Vertex AI Platform の
Gemini モデルで強化されたエンタープライズ対応 AI でイノベーションを加速
Vertex AI は、生成 AI を構築して使用するためのフルマネージド統合 AI 開発プラットフォームです。Vertex AI Studio、Agent Builder、200 以上の基盤モデルにアクセスして活用できます。
新規のお客様には、Vertex AI やその他の Google Cloud プロダクトをお試しいただける無料クレジット最大 $300 分を差し上げます。
機能
Google の高性能マルチモーダル モデル、Gemini
Vertex AI では、Google の最新の Gemini モデルにアクセスできます。Gemini は、実質的にあらゆる入力を理解し、さまざまな種類の情報を組み合わせ、ほぼすべての出力を生成できます。Vertex AI Studio では、テキスト、画像、動画、コードを使用したプロンプトを Gemini に入力してテストを行えます。Gemini の高度な推論機能と最先端の生成機能を使用して、画像からのテキスト抽出、画像テキストの JSON への変換、アップロードされた画像に関する回答の生成のためのサンプル プロンプトを試して、次世代の AI アプリケーションを構築できます。

200 以上の生成 AI モデルと各種ツール
Model Garden では、Google 製(Gemini、Imagen、Chirp、Veo)、サードパーティ製(Anthropic の Claude Model Family)、オープンモデル(Gemma、Llama 3.2)と、幅広いモデルからお選びいただけます。拡張機能を使用すると、モデルがリアルタイムの情報を取得してアクションをトリガーできるようになります。Google のテキストモデル、画像モデル、コードモデルのさまざまなチューニング オプションを使用して、モデルをユースケース用にカスタマイズします。
生成 AI モデルとフルマネージド ツールにより、プロトタイプの作成、カスタマイズ、統合、およびアプリケーションへのデプロイが容易になります。
オープンかつ統合された AI プラットフォーム
Vertex AI Platform のツールを使用して ML モデルをトレーニング、調整、デプロイすることで、データ サイエンティストは迅速に作業できます。
Vertex AI Notebooks(Colab Enterprise または Workbench を選択可能)は、BigQuery とネイティブに統合されており、すべてのデータおよび AI のワークロードに 1 つのサーフェスを提供します。
Vertex AI Training と Vertex AI Prediction では、選択したオープンソース フレームワークと最適化された AI インフラストラクチャを使用して、トレーニング時間を短縮し、モデルを本番環境に簡単にデプロイできます。
予測 AI と生成 AI のための MLOps
Vertex AI Platform には、データ サイエンティストや ML エンジニアが ML プロジェクトを自動化、標準化、管理するための目的に特化した MLOps ツールが用意されています。
モジュール型ツールにより、開発ライフサイクル全体を通じてチーム間の共同作業を行い、モデルを改善できます。具体的には、Vertex AI Evaluation でユースケースに最適なモデルを特定したり、Vertex AI Pipelines でワークフローをオーケストレートしたり、Model Registry であらゆるモデルを管理したり、Feature Store で ML の特徴をサービング、共有、再利用したり、入力のスキューとドリフトをモニタリングしたりできます。
Agent Builder
