Cloud Monitoring 可帮助您了解云应用的性能、正常运行时间和整体运行状况。Google Cloud Observability 会从 Dataproc 集群收集并提取指标、事件和元数据(包括每个集群的 HDFS、YARN、作业和操作指标),以通过信息中心和图表生成数据分析(请参阅 Cloud Monitoring Dataproc 指标)。
如需了解费用,请参阅 Cloud Monitoring 价格。
如需了解指标数据保留,请参阅 Monitoring 配额和上限。
Dataproc 资源指标收集
Cloud Monitoring 会收集与下列 Dataproc 资源相关的指标:
- Cloud Dataproc 集群
- Cloud Dataproc 作业
- Cloud Dataproc 批量
- Cloud Dataproc 会话
Dataproc 资源指标采用以下格式进行收集:dataproc.googleapis.com/RESOURCE/METRIC,并包含多个 OSS 指标的集合。
查看 Dataproc 资源指标
在 Filter by resource or metric name 框中键入“dataproc”,然后选择“Cloud Dataproc”资源,即可在 Metrics Explorer 中选择并查看 Dataproc 资源指标。
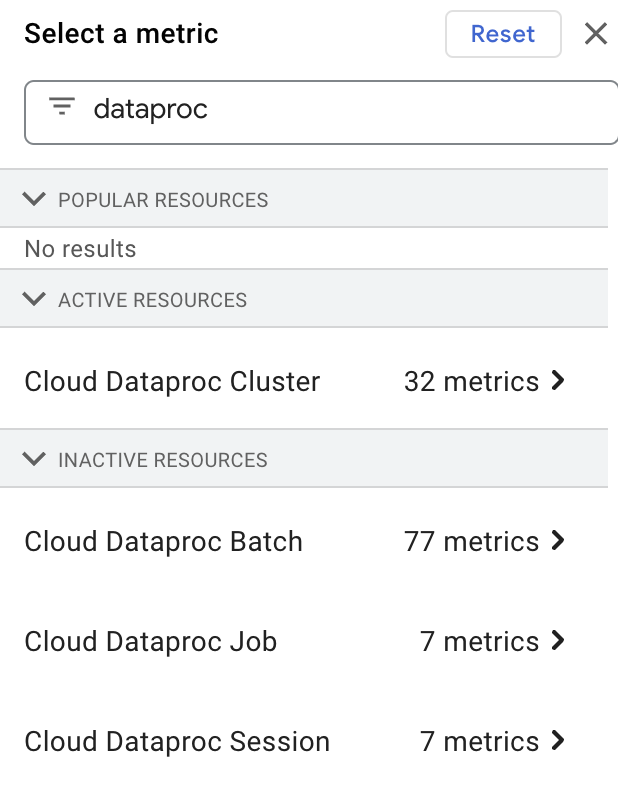
自定义指标收集
创建 Dataproc 集群时,可以启用从一个或多个自定义指标来源收集指标的功能。除非您指定要从指标来源收集的指标(用户指定的指标称为指标“替换项”),否则系统会从每个已启用的指标来源收集一组标准指标。
自定义 OSS 指标采用下列格式进行收集:custom.googleapis.com/OSS_COMPONENT/METRIC
自定义 OSS 指标示例:
custom.googleapis.com/spark/driver/DAGScheduler/job/allJobs custom.googleapis.com/hiveserver2/memory/MaxNonHeapMemory
启用自定义指标收集
您可以使用 gcloud CLI 或 Dataproc API,以便启用从一个或多个指标来源收集自定义指标的功能。
gcloud CLI
自定义指标收集
使用 gcloud dataproc clusters create --metric-sources 标志可启用从一个或多个指标来源收集自定义指标的功能。
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ ... other flags
注意:
--metric-sources:需要指定此项,才能启用自定义指标收集。指定以下一个或多个指标来源:spark、flink、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore和monitoring-agent-defaults。指标来源名称不区分大小写,例如,“yarn”或“YARN”均可接受。- monitoring-agent-defaults 在 2.2 映像版本集群中不可用。您可以安装 Ops Agent,它会收集 syslog 日志和主机指标。
替换指标收集
(可选)添加 --metric-overrides 或 --metric-overrides-file 标志,以便启用从一个或多个指标来源收集一个或多个自定义指标的功能。
-
任何自定义指标和所有 Spark 指标都可以作为指标替换项列出以供收集。替换指标值区分大小写,如果合适,必须以 CamelCase 格式提供。
示例:
sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committedhiveserver2:JVM:Memory:NonHeapMemoryUsage.usedyarn:ResourceManager:JvmMetrics:MemHeapMaxM
-
系统将仅从给定指标来源收集指定的被替换指标。例如,如果一个或多个
spark:executive指标被列为指标替换项,则系统不会收集其他SPARK指标。从其他指标来源收集自定义指标的操作不受影响。例如,如果SPARK和YARN指标来源都已启用,并且您仅为 Spark 指标提供了替换项,则系统将会收集该组已启用的标准 YARN 指标。 -
您必须启用指定的指标替换项的来源。例如,如果将一个或多个
spark:driver指标作为指标替换项提供,则必须启用spark指标来源 (--metric-sources=spark)。
替换指标列表
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC_SOURCE(s) \ --metric-overrides=LIST_OF_METRIC_OVERRIDES \ ... other flags
注意:
--metric-sources:需要指定此项,才能启用自定义指标收集。指定以下一个或多个指标来源:spark、flink、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore和monitoring-agent-defaults。指标来源名称不区分大小写,例如,“yarn”或“YARN”均可接受。--metric-overrides:提供指标列表,格式如下:METRIC_SOURCE:INSTANCE:GROUP:METRIC
示例:
--metric-overrides=sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committed此标志可替代
--metric-overrides-file标志,但两者不能搭配使用。
替换指标文件
gcloud dataproc clusters create cluster-name \ --metric-sources=METRIC-SOURCE(s) \ --metric-overrides-file=METRIC_OVERRIDES_FILENAME \ ... other flags
注意:
-
--metric-sources:需要指定此项,才能启用自定义指标收集。指定以下一个或多个指标来源:spark、flink、hdfs、yarn、spark-history-server、hiveserver2、hivemetastore和monitoring-agent-defaults。指标来源名称不区分大小写,例如,“yarn”或“YARN”均可接受。 -
--metric-overrides-file:指定包含一个或多个指标的本地文件或 Cloud Storage 文件 (gs://bucket/filename),格式如下:METRIC_SOURCE:INSTANCE:GROUP:METRIC
根据需要使用 camelcase 格式。示例:
--metric-overrides-file=gs://my-bucket/my-filename.txt--metric-overrides-file=./local-directory/local-filename.txt此标志可替代
--metric-overrides标志,但两者不能搭配使用。
REST API
在 clusters.create 请求中使用 DataprocMetricConfig 以启用自定义指标的收集。注意:除非您安装了 Ops Agent,否则 monitoring-agent-defaults 在 2.2 映像版本集群中不可用。
查看自定义指标
通过选择 VM Instance 资源,然后选择 Custom metrics,即可在 Metrics Explorer 中选择并查看 Dataproc 资源指标。
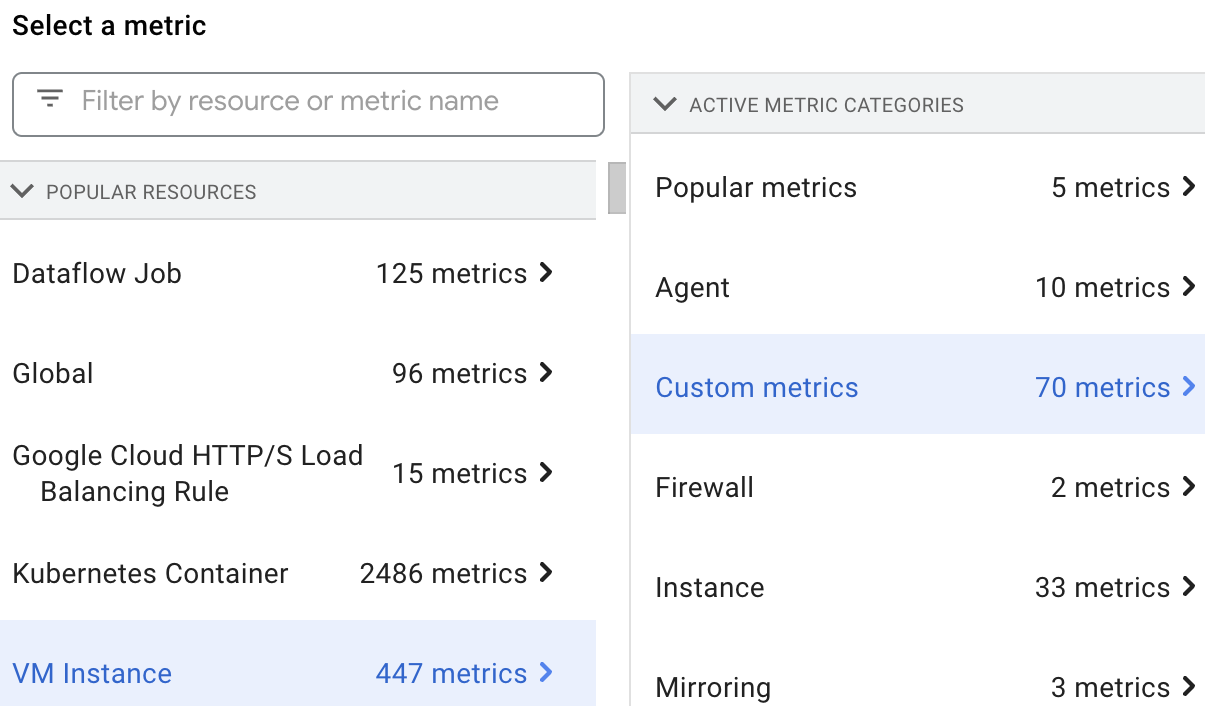
自定义指标
您可以启用 Dataproc 来收集下表中列出的自定义指标。
在您启用关联的指标来源后,如果 Dataproc 收集指标,则已启用指标列会标有“y”。
如果您替换了对指标来源中某组已启用的标准指标的收集,则能够收集为指标来源列出的任意指标以及所有 Spark 指标(请参阅启用自定义指标收集)。
Dataproc 使用监控代理来收集指标。启用任何指标来源都会启用收集代理指标的功能。系统不会向用户收取这些指标的费用;Dataproc 将使用这些指标来诊断指标收集问题。
Hadoop 指标
HDFS 指标
| 指标 | Metrics Explorer 名称 | 已启用指标 |
|---|---|---|
| hdfs:NameNode:FSNamesystem:CapacityTotalGB | dfs/FSNamesystem/CapacityTotalGB | y |
