Resource NodeGroup Dataproc adalah grup node cluster Dataproc yang menjalankan peran yang ditetapkan. Halaman ini menjelaskan grup node driver, yaitu grup VM Compute Engine yang diberi peran Driver untuk tujuan menjalankan driver tugas di cluster Dataproc.
Kapan harus menggunakan grup node driver
- Gunakan grup node driver hanya jika Anda perlu menjalankan banyak tugas serentak di cluster bersama.
- Tingkatkan resource node master sebelum menggunakan grup node driver untuk menghindari batasan grup node driver.
Cara node driver membantu Anda menjalankan tugas serentak
Dataproc memulai proses driver tugas di node master cluster Dataproc untuk setiap tugas. Proses driver, pada gilirannya,
menjalankan driver aplikasi, seperti spark-submit, sebagai proses turunannya.
Namun, jumlah tugas serentak yang berjalan di master dibatasi oleh
resource yang tersedia di node master, dan karena node master Dataproc tidak dapat diskalakan, tugas dapat gagal atau di-throttle jika resource node master tidak cukup untuk menjalankan tugas.
Grup node driver adalah grup node khusus yang dikelola oleh YARN, sehingga konkurensi tugas tidak dibatasi oleh resource node master. Di cluster dengan grup node driver, driver aplikasi berjalan di node driver. Setiap node driver dapat menjalankan beberapa driver aplikasi jika node memiliki resource yang cukup.
Manfaat
Dengan menggunakan cluster Dataproc dengan grup node driver, Anda dapat:
- Menskalakan resource driver tugas secara horizontal untuk menjalankan lebih banyak tugas serentak
- Menskalakan resource driver secara terpisah dari resource pekerja
- Mendapatkan penurunan skala yang lebih cepat pada cluster image Dataproc 2.0+ dan yang lebih baru. Di cluster ini, master aplikasi berjalan dalam driver Spark di
grup node driver (
spark.yarn.unmanagedAM.enableddisetel ketruesecara default). - Menyesuaikan peluncuran node driver. Anda dapat menambahkan
{ROLE} == 'Driver'dalam skrip inisialisasi agar skrip melakukan tindakan untuk grup node driver dalam pemilihan node.
Batasan
- Grup node tidak didukung di template alur kerja Dataproc.
- Cluster grup node tidak dapat dihentikan, dimulai ulang, atau diskalakan otomatis.
- Master aplikasi MapReduce berjalan di node pekerja. Penurunan skala node pekerja dapat berjalan lambat jika Anda mengaktifkan penonaktifan yang lancar.
- Serentak tugas dipengaruhi oleh
dataproc:agent.process.threads.job.maxproperti cluster. Misalnya, dengan tiga master dan properti ini disetel ke nilai default100, konkurensi tugas tingkat cluster maksimum adalah300.
Grup node driver dibandingkan dengan mode cluster Spark
| Fitur | Mode cluster Spark | Grup node driver |
|---|---|---|
| Penurunan skala node pekerja | Driver yang berjalan lama berjalan di worker node yang sama dengan container yang berjalan singkat, sehingga penurunan skala pekerja menggunakan penonaktifan yang lancar menjadi lambat. | Node pekerja diturunkan skalanya lebih cepat saat driver berjalan di grup node. |
| Output driver yang di-streaming | Memerlukan penelusuran di log YARN untuk menemukan node tempat driver dijadwalkan. | Output driver di-streaming ke Cloud Storage, dan dapat dilihat
di konsol Google Cloud dan di output perintah gcloud dataproc jobs wait
setelah tugas selesai. |
Izin IAM grup node driver
Izin IAM berikut dikaitkan dengan tindakan terkait grup node Dataproc.
| Izin | Tindakan |
|---|---|
dataproc.nodeGroups.create
|
Buat grup node Dataproc. Jika pengguna memiliki
dataproc.clusters.create dalam project, izin ini
diberikan. |
dataproc.nodeGroups.get |
Mendapatkan detail grup node Dataproc. |
dataproc.nodeGroups.update |
Mengubah ukuran grup node Dataproc. |
Operasi grup node driver
Anda dapat menggunakan gcloud CLI dan Dataproc API untuk membuat, mendapatkan, mengubah ukuran, menghapus, dan mengirimkan tugas ke grup node driver Dataproc.