Vertex AI Agent Builder を使用すると、デベロッパーはエンタープライズ向け生成 AI エクスペリエンスを簡単に構築、デプロイできます。このサービスでは、優れたグラウンディング、オーケストレーション、カスタマイズ機能とともに、コード不要のエージェント ビルダー コンソールの利便性が提供されます。Vertex AI Agent Builder によって、デベロッパーは組織のデータに基づく幅広い生成 AI エージェントやアプリケーションをすばやく作成できます。
仕組み
Vertex AI には、モデルのトレーニングとデプロイのオプションが複数用意されています。
- 生成 AI では、Gemini 2.5 などの大規模生成 AI モデルにアクセスし、モデルを評価、調整、デプロイして、AI を活用したアプリケーションに使用できます。
- Model Garden では、Vertex AI と厳選されたオープンソース(OSS)モデルとアセットを調査、テスト、カスタマイズ、デプロイできます。
- カスタム トレーニングでは、任意の ML フレームワークの使用、独自のトレーニング コードの記述、ハイパーパラメータ チューニング オプションの選択など、トレーニング プロセスを完全に制御できます。
Vertex AI には、モデルのトレーニングとデプロイのオプションが複数用意されています。
- 生成 AI では、Gemini 2.5 などの大規模生成 AI モデルにアクセスし、モデルを評価、調整、デプロイして、AI を活用したアプリケーションに使用できます。
- Model Garden では、Vertex AI と厳選されたオープンソース(OSS)モデルとアセットを調査、テスト、カスタマイズ、デプロイできます。
- カスタム トレーニングでは、任意の ML フレームワークの使用、独自のトレーニング コードの記述、ハイパーパラメータ チューニング オプションの選択など、トレーニング プロセスを完全に制御できます。
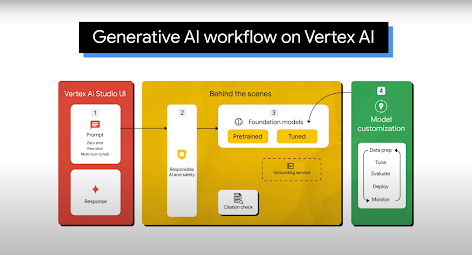
一般的な使用例
Gemini でビルドする
Google Cloud Vertex AI で Gemini API を介して Gemini モデルにアクセスする
- Python
- JavaScript
- Java
- Go
- Curl
コードサンプル
Google Cloud Vertex AI で Gemini API を介して Gemini モデルにアクセスする
- Python
- JavaScript
- Java
- Go
- Curl
アプリケーションにおける生成 AI
Vertex AI の生成 AI の概要を確認する
Vertex AI Studio には、生成 AI モデルを迅速にプロトタイピングしてテストするための Google Cloud コンソール ツールが用意されています。Generative AI Studio を使用して、プロンプト サンプルを使用したモデルのテスト、プロンプトの設計と保存、基盤モデルの調整、音声とテキスト間の変換を行う方法について説明します。
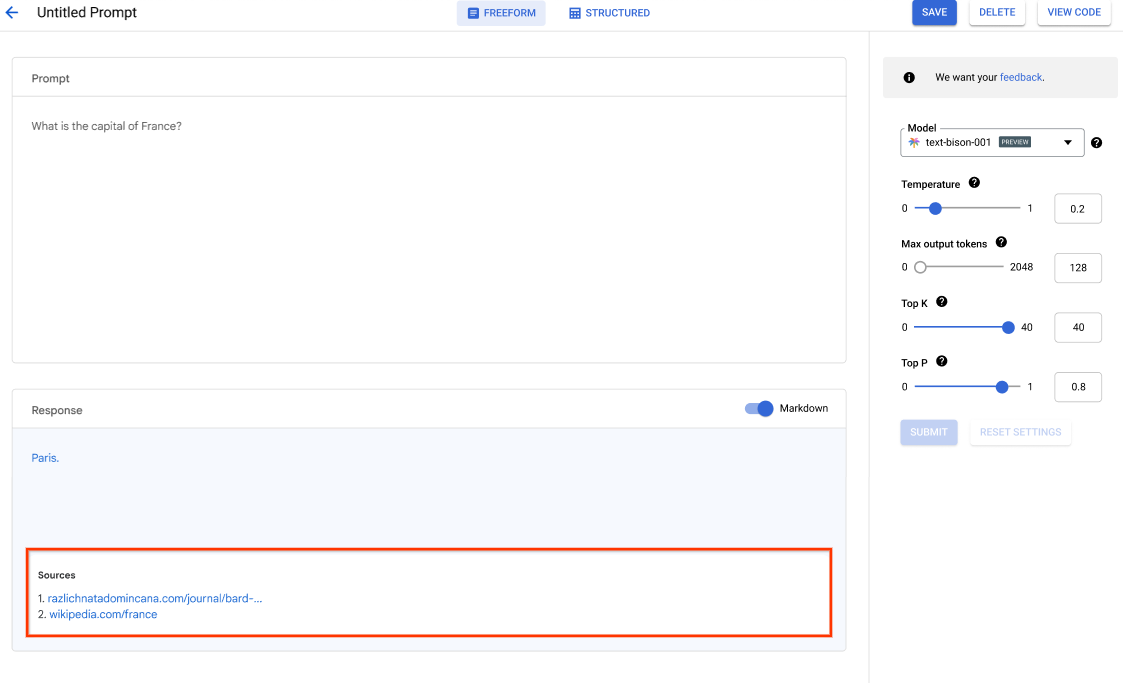
Vertex AI Studio で LLM を調整する方法を学ぶ
チュートリアル、クイックスタート、ラボ
Vertex AI の生成 AI の概要を確認する
Vertex AI Studio には、生成 AI モデルを迅速にプロトタイピングしてテストするための Google Cloud コンソール ツールが用意されています。Generative AI Studio を使用して、プロンプト サンプルを使用したモデルのテスト、プロンプトの設計と保存、基盤モデルの調整、音声とテキスト間の変換を行う方法について説明します。
Vertex AI Studio で LLM を調整する方法を学ぶ
データを抽出、要約、分類する
生成 AI を要約、分類、抽出に使用する
Vertex AI の生成 AI のサポートを利用して、任意の数のタスクを処理するためのテキスト プロンプトを作成する方法を学びます。最も一般的なタスクには、分類、要約、抽出があります。 Vertex AI の Gemini を使用すると、プロンプトの構造と形式を柔軟に指定して設計できます。