| hdfs:NameNode:FSNamesystem:CapacityUsedGB | dfs/FSNamesystem/CapacityUsedGB | y |
| hdfs:NameNode:FSNamesystem:CapacityRemainingGB | dfs/FSNamesystem/CapacityRemainingGB | y |
| hdfs:NameNode:FSNamesystem:FilesTotal | dfs/FSNamesystem/FilesTotal | y |
| hdfs:NameNode:FSNamesystem:MissingBlocks | dfs/FSNamesystem/MissingBlocks | n |
| hdfs:NameNode:FSNamesystem:ExpiredHeartbeats | dfs/FSNamesystem/ExpiredHeartbeats | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastCheckpoint | dfs/FSNamesystem/TransactionsSinceLastCheckpoint | n |
| hdfs:NameNode:FSNamesystem:TransactionsSinceLastLogRoll | dfs/FSNamesystem/TransactionsSinceLastLogRoll | n |
| hdfs:NameNode:FSNamesystem:LastWrittenTransactionId | dfs/FSNamesystem/LastWrittenTransactionId | n |
| hdfs:NameNode:FSNamesystem:CapacityTotal | dfs/FSNamesystem/CapacityTotal | n |
| hdfs:NameNode:FSNamesystem:CapacityUsed | dfs/FSNamesystem/CapacityUsed | n |
| hdfs:NameNode:FSNamesystem:CapacityRemaining | dfs/FSNamesystem/CapacityRemaining | n |
| hdfs:NameNode:FSNamesystem:CapacityUsedNonDFS | dfs/FSNamesystem/CapacityUsedNonDFS | n |
| hdfs:NameNode:FSNamesystem:TotalLoad | dfs/FSNamesystem/TotalLoad | n |
| hdfs:NameNode:FSNamesystem:SnapshottableDirectories | dfs/FSNamesystem/SnapshottableDirectories | n |
| hdfs:NameNode:FSNamesystem:Snapshots | dfs/FSNamesystem/Snapshots | n |
| hdfs:NameNode:FSNamesystem:BlocksTotal | dfs/FSNamesystem/BlocksTotal | n |
| hdfs:NameNode:FSNamesystem:PendingReplicationBlocks | dfs/FSNamesystem/PendingReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:UnderReplicatedBlocks | dfs/FSNamesystem/UnderReplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:CorruptBlocks | dfs/FSNamesystem/CorruptBlocks | n |
| hdfs:NameNode:FSNamesystem:ScheduledReplicationBlocks | dfs/FSNamesystem/ScheduledReplicationBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDeletionBlocks | dfs/FSNamesystem/PendingDeletionBlocks | n |
| hdfs:NameNode:FSNamesystem:ExcessBlocks | dfs/FSNamesystem/ExcessBlocks | n |
| hdfs:NameNode:FSNamesystem:PostponedMisreplicatedBlocks | dfs/FSNamesystem/PostponedMisreplicatedBlocks | n |
| hdfs:NameNode:FSNamesystem:PendingDataNodeMessageCourt | dfs/FSNamesystem/PendingDataNodeMessageCourt | n |
| hdfs:NameNode:FSNamesystem:MillisSinceLastLoadedEdits | dfs/FSNamesystem/MillisSinceLastLoadedEdits | n |
| hdfs:NameNode:FSNamesystem:BlockCapacity | dfs/FSNamesystem/BlockCapacity | n |
| hdfs:NameNode:FSNamesystem:StaleDataNodes | dfs/FSNamesystem/StaleDataNodes | n |
| hdfs:NameNode:FSNamesystem:TotalFiles | dfs/FSNamesystem/TotalFiles | n |
| hdfs:NameNode:JvmMetrics:MemHeapUsedM | dfs/jvm/MemHeapUsedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapCommittedM | dfs/jvm/MemHeapCommittedM | n |
| hdfs:NameNode:JvmMetrics:MemHeapMaxM | dfs/jvm/MemHeapMaxM | n |
| hdfs:NameNode:JvmMetrics:MemMaxM | dfs/jvm/MemMaxM | n |
YARN 指标
| 指标 | Metrics Explorer 名称 | 已启用指标 |
|---|---|---|
| yarn:ResourceManager:ClusterMetrics:NumActiveNMs | yarn/ClusterMetrics/NumActiveNMs | y |
| yarn:ResourceManager:ClusterMetrics:NumDecommissionedNMs | yarn/ClusterMetrics/NumDecommissionedNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumLostNMs | yarn/ClusterMetrics/NumLostNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumUnhealthyNMs | yarn/ClusterMetrics/NumUnhealthyNMs | n |
| yarn:ResourceManager:ClusterMetrics:NumRebootedNMs | yarn/ClusterMetrics/NumRebootedNMs | n |
| yarn:ResourceManager:QueueMetrics:running_0 | yarn/QueueMetrics/running_0 | y |
| yarn:ResourceManager:QueueMetrics:running_60 | yarn/QueueMetrics/running_60 | y |
| yarn:ResourceManager:QueueMetrics:running_300 | yarn/QueueMetrics/running_300 | y |
| yarn:ResourceManager:QueueMetrics:running_1440 | yarn/QueueMetrics/running_1440 | y |
