您可以在 Cloud Logging 中查看、搜尋、篩選及封存 Dataproc 工作和叢集記錄。
請參閱 Google Cloud Observability 定價,瞭解相關費用。
如要瞭解記錄保留期限,請參閱「記錄保留期限」一文。
如要停用所有記錄或從 Logging 排除記錄,請參閱「記錄排除」。
如要將記錄從 Cloud Logging 傳送至 Cloud Storage、BigQuery 或 Pub/Sub,請參閱傳送和儲存總覽。
元件記錄層級
建立叢集時,您可以使用元件專屬的 log4j 叢集屬性 (例如 hadoop-log4j),設定 Spark、Hadoop、Flink 和其他 Dataproc 元件的記錄層級。叢集式元件記錄層級適用於服務 Daemon,例如 YARN ResourceManager,以及在叢集上執行的工作。
如果元件 (例如 Presto 元件) 不支援 log4j 屬性,請編寫初始化動作,編輯元件的 log4j.properties 或 log4j2.properties 檔案。
工作專屬的元件記錄層級:您也可以在提交工作時設定元件記錄層級。這些記錄層級會套用至作業,且優先順序高於您建立叢集時設定的記錄層級。詳情請參閱「叢集與工作屬性」。
Spark 和 Hive 元件版本記錄等級:
Spark 3.3.X 和 Hive 3.X 元件使用 log4j2 屬性,而這些元件的舊版則使用 log4j 屬性 (請參閱 Apache Log4j2)。使用 spark-log4j: 前置字串在叢集上設定 Spark 記錄等級。
範例:Dataproc 映像檔 2.0 版搭配 Spark 3.1,設定
log4j.logger.org.apache.spark:gcloud dataproc clusters create ... \ --properties spark-log4j:log4j.logger.org.apache.spark=DEBUG
範例:Dataproc 映像檔版本 2.1 (含 Spark 3.3) 設定
logger.sparkRoot.level:gcloud dataproc clusters create ...\ --properties spark-log4j:logger.sparkRoot.level=debug
工作驅動程式記錄層級
Dataproc 會使用工作驅動程式的預設 INFO 記錄層級。您可以使用 gcloud dataproc jobs submit
--driver-log-levels 標記,變更一或多個套件的這項設定。
範例:
提交讀取 Cloud Storage 檔案的 Spark 工作時,請設定 DEBUG 記錄層級。
gcloud dataproc jobs submit spark ...\ --driver-log-levels org.apache.spark=DEBUG,com.google.cloud.hadoop.gcsio=DEBUG
