Neste artigo, você encontra conselhos e informações detalhadas sobre a combinação de dados para entender como ela funciona e resolver casos de uso complexos. Para aproveitar ao máximo este artigo, você precisa conhecer os conceitos básicos da junção de dados, que são abordados nos outros artigos deste tópico.
As combinações precisam conter apenas um subconjunto dos dados disponíveis
Uma prática recomendada é incluir apenas os campos específicos que você quer visualizar nos gráficos com base em uma combinação. Confira por que isso é importante:
- A combinação pode criar conjuntos de dados muito grandes, o que pode resultar em baixa performance e custos de consulta mais elevados em serviços pagos, como o BigQuery.
- Os gráficos com base em combinações calculam todas as linhas na combinação, mesmo que elas não sejam usadas no gráfico.
- Por exemplo, digamos que você crie uma combinação contendo 10 campos. defina um gráfico que use apenas um deles. O Looker Studio calcula a combinação de 10 campos e consulta esse campo no resultado para criar o gráfico.
- A reagregação só acontece se a combinação tiver um subconjunto dos dados subjacentes.
Usar a combinação para reagregar métricas
As métricas incluídas na fonte de dados subjacente se tornam números não agregados em uma combinação. Quando a combinação inclui menos do que o conjunto completo de campos da fonte de dados subjacente, esses números são agregados novamente com base nas novas informações. Usar a combinação dessa forma pode ser útil se você precisar aplicar uma agregação diferente a um campo já agregado, como calcular uma média de médias.
Consulte Usar a combinação para reagregar dados para mais informações.
Criar mesclagens com base em uma única fonte de dados
As combinações não precisam usar fontes de dados diferentes. Também pode ser útil agregar dados novamente combinando várias tabelas da mesma fonte.
Por exemplo, digamos que você tenha um conjunto de dados com informações sobre a população dos três principais condados nos estados mais populosos dos EUA, conforme mostrado na tabela a seguir:
| Estado |
Condado |
População (estimativa de 2023) |
|---|---|---|
| Califórnia |
Condado de Los Angeles |
10.014.009 |
| Califórnia |
Condado de San Diego |
3.298.634 |
| Califórnia |
Condado de Orange |
3.186.989 |
| Texas |
Condado de Harris |
4.731.145 |
| Texas |
Condado de Dallas |
2.613.539 |
| Texas |
Condado de Tarrant |
2.110.640 |
| Nova York |
Condado de Kings (Brooklyn) |
2.736.074 |
| Nova York |
Condado de Queens |
2.405.464 |
| Nova York |
Condado do Bronx |
1.418.890 |
Você quer calcular a porcentagem da população de cada condado no estado, mas, para isso, precisa ter a população total de cada estado como um campo próprio. No conjunto de dados, essa métrica não está disponível, mas você pode obtê-la combinando sua fonte de dados de população com ela mesma. Para isso, siga estas etapas:
- Crie uma fonte de dados usando seu conjunto de dados de base.
- Adicione um gráfico que usa essa fonte de dados a um relatório.
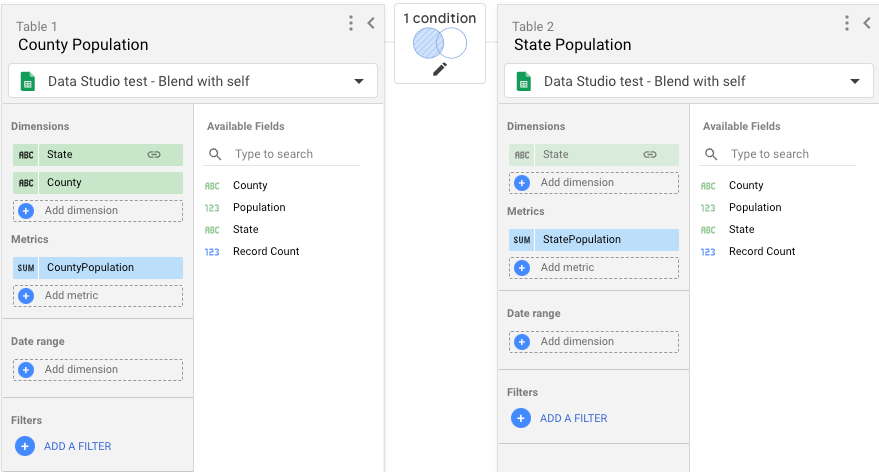
- Crie uma combinação com duas tabelas. Cada tabela vai usar a mesma fonte de dados criada na etapa 1.
