Um recurso do Dataproc NodeGroup é um grupo de nós do cluster do Dataproc que executam uma função atribuída. Esta página descreve o grupo de nós de controlador, que é um grupo de VMs do Compute Engine às quais é atribuída a função Driver para executar controladores de tarefas no cluster do Dataproc.
Quando usar grupos de nós de controlador
- Use grupos de nós de controlador apenas quando precisar de executar muitas tarefas simultâneas num cluster partilhado.
- Aumente os recursos do nó principal antes de usar grupos de nós de controlador para evitar limitações do grupo de nós de controlador.
Como os nós de controlador ajudam a executar trabalhos concorrentes
O Dataproc inicia um processo de controlador de tarefas num nó principal do cluster do Dataproc para cada tarefa. Por sua vez, o processo do controlador executa um controlador de aplicações, como o spark-submit, como processo secundário.
No entanto, o número de tarefas simultâneas em execução no nó principal é limitado pelos recursos disponíveis no nó principal e, uma vez que os nós principais do Dataproc não podem ser dimensionados, uma tarefa pode falhar ou ser limitada quando os recursos do nó principal são insuficientes para executar uma tarefa.
Os grupos de nós de controladores são grupos de nós especiais geridos pelo YARN, pelo que a concorrência de tarefas não é limitada pelos recursos do nó principal. Em clusters com um grupo de nós de controlador, os controladores de aplicações são executados em nós de controlador. Cada nó de controlador pode executar vários controladores de aplicações se o nó tiver recursos suficientes.
Vantagens
A utilização de um cluster do Dataproc com um grupo de nós de controlador permite-lhe:
- Escalar horizontalmente os recursos do controlador de tarefas para executar mais tarefas em simultâneo
- Dimensione os recursos dos motoristas separadamente dos recursos dos trabalhadores
- Obtenha uma redução mais rápida nos clusters de imagens do Dataproc 2.0 e posteriores. Nestes clusters, o mestre da app é executado num controlador do Spark num grupo de nós do controlador (o
spark.yarn.unmanagedAM.enabledestá definido comotruepor predefinição). - Personalize o arranque do nó do controlador. Pode adicionar
{ROLE} == 'Driver'a um script de inicialização para que o script execute ações para um grupo de nós de controlador na seleção de nós.
Limitações
- Os grupos de nós não são suportados em modelos de fluxo de trabalho do Dataproc.
- Não é possível parar, reiniciar nem dimensionar automaticamente os clusters de grupos de nós.
- O mestre da app MapReduce é executado em nós de trabalho. A redução dos nós de trabalho pode ser lenta se ativar a desativação gradual.
- A simultaneidade de tarefas é afetada pela
dataproc:agent.process.threads.job.maxpropriedade do cluster. Por exemplo, com três mestres e esta propriedade definida para o valor predefinido de100, a simultaneidade máxima de tarefas ao nível do cluster é300.
Grupo de nós do controlador em comparação com o modo de cluster do Spark
| Funcionalidade | Modo de cluster do Spark | Grupo de nós de controlador |
|---|---|---|
| Redução da escala do nó trabalhador | Os controladores de longa duração são executados nos mesmos nós de trabalho que os contentores de curta duração, o que torna a redução de trabalhadores através da desativação elegante lenta. | Os nós de trabalho são reduzidos mais rapidamente quando os controladores são executados em grupos de nós. |
| Resultado do controlador transmitido | Requer a pesquisa nos registos do YARN para encontrar o nó onde o controlador foi agendado. | A saída do controlador é transmitida para o Cloud Storage e é visível
na Google Cloud consola e na saída do comando gcloud dataproc jobs wait
após a conclusão de uma tarefa. |
Autorizações de IAM do grupo de nós do controlador
As seguintes autorizações da IAM estão associadas às ações relacionadas com o grupo de nós do Dataproc.
| Autorização | Ação |
|---|---|
dataproc.nodeGroups.create
|
Crie grupos de nós do Dataproc. Se um utilizador tiver a autorização
dataproc.clusters.create no projeto, esta autorização é
concedida. |
dataproc.nodeGroups.get |
Obtenha os detalhes de um grupo de nós do Dataproc. |
dataproc.nodeGroups.update |
Redimensione um grupo de nós do Dataproc. |
Operações do grupo de nós do controlador
Pode usar a CLI gcloud e a API Dataproc para criar, obter, redimensionar, eliminar e enviar uma tarefa para um grupo de nós do controlador do Dataproc.