範例:
將 root 記錄器層級設為 WARN,並將 com.example 記錄器層級設為 INFO。
gcloud dataproc jobs submit hadoop ...\ --driver-log-levels root=WARN,com.example=INFO
Spark 執行器記錄等級
如要設定 Spark 執行器記錄層級,請按照下列步驟操作:
準備 log4j 設定檔,然後上傳至 Cloud Storage
。提交工作時,請參照設定檔。
範例:
gcloud dataproc jobs submit spark ...\ --file gs://my-bucket/path/spark-log4j.properties \ --properties spark.executor.extraJavaOptions=-Dlog4j.configuration=file:spark-log4j.properties
Spark 會將 Cloud Storage 屬性檔案下載至作業的本機工作目錄,並在 -Dlog4j.configuration 中參照為 file:<name>。
Logging 中的 Dataproc 工作記錄
如要瞭解如何在 Logging 中啟用 Dataproc 工作驅動程式記錄,請參閱「Dataproc 工作輸出內容和記錄」。
在 Logging 中存取工作記錄
使用記錄檢視器、gcloud logging 指令或 Logging API 存取 Dataproc 工作記錄。
控制台
Dataproc 工作驅動程式和 YARN 容器記錄檔會列在「Cloud Dataproc Job」資源下方。
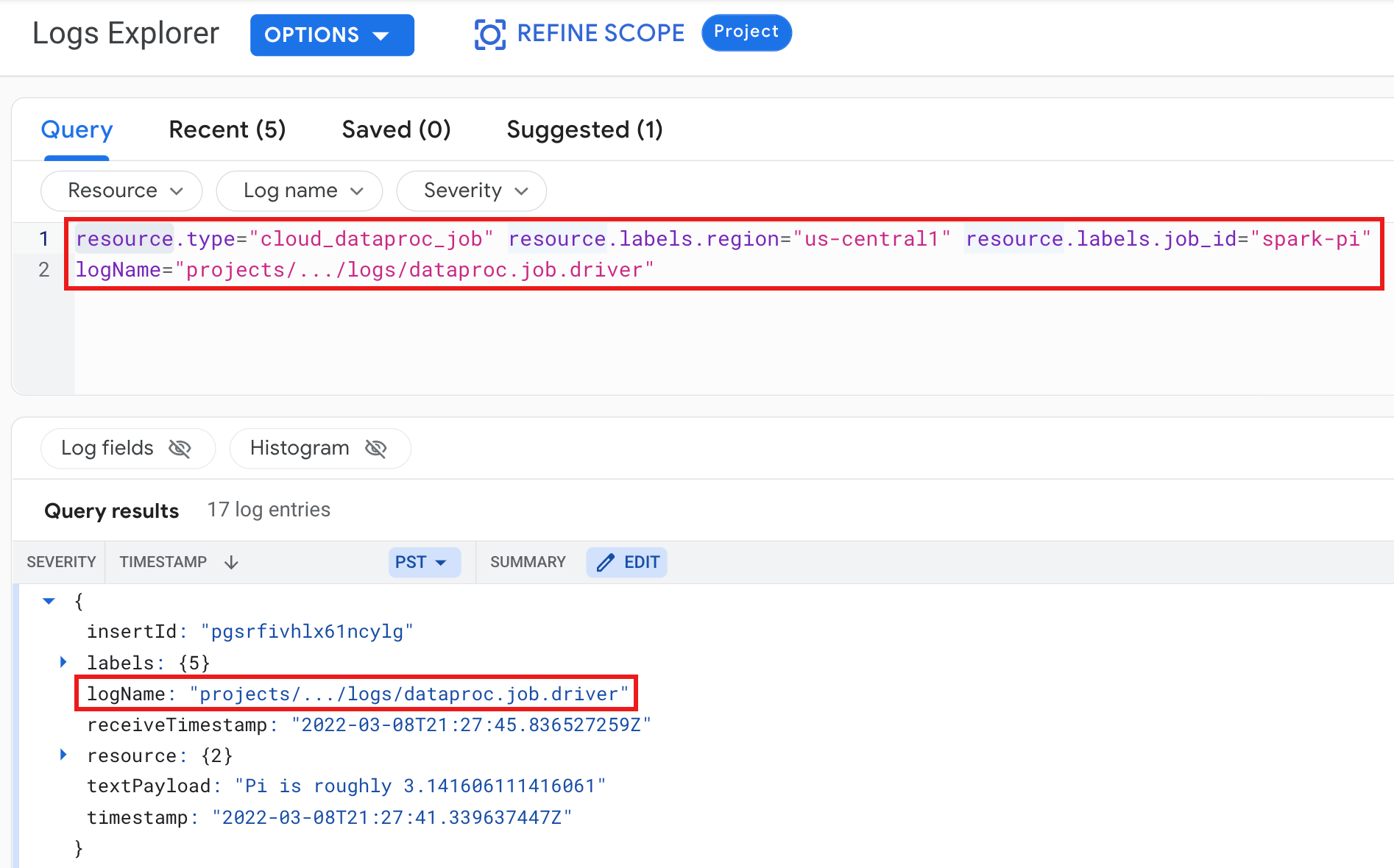
範例:執行記錄檔探索工具查詢後,工作驅動程式記錄檔會顯示下列選取項目:
- 資源:
Cloud Dataproc Job - 記錄檔名稱:
dataproc.job.driver
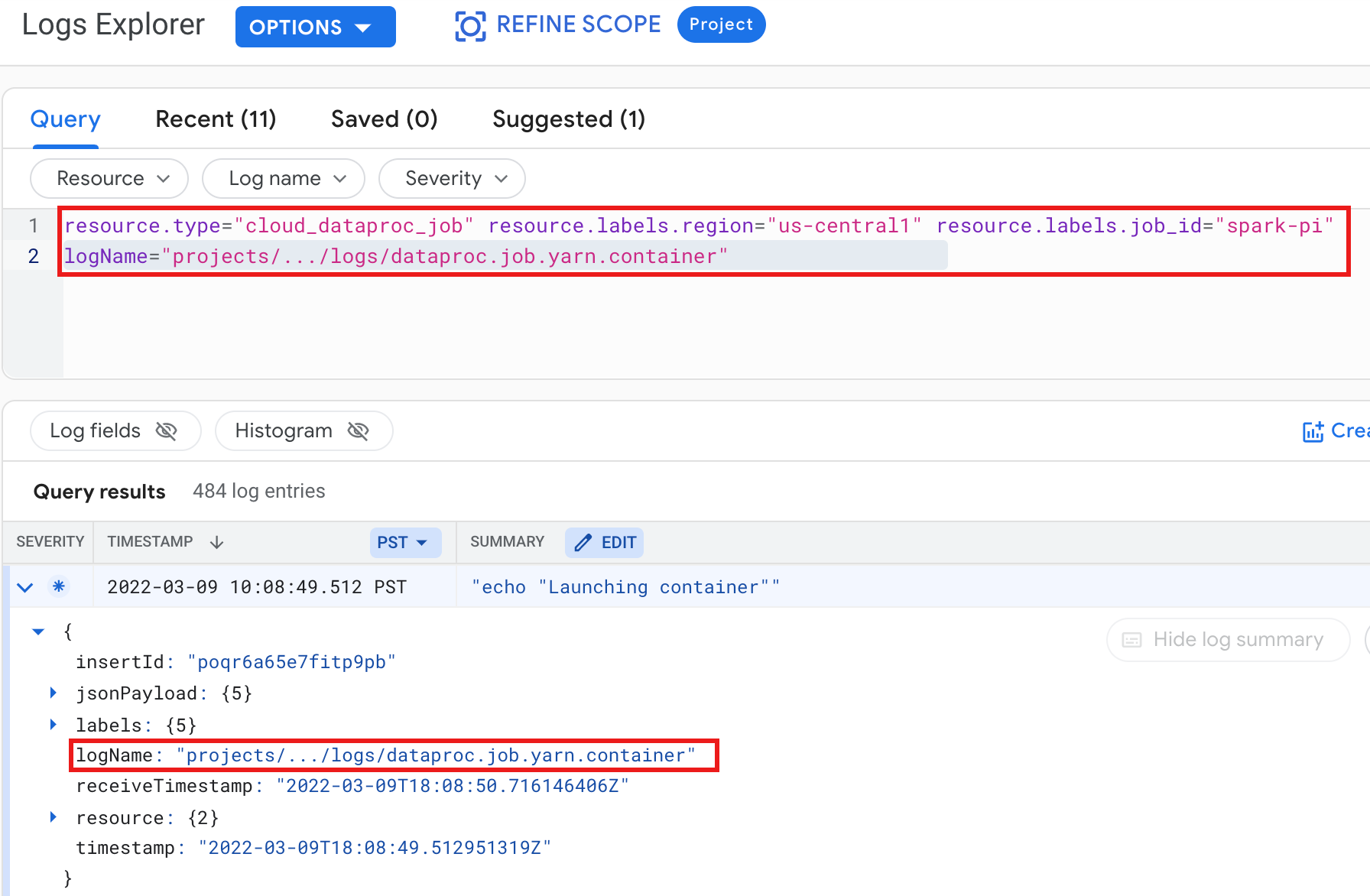
範例:執行記錄檔探索工具查詢後,YARN 容器記錄如下:
- 資源:
Cloud Dataproc Job - 記錄檔名稱:
dataproc.job.yarn.container
gcloud
您可以使用 gcloud logging read 指令讀取工作記錄項目。資源引數必須以引號括住 ("...")。 下列指令會使用叢集標籤篩選傳回的記錄檔項目。
gcloud logging read \ "resource.type=cloud_dataproc_job \ resource.labels.region=cluster-region \ resource.labels.job_id=my-job-id"