チュートリアル、クイックスタート、ラボ
生成 AI を要約、分類、抽出に使用する
Vertex AI の生成 AI のサポートを利用して、任意の数のタスクを処理するためのテキスト プロンプトを作成する方法を学びます。最も一般的なタスクには、分類、要約、抽出があります。 Vertex AI の Gemini を使用すると、プロンプトの構造と形式を柔軟に指定して設計できます。
カスタム ML モデルをトレーニングする
カスタム ML トレーニングの概要とドキュメント
Vertex AI でカスタムモデルをトレーニングするために必要な手順に関するチュートリアル動画を確認する。
チュートリアル、クイックスタート、ラボ
カスタム ML トレーニングの概要とドキュメント
Vertex AI でカスタムモデルをトレーニングするために必要な手順に関するチュートリアル動画を確認する。
本番環境で使用するモデルをデプロイする
バッチ予測またはオンライン予測のためのデプロイ
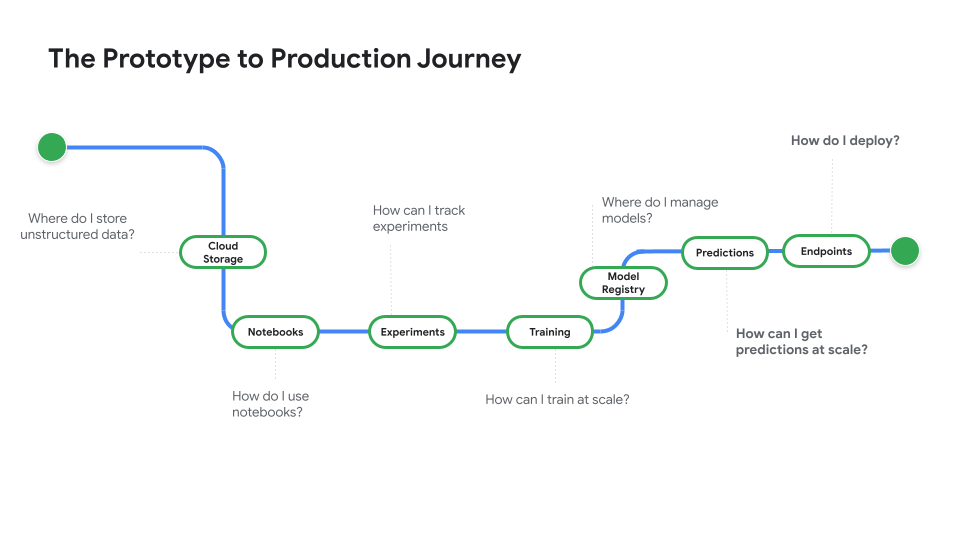
プロトタイプから本番環境へをご覧ください。この動画シリーズは、ノートブック コードからデプロイされたモデルへの移行について説明するものです。
チュートリアル、クイックスタート、ラボ
バッチ予測またはオンライン予測のためのデプロイ
プロトタイプから本番環境へをご覧ください。この動画シリーズは、ノートブック コードからデプロイされたモデルへの移行について説明するものです。
料金
| Vertex AI の料金の仕組み | Vertex AI のツール、ストレージ、コンピューティング、使用した Cloud リソースに対して支払いが発生します。新規のお客様には、Vertex AI やその他の Google Cloud プロダクトをお試しいただける無料クレジット $300 分を差し上げます。 | |
|---|---|---|
| ツールと使用状況 | 説明 | 料金 |
生成 AI | 画像生成のための Imagen モデル 画像入力、文字入力、またはカスタム トレーニングの料金に基づきます。 | 目安 $0.0001 |
テキスト、チャット、コードの生成 1,000 文字単位の入力(プロンプト)と 1,000 文字単位の出力(レスポンス)に基づきます。 | 目安 $0.0001 1,000文字ごと | |
AutoML モデル | 画像データのトレーニング、デプロイ、予測 リソース使用量を反映したノード時間あたりのトレーニング時間と、分類またはオブジェクト検出のいずれであるかに基づきます。 | 目安 $1.375 ノード時間あたり |
動画データのトレーニングと予測 ノード時間あたりの料金と、分類、オブジェクト トラッキング、動作認識に基づきます。 | 目安 $0.462 ノード時間あたり | |
表形式データのトレーニングと予測 ノード時間あたりの料金と、分類 / 回帰、または予測に基づきます。割引の可能性や料金の詳細については、営業担当者にお問い合わせください。 | お問い合わせ | |
テキストデータのアップロード、トレーニング、デプロイ、予測 トレーニングと予測の 1 時間あたりの料金、アップロードしたレガシー データ(PDF のみ)のページ数、テキスト レコード数と予測したページ数に基づきます。 | 目安 $0.05 1 時間あたり | |
カスタム トレーニング済みモデル | カスタムモデルのトレーニング 1 時間あたりに使用されるマシンタイプ、リージョン、使用されたアクセラレータに基づきます。Google の営業担当者を通じて、または料金計算ツールを使用して見積りを取得できます。 | お問い合わせ |
Vertex AI Notebooks | コンピューティングとストレージのリソース Compute Engine および Cloud Storage と同じレートに基づいています。 | プロダクトを参照する |