Crie um cluster de grupo de nós de controlador
Um grupo de nós de controlador está associado a um cluster do Dataproc. Cria um grupo de nós como parte da criação de um cluster do Dataproc. Pode usar a CLI gcloud ou a API REST Dataproc para criar um cluster do Dataproc com um grupo de nós de controlador.
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
Flags obrigatórias:
- CLUSTER_NAME: o nome do cluster, que tem de ser exclusivo num projeto. O nome tem de começar por uma letra minúscula e pode conter até 51 letras minúsculas, números e hífenes. Não pode terminar com um hífen. O nome de um cluster eliminado pode ser reutilizado.
- REGION: a região onde o cluster vai estar localizado.
- SIZE: o número de nós de controlador no grupo de nós. O número de nós necessários depende da carga de trabalho e do tipo de máquina do conjunto de controladores. O número de nós do grupo de controladores mínimo é igual à memória total ou às vCPUs necessárias pelos controladores de tarefas, dividido pela memória ou pelas vCPUs da máquina de cada conjunto de controladores.
- NODE_GROUP_ID: opcional e recomendado. O ID tem de ser exclusivo no cluster. Use este ID para identificar o grupo de controladores em operações futuras, como redimensionar o grupo de nós. Se não for especificado, o Dataproc gera o ID do grupo de nós.
Denúncia recomendada:
--enable-component-gateway: adicione esta flag para ativar o Dataproc Component Gateway, que fornece acesso à interface Web do YARN. As páginas da aplicação e do programador da IU do YARN apresentam o estado do cluster e da tarefa, a memória da fila de aplicações, a capacidade do núcleo e outras métricas.
Flags adicionais: é possível adicionar as seguintes flags driver-pool opcionais ao comando gcloud dataproc clusters create para personalizar o grupo de nós.
| Bandeira | Valor predefinido |
|---|---|
--driver-pool-id |
Um identificador de string, gerado pelo serviço se não for definido pela flag. Este ID pode ser usado para identificar o grupo de nós quando realizar futuras operações do conjunto de nós, como redimensionar o grupo de nós. |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
Nenhuma predefinição. Quando especifica um acelerador, o tipo de GPU é obrigatório; o número de GPUs é opcional. |
--num-driver-pool-local-ssds |
Sem predefinição |
--driver-pool-local-ssd-interface |
Sem predefinição |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
Conclua um
AuxiliaryNodeGroup
como parte de um pedido da API Dataproc
cluster.create.
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT_ID: obrigatório. ID do projeto do Google Cloud.
- REGION: obrigatório. Região do cluster do Dataproc.
- CLUSTER_NAME: obrigatório. O nome do cluster, que tem de ser exclusivo num projeto. O nome tem de começar por uma letra minúscula e pode conter até 51 letras minúsculas, números e hífenes. Não pode terminar com um hífen. O nome de um cluster eliminado pode ser reutilizado.
- SIZE: obrigatório. Número de nós no grupo de nós.
- NODE_GROUP_ID: Opcional e recomendado. O ID tem de ser exclusivo no cluster. Use este ID para identificar o grupo de controladores em operações futuras, como redimensionar o grupo de nós. Se não for especificado, o Dataproc gera o ID do grupo de nós.
Opções adicionais: consulte NodeGroup.
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
Corpo JSON do pedido:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
Obtenha metadados do cluster do grupo de nós do controlador
Pode usar o comando
gcloud dataproc node-groups describe
ou a API Dataproc para
obter metadados do grupo de nós do controlador.
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
Flags obrigatórias:
- NODE_GROUP_ID: pode executar
gcloud dataproc clusters describe CLUSTER_NAMEpara listar o ID do grupo de nós. - CLUSTER_NAME: o nome do cluster.
- REGION: a região do cluster.
REST
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT_ID: obrigatório. ID do projeto do Google Cloud.
- REGION: obrigatório. A região do cluster.
