Log tugas dan cluster Dataproc dapat dilihat, ditelusuri, difilter, dan diarsipkan di Cloud Logging.
Lihat harga Google Cloud Observability untuk memahami biaya Anda.
Lihat Periode retensi log untuk mengetahui informasi tentang retensi logging.
Lihat Pengecualian log untuk menonaktifkan semua log atau mengecualikan log dari Logging.
Lihat Ringkasan perutean dan penyimpanan untuk merutekan log dari Logging ke Cloud Storage, BigQuery, atau Pub/Sub.
Tingkat logging komponen
Tetapkan tingkat logging Spark, Hadoop, Flink, dan komponen Dataproc lainnya dengan properti cluster log4j khusus komponen, seperti hadoop-log4j, saat Anda membuat cluster. Tingkat logging komponen berbasis cluster berlaku untuk daemon layanan, seperti YARN ResourceManager, dan untuk tugas yang berjalan di cluster.
Jika properti log4j tidak didukung untuk komponen, seperti komponen Presto,
tulis tindakan inisialisasi
yang mengedit file log4j.properties atau log4j2.properties komponen.
Tingkat logging komponen khusus tugas: Anda juga dapat menyetel tingkat logging komponen saat mengirimkan tugas. Tingkat logging ini diterapkan ke tugas, dan lebih diprioritaskan daripada tingkat logging yang ditetapkan saat Anda membuat cluster. Lihat Properti cluster vs. tugas untuk mengetahui informasi selengkapnya.
Tingkat logging versi komponen Spark dan Hive:
Komponen Spark 3.3.X dan Hive 3.X menggunakan properti log4j2, sedangkan komponen versi sebelumnya menggunakan properti log4j (lihat Apache Log4j2).
Gunakan awalan spark-log4j: untuk menetapkan level logging Spark pada cluster.
Contoh: Versi image Dataproc 2.0 dengan Spark 3.1 untuk menetapkan
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
Contoh: Versi image Dataproc 2.1 dengan Spark 3.3 untuk menetapkan
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
Tingkat logging driver tugas
Dataproc menggunakan
level logging
default INFO untuk program driver tugas. Anda dapat mengubah setelan ini untuk satu atau beberapa paket dengan tanda gcloud dataproc jobs submit
--driver-log-levels.
Contoh:
Tetapkan tingkat logging DEBUG saat mengirimkan tugas Spark yang membaca file Cloud Storage.
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
Contoh:
Tetapkan level logger root ke WARN, level logger com.example ke INFO.
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Tingkat logging eksekutor Spark
Untuk mengonfigurasi tingkat logging eksekutor Spark:
Siapkan file konfigurasi log4j, lalu upload ke Cloud Storage
.Referensi file konfigurasi Anda saat Anda mengirimkan tugas.
Contoh:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark mendownload file properti Cloud Storage ke direktori kerja lokal tugas, yang dirujuk sebagai file:<name> dalam -Dlog4j.configuration.
Log tugas Dataproc di Logging
Lihat Output dan log tugas Dataproc untuk mengetahui informasi tentang cara mengaktifkan log driver tugas Dataproc di Logging.
Mengakses log tugas di Logging
Akses log tugas Dataproc menggunakan Logs Explorer, perintah gcloud logging, atau Logging API.
Konsol
Log driver tugas Dataproc dan container YARN dicantumkan di bagian resource Cloud Dataproc Job.
