Datastore での高速で信頼性の高いランキング処理
ランキング処理: シンプルでありながら非常に難しい問題
株式会社アプリボットで App Engine リード エンジニアを務める鈴木智明氏(図 1)は、大規模なゲームサービスでよく直面する難問であるランキング処理に取り組んでいました。

アプリボットは、日本の大手ソーシャル アプリケーション プロバイダです。同社の強みは、Google の提供する PaaS(Platform as a Service)である Google App Engine でのスーパー スケーラブルなソーシャル ゲーム サービスの構築に関する豊富な知識と経験にあります。アプリボットは、プラットフォームの機能を活用し、日本だけでなく米国のソーシャル ゲーム市場におけるビジネス機会も獲得してきました。アプリボットには、その成功を証明する実績があります。アプリボットを代表するタイトルの 1 つ、『レジェンド オブ モンスターズ』(図 2)は、北米 Apple AppStore のゲームカテゴリで、2012 年 10 月に 1 位を獲得しました。レジェンド シリーズは、4,700 万回のダウンロードを記録しています。別タイトルの『ギャングロード』は、AppStore Japan の総売り上げランキングで 2012 年 12 月に 1 位を獲得しました。

これらのタイトルでは、スムーズなスケーリングと急激に増加するトラフィックの処理が行われましたが、アプリボットが仮想サーバーや分割データベースの複雑なクラスタを構築するために苦労することはありませんでした。App Engine の機能を活用することで、スケーラビリティと可用性を効率的に実現することができたのです。
しかし、最新のプレーヤー ランキングの処理は簡単に解決できる問題ではありません。これは鈴木氏のみならず、特に同規模のスケールのゲーム開発を行うあらゆるデベロッパーにも言えることです。このケースでの要件は次のようにシンプルです。
- ゲームには数十万以上のプレーヤーがいる
- プレーヤーが敵と戦う(またはその他のアクティビティを行う)たびにスコアが変化する
- ウェブ ポータル ページに常に最新のプレーヤー ランキングを表示する必要がある
ランクの計算方法

スケーラビリティやレスポンスの速さが求められないのであれば、ランクの取得は難しくはありません。たとえば、以下のようなクエリを実行することもできるでしょう。
SELECT count(key) FROM Players WHERE Score > YourScore
このクエリは、特定のプレーヤーよりスコアの高いプレーヤーをすべてカウントします(図 4)。しかし、ポータルページからリクエストがあるたびにこのようなクエリを実行することはおすすめできません。100 万人ものプレーヤーがいる場合、どれほどの時間がかかるかわかりません。
鈴木氏はまずこの方法を試しましたが、レスポンスを得るのに数秒かかってしまいました。これでは遅すぎるうえ、実行コストも高く、プレーヤー数が増えるほどパフォーマンスが落ちてしまいます。
鈴木氏は Memcache でランキング データを保持する方法も検討しました。この方法は、レスポンスが速いものの、信頼性がありませんでした。Memcache のエントリはいつでも強制排除される可能性があり、Memcache サービス自体が一時的に利用できなくなる場合もありました。インメモリキー値にのみ依存するランキング サービスでは、整合性と可用性を維持することは困難でした。
一時的な次善策として、鈴木氏はサービスレベルを下げることを選択しました。リクエストごとにランクを計算するのではなく、タスクのスケジュール設定を行い、全プレーヤーのランクを 1 時間に 1 回スキャンして更新するようにしたのです。この方法では、ポータルページからのリクエストによってすぐにプレーヤーのランクを取得できますが、ランキングは最大で 1 時間前の内容になってしまいます。
最終的に鈴木氏が求めるランキング処理方法は、永続的でトランザクショナルな、レスポンスの速さとスケーラビリティを兼ね備えたものでした。具体的には、1 秒あたり 300 件程のスコア更新に対応し、各プレーヤーのランクを 100 ミリ秒で取得する必要があります。こうしたソリューションを求める鈴木氏は、プレミアムレベル サポート契約によってアプリボットの担当となっていた Google Cloud Platform チームのソリューション アーキテクト(SA)でありテクニカル アカウント マネージャー(TAM)である佐藤一憲に相談しました。
