Nesta página, descrevemos as métricas e os painéis disponíveis para monitorar a latência de inicialização das cargas de trabalho do Google Kubernetes Engine (GKE) e dos nós do cluster subjacentes. Use as métricas para rastrear, resolver problemas e reduzir a latência de inicialização.
Esta página é destinada a administradores e operadores de plataforma que precisam monitorar e otimizar a latência de inicialização das cargas de trabalho. Para saber mais sobre papéis comuns que referenciamos no conteúdo do Google Cloud , consulte Tarefas e funções de usuário comuns do GKE.
Visão geral
A latência de inicialização afeta significativamente a forma como o aplicativo responde a picos de tráfego, a rapidez com que as réplicas se recuperam de interrupções e a eficiência dos custos operacionais dos clusters e das cargas de trabalho. Monitorar a latência de inicialização das cargas de trabalho ajuda a detectar degradações de latência e acompanhar o impacto das atualizações de carga de trabalho e infraestrutura na latência de inicialização.
A otimização da latência de inicialização da carga de trabalho tem os seguintes benefícios:
- Reduz a latência de resposta do seu serviço aos usuários durante picos de tráfego.
- Reduz o excesso de capacidade de veiculação necessário para absorver picos de demanda enquanto novas réplicas são criadas.
- Reduz o tempo ocioso de recursos já implantados e aguardando a inicialização dos recursos restantes durante computações em lote.
Antes de começar
Antes de começar, verifique se você realizou as tarefas a seguir:
- Ativar a API Google Kubernetes Engine. Ativar a API Google Kubernetes Engine
- Se você quiser usar a CLI do Google Cloud para essa tarefa,
instale e inicialize a
gcloud CLI. Se você instalou a CLI gcloud anteriormente, instale a versão
mais recente executando o comando
gcloud components update. Talvez as versões anteriores da CLI gcloud não sejam compatíveis com a execução dos comandos neste documento.
Ative as APIs Cloud Logging e Cloud Monitoring.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Requisitos
Para conferir métricas e painéis da latência de inicialização das cargas de trabalho, o cluster do GKE precisa atender aos seguintes requisitos:
- Você precisa ter o GKE versão 1.31.1-gke.1678000 ou mais recente.
- Você precisa configurar a coleta de métricas do sistema.
- Configure a coleta de registros do sistema.
- Ative as métricas de estado do kube com o componente
PODnos clusters para conferir as métricas de pod e contêiner.
Papéis e permissões necessárias
Para receber as permissões necessárias para ativar a geração de registros e acessar e processar registros, peça ao administrador para conceder a você os seguintes papéis do IAM:
-
Veja clusters, nós e cargas de trabalho do GKE:
Leitor do Kubernetes Engine (
roles/container.viewer) no seu projeto -
Acesse as métricas de latência de inicialização e confira os painéis:
Leitor do Monitoring (
roles/monitoring.viewer) no seu projeto -
Acesse registros com informações de latência, como eventos de extração de imagem do Kubelet, e confira-os no Explorador de registros e na Análise de registros:
Visualizador de registros (
roles/logging.viewer) no seu projeto
Para mais informações sobre a concessão de papéis, consulte Gerenciar o acesso a projetos, pastas e organizações.
Também é possível conseguir as permissões necessárias usando papéis personalizados ou outros papéis predefinidos.
Métricas de latência de inicialização
As métricas de latência de inicialização estão incluídas nas métricas do sistema do GKE e são exportadas para o Cloud Monitoring no mesmo projeto que o cluster do GKE.
Os nomes das métricas do Cloud Monitoring nesta tabela precisam ser prefixados com
kubernetes.io/. Esse prefixo foi omitido das
entradas na tabela.
| Tipo de métrica (níveis da hierarquia de recursos) Nome de exibição |
|
|---|---|
|
Tipo, Classe, Unidade
Recursos monitorados |
Descrição Rótulos |
pod/latencies/pod_first_ready
(projeto)
Latência do primeiro pod pronto |
|
GAUGE, Double, s
k8s_pod |
A latência de inicialização de ponta a ponta do pod (do pod Created para Ready), incluindo extrações de imagem. Amostras coletadas a cada 60 segundos. |
node/latencies/startup
(projeto)
Latência de inicialização de nós |
|
GAUGE, INT64, s
k8s_node |
A latência total de inicialização do nó, da CreationTimestamp da instância do GCE até Kubernetes node ready pela primeira vez. Amostras coletadas a cada 60 segundos.accelerator_family: uma classificação de nós com base em aceleradores de hardware: gpu, tpu, cpu.