- Para a Tabela 1, inclua os seguintes campos:
- Estado, Condado, População.
- Renomeie Population como CountyPopulation.
- Para a Tabela 2, inclua apenas o campo População e renomeie-o como StatePopulation.
- Para a Tabela 1, inclua os seguintes campos:
- Para a condição de junção, use uma junção externa à esquerda, vinculando Estado na Tabela 1 a Estado na Tabela 2.
- Clique em Salvar.
- Para voltar ao editor de relatórios, clique em X.
Em seguida, adicione um novo gráfico (por exemplo, uma tabela) ao relatório e selecione a combinação como a fonte de dados do gráfico seguindo estas etapas:
- Adicione os campos Estado, Condado, PopulaçãoDoCondado e PopulaçãoDoEstado ao gráfico.
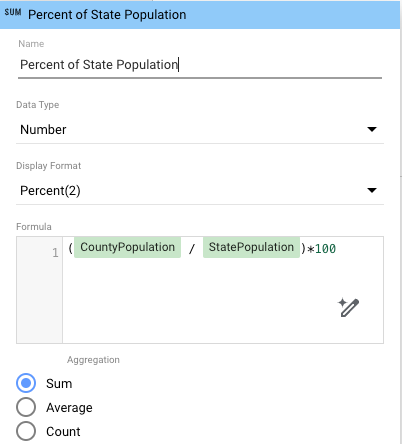
- Para calcular a porcentagem da população estadual de cada município, adicione um campo calculado ao gráfico que usa os novos dados reagrupados:
- No painel de propriedades, clique em Adicionar métrica e depois em Adicionar campo.
- Nomeie o campo, por exemplo, Porcentagem da população do estado.
- Na caixa Fórmula, insira
(CountyPopulation / StatePopulation)*100. - (Opcional) Defina o Formato de exibição para mostrar os valores de porcentagem em um nível específico (por exemplo, Porcentagem (2) para dois dígitos decimais).
Quando você terminar, a tabela vai ficar assim:
| Estado |
Condado |
CountyPopulation |
StatePopulation |
Porcentagem da população do estado |
|---|---|---|---|---|
| Califórnia |
Condado de Los Angeles |
10014009 |
16499632 |
60,69 |
| Texas |
Condado de Harris |
4731145 |
9455324 |
50.04 |
| Califórnia |
Condado de San Diego |
3298634 |
16499632 |
19,99 |
| Califórnia |
Condado de Orange |
3186989 |
16499632 |
19,32 |
| Nova York |
Condado de Kings (Brooklyn) |
2736074 |
6560428 |
41,71 |
| Texas |
Condado de Dallas |
2613539 |
9455324 |
27,64 |
| Nova York |
Condado de Queens |
2405464 |
6560428 |
36,67 |
| Texas |
Condado de Tarrant |
2110640 |
9455324 |
22,32 |
| Nova York |
Condado do Bronx |
1418890 |
6560428 |
21,63 |
Ordem de tabelas na combinação
O Looker Studio avalia as configurações de junção na mesclagem em ordem, começando pela configuração mais à esquerda. Os resultados de cada junção são aplicados à próxima junção à direita. Por exemplo, em uma combinação de três tabelas, a configuração de mesclagem entre a tabela 1 (mais à esquerda) e a tabela 2 (meio) é avaliada, e esses resultados são usados pela configuração de mesclagem entre a tabela 2 e a tabela 3 (mais à direita).
