VM_NAME') | align rate(1m) | every 1m
Per una risorsa
aws_ec2_instance, sostituiscigce_instancenella query.Fai clic su Esegui query.
Ops Agent su Linux o Windows
La posizione del file di configurazione per l&#Ops Agent dipende dal sistema operativo:
- Per Linux:
/etc/google-cloud-ops-agent/config.yaml - Per Windows:
C:\Program Files\Google\Cloud Operations\Ops Agent\config\config.yaml
Per disattivare la raccolta di tutte le metriche dei processi da parte di Ops Agent,
aggiungi quanto segue al file config.yaml:
metrics:
processors:
metrics_filter:
type: exclude_metrics
metrics_pattern:
- agent.googleapis.com/processes/*
Ciò esclude le metriche dei processi dalla raccolta nel metrics_filter
che si applica alla pipeline predefinita nel servizio metrics.
Per maggiori informazioni sulle opzioni di configurazione di Ops Agent, vedi Configurazione di Ops Agent.
Agente Monitoring su Linux
Per disattivare la raccolta delle metriche dei processi con l'agente Monitoring legacy, hai a disposizione le seguenti opzioni:
Le sezioni seguenti descrivono ogni opzione ed elencano i vantaggi e i rischi associati.
Modifica il file di configurazione dell'agente
Con questa opzione, modifichi direttamente il file di configurazione principale dell'agente, /etc/stackdriver/collectd.conf, per rimuovere le sezioni che attivano la raccolta delle metriche di processo.
Procedura
Devi apportare tre gruppi di eliminazioni al file
collectd.conf:
Elimina la seguente direttiva
LoadPlugine la configurazione del plug-in:LoadPlugin processes <Plugin "processes"> ProcessMatch "all" ".*" Detail "ps_cputime" Detail "ps_disk_octets" Detail "ps_rss" Detail "ps_vm" </Plugin>Elimina la seguente direttiva
PostCacheChaine la configurazione della catenaPostCache:PostCacheChain "PostCache" <Chain "PostCache"> <Rule "processes"> <Match "regex"> Plugin "^processes$" Type "^(ps_cputime|disk_octets|ps_rss|ps_vm)$" </Match> <Target "jump"> Chain "MaybeThrottleProcesses" </Target> Target "stop" </Rule> <Rule "otherwise"> <Match "throttle_metadata_keys"> OKToThrottle false HighWaterMark 5700000000 # 950M * 6 LowWaterMark 4800000000 # 800M * 6 </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>Elimina la catena
MaybeThrottleProcessesutilizzata dalla catenaPostCache:<Chain "MaybeThrottleProcesses"> <Rule "default"> <Match "throttle_metadata_keys"> OKToThrottle true TrackedMetadata "processes:pid" TrackedMetadata "processes:command" TrackedMetadata "processes:command_line" TrackedMetadata "processes:owner" </Match> <Target "write"> Plugin "write_gcm" </Target> </Rule> </Chain>
Vantaggi e rischi
- Vantaggi
- Riduzione delle risorse consumate dall'agente, perché le metriche non vengono mai raccolte.
- Se hai apportato altre modifiche al file
collectd.conf, potresti riuscire a conservarle facilmente.
- Rischi
- Per modificare questo file di configurazione, devi utilizzare l'account
root. - Rischi di introdurre errori tipografici nel file.
- Per modificare questo file di configurazione, devi utilizzare l'account
Sostituisci il file di configurazione dell'agente
Con questa opzione, sostituisci il file di configurazione principale dell'agente con una versione pre-modificata in cui sono state rimosse le sezioni pertinenti.
Procedura
Scarica il file pre-modificato,
collectd-no-process-metrics.conf, dal repository GitHub nella directory/tmp, quindi esegui le seguenti operazioni:cd /tmp && curl -sSO https://raw.githubusercontent.com/Stackdriver/agent-packaging/master/collectd-no-process-metrics.confSostituisci il file
collectd.confesistente con il file pre-modificato:cp /tmp/collectd-no-process-metrics.conf /etc/stackdriver/collectd.conf
Vantaggi e rischi
- Vantaggi
- Riduzione delle risorse consumate dall'agente perché le metriche non vengono mai raccolte.
- Non devi modificare manualmente il file come
root. - Gli strumenti di gestione della configurazione possono sostituire facilmente un file.
- Rischi
- Se hai apportato altre modifiche al file
collectd.conf, devi unire queste modifiche al file sostitutivo.
- Se hai apportato altre modifiche al file
Risoluzione dei problemi
Le procedure descritte in questo documento sono modifiche alla configurazione dell'agente, quindi i problemi più probabili sono:
- Privilegi insufficienti per modificare i file di configurazione. I file di configurazione
devono essere modificati dall'account
root. - Introduzione di errori tipografici nel file di configurazione, se lo modifica direttamente.
Per informazioni sulla risoluzione di altri problemi, consulta la sezione Risoluzione dei problemi dell'agente di monitoraggio.
Agente Monitoring su Windows
Non puoi disabilitare la raccolta di metriche dei processi da parte dell'agente Monitoring legacy in esecuzione su VM Windows. Questo agente non è configurabile. Se vuoi disattivare la raccolta di queste metriche su Windows, ti consigliamo di eseguire l'upgrade a Ops Agent versione 2.0.0 o successiva. Per maggiori informazioni, vedi Installazione di Ops Agent.
Se esegui Ops Agent, consulta Ops Agent su Linux o Windows.