kube_control_plane_available: se a solicitação de criação de nó foi recebida quando o KCP (plano de controle do kube) estava disponível.
|
autoscaler/latencies/per_hpa_recommendation_scale_latency_seconds
(projeto)
Latência de escalonamento por recomendação de HPA |
|
GAUGE, DOUBLE, s
k8s_scale |
Latência da recomendação de escalonamento do escalonador automático horizontal de pods (HPA) (tempo entre a criação das métricas e a aplicação da recomendação de escalonamento correspondente ao apiserver) para o destino do HPA. Amostras coletadas a cada 60 segundos. Após a amostragem, os dados não são visíveis por até 20 segundos.metric_type: o tipo de origem da métrica. Ele precisa ser "ContainerResource", "External", "Object", "Pods" ou "Resource".
|
Acessar o painel de latência de inicialização para cargas de trabalho
O painel Latência de inicialização para cargas de trabalho está disponível apenas para implantações. Para conferir as métricas de latência de inicialização dos Deployments, siga estas etapas no console Google Cloud :
Acesse a página Cargas de trabalho.
Para abrir a visualização Detalhes da implantação, clique no nome da carga de trabalho que você quer inspecionar.
Clique na guia Observabilidade.
Selecione Latência de inicialização no menu à esquerda.
Ver a distribuição de latência de inicialização de pods
A latência de inicialização dos pods se refere à latência total, incluindo extrações de imagem, que mede o tempo desde o status Created do pod até o status Ready. É possível avaliar a latência de inicialização dos pods usando os dois gráficos a seguir:
Gráfico Distribuição da latência de inicialização do pod: mostra os percentis de latência de inicialização dos pods (50º, 95º e 99º percentis), que são calculados com base nas observações de eventos de inicialização do pod em intervalos fixos de três horas, por exemplo, de 0h às 3h e de 3h às 6h. Use esse gráfico para:
- Entenda a latência de inicialização do pod de referência.
- Identifique mudanças na latência de inicialização do pod ao longo do tempo.
- Correlacione as mudanças na latência de inicialização do pod com eventos recentes, como implantações de carga de trabalho ou eventos do escalonador automático de cluster. É possível selecionar os eventos na lista Anotações na parte de cima do painel.
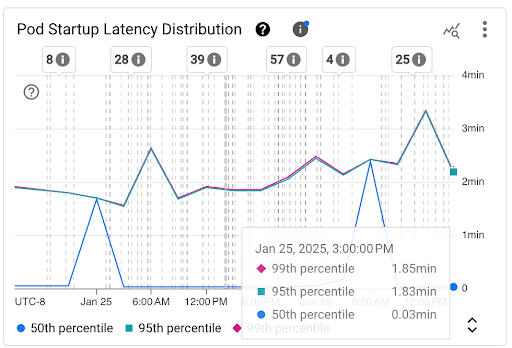
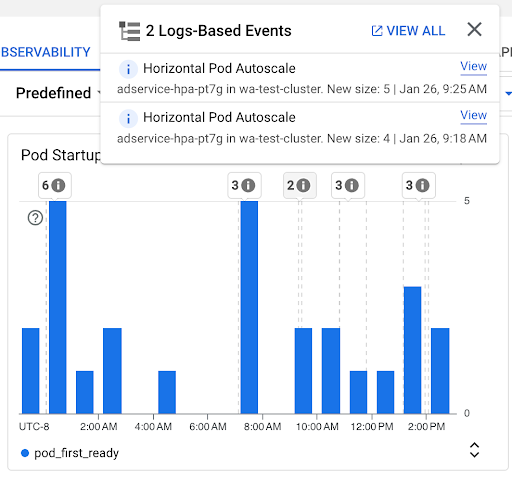
Gráfico Contagem de inicialização de pods: mostra a contagem de pods iniciados durante os intervalos de tempo selecionados. Você pode usar esse gráfico para os seguintes fins:
- Entenda os tamanhos de amostra de pod usados para calcular os percentis da distribuição de latência de inicialização de pod em um determinado intervalo de tempo.
- Entenda as causas das inicializações de pods, como implantações de carga de trabalho ou eventos do escalonador automático horizontal de pods. Selecione os eventos na lista Anotações, na parte de cima do painel.