問題を素早く解決する方法
アプリボットに代表される Google Cloud Platform の大口顧客やパートナーの多くが、プレミアムレベル サポート契約を利用しています。このサポート契約では、Cloud Customer Support チームによる年中無休のサポートや Cloud Sales チームのビジネス サポートに加え、各顧客に割り当てられたテクニカル アカウント マネージャー(TAM)のサポートを受けることができます。
TAM は、実際のクラウド インフラを構築する Google エンジニアリングに顧客の話を伝えます。TAM は顧客のシステムやアーキテクチャを詳細まで理解し、重大な事例が生じたときには、Google エンジニアリングの代表として知識やネットワークを活用し、問題を解決します。TAM は、チーム内のソリューション アーキテクトや Cloud Platform チームのソフトウェア エンジニアに問題をエスカレーションできます。プレミアムレベル サポートがあれば、Google Cloud Platform によって素早くソリューションを見つけることができます。
アプリボットを担当する TAM の佐藤は、ランキング処理が、スケーラブルな分散型サービスでは解決の難しい定番の問題であることを理解していました。佐藤は、それまでに Google Cloud Datastore やその他の NoSQL Datastore で実装されてきたランキング処理を調べ、アプリボットの要件を満たすソリューションを発見しました。
O(log n) アルゴリズムを探す
単純なクエリを使用する方法では、プレーヤーより高いスコアを持つすべてのプレーヤーをスキャンしなければなりません。このアルゴリズムの計算時間は O(n) です。すなわち、クエリの実行時間はプレーヤー数の増加に比例して増加するため、スケーラビリティの高いアルゴリズムであるとは言えません。代わりに、計算時間が O(log n) になるような、プレーヤー数が増加しても処理時間は対数的にしか増えないアルゴリズムが必要です。
コンピュータ サイエンスの授業を受けたことがある方なら、二分木、赤黒木、B 木などのツリー アルゴリズムを用いることでデータの探索を O(log n) 時間で実行できることを覚えているでしょう。ツリー アルゴリズムは、集約した値を個々のブランチノードに置くことにより、ノードの数や最大値 / 最小値、平均値などのさまざまな集計にも応用できます。この方法により、O(log n) パフォーマンスのランキング アルゴリズムを実装することができます。
佐藤は、ツリーベースのランキング アルゴリズムをオープンソースで実装する方法を発見しました。それは、Google のエンジニアが Datastore 向けに実装した Google Code Jam Ranking Library です。
この Python ベースのライブラリは、2 つのメソッドを公開しています。
SetScoreはプレーヤーのスコアを設定します。FindRankは指定のスコアのランクを取得します。
プレーヤーとスコアのペアが SetScore メソッドで作成および更新されるのと同時に、Code Jam Ranking Library は N-ary ツリー1 を構築します。たとえば、スコアが 0~80 のプレーヤーの数をカウントできる三分木があるとします(図 5)。ライブラリは、3 つの数字を 1 つのエンティティとして保持するルートノードを保存します。各数字は、スコアがサブ範囲の 0~26、27~53、54~80 に収まるプレーヤーの数にそれぞれ対応します。ルートノードは、各範囲の子ノードを持ち、結果として、サブ範囲のサブ範囲に収まるプレーヤーの 3 つの値を保持します。81 種類のスコア値を持つプレーヤー数を保存するには、4 つの階層が必要です。
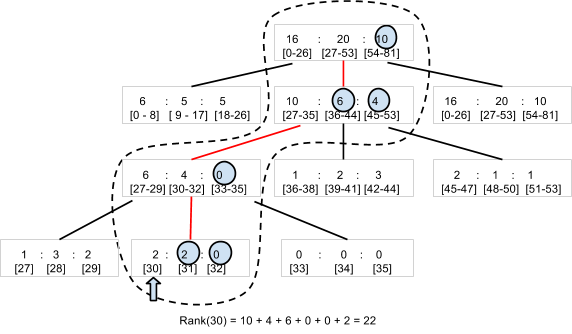
スコアが 30 のプレーヤーのランクを判定する際のライブラリの処理は、4 つのエンティティ(上図の点線で囲まれたノード)を読み取り、スコアが 30 を超えるプレーヤーの数を合計するのみになります。4 つのエンティティの右側のプレーヤー数は 22 であるため、プレーヤーのランクは 23 位になります。