| yarn:ResourceManager:QueueMetrics:AppsSubmitted | yarn/QueueMetrics/AppsSubmitted | y |
| yarn:ResourceManager:QueueMetrics:AvailableMB | yarn/QueueMetrics/AvailableMB | y |
| yarn:ResourceManager:QueueMetrics:PendingContainers | yarn/QueueMetrics/PendingContainers | y |
| yarn:ResourceManager:QueueMetrics:AppsRunning | yarn/QueueMetrics/AppsRunning | n |
| yarn:ResourceManager:QueueMetrics:AppsPending | yarn/QueueMetrics/AppsPending | n |
| yarn:ResourceManager:QueueMetrics:AppsCompleted | yarn/QueueMetrics/AppsCompleted | n |
| yarn:ResourceManager:QueueMetrics:AppsKilled | yarn/QueueMetrics/AppsKilled | n |
| yarn:ResourceManager:QueueMetrics:AppsFailed | yarn/QueueMetrics/AppsFailed | n |
| yarn:ResourceManager:QueueMetrics:AllocatedMB | yarn/QueueMetrics/AllocatedMB | n |
| yarn:ResourceManager:QueueMetrics:AllocatedVCores | yarn/QueueMetrics/AllocatedVCores | n |
| yarn:ResourceManager:QueueMetrics:AllocatedContainers | yarn/QueueMetrics/AllocatedContainers | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersAllocated | yarn/QueueMetrics/AggregateContainersAllocated | n |
| yarn:ResourceManager:QueueMetrics:AggregateContainersReleased | yarn/QueueMetrics/AggregateContainersReleased | n |
| yarn:ResourceManager:QueueMetrics:AvailableVCores | yarn/QueueMetrics/AvailableVCores | n |
| yarn:ResourceManager:QueueMetrics:PendingMB | yarn/QueueMetrics/PendingMB | n |
| yarn:ResourceManager:QueueMetrics:PendingVCores | yarn/QueueMetrics/PendingVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedMB | yarn/QueueMetrics/ReservedMB | n |
| yarn:ResourceManager:QueueMetrics:ReservedVCores | yarn/QueueMetrics/ReservedVCores | n |
| yarn:ResourceManager:QueueMetrics:ReservedContainers | yarn/QueueMetrics/ReservedContainers | n |
| yarn:ResourceManager:QueueMetrics:ActiveUsers | yarn/QueueMetrics/ActiveUsers | n |
| yarn:ResourceManager:QueueMetrics:ActiveApplications | yarn/QueueMetrics/ActiveApplications | n |
| yarn:ResourceManager:QueueMetrics:FairShareMB | yarn/QueueMetrics/FairShareMB | n |
| yarn:ResourceManager:QueueMetrics:FairShareVCores | yarn/QueueMetrics/FairShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MinShareMB | yarn/QueueMetrics/MinShareMB | n |
| yarn:ResourceManager:QueueMetrics:MinShareVCores | yarn/QueueMetrics/MinShareVCores | n |
| yarn:ResourceManager:QueueMetrics:MaxShareMB | yarn/QueueMetrics/MaxShareMB | n |
| yarn:ResourceManager:QueueMetrics:MaxShareVCores | yarn/QueueMetrics/MaxShareVCores | n |
| yarn:ResourceManager:JvmMetrics:MemHeapUsedM | yarn/jvm/MemHeapUsedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapCommittedM | yarn/jvm/MemHeapCommittedM | n |
| yarn:ResourceManager:JvmMetrics:MemHeapMaxM | yarn/jvm/MemHeapMaxM | n |
| yarn:ResourceManager:JvmMetrics:MemMaxM | yarn/jvm/MemMaxM | n |
Spark 指标
Spark 驱动程序指标
| 指标 | Metrics Explorer 名称 | 已启用指标 |
|---|---|---|
| spark:driver:BlockManager:disk.diskSpaceUsed_MB | spark/driver/BlockManager/disk/diskSpaceUsed_MB | y |
| spark:driver:BlockManager:memory.maxMem_MB | spark/driver/BlockManager/memory/maxMem_MB | y |
| spark:driver:BlockManager:memory.memUsed_MB | spark/driver/BlockManager/memory/memUsed_MB | y |
| spark:driver:DAGScheduler:job.allJobs | spark/driver/DAGScheduler/job/allJobs | y |
| spark:driver:DAGScheduler:stage.failedStages | spark/driver/DAGScheduler/stage/failedStages | y |
| spark:driver:DAGScheduler:stage.waitingStages | spark/driver/DAGScheduler/stage/waitingStages | y |
Spark 执行程序指标
| 指标 | Metrics Explorer 名称 | 已启用指标 |
|---|---|---|
| spark:executor:executor:bytesRead | spark/executor/bytesRead | y |
| spark:executor:executor:bytesWritten | spark/executor/bytesWritten | y |
| spark:executor:executor:cpuTime | spark/executor/cpuTime | y |
| spark:executor:executor:diskBytesSpilled | spark/executor/diskBytesSpilled | y |
| spark:executor:executor:recordsRead | spark/executor/recordsRead | y |