- CLUSTER_NAME: obrigatório. O nome do cluster.
- NODE_GROUP_ID: obrigatório. Pode executar
gcloud dataproc clusters describe CLUSTER_NAMEpara listar o ID do grupo de nós.
Método HTTP e URL:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
Redimensione um grupo de nós de controlador
Pode usar o comando
gcloud dataproc node-groups resize
ou a API Dataproc
para adicionar ou remover nós de controlador de um grupo de nós de controlador de cluster.
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
Flags obrigatórias:
- NODE_GROUP_ID: pode executar
gcloud dataproc clusters describe CLUSTER_NAMEpara listar o ID do grupo de nós. - CLUSTER_NAME: o nome do cluster.
- REGION: a região do cluster.
- SIZE: especifique o novo número de nós de controlador no grupo de nós.
Flag opcional:
--graceful-decommission-timeout=TIMEOUT_DURATION: Quando reduz a escala de um grupo de nós, pode adicionar esta flag para especificar uma desativação gradual TIMEOUT_DURATION para evitar o encerramento imediato dos controladores de tarefas. Recomendação: defina uma duração do limite de tempo que seja, pelo menos, igual à duração da tarefa mais longa em execução no grupo de nós (a recuperação de controladores com falhas não é suportada).
Exemplo: comando NodeGroupscale up da CLI gcloud:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
Exemplo: comando NodeGroupscale down da CLI gcloud:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT_ID: obrigatório. ID do projeto do Google Cloud.
- REGION: obrigatório. A região do cluster.
- NODE_GROUP_ID: obrigatório. Pode executar
gcloud dataproc clusters describe CLUSTER_NAMEpara listar o ID do grupo de nós. - SIZE: obrigatório. Novo número de nós no grupo de nós.
- TIMEOUT_DURATION: opcional. Quando reduz a escala de um grupo de nós,
pode adicionar um
gracefulDecommissionTimeoutao corpo do pedido para evitar o encerramento imediato dos controladores de tarefas. Recomendação: defina uma duração do limite de tempo que seja, pelo menos, igual à duração da tarefa mais longa em execução no grupo de nós (a recuperação de controladores com falhas não é suportada).Exemplo:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
Corpo JSON do pedido:
{
"size": SIZE,
}
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
Elimine um cluster de grupo de nós de controlador
Quando elimina um cluster do Dataproc, os grupos de nós associados ao cluster são eliminados.
Envie um trabalho
Pode usar o comando gcloud dataproc jobs submit ou a API Dataproc para enviar uma tarefa para um cluster com um grupo de nós de controlador.
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
Flags obrigatórias:
- JOB_COMMAND: especifique o comando de tarefa.
- CLUSTER_NAME: o nome do cluster.
- DRIVER_MEMORY: quantidade de memória dos controladores de tarefas em MB necessária para executar uma tarefa (consulte os controlos de memória do Yarn).
- DRIVER_VCORES: o número de vCPUs necessárias para executar uma tarefa.
Flags adicionais:
- DATAPROC_FLAGS: adicione quaisquer flags gcloud dataproc jobs submit adicionais relacionadas com o tipo de tarefa.
- JOB_ARGS: adicione quaisquer argumentos (após o
--) para transmitir para a tarefa.
Exemplos: pode executar os exemplos seguintes a partir de uma sessão de terminal SSH num cluster de grupo de nós do controlador do Dataproc.
Tarefa do Spark para estimar o valor de
pi:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Tarefa de contagem de palavras do Spark:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
Tarefa do PySpark para estimar o valor de
pi:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Tarefa MapReduce TeraGen do Hadoop:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
Antes de usar qualquer um dos dados do pedido, faça as seguintes substituições:
- PROJECT_ID: obrigatório. ID do projeto do Google Cloud.
- REGION: obrigatório. Região do cluster do Dataproc
- CLUSTER_NAME: obrigatório. O nome do cluster, que tem de ser exclusivo num projeto. O nome tem de começar por uma letra minúscula e pode conter até 51 letras minúsculas, números e hífenes. Não pode terminar com um hífen. O nome de um cluster eliminado pode ser reutilizado.