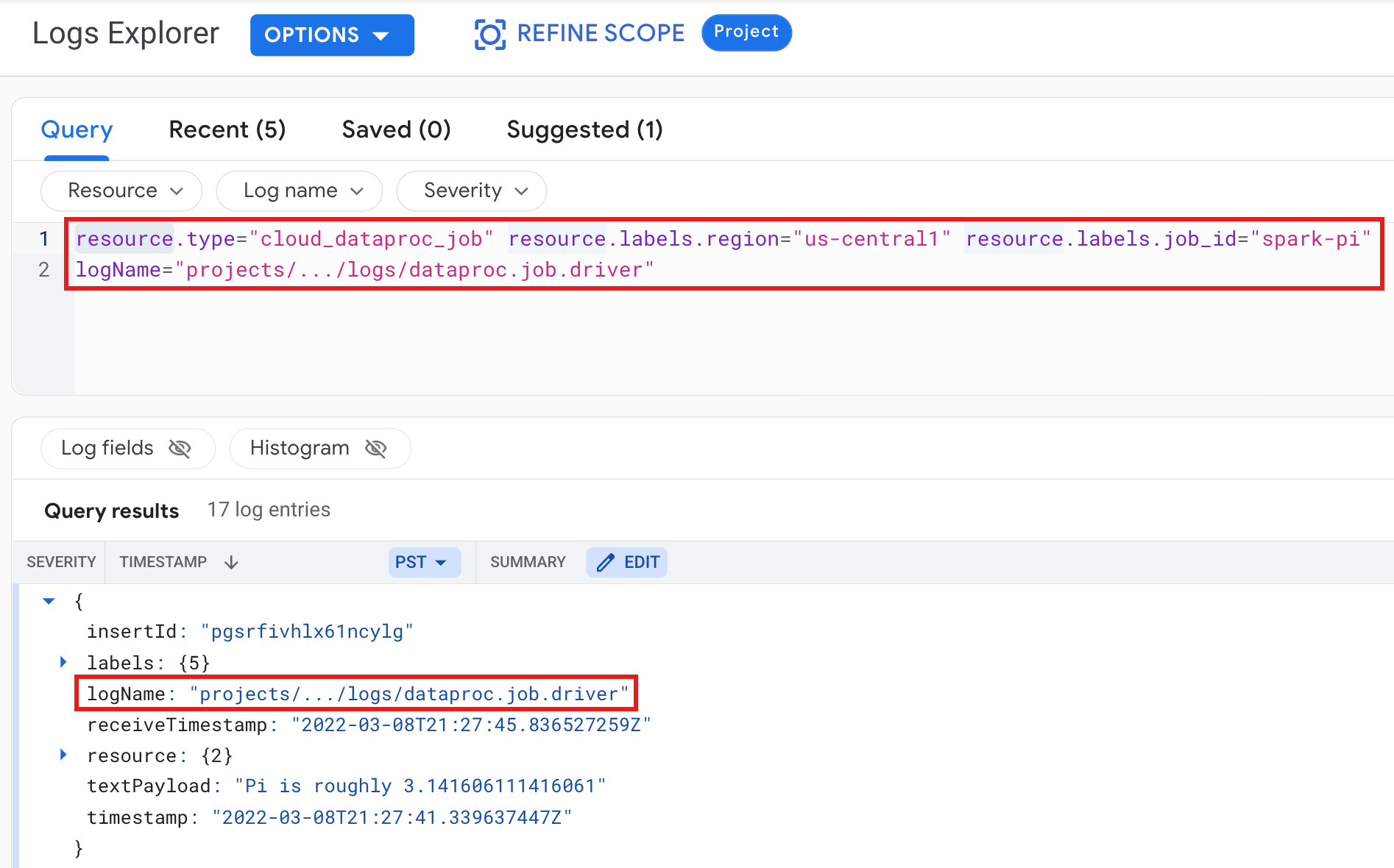
Contoh: Log driver tugas setelah menjalankan kueri Logs Explorer dengan pilihan berikut:
- Resource:
Cloud Dataproc Job - Nama log:
dataproc.job.driver
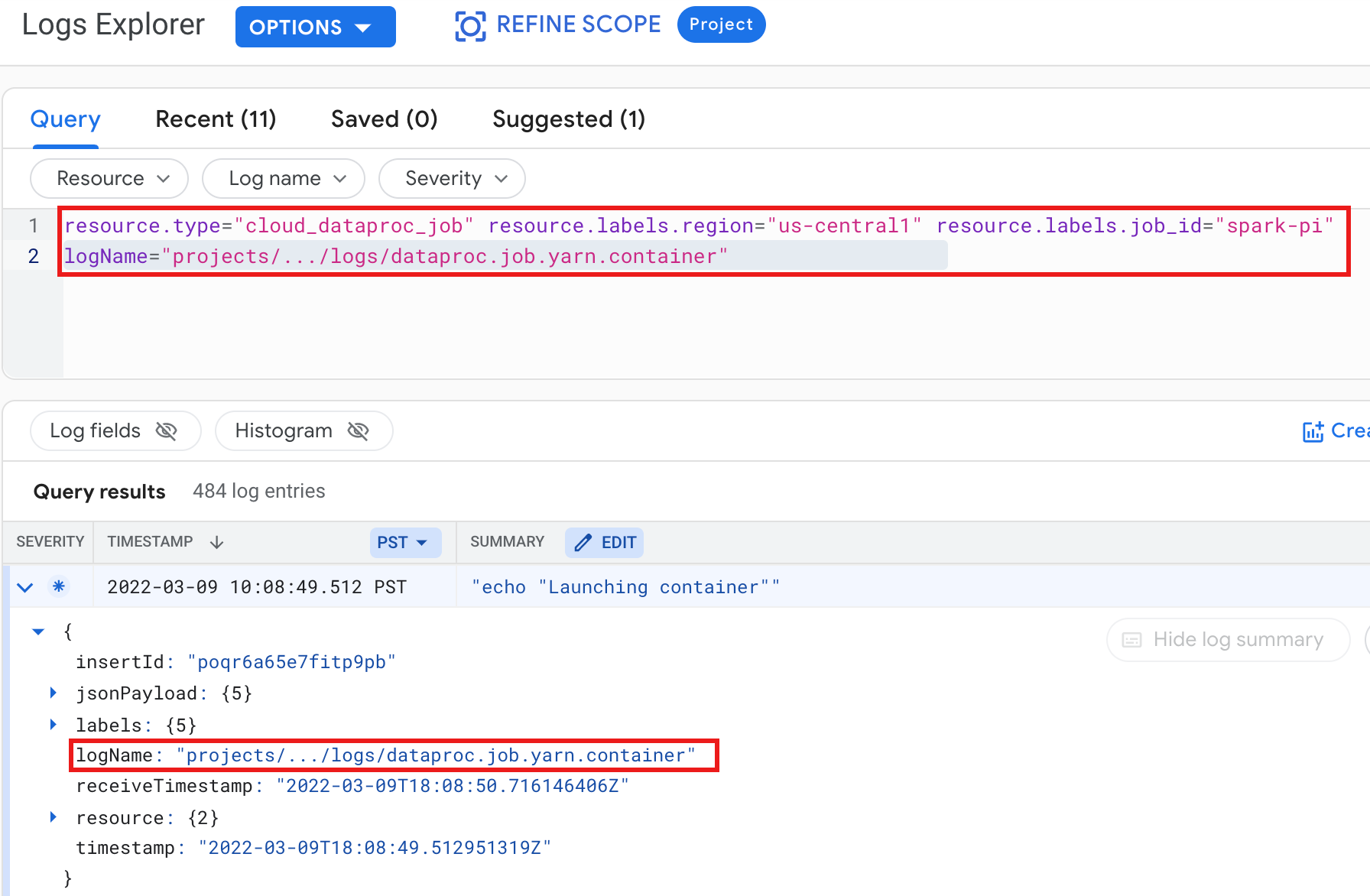
Contoh: Log penampung YARN setelah menjalankan kueri Logs Explorer dengan pilihan berikut:
- Resource:
Cloud Dataproc Job - Nama log:
dataproc.job.yarn.container
gcloud
Anda dapat membaca entri log tugas menggunakan perintah gcloud logging read. Argumen resource harus diapit tanda kutip ("..."). Perintah berikut menggunakan label cluster untuk memfilter entri log yang ditampilkan.
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
Contoh output (sebagian):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
REST API
Anda dapat menggunakan Logging REST API untuk mencantumkan entri log (lihat entries.list).
Log cluster Dataproc di Logging
Dataproc mengekspor log cluster Apache Hadoop, Spark, Hive, Zookeeper, dan cluster Dataproc lainnya berikut ke Cloud Logging.
| Jenis Log | Nama Log | Deskripsi | Catatan |
|---|---|---|---|
| Log daemon master | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
Node jurnal HDFS namenode HDFS secondary namenode Zookeeper failover controller YARN resource manager YARN timeline server Hive metastore Hive server2 Mapreduce job history server Zookeeper server |
|
| Log daemon pekerja |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS datanode YARN nodemanager |
|
| Log sistem |
autoscaler google.dataproc.agent google.dataproc.startup |
Log penskalaan otomatis Dataproc Log agen Dataproc Log skrip startup Dataproc + log tindakan inisialisasi |
|
| Log yang diperluas (tambahan) |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Semua log di dalam subdirektori /var/log/ yang cocok dengan:knox (mencakup gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
Menetapkan properti
dataproc:dataproc.logging.extended.enabled=false akan menonaktifkan pengumpulan log yang diperluas di cluster
|
| Syslog VM |
syslog |
Syslog dari node master dan worker cluster |
Menetapkan properti
dataproc:dataproc.logging.syslog.enabled=false akan menonaktifkan pengumpulan syslog VM di cluster
|
Mengakses log cluster di Cloud Logging
Anda dapat mengakses log cluster Dataproc menggunakan Logs Explorer, perintah gcloud logging, atau Logging API.