| spark:executor:executor:recordsWritten | spark/executor/recordsWritten | y |
| spark:executor:executor:runTime | spark/executor/runTime | y |
| spark:executor:executor:shuffleRecordsRead | spark/executor/shuffleRecordsRead | y |
| spark:executor:executor:shuffleRecordsWritten | spark/executor/shuffleRecordsWritten | y |
Flink 指标
| 指标 | Metrics Explorer 名称 | 已启用指标 |
|---|---|---|
| flink:jobmanager:numRegisteredTaskManagers | flink/jobmanager/numRegisteredTaskManagers | n |
| flink:jobmanager:numRunningJobs | flink/jobmanager/numRunningJobs | n |
| flink:jobmanager:Status.JVM.ClassLoader.ClassesLoaded | flink/jobmanager/Status.JVM.ClassLoader.ClassesLoaded | n |
| flink:jobmanager:Status.JVM.ClassLoader.ClassesUnloaded | flink/jobmanager/Status.JVM.ClassLoader.ClassesUnloaded | n |
| flink:jobmanager:Status.JVM.CPU.Load | flink/jobmanager/Status.JVM.CPU.Load | n |
| flink:jobmanager:Status.JVM.CPU.Time | flink/jobmanager/Status.JVM.CPU.Time | y |
| flink:jobmanager:Status.JVM.GarbageCollector.PSMarkSweep.Count | flink/jobmanager/Status.JVM.GarbageCollector.PSMarkSweep.Count | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSMarkSweep.Time | flink/jobmanager/Status.JVM.GarbageCollector.PSMarkSweep.Time | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSScavenge.Count | flink/jobmanager/Status.JVM.GarbageCollector.PSScavenge.Count | n |
| flink:jobmanager:Status.JVM.GarbageCollector.PSScavenge.Time | flink/jobmanager/Status.JVM.GarbageCollector.PSScavenge.Time | n |
| flink:jobmanager:Status.JVM.Memory.Direct.Count | flink/jobmanager/Status.JVM.Memory.Direct.Count | y |
| flink:jobmanager:Status.JVM.Memory.Direct.MemoryUsed | flink/jobmanager/Status.JVM.Memory.Direct.MemoryUsed | y |
| flink:jobmanager:Status.JVM.Memory.Direct.TotalCapacity | flink/jobmanager/Status.JVM.Memory.Direct.TotalCapacity | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Committed | flink/jobmanager/Status.JVM.Memory.Heap.Committed | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Max | flink/jobmanager/Status.JVM.Memory.Heap.Max | y |
| flink:jobmanager:Status.JVM.Memory.Heap.Used | flink/jobmanager/Status.JVM.Memory.Heap.Used | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.Count | flink/jobmanager/Status.JVM.Memory.Mapped.Count | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.MemoryUsed | flink/jobmanager/Status.JVM.Memory.Mapped.MemoryUsed | y |
| flink:jobmanager:Status.JVM.Memory.Mapped.TotalCapacity | flink/jobmanager/Status.JVM.Memory.Mapped.TotalCapacity | y |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Committed | flink/jobmanager/Status.JVM.Memory.Metaspace.Committed | n |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Max | flink/jobmanager/Status.JVM.Memory.Metaspace.Max | n |
| flink:jobmanager:Status.JVM.Memory.Metaspace.Used | flink/jobmanager/Status.JVM.Memory.Metaspace.Used | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Committed | flink/jobmanager/Status.JVM.Memory.NonHeap.Committed | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Max | flink/jobmanager/Status.JVM.Memory.NonHeap.Max | n |
| flink:jobmanager:Status.JVM.Memory.NonHeap.Used | flink/jobmanager/Status.JVM.Memory.NonHeap.Used | n |
| flink:jobmanager:Status.JVM.Threads.Count | flink/jobmanager/Status.JVM.Threads.Count | n |
| flink:jobmanager:taskSlotsAvailable | flink/jobmanager/taskSlotsAvailable | y |
| flink:jobmanager:taskSlotsTotal | flink/jobmanager/taskSlotsTotal | y |
| flink:operator:numRecordsIn | flink/operator/numRecordsIn | n |
| flink:operator:numRecordsInPerSecond.count | flink/operator/numRecordsInPerSecond.count | n |
| flink:operator:numRecordsInPerSecond.rate | flink/operator/numRecordsInPerSecond.rate | n |
| flink:operator:numRecordsOut | flink/operator/numRecordsOut | n |