Membuat cluster grup node driver
Grup node driver dikaitkan dengan satu cluster Dataproc. Anda membuat grup node sebagai bagian dari membuat cluster Dataproc. Anda dapat menggunakan gcloud CLI atau Dataproc REST API untuk membuat cluster Dataproc dengan grup node driver.
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
Bendera yang diperlukan:
- CLUSTER_NAME: Nama cluster, yang harus unik dalam project. Nama harus diawali dengan huruf kecil, dan dapat berisi hingga 51 huruf kecil, angka, dan tanda hubung. Tidak boleh diakhiri dengan tanda hubung. Nama cluster yang dihapus dapat digunakan kembali.
- REGION: Region tempat cluster akan berada.
- SIZE: Jumlah node driver dalam grup node. Jumlah node yang diperlukan bergantung pada beban tugas dan jenis mesin kumpulan driver. Jumlah node grup driver minimum sama dengan total memori atau vCPU yang diperlukan oleh driver tugas dibagi dengan memori atau vCPU mesin setiap kumpulan driver.
- NODE_GROUP_ID: Opsional dan direkomendasikan. ID harus unik dalam cluster. Gunakan ID ini untuk mengidentifikasi grup driver dalam operasi mendatang, seperti mengubah ukuran grup node. Jika tidak ditentukan, Dataproc akan membuat ID grup node.
Flag yang direkomendasikan:
--enable-component-gateway: Tambahkan tanda ini untuk mengaktifkan Gateway Komponen Dataproc, yang menyediakan akses ke antarmuka web YARN. Halaman Aplikasi dan Penjadwal UI YARN menampilkan status cluster dan tugas, memori antrean aplikasi, kapasitas inti, dan metrik lainnya.
Flag tambahan: Flag driver-pool opsional berikut dapat ditambahkan
ke perintah gcloud dataproc clusters create untuk menyesuaikan grup node.
| Flag | Nilai default |
|---|---|
--driver-pool-id |
ID string, yang dibuat oleh layanan jika tidak ditetapkan oleh flag. ID ini dapat digunakan untuk mengidentifikasi grup node saat melakukan operasi node pool di masa mendatang, seperti mengubah ukuran grup node. |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
Tidak ada default. Saat menentukan akselerator, jenis GPU diperlukan; jumlah GPU bersifat opsional. |
--num-driver-pool-local-ssds |
Tidak ada default |
--driver-pool-local-ssd-interface |
Tidak ada default |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
Lengkapi
AuxiliaryNodeGroup
sebagai bagian dari permintaan
cluster.create
Dataproc API.
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_ID: Wajib diisi. ID project Google Cloud.
- REGION: Wajib diisi. Region cluster Dataproc.
- CLUSTER_NAME: Wajib diisi. Nama cluster, yang harus unik dalam project. Nama harus diawali dengan huruf kecil, dan dapat berisi hingga 51 huruf kecil, angka, dan tanda hubung. Tidak boleh diakhiri dengan tanda hubung. Nama cluster yang dihapus dapat digunakan kembali.
- SIZE: Wajib diisi. Jumlah node dalam grup node.
- NODE_GROUP_ID: Opsional dan direkomendasikan. ID harus unik dalam cluster. Gunakan ID ini untuk mengidentifikasi grup driver dalam operasi mendatang, seperti mengubah ukuran grup node. Jika tidak ditentukan, Dataproc akan membuat ID grup node.
Opsi tambahan: Lihat NodeGroup.
Metode HTTP dan URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
Meminta isi JSON:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
Mendapatkan metadata cluster grup node driver
Anda dapat menggunakan perintah
gcloud dataproc node-groups describe
atau Dataproc API untuk
mendapatkan metadata grup node driver.
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
Bendera yang diperlukan:
- NODE_GROUP_ID: Anda dapat menjalankan
gcloud dataproc clusters describe CLUSTER_NAMEuntuk mencantumkan ID grup node. - CLUSTER_NAME: Nama cluster.
- REGION: Region cluster.
REST
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_ID: Wajib diisi. ID project Google Cloud.
- REGION: Wajib diisi. Region cluster.
- CLUSTER_NAME: Wajib diisi. Nama cluster.
