Objetivos
Neste tutorial, mostramos como instalar o componente Jupyter do Dataproc em um novo cluster e, em seguida, se conectar à interface do notebook Jupyter UI execução no cluster a partir do navegador local usando o gateway de componentes do Dataproc.
Custos
Neste documento, você usará os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
Se ainda não tiver feito isso, crie um Google Cloud projeto e um bucket do Cloud Storage.
Como configurar o projeto
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, and Cloud Storage APIs.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, Compute Engine, and Cloud Storage APIs.
- Install the Google Cloud CLI.
-
To initialize the gcloud CLI, run the following command:
gcloud init
Como criar um bucket do Cloud Storage no projeto para armazenar todos os notebooks criados neste tutorial.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create bucket.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
- For Name your bucket, enter a name that meets the bucket naming requirements.
-
For Choose where to store your data, do the following:
- Select a Location type option.
- Select a Location option.
- For Choose a default storage class for your data, select a storage class.
- For Choose how to control access to objects, select an Access control option.
- For Advanced settings (optional), specify an encryption method, a retention policy, or bucket labels.
- Click Create. Seus blocos de notas serão armazenados no Cloud Storage em
gs://bucket-name/notebooks/jupyter.
Criar um cluster e instalar o componente Jupyter
Crie um cluster com o componente Jupyter instalado.
Abrir as IUs do Jupyter e do JupyterLab
Clique nos links do Gateway de componentes do console do Google Cloud no console do Google Cloud para abrir o notebook do Jupyter ou as IUs do JupyterLab em execução no nó mestre do cluster.
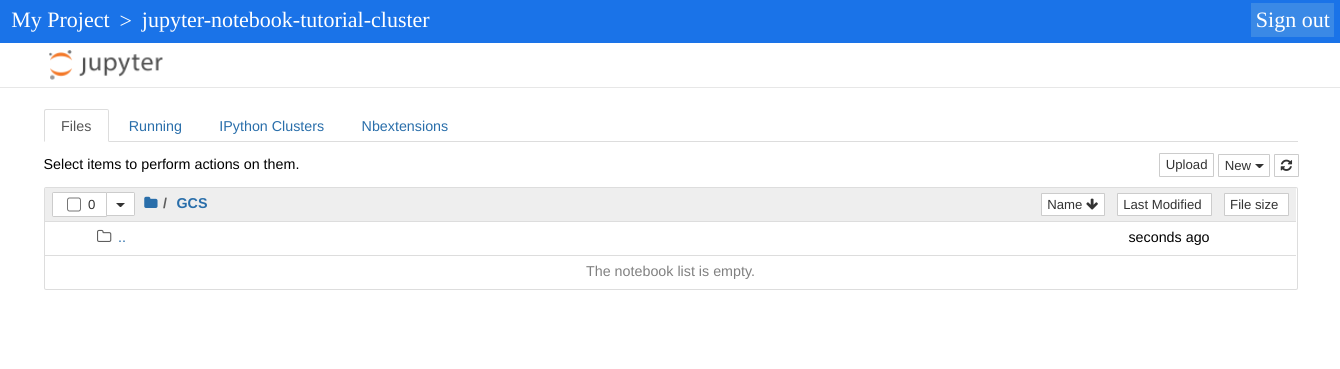
O diretório de nível superior exibido pela instância do Jupyter é um diretório virtual que permite ver o conteúdo do bucket do Cloud Storage ou do sistema de arquivos local. Escolha um dos locais clicando no link GCS do Cloud Storage ou em Disco local para o sistema de arquivos local do nó mestre no cluster.
- Clique no link GCS. A IU da Web do notebook Jupyter exibe os notebooks armazenados no bucket do Cloud Storage, incluindo os notebooks criados neste tutorial.
Limpar
Depois de concluir o tutorial, você pode limpar os recursos que criou para que eles parem de usar a cota e gerar cobranças. Nas seções a seguir, você aprenderá a excluir e desativar esses recursos.
Excluir o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para o tutorial.
Para excluir o projeto:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Exclusão do cluster
- Para excluir o cluster:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}
Exclusão do bucket
- Para excluir o bucket do Cloud Storage criado em Antes de começar, siga a etapa 2, incluindo os notebooks
armazenados no bucket:
gcloud storage rm gs://${BUCKET_NAME} --recursive