| flink:operator:numRecordsOutPerSecond.count | flink/operator/numRecordsOutPerSecond.count | n |
| flink:operator:numRecordsOutPerSecond.rate | flink/operator/numRecordsOutPerSecond.rate | n |
| flink:operator:numSplitsProcessed | flink/operator/numSplitsProcessed | n |
| flink:task:buffers.inPoolUsage | flink/task/buffers.inPoolUsage | n |
| flink:task:buffers.inputExclusiveBuffersUsage | flink/task/buffers.inputExclusiveBuffersUsage | n |
| flink:task:buffers.inputFloatingBuffersUsage | flink/task/buffers.inputFloatingBuffersUsage | n |
| flink:task:buffers.inputQueueLength | flink/task/buffers.inputQueueLength | n |
| flink:task:buffers.outPoolUsage | flink/task/buffers.outPoolUsage | n |
| flink:task:buffers.outputQueueLength | flink/task/buffers.outputQueueLength | n |
| flink:task:idleTimeMsPerSecond.count | flink/task/idleTimeMsPerSecond.count | n |
| flink:task:idleTimeMsPerSecond.rate | flink/task/idleTimeMsPerSecond.rate | n |
| flink:task:numBuffersInLocal | flink/task/numBuffersInLocal | n |
| flink:task:numBuffersInLocalPerSecond.count | flink/task/numBuffersInLocalPerSecond.count | n |
| flink:task:numBuffersInLocalPerSecond.rate | flink/task/numBuffersInLocalPerSecond.rate | n |
| flink:task:numBuffersInRemote | flink/task/numBuffersInRemote | n |
| flink:task:numBuffersInRemotePerSecond.count | flink/task/numBuffersInRemotePerSecond.count | n |
| flink:task:numBuffersInRemotePerSecond.rate | flink/task/numBuffersInRemotePerSecond.rate | n |
| flink:task:numBuffersOut | flink/task/numBuffersOut | n |
| flink:task:numBuffersOutPerSecond.count | flink/task/numBuffersOutPerSecond.count | n |
| flink:task:numBuffersOutPerSecond.rate | flink/task/numBuffersOutPerSecond.rate | n |
| flink:task:numBytesIn | flink/task/numBytesIn | n |
| flink:task:numBytesInLocal | flink/task/numBytesInLocal | n |
| flink:task:numBytesInLocalPerSecond.count | flink/task/numBytesInLocalPerSecond.count | n |
| flink:task:numBytesInLocalPerSecond.rate | flink/task/numBytesInLocalPerSecond.rate | n |
| flink:task:numBytesInPerSecond.count | flink/task/numBytesInPerSecond.count | n |
| flink:task:numBytesInPerSecond.rate | flink/task/numBytesInPerSecond.rate | n |
| flink:task:numBytesInRemote | flink/task/numBytesInRemote | n |
| flink:task:numBytesInRemotePerSecond.count | flink/task/numBytesInRemotePerSecond.count | n |
| flink:task:numBytesInRemotePerSecond.rate | flink/task/numBytesInRemotePerSecond.rate | n |
| flink:task:numBytesOut | flink/task/numBytesOut | n |
| flink:task:numBytesOutPerSecond.count | flink/task/numBytesOutPerSecond.count | n |
| flink:task:numBytesOutPerSecond.rate | flink/task/numBytesOutPerSecond.rate | n |
| flink:task:numRecordsIn | flink/task/numRecordsIn | n |
| flink:task:numRecordsInPerSecond.count | flink/task/numRecordsInPerSecond.count | n |
| flink:task:numRecordsInPerSecond.rate | flink/task/numRecordsInPerSecond.rate | n |
| flink:task:numRecordsOut | flink/task/numRecordsOut | n |
| flink:task:numRecordsOutPerSecond.count | flink/task/numRecordsOutPerSecond.count | n |
| flink:task:numRecordsOutPerSecond.rate | flink/task/numRecordsOutPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.Buffers.inPoolUsage | flink/task/Shuffle.Netty.Input.Buffers.inPoolUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputExclusiveBuffersUsage | flink/task/Shuffle.Netty.Input.Buffers.inputExclusiveBuffersUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputFloatingBuffersUsage | flink/task/Shuffle.Netty.Input.Buffers.inputFloatingBuffersUsage | n |