管理手数料 上記のリソース使用量に加えて、使用するリージョン、インスタンス、ノートブック、マネージド ノートブックに応じて管理手数料が適用されます。詳細を表示 | 詳細を参照する | |
Vertex AI Pipelines | 実行料金と追加料金 実行料金、使用したリソース、追加のサービス手数料に基づきます。 | 目安 $0.03 パイプラインの実行あたり |
Vertex AI Vector Search | 利用料金と構築料金 データのサイズ、実行する秒間クエリ数(QPS)、使用するノード数に基づきます。サンプルを表示。 | 例を参照する |
Vertex AI のすべての機能とサービスの料金の詳細を確認する。
Vertex AI の料金の仕組み
Vertex AI のツール、ストレージ、コンピューティング、使用した Cloud リソースに対して支払いが発生します。新規のお客様には、Vertex AI やその他の Google Cloud プロダクトをお試しいただける無料クレジット $300 分を差し上げます。
テキスト、チャット、コードの生成
1,000 文字単位の入力(プロンプト)と 1,000 文字単位の出力(レスポンス)に基づきます。
Starting at
$0.0001
1,000文字ごと
画像データのトレーニング、デプロイ、予測
リソース使用量を反映したノード時間あたりのトレーニング時間と、分類またはオブジェクト検出のいずれであるかに基づきます。
Starting at
$1.375
ノード時間あたり
動画データのトレーニングと予測
ノード時間あたりの料金と、分類、オブジェクト トラッキング、動作認識に基づきます。
Starting at
$0.462
ノード時間あたり
テキストデータのアップロード、トレーニング、デプロイ、予測
トレーニングと予測の 1 時間あたりの料金、アップロードしたレガシー データ(PDF のみ)のページ数、テキスト レコード数と予測したページ数に基づきます。
Starting at
$0.05
1 時間あたり
カスタムモデルのトレーニング
1 時間あたりに使用されるマシンタイプ、リージョン、使用されたアクセラレータに基づきます。Google の営業担当者を通じて、または料金計算ツールを使用して見積りを取得できます。
お問い合わせ
コンピューティングとストレージのリソース
Compute Engine および Cloud Storage と同じレートに基づいています。
プロダクトを参照する
実行料金と追加料金
実行料金、使用したリソース、追加のサービス手数料に基づきます。
Starting at
$0.03
パイプラインの実行あたり
Vertex AI のすべての機能とサービスの料金の詳細を確認する。
ビジネスケース
生成 AI の可能性を最大限に引き出す

「Google Cloud の生成 AI ソリューションの精度と Vertex AI Platform の実用性のおかげで、この最先端テクノロジーをビジネスの中核に導入し、応答時間 0 分という長期的な目標を達成するために必要な自信が持てました。」
GA Telesis CEO、Abdol Moabery 氏
アナリスト レポート
TKTKT
Google は The Forrester Wave™: AI Infrastructure Solutions, Q1 2024 においてリーダーに選出され、「現在のサービス」と「戦略」の両カテゴリにおいて、評価対象となった全ベンダーの中で最高スコアを獲得しました。
Google が The Forrester Wave™: AI Foundation Models for Language, Q2 2024 のリーダーに選出されました。レポートをお読みください。
Forrester Wave: AI/ML Platforms, Q3 2024 において、Google がリーダーに選出されました。詳細はこちら。