このように、SetScore の呼び出しで必要なのは、4 つのエンティティの更新のみです。異なるスコアが大量にあったとしても、Datastore のアクセスは O(log n) でしか増加せず、プレーヤーの数に影響を受けません。実際に、Code Jam Ranking Library は、ノードごとのデフォルト値として(3 ではなく)100 を使用するため、アクセスする必要があるのは 2 つ(スコア範囲が 100,000 を超える場合は 3 つ)のエンティティのみです。
佐藤は有名な負荷テストツール Apache JMeter を使用して Code Jam Ranking Library の負荷テストを実行し、ライブラリのレスポンスが速いことを確認しました。SetScore と FindRank のいずれも、O(log n) 時間で機能する N-ary ツリー アルゴリズムを使用して 100 ミリ秒以内にジョブを完了できます。
同時更新によるスケーラビリティの制限
しかし、負荷テストを行う中、佐藤は Code Jam Ranking Library に重大な制限を発見しました。更新スループットのスケーラビリティが非常に低かったのです。負荷テストによる更新処理を毎秒 3 件に上げると、ライブラリはトランザクション リトライ エラーを返すようになりました。この状況では、アプリボットの要件である毎秒 300 件の更新をこのライブラリで実現できないことは明らかでした。スループットのわずか 1% しか処理できないことになります。
この理由は、ツリーの整合性を維持するコストにあります。Datastore では、トランザクションで複数のエンティティを更新するときに、エンティティ グループを使用して強整合性を確保する必要があります(詳しくは Google Cloud Datastore での強整合性と結果整合性のバランスをご覧ください)。Code Jam Ranking Library では、ツリー全体を 1 つのエンティティ グループに収めることで、ツリー エレメントのカウントの整合性を保つ設計になっています。
しかし、Datastore のエンティティ グループにはパフォーマンスの制限があります。Datastore は、1 つのエンティティ グループで 1 秒あたり 1 トランザクションしかサポートできません。さらに、同じエンティティ グループが同時実行トランザクションで変更された場合、これらは失敗する可能性が高く、再試行が必要になります。こうして Code Jam Ranking Library は整合性に優れ、トランザクショナルで、十分な速さがあるものの、大量の同時更新はサポートできないことがわかりました。
Datastore チームのソリューション: ジョブ アグリゲーション
佐藤は、Datastore チームのソフトウェア エンジニアが、エンティティ グループで 1 秒ごとに更新するよりも高いスループットを実現するための技術について話していたことを思い出しました。これは、更新のバッチをそれぞれ独立したトランザクションとして更新するのではなく、1 つのトランザクションに集約させることで実現します。しかし、トランザクションには大量の更新が含まれるため、各トランザクションの処理は時間がかかり、同時実行トランザクションで競合が生じる可能性が高まります。
佐藤からリクエストを受けた Datastore チームは、この問題について議論を始め、Megastore で使用されている設計パターンの 1 つであるジョブ アグリゲーションを使用するようにアドバイスしました。
Megastore は、Datastore の基盤となるストレージ レイヤで、エンティティ グループの整合性とトランザクション性を管理します。1 秒に 1 件の更新の制限はこのレイヤから生まれたものです。Megastore は、さまざまな Google サービスで幅広く使用されています。エンジニアは、ベスト プラクティスと設計パターンを収集して社内で共有し、この NoSQL Datastore によってスケーラブルで整合性のあるシステムを構築します。
ジョブ アグリゲーションの基本的な考え方は、シングル スレッドを使用して更新のバッチを処理するというものです。エンティティ グループにはスレッドとオープンなトランザクションがそれぞれ 1 つしかないため、同時更新によってトランザクションが失敗することはありません。VoltDb や Redis などの他のストレージ プロダクトでも同様のアイデアが見られます。