| flink:task:Shuffle.Netty.Input.Buffers.inputQueueLength | flink/task/Shuffle.Netty.Input.Buffers.inputQueueLength | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocal | flink/task/Shuffle.Netty.Input.numBuffersInLocal | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocalPerSecond.count | flink/task/Shuffle.Netty.Input.numBuffersInLocalPerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBuffersInLocalPerSecond.rate | flink/task/Shuffle.Netty.Input.numBuffersInLocalPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemote | flink/task/Shuffle.Netty.Input.numBuffersInRemote | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemotePerSecond.count | flink/task/Shuffle.Netty.Input.numBuffersInRemotePerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBuffersInRemotePerSecond.rate | flink/task/Shuffle.Netty.Input.numBuffersInRemotePerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocal | flink/task/Shuffle.Netty.Input.numBytesInLocal | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocalPerSecond.count | flink/task/Shuffle.Netty.Input.numBytesInLocalPerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBytesInLocalPerSecond.rate | flink/task/Shuffle.Netty.Input.numBytesInLocalPerSecond.rate | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemote | flink/task/Shuffle.Netty.Input.numBytesInRemote | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemotePerSecond.count | flink/task/Shuffle.Netty.Input.numBytesInRemotePerSecond.count | n |
| flink:task:Shuffle.Netty.Input.numBytesInRemotePerSecond.rate | flink/task/Shuffle.Netty.Input.numBytesInRemotePerSecond.rate | n |
| flink:task:Shuffle.Netty.Output.Buffers.outPoolUsage | flink/task/Shuffle.Netty.Output.Buffers.outPoolUsage | n |
| flink:task:Shuffle.Netty.Output.Buffers.outputQueueLength | flink/task/Shuffle.Netty.Output.Buffers.outputQueueLength | n |
| flink:taskmanager:Status.flink.Memory.Managed.Total | flink/taskmanager/Status.flink.Memory.Managed.Total | n |
| flink:taskmanager:Status.flink.Memory.Managed.Used | flink/taskmanager/Status.flink.Memory.Managed.Used | n |
| flink:taskmanager:Status.JVM.ClassLoader.ClassesLoaded | flink/taskmanager/Status.JVM.ClassLoader.ClassesLoaded | n |
| flink:taskmanager:Status.JVM.ClassLoader.ClassesUnloaded | flink/taskmanager/Status.JVM.ClassLoader.ClassesUnloaded | n |
| flink:taskmanager:Status.JVM.CPU.Load | flink/taskmanager/Status.JVM.CPU.Load | n |
| flink:taskmanager:Status.JVM.CPU.Time | flink/taskmanager/Status.JVM.CPU.Time | y |
| flink:taskmanager:Status.JVM.GarbageCollector.PSMarkSweep.Count | flink/taskmanager/Status.JVM.GarbageCollector.PSMarkSweep.Count | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSMarkSweep.Time | flink/taskmanager/Status.JVM.GarbageCollector.PSMarkSweep.Time | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSScavenge.Count | flink/taskmanager/Status.JVM.GarbageCollector.PSScavenge.Count | n |
| flink:taskmanager:Status.JVM.GarbageCollector.PSScavenge.Time | flink/taskmanager/Status.JVM.GarbageCollector.PSScavenge.Time | n |
| flink:taskmanager:Status.JVM.Memory.Direct.Count | flink/taskmanager/Status.JVM.Memory.Direct.Count | y |
| flink:taskmanager:Status.JVM.Memory.Direct.MemoryUsed | flink/taskmanager/Status.JVM.Memory.Direct.MemoryUsed | y |
| flink:taskmanager:Status.JVM.Memory.Direct.TotalCapacity | flink/taskmanager/Status.JVM.Memory.Direct.TotalCapacity | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Committed | flink/taskmanager/Status.JVM.Memory.Heap.Committed | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Max | flink/taskmanager/Status.JVM.Memory.Heap.Max | y |
| flink:taskmanager:Status.JVM.Memory.Heap.Used | flink/taskmanager/Status.JVM.Memory.Heap.Used | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.Count | flink/taskmanager/Status.JVM.Memory.Mapped.Count | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.MemoryUsed | flink/taskmanager/Status.JVM.Memory.Mapped.MemoryUsed | y |
| flink:taskmanager:Status.JVM.Memory.Mapped.TotalCapacity | flink/taskmanager/Status.JVM.Memory.Mapped.TotalCapacity | y |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Committed | flink/taskmanager/Status.JVM.Memory.Metaspace.Committed | n |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Max | flink/taskmanager/Status.JVM.Memory.Metaspace.Max | n |
