仅包含美国、加拿大或墨西哥
假设您想将图表的信息限制为仅包含来自美国、墨西哥或加拿大境内的数据。选择图表,然后添加以下过滤条件:
- 包含/排除: 包含
- 维度: 国家/地区
- 匹配类型: IN
- 值:
United States, Canada, Mexico
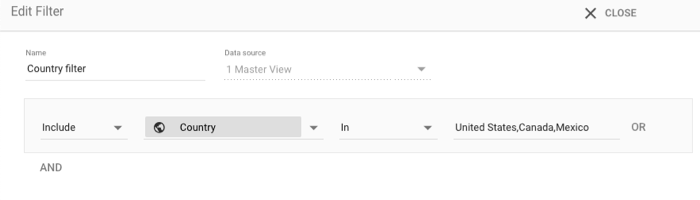
您也可以使用 3 个 OR 子句来实现此目的。但使用 IN 和列表会更简单。
排除“(not set)”
如需从图表中排除“(未设置)”值,请使用“排除”过滤条件。例如:
- 包含/排除: 排除
- 维度: 广告系列
- 匹配类型: 完全一致
- 值:
(not set)

查找值末尾的数据
借助“正则表达式匹配”和“正则表达式包含”运算符,您可以执行更复杂的匹配。例如,如需过滤末尾包含某个值的数据,您可以使用行尾标记 $:
- 包含/排除: 包含
- 维度: 媒体
- 匹配类型: 正则表达式匹配
- 值:。
*c$

如果应用于 Analytics 的 媒介 维度,则可以包含“organic”和“cpc”等值。
了解正则表达式:。*c$
.*表示“匹配任何内容”(包括不匹配任何内容),然后是字面意义上的字母“c”
$表示“行尾”字符。(如需匹配字符串的开头,请使用 ^。)
再举一个例子:
^c.*k.*$ 匹配以字母 c 开头、后跟任意字符、再后跟字母 k、再后跟任意字符直到字符串末尾的文本。这会与“cook”“cookie”和“cake”等值匹配。
排除不以字母字符开头的数据
正则表达式字符类是一种强大的快捷方式,可用于匹配特定类型的字符。例如:
- 包含/排除: 排除
- 匹配类型: 正则表达式匹配
- 值:
^[[:^alpha:]].*

这样会滤除非字母字符,例如日语汉字或韩语谚文。
了解正则表达式: ^[[:^alpha:]].*
^表示“字符串开头”
[[:alpha:]]是字母 [A-Za-z] 字符类。[[:^alpha:]] 会否定该类(“非字母”)
.*表示“匹配任何内容”