- NODE_GROUP_ID: Wajib diisi. Anda dapat menjalankan
gcloud dataproc clusters describe CLUSTER_NAMEuntuk mencantumkan ID grup node.
Metode HTTP dan URL:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
Untuk mengirim permintaan, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
Mengubah ukuran grup node driver
Anda dapat menggunakan perintah
gcloud dataproc node-groups resize
atau Dataproc API
untuk menambahkan atau menghapus node driver dari grup node driver cluster.
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
Bendera yang diperlukan:
- NODE_GROUP_ID: Anda dapat menjalankan
gcloud dataproc clusters describe CLUSTER_NAMEuntuk mencantumkan ID grup node. - CLUSTER_NAME: Nama cluster.
- REGION: Region cluster.
- SIZE: Tentukan jumlah baru node driver dalam grup node.
Flag opsional:
--graceful-decommission-timeout=TIMEOUT_DURATION: Saat menurunkan skala grup node, Anda dapat menambahkan tanda ini untuk menentukan penonaktifan yang benar TIMEOUT_DURATION untuk menghindari penghentian driver tugas secara langsung. Rekomendasi: Tetapkan durasi waktu tunggu yang setidaknya sama dengan durasi tugas terlama yang berjalan di grup node (pemulihan driver yang gagal tidak didukung).
Contoh: Perintah penskalaan gcloud CLI NodeGroup:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
Contoh: Perintah penurunan skala NodeGroup gcloud CLI:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_ID: Wajib diisi. ID project Google Cloud.
- REGION: Wajib diisi. Region cluster.
- NODE_GROUP_ID: Wajib diisi. Anda dapat menjalankan
gcloud dataproc clusters describe CLUSTER_NAMEuntuk mencantumkan ID grup node. - SIZE: Wajib diisi. Jumlah node baru dalam grup node.
- TIMEOUT_DURATION: Opsional. Saat menskalakan grup node,
Anda dapat menambahkan
gracefulDecommissionTimeoutke isi permintaan untuk menghindari penghentian langsung driver tugas. Rekomendasi: Tetapkan durasi waktu tunggu yang setidaknya sama dengan durasi tugas terlama yang berjalan di grup node (pemulihan driver yang gagal tidak didukung).Contoh:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
Metode HTTP dan URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
Meminta isi JSON:
{
"size": SIZE,
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
Menghapus cluster grup node driver
Saat Anda menghapus cluster Dataproc, grup node yang terkait dengan cluster tersebut akan dihapus.
Mengirim tugas
Anda dapat menggunakan perintah gcloud dataproc jobs submit
atau Dataproc API untuk
mengirimkan tugas ke cluster
dengan grup node driver.
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
Bendera yang diperlukan:
- JOB_COMMAND: Tentukan perintah tugas.
- CLUSTER_NAME: Nama cluster.
- DRIVER_MEMORY: Jumlah memori driver tugas dalam MB yang diperlukan untuk menjalankan tugas (lihat Kontrol Memori Yarn).
- DRIVER_VCORES: Jumlah vCPU yang diperlukan untuk menjalankan tugas.
Tanda tambahan:
- DATAPROC_FLAGS: Tambahkan flag gcloud dataproc jobs submit tambahan yang terkait dengan jenis tugas.
- JOB_ARGS: Tambahkan argumen apa pun (setelah
--) untuk diteruskan ke tugas.
Contoh: Anda dapat menjalankan contoh berikut dari sesi terminal SSH di cluster grup node driver Dataproc.
Tugas Spark untuk memperkirakan nilai
pi:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Tugas wordcount Spark:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
Tugas PySpark untuk memperkirakan nilai
pi:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Tugas MapReduce TeraGen Hadoop:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
Sebelum menggunakan salah satu data permintaan, lakukan penggantian berikut:
- PROJECT_ID: Wajib diisi. ID project Google Cloud.
- REGION: Wajib diisi. Region cluster Dataproc
- CLUSTER_NAME: Wajib diisi. Nama cluster, yang harus unik dalam project. Nama harus diawali dengan huruf kecil, dan dapat berisi hingga 51 huruf kecil, angka, dan tanda hubung. Tidak boleh diakhiri dengan tanda hubung. Nama cluster yang dihapus dapat digunakan kembali.