しかし、ジョブ アグリゲーション パターンには欠点が 1 つあります。それは、すべての更新の集約にスレッドを 1 つしか使用しないため、Datastore に更新を送信する速度に制限があるという点です。そのため、ジョブ アグリゲーションが毎秒 300 件の更新というアプリボットのスループット要件を満たすことができるかどうかを確認する必要がありました。
pull キューによるジョブ アグリゲーション
Datastore チームのアドバイスに基づき、佐藤は PoC(Proof of Concept)コードを作成しました。これはジョブ アグリゲーション パターンと Code Jam Ranking Library を組み合わせるものです。概念実証には次のコンポーネントがあります。
- フロントエンド: ユーザーからの
SetScoreリクエストを承認し、pull キューにタスクとして追加します。 - pull キュー: フロントエンドから
SetScore更新リクエストを受け取って保持します。 - バックエンド: 1 つのスレッドで無限ループを実行して更新リクエストをキューから pull し、Code Jam Ranking Library で実行します。
概念実証は pull キューを作成します。このキューは App Engine のタスクキューの 1 つで、これによってデベロッパーはキューに追加されたタスクを消費するワーカー(複数可)を実装できます。バックエンド インスタンスは、無限ループ内にシングル スレッドを持ち、キューから可能な限り多くのタスクを pull し続けます(最大 1,000)。スレッドは各更新リクエストを Code Jam Ranking Library にパスし、Code Jam Ranking Library はリクエストを 1 つのトランザクションでバッチとして実行します。トランザクションは 1 秒以上オープンになる場合がありますが、ライブラリや Datastore をドライブしているスレッドが 1 つしかないため、競合や同時変更の問題は発生しません。
バックエンド インスタンスは、モジュールとして定義されます。これは App Engine の機能で、これによりデベロッパーはさまざまな特長を持つアプリケーション インスタンスを定義できます。この PoC では、バックエンド インスタンスは手動スケーリング インスタンスとして定義されます。このようなインスタンスは常に 1 つしか実行されません。
佐藤は、JMeter を使用して PoC の負荷テストを行いました。PoC が秒間 200 の SetScore リクエストを処理でき、トランザクションあたり 500~600 の更新に対応できることがわかり、ジョブ アグリゲーションが要件を満たしていることが確認されました。
キュー分散でパフォーマンスを安定させる
しかし、佐藤はすぐに別の問題を発見しました。負荷テストを数分間継続したことにより、pull キューのスループットがときどき変動することがわかったのです(図 6)。具体的には、秒間 200 のタスクでキューにリクエストを数分間追加し続けると、突然キューがタスクをバックエンドに渡さなくなり、各タスクのレイテンシが劇的に上昇しました。
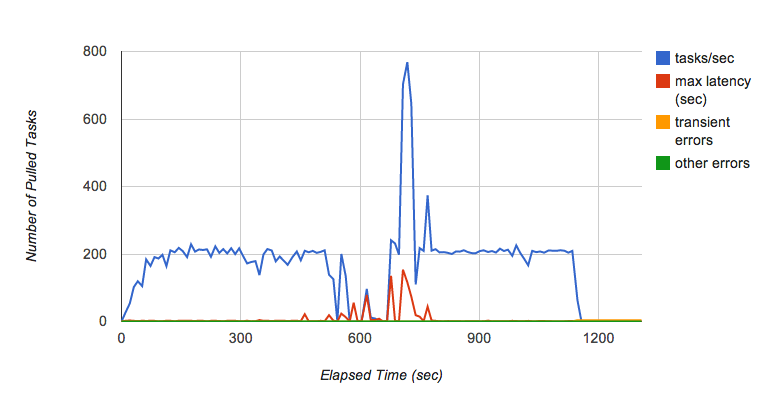
佐藤はタスクキュー チームに相談し、この原因を探りました。タスクキュー チームによれば、これは現在の pull キュー実装で報告されている動作であり、永続性レイヤである Bigtable に起因するとのことでした。Bigtable タブレットは、大きくなりすぎると、複数のタブレットに分割されます。タブレットが分割されるとタスクが配信されず、キューが高レートでタスクを受信している場合にはパフォーマンスの変動が発生します。タスクキュー チームは、現在このパフォーマンスの問題の解決に取り組んでいます。