Konsol
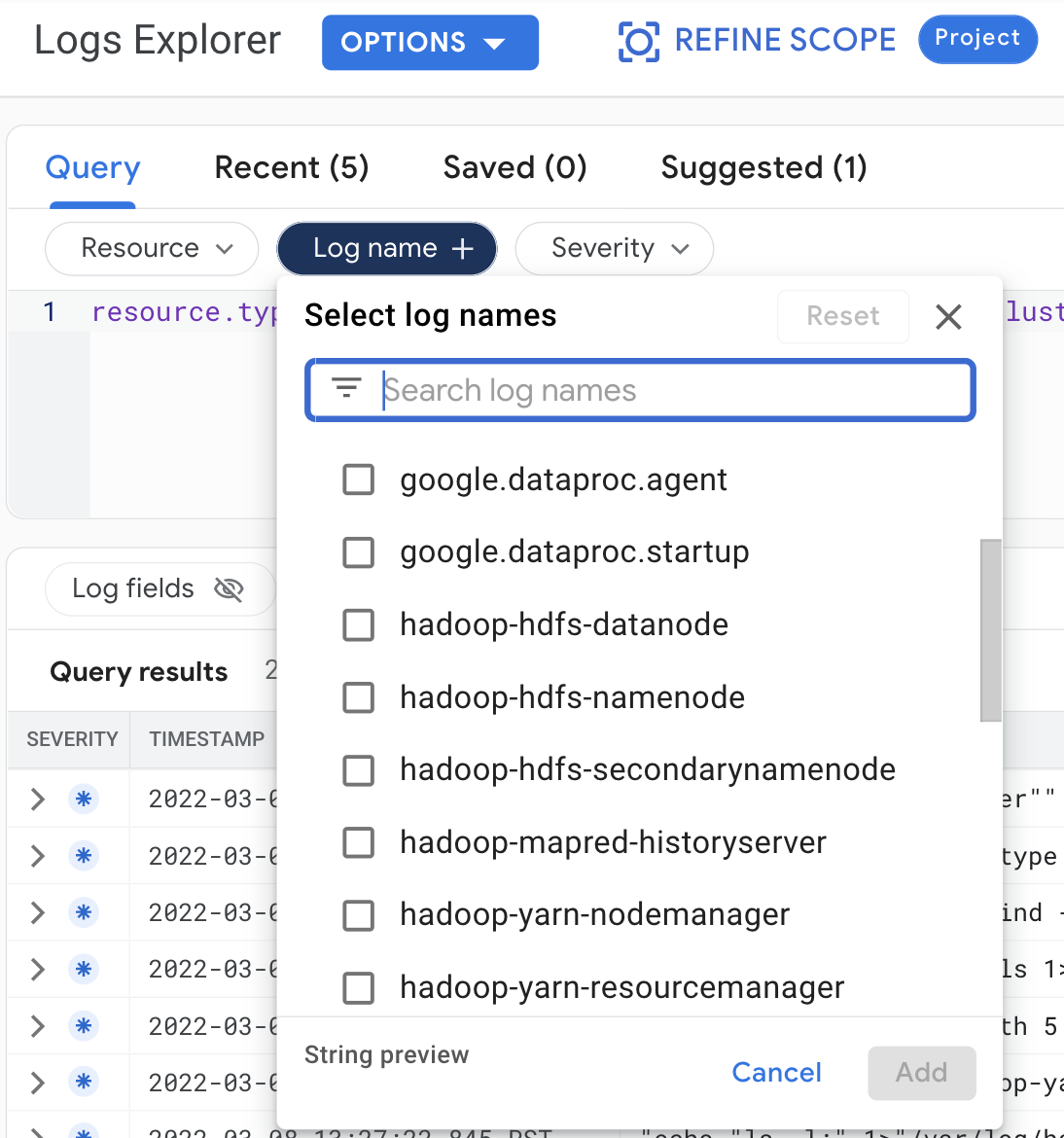
Buat pilihan kueri berikut untuk melihat log cluster di Logs Explorer:
- Resource:
Cloud Dataproc Cluster - Nama log: log name
gcloud
Anda dapat membaca entri log cluster menggunakan perintah gcloud logging read. Argumen resource harus diapit tanda kutip ("..."). Perintah berikut menggunakan label cluster untuk memfilter entri log yang ditampilkan.
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
Contoh output (sebagian):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
REST API
Anda dapat menggunakan Logging REST API untuk mencantumkan entri log (lihat entries.list).
Izin
Untuk menulis log ke Logging, akun layanan VM Dataproc harus memiliki peran IAM logging.logWriter. Akun layanan Dataproc default memiliki peran ini. Jika Anda menggunakan
akun layanan kustom,
Anda harus menetapkan peran ini ke akun layanan tersebut.
Melindungi log
Secara default, log di Logging dienkripsi dalam penyimpanan. Anda dapat mengaktifkan kunci enkripsi yang dikelola pelanggan (CMEK) untuk mengenkripsi log. Untuk mengetahui informasi selengkapnya tentang dukungan CMEK, lihat Mengelola kunci yang melindungi data Log Router dan Mengelola kunci yang melindungi data penyimpanan Logging.
Langkah berikutnya
- Pelajari Google Cloud Observability.