Ordem de tabelas em combinações criadas automaticamente
Quando você combina uma seleção de gráficos, o Looker Studio cria uma tabela para cada um deles e adiciona os campos à tabela correspondente. A ordem das tabelas na combinação segue a ordem de seleção dos gráficos: o primeiro gráfico selecionado se torna a primeira tabela (à esquerda), o segundo gráfico, a segunda tabela e assim por diante.
O Looker Studio também cria automaticamente uma configuração de junção para cada tabela e usa o tipo de junção externa à esquerda.
Se a configuração padrão não for a que você quer ou se não houver vinculações claras entre as tabelas, edite a combinação de acordo com suas metas.
As tabelas são criadas antes da combinação
Os dados de cada tabela em uma combinação são consultados antes de serem mesclados à combinação final. Os períodos, filtros e campos calculados em uma tabela são usados na consulta que gera a tabela antes de qualquer mesclagem ser realizada. Esses fatores podem afetar os dados incluídos nas tabelas de combinação e mudar o resultado da combinação.
As combinações podem conter mais linhas do que os dados originais
Talvez você veja mais dados em um gráfico combinado do que em gráficos com base nas fontes de dados individuais que compõem a combinação. O resultado pode depender dos seus dados e da configuração de junção escolhida para a combinação. Por exemplo, uma mesclagem externa à esquerda inclui todos os registros da tabela à esquerda, além de todos os registros das tabelas à direita que têm os mesmos valores em toda a condição de mesclagem. Quando há várias correspondências para a condição de agrupamento, haverá mais linhas de dados combinados do que na fonte de dados mais à esquerda.
Combinações e filtros e períodos explícitos
Duas formas de limitar o número de linhas nas combinações são usar um período ou um filtro. É possível limitar as linhas em gráficos com base em uma combinação ou nas tabelas que compõem a combinação. É útil pensar no processo como "pré-fusão" ou "pós-fusão".
Quando você usa um filtro ou período em uma tabela na combinação, ele entra em vigor antes de os dados serem mesclados às outras tabelas na combinação. As linhas fora do período ou excluídas pelo filtro não ficam disponíveis para a consulta de agrupamento.
Quando você aplica um período ou filtro a um gráfico com base em uma combinação, ele é usado nos dados depois que a combinação é criada ("pós-combinação").
Essa diferença pode ter um grande impacto nos resultados mostrados nos gráficos, dependendo dos seus dados e de como você configurou a combinação.
Combinações e filtros herdados
As combinações herdam os filtros no nível do relatório, da página ou do grupo, desde que o filtro seja compatível com os dados de antes ou depois da combinação. Se o filtro for compatível com as fontes de dados associadas usadas pela combinação, ele vai filtrar os dados pré-combinados. Caso contrário, o filtro é aplicado aos dados pós-combinados. Se o filtro não for compatível com os dados pré ou pós-combinação, ele vai ser ignorado.
Saiba mais sobre a herança de filtros.
Quando um gráfico com base em uma combinação está sujeito a um filtro herdado, o Looker Studio processa os dados em cinco etapas:
(Pré-fusão):
- Etapa 1:os dados são agrupados e agregados de acordo com as dimensões especificadas no painel Combinar dados.
- Etapa 2:os filtros de dimensão herdados e de métricas compatíveis são aplicados às fontes de dados incluídas no painel Combinar dados.
(Fusão):
- Etapa 3:os dados são combinados usando a configuração de mesclagem especificada.
(pós-fusão):
- Etapa 4:os dados são agrupados e agregados de acordo com as dimensões no gráfico.
- Etapa 5:os filtros de métrica, quando compatíveis com os dados combinados, são usados no gráfico.