本教程介绍如何在 Google Kubernetes Engine (GKE) 上部署计划的自动扩缩器来降低费用。这种自动扩缩器会根据基于按一天中的时间或星期几的时间表来扩缩集群。如果您的流量具有可预测的 ebb 和流(例如,如果您是地区零售商,或者您的软件面向工作时间限制在一天中的特定时段的员工),则计划的自动扩缩器非常有用。
本教程适用于想要实现以下目的开发者和运营商:在高峰期到来之前可靠地将集群纵向扩容,并在夜间、周末或在线用户数较少的任何其他时间再次缩减,以节省费用。本文假设您熟悉 Docker、Kubernetes、Kubernetes CronJobs、GKE 和 Linux。
简介
许多应用都会遇到不均匀的流量模式。例如,组织中的员工可能仅在白天与应用交互。因此,该应用的数据中心服务器在夜间保持闲置状态。
除了其他好处之外, Google Cloud 还可以根据流量负载动态分配基础设施,从而帮助您节省费用。在某些情况下,简单的自动扩缩配置可以克服不均匀流量的分配难题。如果您遇到了此类难题,请使用简单的自动扩缩配置。但是,在其他情况下,流量模式的急剧变化需要更精细调整的自动扩缩配置,以避免在纵向扩容期间系统不稳定,以及避免超额预配集群。
本教程重点介绍了充分了解流量模式急剧变化的场景,您需要向自动扩缩器提供一条提示,告知基础设施将迎来高峰期。本文档展示了如何在早晨将 GKE 集群纵向扩容,在夜间进行缩减,但您可以使用类似的方法来针对任何已知事件(例如高峰期扩缩事件、广告系列或周末数据流量)增加和降低容量。
在具有承诺使用折扣的情况下缩减集群
本教程介绍如何在非高峰时段将 GKE 集群缩减至最低,从而降低费用。但是,如果您购买了承诺使用折扣,请务必了解如何将这些折扣与自动扩缩结合使用。
当您承诺购买一定数量的资源(vCPU、内存等)时,承诺使用折扣可给予您大幅度的折扣价格。但是,为了确定需要承诺的资源数量,您需要事先了解工作负载在一段时间内使用的资源数量。为了帮助您降低费用,下图说明了哪些资源应不应该包含在计划中。

如图所示,承诺使用合同中的资源分配是固定的。必须在大部分时间使用合同涵盖的资源,以实现承诺的价值。因此,在计算承诺资源时,不应该纳入在高峰期使用的资源。对于在高峰期使用的资源,建议您使用 GKE 自动扩缩器选项。这些选项包含了本文中介绍的计划的自动扩缩器,或在 GKE 上运行费用经过优化的 Kubernetes 应用的最佳做法中所述的其他代管式选项。
如果您已有给定数量的资源的承诺使用合同,则不能通过将集群缩减到低于该最小值来降低费用。在此类情况下,建议您尝试计划一些作业以在计算需求较少的时段弥补空隙。
架构
下图显示了您在本教程中部署的基础架构和计划的自动扩缩器的架构。计划的自动扩缩器由一组组件组成,这些组件一起工作,以根据时间表管理扩缩。

在此架构中,一组 Kubernetes CronJobs 将有关流量模式的已知信息导出到 Cloud Monitoring 自定义指标。然后,Kubernetes Pod 横向自动扩缩器 (HPA) 会读取这些数据,作为确定 HPA 何时应扩缩工作负载的输入。结合其他负载指标(如目标 CPU 利用率),HPA 会确定如何扩缩给定部署的副本。
准备环境
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
在 Cloud Shell 中,配置您的 Google Cloud 项目 ID、邮箱以及计算可用区和区域:
PROJECT_ID=YOUR_PROJECT_ID ALERT_EMAIL=YOUR_EMAIL_ADDRESS gcloud config set project $PROJECT_ID gcloud config set compute/region us-central1 gcloud config set compute/zone us-central1-f替换以下内容:
YOUR_PROJECT_ID:您要使用的项目的 Google Cloud 项目名称。YOUR_EMAIL_ADDRESS:用于在计划的自动扩缩器无法正常运行时接收通知的电子邮件地址。
您可以根据需要为本教程选择其他地区和区域。
克隆
kubernetes-engine-samplesGitHub 代码库:git clone https://github.com/GoogleCloudPlatform/kubernetes-engine-samples/ cd kubernetes-engine-samples/cost-optimization/gke-scheduled-autoscaler此代码库中的代码会构建到以下文件夹中:
- Root:包含 CronJobs 用于将自定义指标导出到 Cloud Monitoring 的代码。
k8s/:包含具有 Kubernetes HPA 的部署示例。k8s/scheduled-autoscaler/:包含导出自定义指标的 CronJobs 和更新的 HPA 版本以从自定义指标中读取。k8s/load-generator/:包含一个 Kubernetes Deployment,其中含有可模拟每小时使用量的应用。Deployment 是一个 Kubernetes API 对象,可让您运行在集群节点中分布的多个 Pod 副本。monitoring/:包含在本教程中配置的 Cloud Monitoring 组件。
在 Cloud Shell 中,创建用于运行计划自动扩缩器的 GKE 集群:
gcloud container clusters create scheduled-autoscaler \ --enable-ip-alias \ --release-channel=stable \ --machine-type=e2-standard-2 \ --enable-autoscaling --min-nodes=1 --max-nodes=10 \ --num-nodes=1 \ --autoscaling-profile=optimize-utilization输出内容类似如下:
NAME LOCATION MASTER_VERSION MASTER_IP MACHINE_TYPE NODE_VERSION NUM_NODES STATUS scheduled-autoscaler us-central1-f 1.22.15-gke.100 34.69.187.253 e2-standard-2 1.22.15-gke.100 1 RUNNING这不是生产配置,而是适合本教程的配置。在此设置中,您需配置集群自动扩缩器(最少 1 个节点,最多 10 个节点)。您还可以启用
optimize-utilization配置文件以加快缩减过程。部署不含计划的自动扩缩器的示例应用:
kubectl apply -f ./k8s打开
k8s/hpa-example.yaml文件。以下列表显示了该文件的内容。
请注意,最小副本数 (
minReplicas) 设置为 10。此配置还会设置集群,以根据 CPU 利用率(name: cpu和type: Utilization设置)进行扩缩。等待应用变得可用:
kubectl wait --for=condition=available --timeout=600s deployment/php-apache EXTERNAL_IP='' while [ -z $EXTERNAL_IP ] do EXTERNAL_IP=$(kubectl get svc php-apache -o jsonpath={.status.loadBalancer.ingress[0].ip}) [ -z $EXTERNAL_IP ] && sleep 10 done curl -w '\n' http://$EXTERNAL_IP当应用可用时,输出如下所示:
