Le informazioni contenute in questo articolo forniscono consigli e informazioni dettagliate sull'unione dei dati per aiutarti a capire come funziona e a risolvere casi d'uso complessi. Per trarre il massimo vantaggio da questo articolo, dovresti già conoscere le nozioni di base della fusione dei dati, trattate negli altri articoli di questo argomento.
Le combinazioni devono contenere solo un sottoinsieme dei dati disponibili
Come best practice, devi includere solo i campi specifici che vuoi visualizzare nei grafici basati su una combinazione. Ecco perché è importante:
- La combinazione può generare set di dati molto grandi, il che può portare a un rallentamento delle prestazioni e a possibili costi di query più elevati per i servizi a pagamento come BigQuery.
- I grafici basati su combinazioni calcolano tutte le righe nella combinazione anche se non sono utilizzate nel grafico.
- Ad esempio, supponiamo che crei una combinazione contenente dieci campi, poi definisci un grafico che ne utilizza solo uno. Looker Studio calcola la combinazione di dieci campi, poi esegue una query su quel campo nell'output della combinazione per creare il grafico.
- La riaggregazione si verifica solo se la combinazione contiene un sottoinsieme dei dati sottostanti.
Utilizzare la combinazione per riaggregare le metriche
Le metriche che includi dall'origine dati sottostante diventano numeri non aggregati in una combinazione. Quando la combinazione include un numero di campi inferiore all'intero set dalle origini dati sottostanti, questi numeri vengono riaggregati in base ai nuovi dati. L'utilizzo della combinazione in questo modo può risultare utile se devi applicare un'aggregazione diversa a un campo già aggregato, ad esempio il calcolo di una media di medie.
Per saperne di più, consulta Utilizzare la combinazione per riaggregare i dati.
Creare combinazioni da una singola origine dati
Le fusioni non devono utilizzare origini dati diverse. Potrebbe anche essere utile riaggregare i dati combinando più tabelle della stessa origine dati.
Ad esempio, supponiamo di avere un set di dati che contiene i dati sulla popolazione delle prime tre contee degli stati più popolosi degli Stati Uniti, come mostrato nella tabella seguente:
| Stato |
Contea |
Popolazione (stima 2023) |
|---|---|---|
| California |
Contea di Los Angeles |
10.014.009 |
| California |
Contea di San Diego |
3.298.634 |
| California |
Contea di Orange |
3.186.989 |
| Texas |
Contea di Harris |
4.731.145 |
| Texas |
Contea di Dallas |
2.613.539 |
| Texas |
Contea di Tarrant |
2.110.640 |
| New York |
Contea di Kings (Brooklyn) |
2.736.074 |
| New York |
Contea di Queens |
2.405.464 |
| New York |
Contea di Bronx |
1.418.890 |
Vuoi calcolare la percentuale di popolazione per ogni contea dello stato, ma per farlo devi avere la popolazione totale di ogni stato come campo separato. Nel set di dati, questa metrica non è disponibile, ma puoi ottenerla unendo l'origine dati della popolazione con se stessa seguendo questi passaggi:
- Crea un'origine dati utilizzando il set di dati di base.
- Aggiungi a un report un grafico che utilizza questa origine dati.
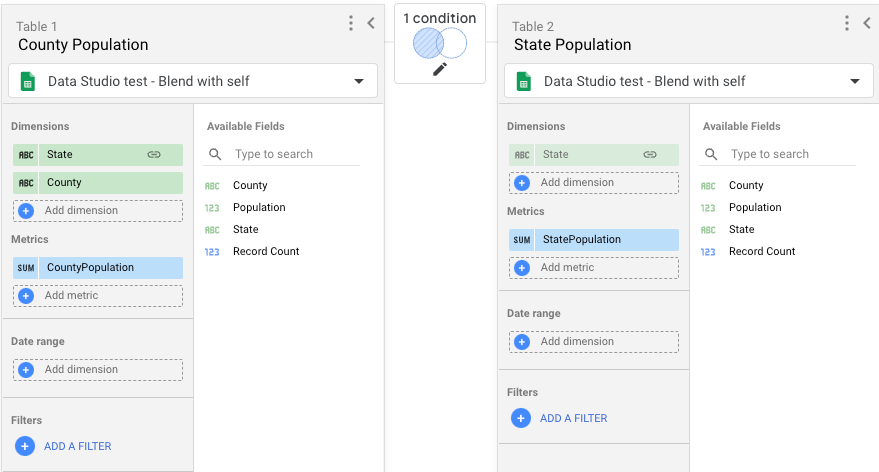
- Crea un'unione con due tabelle. Ogni tabella utilizzerà la stessa origine dati creata nel passaggio 1.