- DRIVER_MEMORY: obrigatório. Quantidade de memória dos controladores de tarefas em MB necessária para executar uma tarefa (consulte os controlos de memória do Yarn).
- DRIVER_VCORES: obrigatório. O número de vCPUs necessárias para executar uma tarefa.
pi).
Método HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corpo JSON do pedido:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
Para enviar o seu pedido, expanda uma destas opções:
Deve receber uma resposta JSON semelhante à seguinte:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- Instale a biblioteca cliente
- Configure as credenciais padrão da aplicação
- Execute o código
- Tarefa do Spark para estimar o valor de pi:
- Tarefa do PySpark para imprimir "hello world":
Veja registos de tarefas
Para ver o estado da tarefa e ajudar a depurar problemas da tarefa, pode ver os registos do controlador através da CLI gcloud ou da Google Cloud consola.
gcloud
Os registos do controlador de tarefas são transmitidos para o resultado da CLI gcloud ou para a consola durante a execução da tarefa.Google Cloud Os registos do controlador persistem no contentor de preparação do cluster do Dataproc no Cloud Storage.
Execute o seguinte comando da CLI gcloud para listar a localização dos registos do controlador no Cloud Storage:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
A localização do armazenamento na nuvem dos registos do condutor é apresentada como o
driverOutputResourceUri na saída do comando no seguinte formato:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
Consola
Para ver os registos de clusters de grupos de nós:
Pode usar o seguinte formato de consulta do Explorador de registos para encontrar registos:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud ID do projeto.
- CLUSTER_NAME: o nome do cluster.
- LOG_TYPE:
- Registos do utilizador do Yarn:
yarn-userlogs - Registos do gestor de recursos do Yarn:
hadoop-yarn-resourcemanager - Registos do gestor de nós do Yarn:
hadoop-yarn-nodemanager
- Registos do utilizador do Yarn:
Monitorize métricas
Os controladores de tarefas do grupo de nós do Dataproc são executados numa fila secundária dataproc-driverpool-driver-queue numa partição dataproc-driverpool.
Métricas do grupo de nós do controlador
A tabela seguinte apresenta as métricas do controlador do grupo de nós associadas, que são recolhidas por predefinição para grupos de nós de controladores.
| Métrica do grupo de nós do controlador | Descrição |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
A quantidade de memória disponível em mebibytes em
dataproc-driverpool-driver-queue na partição
dataproc-driverpool.