ソリューション アーキテクトの Michael Tang は、この問題について、キュー分散を使用した回避策を推奨しました。Tang が提案したのは、1 つのキューのみを使用する代わりに、複数のキューに負荷を分散することです。これによって各キューは、それぞれ異なる Bigtable タブレット サーバーに保存されるようになり、タブレットの分割の影響が最小化され、タスクの高い処理速度が維持されるようになります。1 つのキューが 1 つのスプリットを処理している間、他のキューは稼働し続けます。さらに、分散によって各キューの負荷は低減するため、タブレットが分割される頻度も下がります。
強化されたバックエンドのインスタンス ループは、次のアルゴリズムを実行します。
- 10 のキューから
SetScoreタスクをリースする。 - タスクで
SetScoresメソッドを呼び出す。 - リースされたタスクをキューから削除する。
ステップ 1 では、各キューは最大 1,000 のタスクを提供し、各タスクはプレーヤー名とスコアを保持します。すべてのプレーヤーとスコアのペアが辞書に集約された後、ステップ 2 で更新のバッチが Code Jam Ranking Library の SetScores メソッドに渡されます。このメソッドはトランザクションを開いて Datastore にペアを保存します。メソッドの実行にエラーがなければ、ステップ 3 によってリースされたタスクがキューから削除されます。
ループまたはバックエンド インスタンスのエラーや予期せぬシャットダウンがあった場合、更新タスクはタスクキューに残るので、インスタンスが再開すれば処理できます。本番環境では、スタンバイ モードのウォッチドッグとして機能し、最初のインスタンスが失敗した場合に処理を引き継げるように備える別のバックエンドが存在する場合があります。
ソリューション案: 秒間 300 の更新を維持して稼働する2
図 7 は、キュー分散を使用した最後の PoC 実装の負荷テストの結果です。キューでのパフォーマンスの変動が効率良く抑えられ、秒間 300 の更新が数時間にわたって維持されるようになっています。一般的な負荷条件下では、各更新はリクエスト受信から数秒以内に Datastore に適用されます。
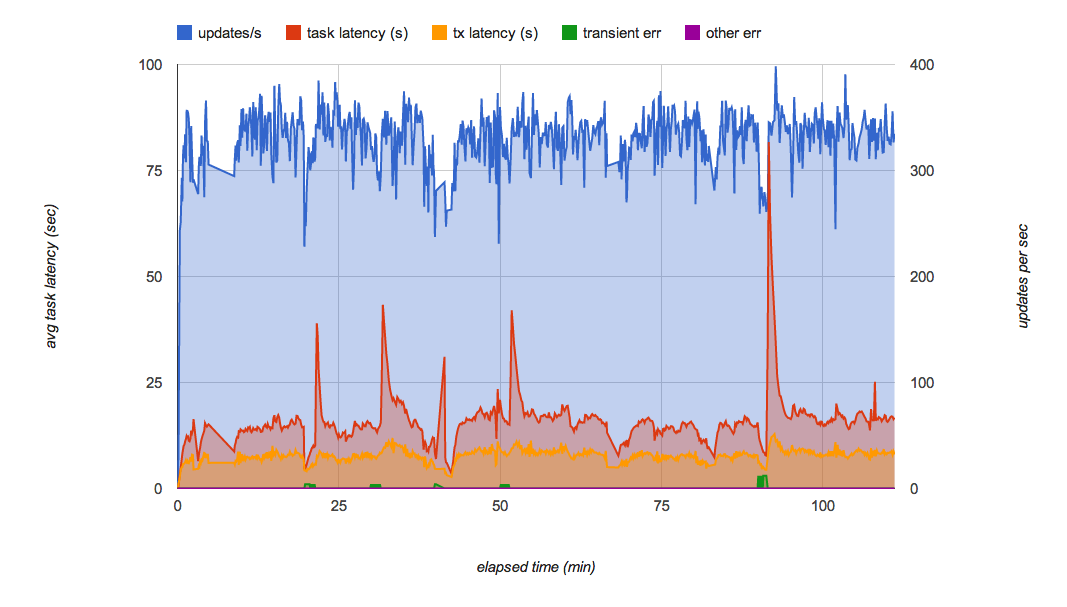
このソリューションは、アプリボットの元の要件をすべて満たしています。
- 数万のプレーヤーに対応するスケーラビリティ
- すべての更新が Datastore のトランザクションで実行される永続性と整合性
- 秒間 300 の更新を処理する速度
佐藤は、負荷テストの結果と PoC コードとともに、ソリューションを鈴木氏をはじめとするアプリボットのエンジニアに提示しました。鈴木氏は、ランキング処理の更新のレイテンシが 1 時間から数秒に削減されること、そしてユーザー エクスペリエンスが劇的に向上することを期待してアプリボットの本番環境システムにこのソリューションを組み込むことを計画しました。
ランキング ツリーの概要とジョブ アグリゲーション
今回のソリューション案には、何点かのメリットと 1 点のデメリットがあります。
メリット:
- 速度:
FindRankの呼び出しが数百ミリ秒以下 - 速度:
SetScoreが送信したタスクは、数秒以内にバックエンドで処理される - Datastore での強整合性と永続性
- 正確なランク
- プレーヤー数を問わないスケーラビリティ
デメリット:
- スループットに制限がある(現在の実装で更新は毎秒 300)
このソリューションはジョブ アグリゲーション パターンを使用するため、すべての更新の集約をシングル スレッドに依存しています。App Engine インスタンスの現在の CPU パワーと Datastore のパフォーマンスで更新が毎秒 300 を超えるスループットを実現するには、追加の作業や組み合わせが必要です。
分散ツリーを使用したさらにスケーラブルなソリューション
さらに更新速度を上げる必要がある場合は、ランキング ツリーを分散して対応することができます。この場合、上記システムを複数(自分のランキング ツリーを更新するバックエンド モジュールをそれぞれが駆動するキューのセット)実装することになるでしょう。
一般に、ツリー間の調整は必要ではなく、また期待もされていません。最も単純なケースでは、各 SetScore の更新はランダムにキューに送信されます。それぞれ固有の Datastore エンティティ グループとバックエンド サーバーを持つツリーが 3 つあると、更新スループットの期待値は 3 倍になります。その代わりに、FindRank は各ランキング ツリーにクエリ送信してスコアのランクを取得し、各ツリーのランクを合算して実際のランクを判断しなければならなくなり、処理時間がわずかに長くなります。FindRank のクエリ時間は、エンティティを Memcache に維持することで大幅に低減できます。