| flink:taskmanager:Status.JVM.Memory.Metaspace.Used | flink/taskmanager/Status.JVM.Memory.Metaspace.Used | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Committed | flink/taskmanager/Status.JVM.Memory.NonHeap.Committed | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Max | flink/taskmanager/Status.JVM.Memory.NonHeap.Max | n |
| flink:taskmanager:Status.JVM.Memory.NonHeap.Used | flink/taskmanager/Status.JVM.Memory.NonHeap.Used | n |
| flink:taskmanager:Status.JVM.Threads.Count | flink/taskmanager/Status.JVM.Threads.Count | n |
| flink:taskmanager:Status.Network.AvailableMemorySegments | flink/taskmanager/Status.Network.AvailableMemorySegments | n |
| flink:taskmanager:Status.Network.TotalMemorySegments | flink/taskmanager/Status.Network.TotalMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.AvailableMemory | flink/taskmanager/Status.Shuffle.Netty.AvailableMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.AvailableMemorySegments | flink/taskmanager/Status.Shuffle.Netty.AvailableMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.TotalMemory | flink/taskmanager/Status.Shuffle.Netty.TotalMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.TotalMemorySegments | flink/taskmanager/Status.Shuffle.Netty.TotalMemorySegments | n |
| flink:taskmanager:Status.Shuffle.Netty.UsedMemory | flink/taskmanager/Status.Shuffle.Netty.UsedMemory | n |
| flink:taskmanager:Status.Shuffle.Netty.UsedMemorySegments | flink/taskmanager/Status.Shuffle.Netty.UsedMemorySegments | n |
Spark 历史记录服务器指标
Dataproc 会收集以下 Spark 历史记录服务 JVM 内存指标:
| 指标 | Metrics Explorer 名称 | 已启用指标 |
|---|---|---|
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.used | sparkHistoryServer/memory/UsedHeapMemory | y |
| sparkHistoryServer:JVM:Memory:HeapMemoryUsage.max | sparkHistoryServer/memory/MaxHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.committed | sparkHistoryServer/memory/CommittedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.used | sparkHistoryServer/memory/UsedNonHeapMemory | y |
| sparkHistoryServer:JVM:Memory:NonHeapMemoryUsage.max | sparkHistoryServer/memory/MaxNonHeapMemory | y |
HiveServer 2 指标
| 指标 | Metrics Explorer 名称 | 已启用指标 |
|---|---|---|
| hiveserver2:JVM:Memory:HeapMemoryUsage.committed | hiveserver2/memory/CommittedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.used | hiveserver2/memory/UsedHeapMemory | y |
| hiveserver2:JVM:Memory:HeapMemoryUsage.max | hiveserver2/memory/MaxHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.committed | hiveserver2/memory/CommittedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.used | hiveserver2/memory/UsedNonHeapMemory | y |
| hiveserver2:JVM:Memory:NonHeapMemoryUsage.max | hiveserver2/memory/MaxNonHeapMemory | y |
Hive Metastore 指标
| 指标 | Metrics Explorer 名称 | 已启用指标 |
|---|---|---|
| hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean | y |
| hivemetastore:API:CreateDatabase:Mean | hivemetastore/create_database/mean | y |
| hivemetastore:API:DropDatabase:Mean | hivemetastore/drop_database/mean | y |
| hivemetastore:API:AlterDatabase:Mean | hivemetastore/alter_database/mean | y |
| hivemetastore:API:GetAllDatabases:Mean | hivemetastore/get_all_databases/mean | y |
| hivemetastore:API:CreateTable:Mean | hivemetastore/create_table/mean | y |
| hivemetastore:API:DropTable:Mean | hivemetastore/drop_table/mean | y |
| hivemetastore:API:AlterTable:Mean | hivemetastore/alter_table/mean | y |
| hivemetastore:API:GetTable:Mean | hivemetastore/get_table/mean | y |
| hivemetastore:API:GetAllTables:Mean | hivemetastore/get_all_tables/mean | y |
| hivemetastore:API:AddPartitionsReq:Mean | hivemetastore/add_partitions_req/mean | y |