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
O número de contentores pendentes (em fila) em dataproc-driverpool-driver-queue na partição dataproc-driverpool. |
Métricas da fila de crianças
A tabela seguinte lista as métricas da fila secundária. As métricas são recolhidas por predefinição para grupos de nós de controladores e podem ser ativadas para recolha em quaisquer clusters do Dataproc.
| Métrica de fila secundária | Descrição |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
A quantidade de memória disponível em mebibytes nesta fila na partição predefinida. |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
Número de contentores pendentes (em fila) nesta fila na partição predefinida. |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
O número de trabalhos com um tempo de execução entre 0 e 60 minutos
nesta fila em todas as partições. |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
O número de trabalhos com um tempo de execução entre 60 e 300 minutos
nesta fila em todas as partições. |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
O número de trabalhos com um tempo de execução entre 300 e 1440 minutos
nesta fila em todas as partições. |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
O número de trabalhos com um tempo de execução superior a 1440 minutos
nesta fila em todas as partições. |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
O número de candidaturas enviadas para esta fila em todas as partições. |
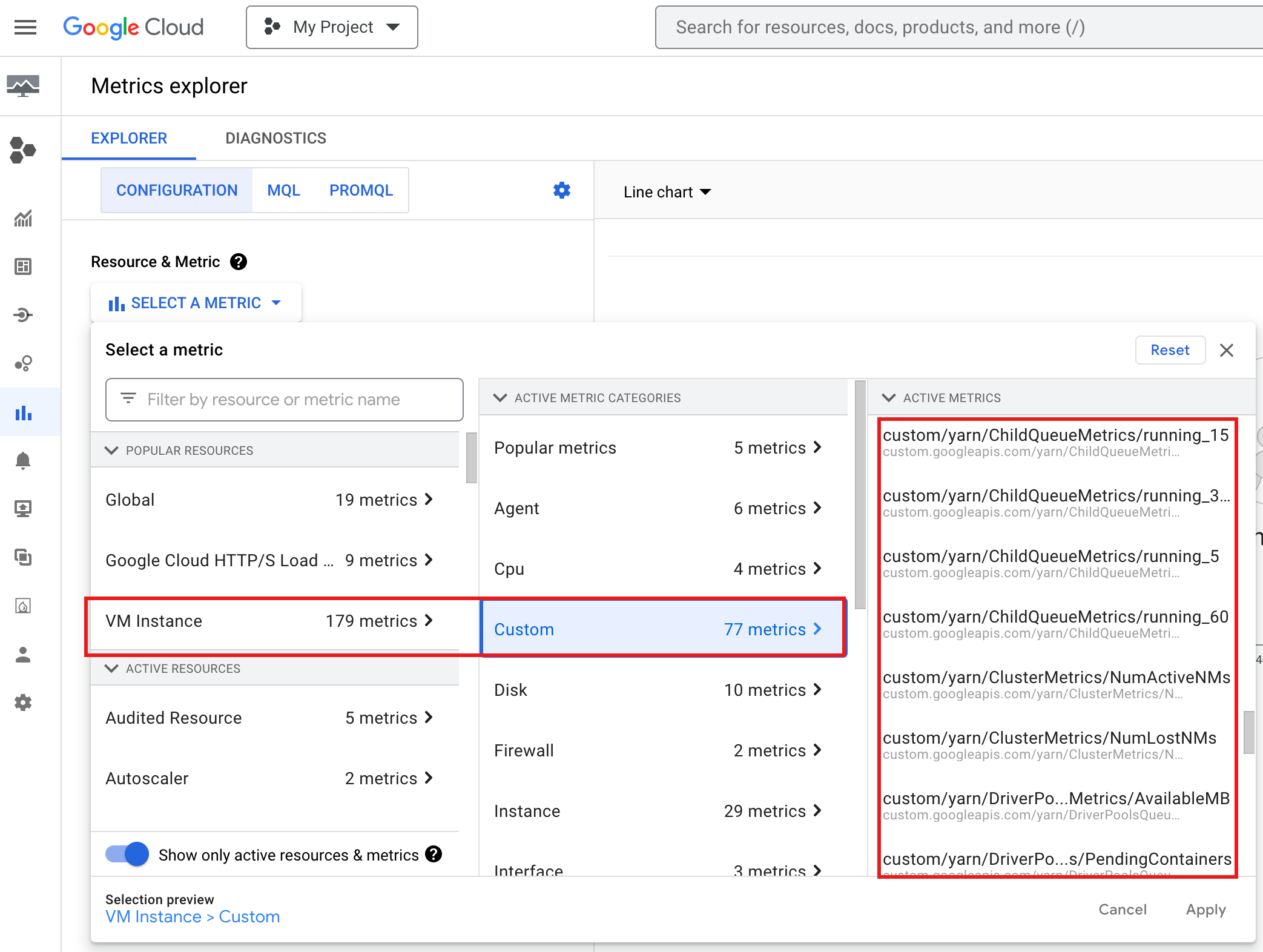
Para ver YARN ChildQueueMetrics e DriverPoolsQueueMetrics na
Google Cloud consola:
Selecione Instância de VM → Recursos personalizados no Explorador de métricas.
Depure o controlador de tarefas do grupo de nós
Esta secção apresenta as condições e os erros do grupo de nós do controlador com recomendações para corrigir a condição ou o erro.
Condições
Condição:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBestá a aproximar-se de0. Isto indica que as filas de pools de controladores de clusters estão a ficar sem memória.Recomendação:: aumente o tamanho do conjunto de motoristas.
Condição:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainersé superior a 0. Isto pode indicar que as filas de controladores do cluster estão a ficar sem memória e que o YARN está a colocar trabalhos em fila.Recomendação:: aumente o tamanho do conjunto de motoristas.
Erros
Erro:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.Recomendação: defina
driver-required-memory-mbedriver-required-vcorescom números positivos.Erro:
Container exited with a non-zero exit code 137.Recomendação: aumente
driver-required-memory-mbpara a utilização de memória da tarefa.