- DRIVER_MEMORY: Wajib diisi. Jumlah memori driver tugas dalam MB yang diperlukan untuk menjalankan tugas (lihat Kontrol Memori Yarn).
- DRIVER_VCORES: Wajib diisi. Jumlah vCPU yang diperlukan untuk menjalankan tugas.
pi).
Metode HTTP dan URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Meminta isi JSON:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
Untuk mengirim permintaan Anda, perluas salah satu opsi berikut:
Anda akan melihat respons JSON seperti berikut:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- Instal library klien
- Menyiapkan kredensial default aplikasi
- Jalankan kode
- Tugas Spark untuk memperkirakan nilai pi:
- Tugas PySpark untuk mencetak 'hello world':
Lihat log tugas
Untuk melihat status tugas dan membantu men-debug masalah tugas, Anda dapat melihat log driver menggunakan gcloud CLI atau konsol Google Cloud .
gcloud
Log driver tugas di-streaming ke output gcloud CLI atau konsolGoogle Cloud selama eksekusi tugas. Log driver tetap ada di bucket penampung staging bucket di Cloud Storage.
Jalankan perintah gcloud CLI berikut untuk mencantumkan lokasi log driver di Cloud Storage:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
Lokasi Cloud Storage untuk log driver dicantumkan sebagai
driverOutputResourceUri dalam output perintah dengan format berikut:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
Konsol
Untuk melihat log cluster grup node:
Anda dapat menggunakan format kueri Logs Explorer berikut untuk menemukan log:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud project ID.
- CLUSTER_NAME: Nama cluster.
- LOG_TYPE:
- Log pengguna Yarn:
yarn-userlogs - Log pengelola resource Yarn:
hadoop-yarn-resourcemanager - Log pengelola node Yarn:
hadoop-yarn-nodemanager
- Log pengguna Yarn:
Memantau metrik
Driver tugas grup node Dataproc berjalan di
dataproc-driverpool-driver-queue antrean turunan di bawah partisi dataproc-driverpool.
Metrik grup node driver
Tabel berikut mencantumkan metrik driver grup node terkait, yang dikumpulkan secara default untuk grup node driver.
| Metrik grup node driver | Deskripsi |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
Jumlah memori yang tersedia dalam Mebibyte di
dataproc-driverpool-driver-queue di bawah partisi
dataproc-driverpool.
|
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
Jumlah container yang tertunda (dalam antrean) di