OK!验证设置:
kubectl get hpa php-apache输出内容类似如下:
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE php-apache Deployment/php-apache 9%/60% 10 20 10 6d19hREPLICAS列会显示10,它与hpa-example.yaml文件中minReplicas字段的值匹配。检查节点数是否已增加到 4:
kubectl get nodes输出内容类似如下:
NAME STATUS ROLES AGE VERSION gke-scheduled-autoscaler-default-pool-64c02c0b-9kbt Ready <none> 21S v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-ghfr Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-gvl9 Ready <none> 21s v1.17.9-gke.1504 gke-scheduled-autoscaler-default-pool-64c02c0b-t9sr Ready <none> 21s v1.17.9-gke.1504创建集群时,您可以使用
min-nodes=1标志设置最低配置。但是,您在此过程开始时部署的应用请求更多基础架构,因为hpa-example.yaml文件中的minReplicas设置为 10。一些公司(例如零售商)预计在工作日的前几个小时内流量会突然增加,因此将
minReplicas设置为 10 之类的值是他们常用的策略。但是,为 HPAminReplicas设置较高的值可能会增加费用,因为集群无法缩减,甚至在夜间应用流量较低时也是如此。在 Cloud Shell 中,在 GKE 集群中安装自定义指标 - Cloud Monitoring 适配器:
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/k8s-stackdriver/master/custom-metrics-stackdriver-adapter/deploy/production/adapter_new_resource_model.yaml kubectl wait --for=condition=available --timeout=600s deployment/custom-metrics-stackdriver-adapter -n custom-metrics此适配器根据 Cloud Monitoring 自定义指标启用 Pod 自动扩缩。
在 Artifact Registry 中创建代码库并授予读取权限:
gcloud artifacts repositories create gke-scheduled-autoscaler \ --repository-format=docker --location=us-central1 gcloud auth configure-docker us-central1-docker.pkg.dev gcloud artifacts repositories add-iam-policy-binding gke-scheduled-autoscaler \ --location=us-central1 --member=allUsers --role=roles/artifactregistry.reader构建并推送自定义指标导出器代码:
docker build -t us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter . docker push us-central1-docker.pkg.dev/$PROJECT_ID/gke-scheduled-autoscaler/custom-metric-exporter部署 CronJobs,其会导出自定义指标,并部署更新的 HPA 版本以用于从以下自定义指标中读取数据:
sed -i.bak s/PROJECT_ID/$PROJECT_ID/g ./k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml kubectl apply -f ./k8s/scheduled-autoscaler打开并检查
k8s/scheduled-autoscaler/scheduled-autoscale-example.yaml文件。以下列表显示了该文件的内容。
此配置指定 CronJobs 应该根据一天中的时间将建议的 Pod 副本数量导出到名为
custom.googleapis.com/scheduled_autoscaler_example的自定义指标。为了方便本教程监控部分的工作,时间表字段配置定义了每小时纵向扩容和缩减。对于生产环境,您可以自定义此时间表以满足您的业务需求。打开并检查
k8s/scheduled-autoscaler/hpa-example.yaml文件。以下列表显示了该文件的内容。
此配置指定 HPA 对象应取代之前部署的 HPA。请注意,该配置会将
minReplicas中的值减小到 1。这意味着工作负载可以缩减到其最小值。该配置还会添加外部指标 (type: External)。此添加意味着自动扩缩现在由两个因素触发。在这种多指标情况下,HPA 会计算每个指标的建议副本数量,然后选择返回最高值的指标。请务必了解这一点 - 计划的自动扩缩器可能会建议在给定时间 Pod 数量应是 1。但是,如果单个 Pod 的实际 CPU 利用率高于预期,则 HPA 会创建更多副本。
再次运行以下每个命令,以再次检查节点数量和 HPA 副本数量:
kubectl get nodes kubectl get hpa php-apache您看到的输出取决于计划的自动扩缩器最近执行的操作 - 具体来说,在扩缩周期内不同时间点,
minReplicas和nodes的值有所不同。例如,在每小时的大约 51 到 60 分钟(代表流量高峰时段)期间,
minReplicas的 HPA 值为 10,nodes的值为 4。相比之下,对于 1 到 50 分钟(表示流量较低时段),
minReplicas的 HPA 值将为 1,nodes值将为 1 或 2,具体取决于已分配和已移除的 Pod 数量。对于较低的值(1 到 50 分钟),集群可能需要长达 10 分钟才能完成缩减。在 Cloud Shell 中,创建通知渠道:
gcloud beta monitoring channels create \ --display-name="Scheduled Autoscaler team (Primary)" \ --description="Primary contact method for the Scheduled Autoscaler team lead" \ --type=email \ --channel-labels=email_address=${ALERT_EMAIL}输出类似于以下内容:
Created notification channel NOTIFICATION_CHANNEL_ID.此命令会创建一个类型为
email的通知渠道,以简化教程步骤。在生产环境中,建议您通过将通知渠道设置为sms或pagerduty,使用同步程度较高的策略。设置一个变量,其具有
NOTIFICATION_CHANNEL_ID占位符中显示的值:NOTIFICATION_CHANNEL_ID=NOTIFICATION_CHANNEL_ID部署提醒政策:
gcloud alpha monitoring policies create \ --policy-from-file=./monitoring/alert-policy.yaml \ --notification-channels=$NOTIFICATION_CHANNEL_IDalert-policy.yaml文件包含用于在指标在 5 分钟后不存在时发送提醒的指定内容。转到 Cloud Monitoring 提醒页面以查看提醒政策。
点击计划的自动扩缩器政策,并验证提醒政策的详细信息。
在 Cloud Shell 中,部署负载生成器:
kubectl apply -f ./k8s/load-generator以下列表显示了
load-generator脚本:command: ["/bin/sh", "-c"] args: - while true; do RESP=$(wget -q -O- http://php-apache.default.svc.cluster.local); echo "$(date +%H)=$RESP"; sleep $(date +%H | awk '{ print "s("$0"/3*a(1))*0.5+0.5" }' | bc -l); done;该脚本在集群中运行,直到您删除
load-generator部署为止。它每隔几毫秒就会向您的php-apache服务发出请求。sleep命令会模拟一天中的负载分布变化。通过使用以这种方式生成流量的脚本,您可以了解在 HPA 配置中结合使用 CPU 利用率和自定义指标时发生的情况。在 Cloud Shell 中,创建一个新的信息中心:
gcloud monitoring dashboards create \ --config-from-file=./monitoring/dashboard.yaml转到 Cloud Monitoring 信息中心页面:
点击计划的自动扩缩器信息中心。
信息中心会显示三个图表。您至少需要等待 2 小时(理想情况下,否则是 24 小时或更长时间)才能看到纵向扩容和缩减的动态,以及看到一天中不同的负载分布如何影响自动扩缩。
如需了解该图表显示的内容,您可以研究以下图表,它们显示了一整天的视图:
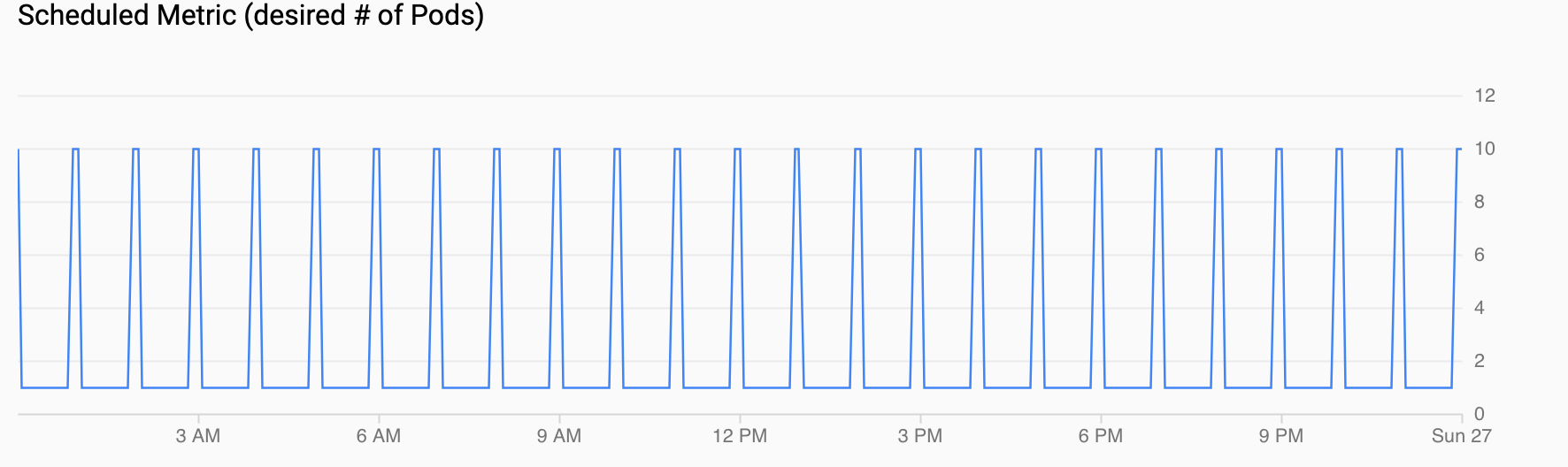
计划的指标(需要的 Pod 数量)显示了自定义指标的时间序列;您通过在设置计划的自动扩缩器中配置的 CronJobs 将这些自定义指标导出到 Cloud Monitoring。
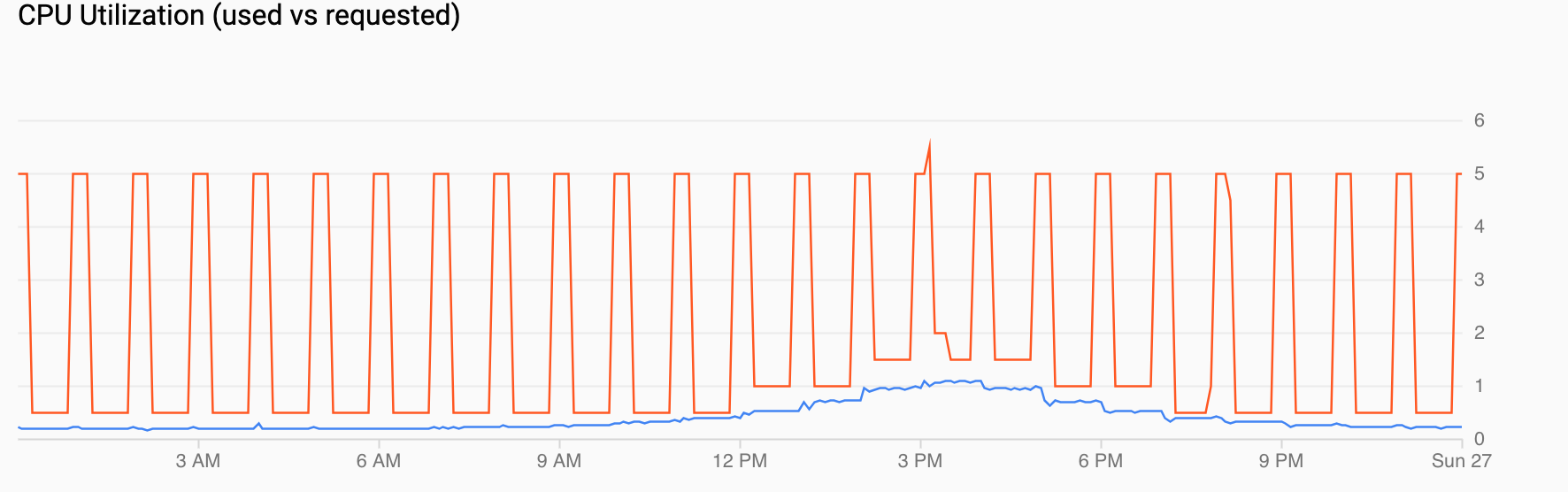
CPU 利用率(请求与使用)显示请求的 CPU(红色)和实际 CPU 利用率(蓝色)的时间序列。当负载较低时,HPA 会遵循计划的自动扩缩器的利用率决策。但是,当数据流量增加时,HPA 会根据需要增加 Pod 的数量,如您在中午 12 点到下午 6 点之间可以看到的数据点。
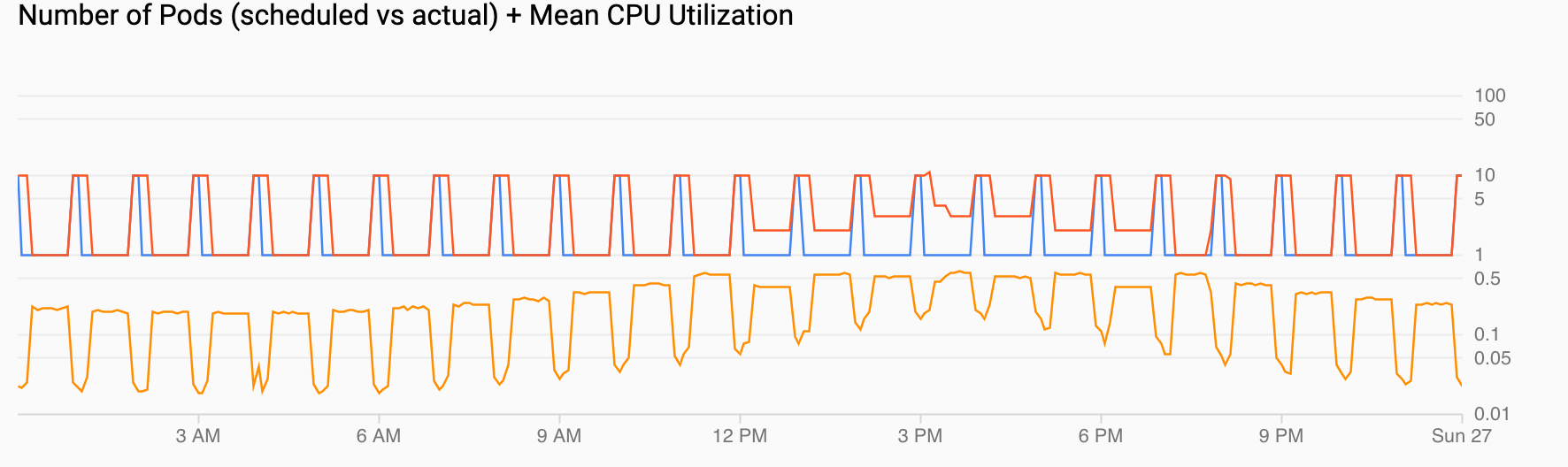
Pod 数量(计划和实际)+ 平均 CPU 利用率显示与前面的视图类似的视图。Pod 数量(红色)增加到每小时的 10 个,如计划的(蓝色)一样。Pod 数量会随着时间的推移根据负载自然增加和减少(中午 12 点到下午 6 点)。平均 CPU 利用率(橙色)保持低于您设置的目标 (60%)。
创建 GKE 集群
部署示例应用
安装计划的自动扩缩器
配置当计划的自动扩缩器无法正常运行时的提醒
在生产环境中,您通常需要知道 CronJobs 何时不会填充自定义指标。为此,您可以创建一个提醒,该提醒会在任何 custom.googleapis.com/scheduled_autoscaler_example 流不存在达到五分钟时触发。
为示例应用生成负载
直观呈现根据流量或计划指标扩缩
在本部分中,您将查看展示纵向扩容和缩减效果的直观呈现。