Ver a latência de inicialização de pods individuais
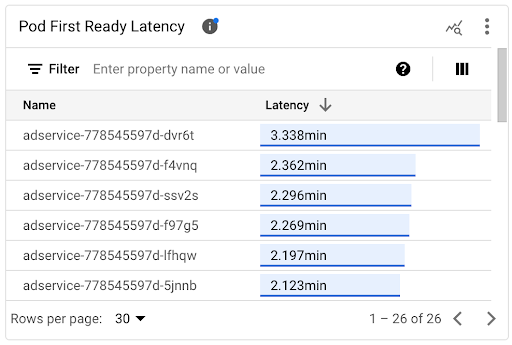
É possível conferir a latência de inicialização de pods individuais no gráfico de linha do tempo Latência do primeiro pod pronto e na lista associada.
- Use o gráfico de linha do tempo Latência de primeiro pronto do pod para correlacionar inicializações de pods individuais com eventos recentes, como eventos do Escalonador automático horizontal de pods ou do Autoescalador de cluster. É possível selecionar esses eventos na lista Anotações, na parte de cima do painel. Esse gráfico ajuda a determinar possíveis causas para mudanças na latência de inicialização em comparação com outros pods.
- Use a lista Latência do primeiro pronto do pod para identificar os pods individuais que levaram mais ou menos tempo para serem iniciados. É possível classificar a lista pela coluna Latência. Ao identificar os pods com a maior latência de inicialização, é possível resolver a degradação da latência correlacionando os eventos de início do pod com outros eventos recentes.
Para saber quando um pod individual foi criado, consulte o valor no campo timestamp em um evento de criação de pod correspondente. Para ver o campo
timestamp, execute a seguinte consulta no
Explorador de registros:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.pods.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.namespace=NAMESPACE AND
protoPayload.response.metadata.name=POD_NAME
Para listar todos os eventos de criação de pod da sua carga de trabalho, use o seguinte filtro na consulta anterior:
protoPayload.response.metadata.name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Ao comparar as latências de pods individuais, é possível testar o impacto de várias configurações na latência de inicialização do pod e identificar uma configuração ideal com base nos seus requisitos.
Determinar a latência de programação do pod
A latência de programação de pods é o tempo entre a criação de um pod e a programação dele em um nó. A latência de programação de pods contribui para o tempo de inicialização de ponta a ponta de um pod e é calculada subtraindo os carimbos de data/hora de um evento de programação de pod e uma solicitação de criação de pod.
É possível encontrar um carimbo de data/hora de um evento de programação de pod individual no campo
jsonPayload.eventTime de um evento de programação de pod correspondente. Para ver o campo jsonPayload.eventTime, execute a seguinte consulta no Explorador de registros:
log_id("events")
jsonPayload.reason="Scheduled"
resource.type="k8s_pod"
resource.labels.project_id=PROJECT_ID
resource.labels.location=CLUSTER_LOCATION
resource.labels.cluster_name=CLUSTER_NAME
resource.labels.namespace_name=NAMESPACE
resource.labels.pod_name=POD_NAME
Para listar todos os eventos de programação de pods da sua carga de trabalho, use o seguinte filtro na consulta anterior: resource.labels.pod_name=~"POD_NAME_PREFIX-[a-f0-9]{7,10}-[a-z0-9]{5}"
Ver a latência de extração de imagens
A latência de extração de imagens de contêiner contribui para a latência de inicialização do pod em cenários em que a imagem ainda não está disponível no nó ou precisa ser atualizada. Ao otimizar a latência de extração de imagens, você reduz a latência de inicialização da carga de trabalho durante eventos de escalonamento horizontal do cluster.
É possível consultar a tabela Eventos de extração de imagens do Kubelet para saber quando as imagens de contêiner da carga de trabalho foram extraídas e quanto tempo o processo levou.
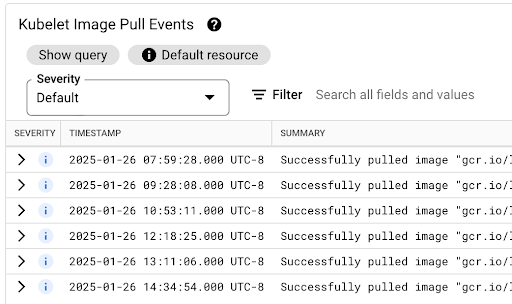
A latência de extração de imagens está disponível no campo jsonPayload.message, que contém uma mensagem como esta:
"Successfully pulled image "gcr.io/example-project/image-name" in 17.093s (33.051s including waiting). Image size: 206980012 bytes."
Ver a distribuição de latência das recomendações de escalonamento do HPA
A latência das recomendações de escalonamento do escalonador automático horizontal de pods (HPA) para o destino do HPA é o tempo entre a criação das métricas e a aplicação da recomendação de escalonamento correspondente ao servidor de API. Ao otimizar a latência de recomendação de escalonamento do HPA, você reduz a latência de inicialização da carga de trabalho durante eventos de escalonamento horizontal.