| hivemetastore:API:DropPartition:Mean | hivemetastore/drop_partition/mean | y |
| hivemetastore:API:AlterPartition:Mean | hivemetastore/alter_partition/mean | y |
| hivemetastore:API:GetPartition:Mean | hivemetastore/get_partition/mean | y |
| hivemetastore:API:GetPartitionNames:Mean | hivemetastore/get_partition_names/mean | y |
| hivemetastore:API:GetPartitionsPs:Mean | hivemetastore/get_partitions_ps/mean | y |
| hivemetastore:API:GetPartitionsPsWithAuth:Mean | hivemetastore/get_partitions_ps_with_auth/mean | y |
Hive Metastore 指标度量
| 统计度量 | 示例指标 | 示例指标名称 |
|---|---|---|
| 最大值 | hivemetastore:API:GetDatabase:Max | hivemetastore/get_database/max |
| 最小值 | hivemetastore:API:GetDatabase:Min | hivemetastore/get_database/min |
| 平均值 | hivemetastore:API:GetDatabase:Mean | hivemetastore/get_database/mean |
| 计数 | hivemetastore:API:GetDatabase:Count | hivemetastore/get_database/count |
| 第 50 百分位 | hivemetastore:API:GetDatabase:50thPercentile | hivemetastore/get_database/median |
| 第 75 百分位 | hivemetastore:API:GetDatabase:75thPercentile | hivemetastore/get_database/75th_percentile |
| 第 95 百分位 | hivemetastore:API:GetDatabase:95thPercentile | hivemetastore/get_database/95th_percentile |
| 第 98 百分位 | hivemetastore:API:GetDatabase:98thPercentile | hivemetastore/get_database/98th_percentile |
| 第 99 百分位 | hivemetastore:API:GetDatabase:99thPercentile | hivemetastore/get_database/99th_percentile |
| 第 999 百分位 | hivemetastore:API:GetDatabase:999thPercentile | hivemetastore/get_database/999th_percentile |
| StdDev | hivemetastore:API:GetDatabase:StdDev | hivemetastore/get_database/stddev |
| FifteenMinuteRate | hivemetastore:API:GetDatabase:FifteenMinuteRate | hivemetastore/get_database/15min_rate |
| FiveMinuteRate | hivemetastore:API:GetDatabase:FiveMinuteRate | hivemetastore/get_database/5min_rate |
| OneMinuteRate | hivemetastore:API:GetDatabase:OneMinuteRate | hivemetastore/get_database/1min_rate |
| MeanRate | hivemetastore:API:GetDatabase:MeanRate | hivemetastore/get_database/mean_rate |
Dataproc 监控代理指标
在您设置 --metric-sources=monitoring-agent-defaults 后,Dataproc 会收集以下 Dataproc 监控代理指标。这些指标发布时会带有 agent.googleapis.com 前缀。
CPU
agent.googleapis.com/cpu/load_15m
agent.googleapis.com/cpu/load_1m
agent.googleapis.com/cpu/load_5m
agent.googleapis.com/cpu/usage_time*
agent.googleapis.com/cpu/utilization*
磁盘
agent.googleapis.com/disk/bytes_used
agent.googleapis.com/disk/io_time
agent.googleapis.com/disk/merged_operations
agent.googleapis.com/disk/operation_count
agent.googleapis.com/disk/operation_time
agent.googleapis.com/disk/pending_operations
agent.googleapis.com/disk/percent_used
agent.googleapis.com/disk/read_bytes_count
交换
agent.googleapis.com/swap/bytes_used
agent.googleapis.com/swap/io
agent.googleapis.com/swap/percent_used
内存
agent.googleapis.com/memory/bytes_used
agent.googleapis.com/memory/percent_used
进程 - 某些属性遵循独特的配额政策。
agent.googleapis.com/processes/count_by_state
agent.googleapis.com/processes/cpu_time
agent.googleapis.com/processes/disk/read_bytes_count
agent.googleapis.com/processes/disk/write_bytes_count
agent.googleapis.com/processes/fork_count
agent.googleapis.com/processes/rss_usage
agent.googleapis.com/processes/vm_usage
接口
agent.googleapis.com/interface/errors
agent.googleapis.com/interface/packets
agent.googleapis.com/interface/traffic
网络
agent.googleapis.com/network/tcp_connections
构建 Monitoring 信息中心
您可以构建 Monitoring 信息中心,用于显示所选 Dataproc 指标的图表。
从 Monitoring Dashboards Overview 页面中选择 + CREATE DASHBOARD。为信息中心提供一个名称,然后点击右上方菜单中的 Add Chart 以打开 Add Chart 窗口。选择“Cloud Dataproc Cluster”作为资源类型。 选择一个或多个指标以及指标和图表属性。然后保存该图表。
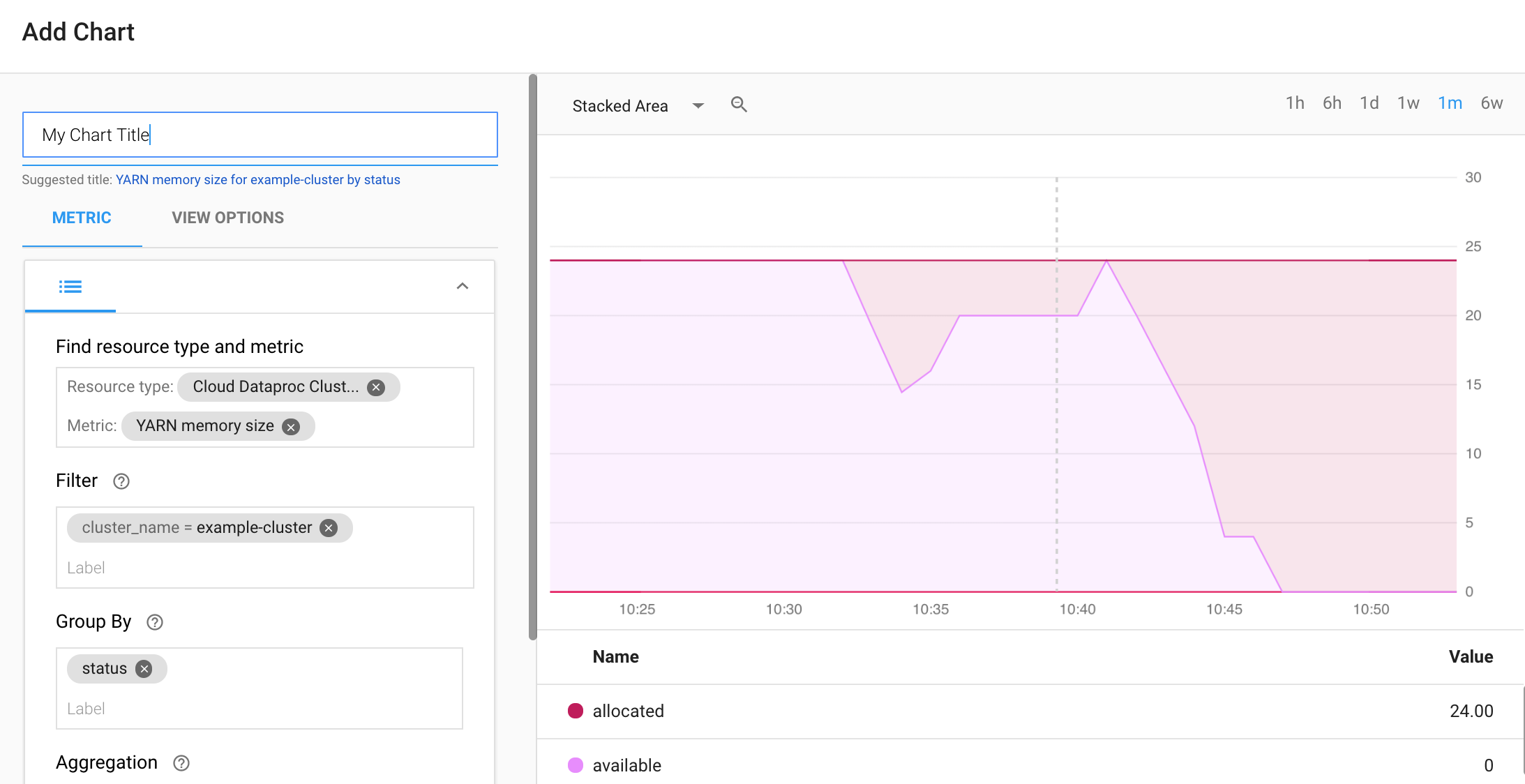
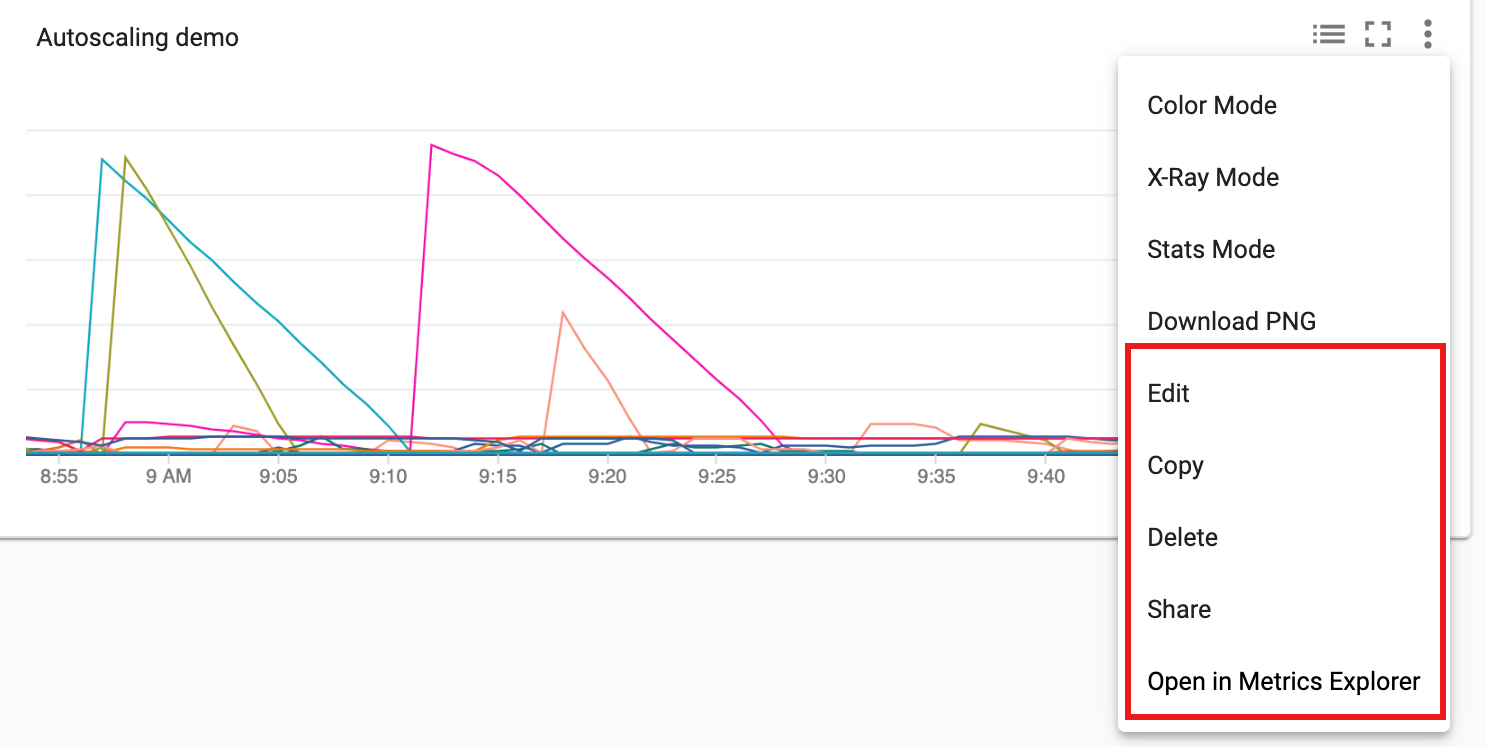
您可以将其他图表添加到信息中心。保存信息中心后,其标题会显示在 Monitoring Dashboards Overview 页面中。您可以在信息中心显示页面中查看、更新和删除信息中心图表。
后续步骤
- 请参阅 Cloud Monitoring 文档
- 了解如何创建 Dataproc 指标提醒