- Per la tabella 1, includi i seguenti campi:
- Stato, Contea, Popolazione.
- Rinomina Population in CountyPopulation.
- Per la tabella 2, includi solo il campo Popolazione e rinominalo in StatePopulation.
- Per la tabella 1, includi i seguenti campi:
- Per la condizione di join, utilizza un join Left Outer, collegando State nella tabella 1 a State nella tabella 2.
- Fai clic su Salva.
- Torna all'editor del report facendo clic su X.
Successivamente, aggiungi un nuovo grafico (ad esempio una tabella) al report e seleziona la combinazione come origine dati per il grafico seguendo questi passaggi:
- Aggiungi i campi Stato, Contea, Popolazione della contea e Popolazione dello stato al grafico.
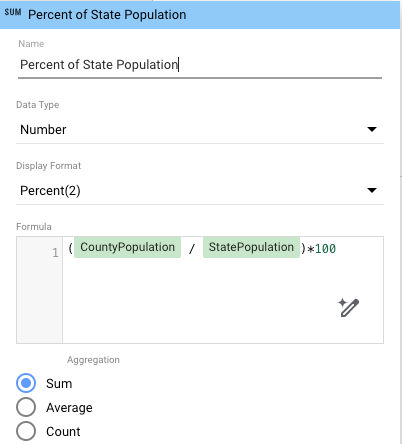
- Per calcolare la percentuale della popolazione statale per ogni contea, aggiungi un campo calcolato al grafico che utilizza i nuovi dati riaggregati:
- Nel riquadro delle proprietà, fai clic su Aggiungi metrica e poi su Aggiungi campo.
- Assegna un nome al campo, ad esempio Percentuale della popolazione dello stato.
- Nella casella Formula, inserisci
(CountyPopulation / StatePopulation)*100. - (Facoltativo) Imposta il Formato visualizzazione per mostrare i valori percentuali a un livello specifico (ad esempio, Percentuale (2) per due cifre decimali).
Al termine, la tabella dovrebbe avere un aspetto simile a questo:
| Stato |
Contea |
CountyPopulation |
StatePopulation |
Percentuale della popolazione statale |
|---|---|---|---|---|
| California |
Contea di Los Angeles |
10014009 |
16499632 |
60,69 |
| Texas |
Contea di Harris |
4731145 |
9455324 |
50,04 |
| California |
Contea di San Diego |
3298634 |
16499632 |
19,99 |
| California |
Contea di Orange |
3186989 |
16499632 |
19,32 |
| New York |
Contea di Kings (Brooklyn) |
2736074 |
6560428 |
41,71 |
| Texas |
Contea di Dallas |
2613539 |
9455324 |
27,64 |
| New York |
Contea di Queens |
2405464 |
6560428 |
36,67 |
| Texas |
Contea di Tarrant |
2110640 |
9455324 |
22,32 |
| New York |
Contea di Bronx |
1418890 |
6560428 |
21,63 |
Ordine della tabella nella combinazione
Looker Studio valuta le configurazioni di join nella combinazione in ordine, partendo da quella più a sinistra. I risultati di ogni join vengono poi applicati al successivo join a destra. Ad esempio, in una combinazione di tre tabelle, viene valutata la configurazione di join tra la tabella 1 (più a sinistra) e la tabella 2 (al centro), quindi i risultati vengono utilizzati dalla configurazione di join tra la tabella 2 e la tabella 3 (più a destra).