O escalonamento do HPA pode ser visto nos dois gráficos a seguir:
Gráfico Distribuição de latência de recomendação de escalonamento de HPA: mostra os percentis de latência de recomendação de escalonamento de HPA (50º, 95º e 99º percentis) calculados com base nas observações de recomendações de escalonamento de HPA em intervalos de tempo de três horas. Você pode usar esse gráfico para os seguintes propósitos:
- Entenda a latência de recomendação de escalonamento do HPA de referência.
- Identifique mudanças na latência das recomendações de escalonamento do HPA ao longo do tempo.
- Correlacione mudanças na latência de recomendação de escalonamento do HPA com eventos recentes. É possível selecionar os eventos na lista Anotações na parte de cima do painel.
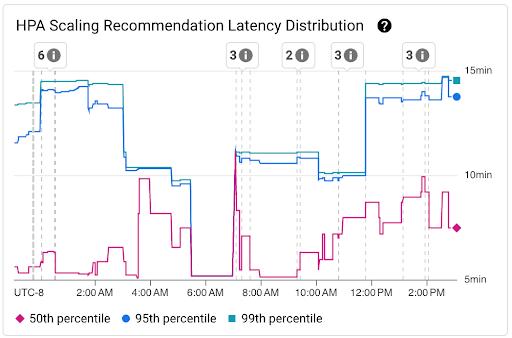
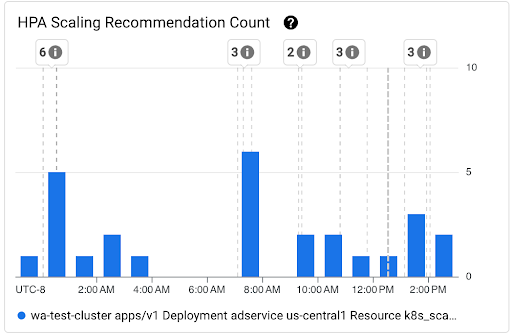
Gráfico Contagem de recomendações de escalonamento do HPA: mostra a contagem de recomendações de escalonamento do HPA observadas durante o intervalo de tempo selecionado. Use o gráfico para as seguintes tarefas:
- Entenda os tamanhos de amostra das recomendações de escalonamento do HPA. As amostras são usadas para calcular os percentis na distribuição de latência das recomendações de escalonamento do HPA para um determinado intervalo de tempo.
- Correlacione as recomendações de escalonamento do HPA com novos eventos de inicialização de pod e com eventos do escalonador automático horizontal de pods. É possível selecionar os eventos na lista Anotações na parte de cima do painel.
Conferir problemas de programação para pods
Problemas de programação de pods podem afetar a latência de inicialização de ponta a ponta da sua carga de trabalho. Para reduzir a latência de inicialização de ponta a ponta da sua carga de trabalho, resolva e reduza o número desses problemas.
Estes são os dois gráficos disponíveis para rastrear esses problemas:
- O gráfico Pods não programáveis/pendentes/com falha mostra as contagens de pods não programáveis, pendentes e com falha ao longo do tempo.
- O gráfico Contêineres com falha de espera/suspensão/prontidão mostra as contagens de contêineres nesses estados ao longo do tempo.
Ver o painel de latência de inicialização dos nós
Para conferir as métricas de latência de inicialização dos nós, siga estas etapas no console doGoogle Cloud :
Acesse a página Clusters do Kubernetes.
Para abrir a visualização Detalhes do cluster, clique no nome do cluster que você quer inspecionar.
Clique na guia Observabilidade.
No menu à esquerda, selecione Latência de inicialização.
Ver a distribuição da latência de inicialização dos nós
A latência de inicialização de um nó se refere à latência total, que mede o tempo desde o CreationTimestamp do nó até o status Kubernetes node ready. A latência de inicialização do nó pode ser vista nos dois gráficos a seguir:
Gráfico Distribuição da latência de inicialização do nó: mostra os percentis da latência de inicialização do nó (50º, 95º e 99º percentis) calculados com base nas observações de eventos de inicialização do nó em intervalos fixos de três horas, por exemplo, de 0h às 3h e de 3h às 6h. Use esse gráfico para:
- Entenda a latência de inicialização do nó de referência.
- Identifique mudanças na latência de inicialização do nó ao longo do tempo.
- Correlacione as mudanças na latência de inicialização do nó com eventos recentes, como atualizações de cluster ou de pool de nós. É possível selecionar os eventos na lista Anotações na parte de cima do painel.
