僅限美國、加拿大或墨西哥
假設您想將圖表的資訊限制為僅來自美國、墨西哥或加拿大的資料,選取圖表並新增下列篩選器:
- 包括/排除: 包括
- 維度: 國家/地區
- 比對類型: IN
- 值:
United States, Canada, Mexico
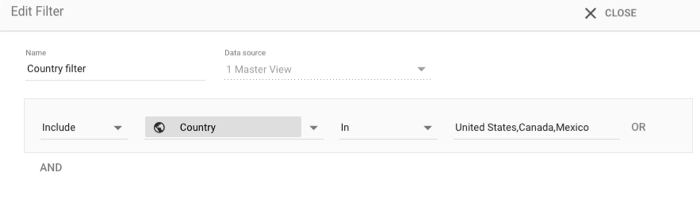
您也可以使用 3 個 OR 子句執行這項操作。但使用 IN 搭配清單會比較簡單。
排除「(未設定)」
如要從圖表中排除「(not set)」值,請使用「排除」篩選器。例如:
- 包括/排除: 排除
- 維度: 廣告活動
- 比對類型: 等於
- 值:
(not set)

在值結尾尋找資料
「符合規則運算式」和「包含規則運算式」運算子可讓您執行更複雜的相符項目。舉例來說,如要篩選資料結尾包含特定值的資料,可以使用行尾標記「$」:
- 包括/排除: 包括
- 維度: 媒介
- 比對類型: 規則運算式比對
- 值:。
*c$

套用至 Analytics 的「媒介」 維度時,您會納入「自然」和「單次點擊出價」等值。
瞭解規則運算式:。*c$
.*表示「比對任何內容」(包括空白),然後是字面上的字母「c」
$代表「行尾」字元。(如要比對字串開頭,請使用 ^)。
以下再舉一例說明:
^c.*k.*$ 會比對以字母 c 開頭的文字,後方可接任何內容,接著是字母 k,最後是字串結尾前的任何內容。這會比對「cook」、「cookie」和「cake」等值。
排除開頭不是英文字母的資料
規則運算式字元類別是功能強大的捷徑,可比對類型字元。例如:
- 包括/排除: 排除
- 比對類型: 規則運算式比對
- 值:
^[[:^alpha:]].*

這樣一來,系統就會篩除非英文字母的字元,例如日文漢字或韓文諺文。
瞭解規則運算式: ^[[:^alpha:]].*
^表示「字串開頭」
[[:alpha:]]是字母 [A-Za-z] 字元類別。[[:^alpha:]] 會否定類別 (「非字母」)
.*表示「比對任何內容」