dataproc-driverpool-driver-queue dalam
partisi dataproc-driverpool. |
Metrik antrean turunan
Tabel berikut mencantumkan metrik antrean turunan. Metrik dikumpulkan secara default untuk grup node driver, dan dapat diaktifkan untuk pengumpulan di cluster Dataproc mana pun.
| Metrik antrean turunan | Deskripsi |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
Jumlah memori yang tersedia dalam Mebibyte di antrean ini di bawah partisi default. |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
Jumlah kontainer yang menunggu (dalam antrean) di antrean ini dalam partisi default. |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
Jumlah tugas dengan runtime antara 0 dan 60 menit
dalam antrean ini di semua partisi. |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
Jumlah tugas dengan runtime antara 60 dan 300 menit
dalam antrean ini di semua partisi. |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
Jumlah tugas dengan runtime antara 300 dan 1440 menit
dalam antrean ini di semua partisi. |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
Jumlah tugas dengan runtime lebih dari 1440 menit
dalam antrean ini di semua partisi. |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
Jumlah aplikasi yang dikirimkan ke antrean ini di semua partisi. |
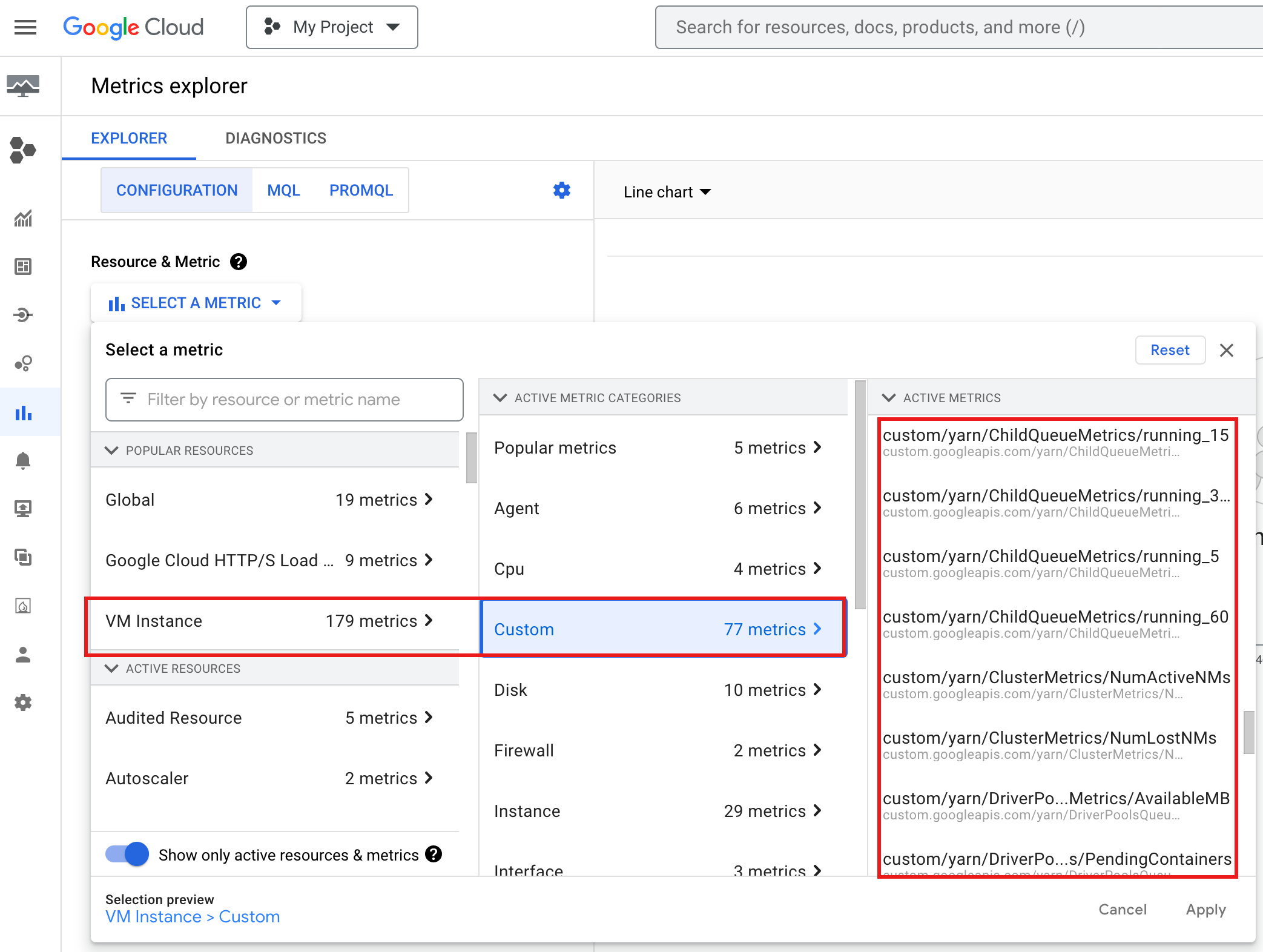
Untuk melihat YARN ChildQueueMetrics dan DriverPoolsQueueMetrics di
Google Cloud console:
Pilih resource VM Instance → Custom di Metrics Explorer.
Melakukan debug driver tugas grup node
Bagian ini memberikan kondisi dan error grup node driver dengan rekomendasi untuk memperbaiki kondisi atau error tersebut.
Kondisi
Kondisi:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMBakan segera0. Hal ini menunjukkan bahwa antrean kumpulan driver cluster kehabisan memori.Rekomendasi:: Tingkatkan ukuran kumpulan pengemudi.
Kondisi:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainerslebih besar dari 0. Hal ini dapat menunjukkan bahwa antrean kumpulan driver cluster kehabisan memori dan YARN mengantrekan tugas.Rekomendasi:: Tingkatkan ukuran kumpulan pengemudi.
Error
Error:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.Rekomendasi: Tetapkan
driver-required-memory-mbdandriver-required-vcoresdengan bilangan positif.Error:
Container exited with a non-zero exit code 137.Rekomendasi: Tingkatkan
driver-required-memory-mbke penggunaan memori tugas.