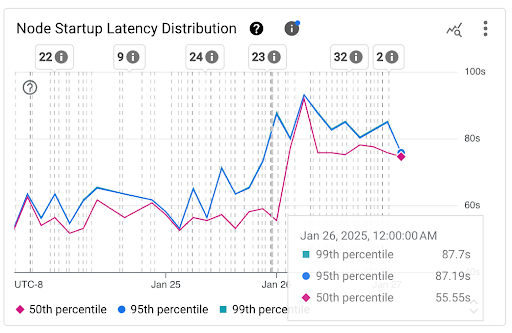
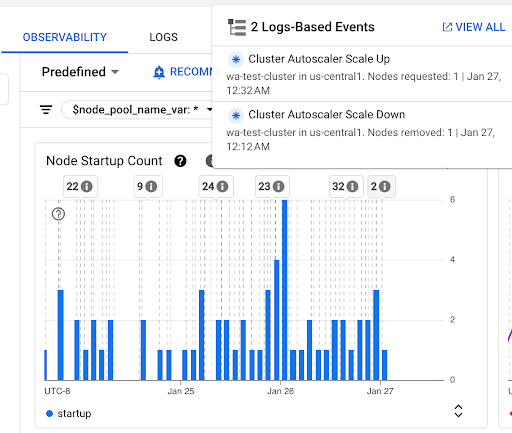
Gráfico Contagem de inicialização de nós: mostra a contagem de nós iniciados durante os intervalos de tempo selecionados. É possível usar o gráfico para as seguintes finalidades:
- Entenda os tamanhos de amostra de nós, usados para calcular os percentis de distribuição de latência de inicialização de nós em um determinado intervalo de tempo.
- Entenda as causas das inicializações de nós, como atualizações de pool de nós ou eventos do escalonador automático de cluster. É possível selecionar os eventos na lista Anotações na parte de cima do painel.
Ver a latência de inicialização de nós individuais
Ao comparar as latências de nós individuais, é possível testar o impacto de várias configurações de nós na latência de inicialização e identificar uma configuração ideal com base nos seus requisitos. É possível conferir a latência de inicialização de nós individuais no gráfico de linha do tempo Latência de inicialização do nó e na lista associada.
Use o gráfico de linha do tempo Latência de inicialização do nó para correlacionar inicializações de nós individuais com eventos recentes, como atualizações de cluster ou de pool de nós. Você pode determinar as possíveis causas das mudanças na latência de inicialização em comparação com outros nós. É possível selecionar os eventos na lista Anotações na parte de cima do painel.
Use a lista Latência de inicialização do nó para identificar os nós individuais que levaram mais ou menos tempo para serem iniciados. É possível classificar a lista pela coluna Latência. Ao identificar os nós com a maior latência de inicialização, é possível resolver problemas de degradação de latência correlacionando eventos de início de nó com outros eventos recentes.
Para saber quando um nó individual foi criado, consulte o valor do campo protoPayload.metadata.creationTimestamp em um evento de criação de nó correspondente. Para ver o campo protoPayload.metadata.creationTimestamp, execute a
consulta a seguir no Explorador de registros:
log_id("cloudaudit.googleapis.com/activity") AND
protoPayload.methodName="io.k8s.core.v1.nodes.create" AND
resource.labels.project_id=PROJECT_ID AND
resource.labels.cluster_name=CLUSTER_NAME AND
resource.labels.location=CLUSTER_LOCATION AND
protoPayload.response.metadata.name=NODE_NAME
Ver a latência de inicialização em um pool de nós
Se os pools de nós tiverem configurações diferentes, por exemplo, para executar cargas de trabalho diferentes, talvez seja necessário monitorar a latência de inicialização do nó separadamente por pools de nós. Ao comparar as latências de inicialização de nós nos pools, é possível entender como a configuração afeta a latência e, consequentemente, otimizá-la.
Por padrão, o painel Latência de inicialização do nó mostra a distribuição agregada de latência de inicialização e as latências de inicialização de nós individuais em todos os pools de nós de um cluster. Para conferir a latência de inicialização de um pool de nós específico, selecione o nome dele usando o filtro $node_pool_name_var, localizado na parte de cima do painel.
A seguir
- Saiba como otimizar o escalonamento automático de pods com base em métricas.
- Saiba mais sobre maneiras de reduzir a latência de inicialização a frio no GKE.
- Saiba como reduzir a latência de extração de imagens com o streaming de imagens.
- Saiba mais sobre a economia surpreendente do ajuste do escalonamento automático horizontal de pods.
- Monitore suas cargas de trabalho com o monitoramento automático de aplicativos.