これは、分散カウンタを使用した有名なアプローチに似ています。そのアプローチでは、各カウンタはそれぞれ独立して増分し、クライアントに要求された場合にのみ合計値が算出されます。
たとえば、ツリーが 3 つで、FindRank(865) が 124、183、156 の 3 つのランクを検出するとします。これは、865 を超えるスコアがそれぞれのツリーにそれだけの数だけ存在することを意味します。865 を超えるスコアの合計数として算出される値は、124 + 183 + 156 = 463 となります。
このアプローチは、すべての分散アルゴリズムで機能するわけではありませんが、ランキング処理は基本的に累積カウントの問題であるため、ボリュームの大きなランキング処理の問題解決に役立ちます。
近似アプローチによるさらにスケーラブルなソリューション
アプリケーションでランクの精度よりもスケーラビリティが重視され、一定の誤差や近似値が許容される場合は、次のような推計アプローチを選択できます。
- グローバル クエリとバケット
- Lossy Counting メソッド
- フルーガル ストリーミング
これらの近似アプローチは、すべて 1 つのアイデアが変化したものです。そのアイデアとは、ランキング精度をある程度犠牲にしてランキング情報のストレージを圧縮するというものです。
グローバル クエリとバケット: Datastore チームと Alex Amies(TAM)が提案する代替ソリューションです。Amies は Datastore チームのアイデアに基づいて概念実証を実装し、拡張パフォーマンス解析を行いました。解析により、バケットとグローバル クエリは、ランキング精度の低下を最小限に抑えたスケーラブルなランキング処理ソリューションであり、Code Jam Ranking Library よりも高いスループットが必要なアプリケーションに適していることが証明されました。詳しい説明とテスト結果については、付録をご覧ください。
Lossy Counting メソッドとフルーガル ストリーミング: いわゆるオンライン アルゴリズムとストリーム アルゴリズムです。非常に小さなインメモリ ストレージを使用して、プレーヤーとスコアのペアのストリーミングからトップランクの統計的推定値を算出できます。これらのアルゴリズムは、更新が毎秒数千に及ぶなど、ランキング結果の精度や範囲よりも、レイテンシの低さと帯域幅の高さが優先されるアプリケーションに適しています。たとえば、ソーシャル ネットワーキング ストリーミングに入力されるキーワードの上位 100 を示すリアルタイムのダッシュボードが必要な場合、このアルゴリズムが役立ちます。
まとめ
ランキング処理は、スケーラビリティ、整合性、速度の優れたアルゴリズムが求められる場合、定番ではあるものの解決が難しい問題です。この記事では、Google TAM が顧客や Google エンジニアリング チームと連携して問題に取り組み、ランキング更新のレイテンシを 1 時間から数秒に短縮するソリューションを提示するまでを説明しました。プロセスの中で発見された設計パターンであるジョブ アグリゲーションやキュー分散は、毎秒数百の更新と強整合性が必要な他の Datastore ベースのシステム設計の一般的な問題にも適用可能です。
備考
- Code Jam Ranking Library は、「ブランチング ファクター」と呼ばれるパラメータを使用します。このパラメータは、各エンティティが保持するスコアの数を指定します。デフォルトでは、ライブラリはパラメータとして 100 を使用します。この場合、0~9999 のスコアは、ルートノードの子として、100 エンティティに保存されます。より広い範囲のスコアを処理することが必要な場合は、ブランチング ファクターを高い値に変更し、エンティティ アクセスの数を最適化することができます。
- この記事で説明されているパフォーマンス数値は参考用のサンプルであり、App Engine や Datastore などのサービスの絶対的パフォーマンスを保証するものではありません。