Ordine della tabella nelle combinazioni create automaticamente
Quando combini una selezione di grafici, Looker Studio crea una tabella per ogni grafico e aggiunge i campi del grafico alla tabella corrispondente. L'ordine delle tabelle nella combinazione corrisponde all'ordine in cui selezioni i grafici: il primo grafico selezionato diventa la prima tabella (più a sinistra), il secondo grafico selezionato diventa la seconda tabella e così via.
Looker Studio crea automaticamente anche una configurazione di join per ogni tabella e utilizza il tipo di join esterno sinistro.
Se la configurazione predefinita non è quella che vuoi o se non sono presenti collegamenti chiari tra le tabelle, puoi modificare la combinazione in base ai tuoi obiettivi.
Le tabelle vengono create prima della combinazione
Viene eseguita una query sui dati di ogni tabella in una combinazione prima che venga creata la combinazione finale. Gli intervalli di date, i filtri e i campi calcolati di una tabella vengono applicati alla query che genera la tabella prima che vengano eseguiti i join. Questi fattori possono influire sui dati inclusi nelle tabelle di combinazione e modificare l'output della combinazione.
Le combinazioni possono contenere più righe rispetto ai dati originali
In un grafico combinato potresti vedere più dati rispetto a quelli riportati nei grafici basati sulle singole origini dati che costituiscono la combinazione. Il risultato può dipendere dai dati e dalla configurazione di join scelta per la combinazione. Ad esempio, un left outer join include tutti i record della tabella a sinistra, nonché tutti i record delle tabelle a destra che condividono gli stessi valori nella condizione di join. Più corrispondenze per la condizione di join possono comportare la visualizzazione di più righe nei dati combinati rispetto a quelle esistenti nell'origine dati più a sinistra.
Combinazioni e intervalli di date e filtri espliciti
Per limitare il numero di righe nelle combinazioni, puoi utilizzare un intervallo di date o applicare un filtro. Puoi limitare le righe nei grafici basati su una combinazione o nelle tabelle che compongono la combinazione. È utile pensare al processo in termini di situazione "prima della combinazione" o "dopo la combinazione".
Quando viene applicato a una tabella della combinazione, un intervallo di date o un filtro ha effetto prima che i dati vengano uniti alle altre tabelle della combinazione. Le righe che non rientrano nell'intervallo di date o che vengono escluse dal filtro non sono prese in considerazione nella query di join.
Quando applichi un intervallo di date o un filtro a un grafico basato su una combinazione, lo applichi ai dati dopo la creazione della combinazione ("dopo la combinazione").
Questa differenza potrebbe influire notevolmente sui risultati visualizzati nei grafici, a seconda dei dati e della configurazione della combinazione.
Combinazioni e filtri ereditati
Le combinazioni ereditano i filtri a livello di report, pagina o gruppo, a condizione che il filtro sia compatibile con i dati prima o dopo la combinazione. Se il filtro è compatibile con le origini dati sottostanti utilizzate dalla combinazione, interviene sui dati prima della combinazione. In caso contrario, il filtro agisce sui dati dopo la combinazione. Se non è compatibile con i dati prima o dopo la combinazione, il filtro viene ignorato.
Scopri di più sull'ereditarietà dei filtri.
Quando un grafico basato su una combinazione è soggetto a un filtro ereditato, Looker Studio elabora i dati in cinque passaggi:
(Pre-blend):
- Passaggio 1: i dati vengono raggruppati e aggregati in base alle dimensioni specificate nel riquadro Combina dati.
- Passaggio 2: i filtri delle dimensioni ereditati e i filtri delle metriche compatibili vengono applicati alle origini dati incluse nel riquadro Combina dati.
(Blend):
- Passaggio 3: i dati vengono combinati utilizzando la configurazione di join specificata.
(Post-blend):
- Passaggio 4: i dati vengono raggruppati e aggregati in base alle dimensioni nel grafico.
- Passaggio 5: al grafico vengono applicati i filtri delle metriche, se compatibili con i dati combinati.