付録: バケットとグローバル クエリによるソリューション
ランクの取得方法のセクションにあるように、ランキングのリクエストがあるたびにデータベースにクエリを送信するとコストがかさみます。この代替アプローチは、すべてのスコアのカウントを定期的に取得して指定のスコアのランクを算出し、特定のプレーヤーのランク算出に使用できるようにこれらのデータポイントを提供します。スコアの全範囲は、「バケット」に分割されます。各バケットは、スコアのサブ範囲やスコアがその範囲内にあるプレーヤーの数で区別できます。このデータから、すべてのスコアのランクを近似値で出すことができます。これらのバケットは、ランキング ツリーのトップレベル ノードと同様ですが、このアルゴリズムは、より詳細なノードに下りる代わりにバケット内で補間を行います。
ユーザーによるフロントエンドからのランクの取得は、バケットでのランク算出から分離されるため、ランクの確認にかかる時間は最小限に抑えられます。プレーヤーのランクがリクエストされると、プレーヤーのスコアに基づいて該当するバケットが検出されます。バケットには、上位ランクの境界やバケット内のプレーヤーの数が含まれます。バケット内での線形補間は、バケット内のプレーヤーのランクを見積もるために使用されます。今回のテストでは、完全な HTTP ラウンド トリップで、プレーヤーのランクを一貫して 400 ミリ秒未満で取得できました。FindRank メソッドのコストは、ポピュレーション内のプレーヤー数に依存しません。
指定スコアのランクを算出する

カウントと最上位ランク(バケット内の最高ランク)は、バケットごとに記録されます。バケット内の低スコアと高スコアの境界の間のスコアについては、線形補間を使用してランクを見積もります。たとえば、プレーヤーのスコアが 60 である場合、カウント(バケット内のプレーヤー / スコアの数)(42)と最上位ランク(5)を使用して [50, 74] のバケットを調べ、次の式でプレーヤーのランクを算出します。
rank = 5 + (74 - 60)*42/(74 - 50) = 30
各バケットのカウントと範囲の算出
各バケットのカウントは、バックグラウンドで cron ジョブやタスクキューを使用して算出され、すべてのバケットで反復処理されて保存されます。この処理は、「グローバル クエリ」と呼ばれます。すべてのプレーヤーのスコアを調べてランクを見積もるのに必要なパラメータを算出するためです。各バケットの範囲 [low_score, high_score] 内のスコアによってこれを行うサンプルの Python コードを以下に示します。
next_upper_rank = 1 for b in buckets: count = GetCountInRange(b.low_score, b.high_score) b.count = count b.upper_rank = next_upper_rank b.put() next_upper_rank += count
GetCountInRange() メソッドは、スコアがバケットの範囲内に収まる各プレーヤーをカウントします。Datastore は、プレーヤー スコアに並べ替えられたインデックスを維持するため、このカウントは効率的に算出されます。
特定のプレーヤーのランクを確認する場合は、次のようなコードを使用できます。
b = GetBucketByScore(score) rank = RankInBucket(b, score) return rank + b.upper_rank - 1
GetBucketByScore(score) メソッドは、指定のスコアを含むバケットを取得します。RankInBucket() メソッドは、バケット内のランクの見積もりを実行します。プレーヤーのランクは、バケットの最上位ランクと、プレーヤーのスコアを含む指定バケット内のランクの合計です。この結果からは 1 を引く必要があります。これは、トップバケットの最上位ランクが 1 となり、指定バケットのトップ プレーヤーのランクも 1 となるためです。
バケットは、Datastore と Memcache の両方に保存されます。ランクの算出では、Memcache(Memcache のデータが失われている場合は Datastore)からバケットが読み取られます。このアルゴリズムの Google 独自の実装では、Datastore に保存されたデータを Memcache でキャッシュ保存する Python NDB Client Library を使用しました。
バケット(またはメソッド)はデータのコンパクト化を目的に使用されるため、算出されるランクは正確ではありません。バケット内のランクは線形補間による近似値になっています。精度を上げる必要がある場合は、回帰式などの補間メソッドを使用して、バケット内の近似値の精度を上げることができます。
コスト
ランク確認とプレーヤーのスコアの更新のコストは、いずれも「O(1)」です。これは、コストがプレーヤーの数に依存しないことを意味しています。
グローバル クエリジョブのコストは「O(Players) × キャッシュ更新の頻度」になります。
バックエンド ジョブでのバケットデータの算出のコストも、バケットの数に関連します。これは、各バケットに対してカウントクエリが実行されるためです。「カウントクエリ」は、キーのみのクエリを使用するように最適化されますが、たとえそうであっても、完全なキーリストを取得する必要があります。
長所
このメソッドは、プレーヤーのスコアの更新とスコアのランクの確認の両方を非常に素早く処理できます。結果がバックグラウンド ジョブに基づいていたとしても、プレーヤーのスコアが変化すると、ランクはすぐに適切に変化します。これは、バケット内部で補間が使用されるためです。
バケットの再上位ランクの算出はスケジューリングされたジョブによってバックグラウンドで実行されるため、プレーヤーのスコアは、バケットデータを同期させることなく更新できます。そのため、プレーヤーのスコアの更新のスループットは、このアプローチでは制限されません。
短所
すべてのプレーヤーのスコアをカウントする時間、グローバル ランクを算出する時間、バケットを更新する時間を考慮する必要があります。このテストでは、Google の App Engine のテストシステムを使用し、プレーヤー数は 1,000 万人、時間は 8 分 34 秒でした。各プレーヤーのランクを算出した場合にかかる数時間よりも速くなっているものの、代わりに各バケットのスコアは近似値になります。対照的に、ツリー アルゴリズムは「バケット範囲」(ツリーのトップノード)を数秒ごとに追加算出しますが、実装手順が非常に複雑で、スループットが制限されます。
すべてのケースにおいて、FindRank の時間は、Memcache からの素早いデータ取得(バケットまたはツリーノード)に依存します。Memcache から排除されたデータは、Datastore から再フェッチされ、その後の FindRank リクエストのために再度キャッシュに保存される必要があります。
精度
バケット メソッドの精度は、バケット数、プレーヤーのランク、スコアの分散に依存します。図 9 に、バケット数によるランク見積もりの精度の変化を確認した Google の研究の結果を示します。

プレーヤー 10,000 名に対し、範囲 [0-9999] のスコアを均等に分散してテストを行いました。相対誤差は、バケット数が 5 の場合であっても約 1% でした。
精度は、高ランク プレーヤーの場合に下がります。この主な理由は、トップスコアのみを見た場合には大数の法則が適用されないためです。多くの場合、より正確なアルゴリズムを使用して 1,000~2,000 人のトップスコア プレーヤーのランクを維持することが解決策となります。トラッキングされるプレーヤーが少なくなり、それに応じて集約率が下がるため、問題は大幅に軽減します。
均等に分布したランダムな数字を使用し、累積分布関数が線形である上記テストでは、バケット内での線形補間が使用されています。しかし、バケット内の補間は、スコアが高濃度分布である場合も適切に機能します。図 10 に、スコアがほぼ正規分布の場合のランクの見積もりと実際値を示します。
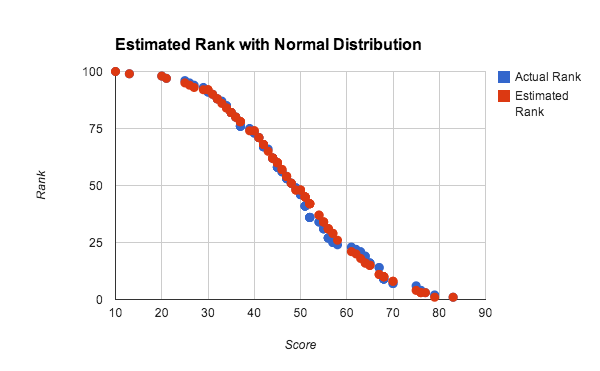
この実験では、プレーヤー 100 名で、小規模データセットでの精度をテストしました。各スコアは、0~100 の 4 つのランダムな数字を使用して生成され、おおよそ正規分布になっています。ランクの見積もりは、10 のバケットで線形補間を行い、グローバル クエリ メソッドを使用して算出されました。非常に小規模なデータセットや不均一な分布であっても、良好な結果が得られています。