輸出範例 (部分):
jsonPayload: class: org.apache.hadoop.hdfs.StateChange filename: hadoop-hdfs-namenode-test-dataproc-resize-cluster-20190410-38an-m-0.log ,,, logName: projects/project-id/logs/hadoop-hdfs-namenode --- jsonPayload: class: SecurityLogger.org.apache.hadoop.security.authorize.ServiceAuthorizationManager filename: cluster-name-dataproc-resize-cluster-20190410-38an-m-0.log ... logName: projects/google.com:hadoop-cloud-dev/logs/hadoop-hdfs-namenode
REST API
您可以使用 Logging REST API 列出記錄項目 (請參閱 entries.list)。
Logging 中的 Dataproc 叢集記錄
Dataproc 會將下列 Apache Hadoop、Spark、Hive、Zookeeper 和其他 Dataproc 叢集記錄檔匯出至 Cloud Logging。
| 記錄類型 | 記錄檔名稱 | 說明 |
|---|---|---|
| 主要精靈記錄 | hadoop-hdfs hadoop-hdfs-namenode hadoop-hdfs-secondary namenode hadoop-hdfs-zkfc hadoop-yarn-resourcemanager hadoop-yarn-timelineserver hive-metastore hive-server2 mapred-mapred-historyserver zookeeper |
日誌節點 HDFS namenode HDFS secondary namenode Zookeeper 容錯移轉控制器 YARN 資源管理工具 YARN 時間軸伺服器 Hive metastore Hive server2 Mapreduce 工作記錄伺服器 Zookeeper 伺服器 |
| 工作站 Daemon 記錄檔 |
hadoop-hdfs-datanode hadoop-yarn-nodemanager |
HDFS 資料節點 YARN 節點管理員 |
| 系統記錄 |
autoscaler google.dataproc.agent google.dataproc.startup |
Dataproc 自動調度程式記錄 Dataproc 代理程式記錄 Dataproc 啟動指令碼記錄 + 初始化動作記錄 |
| 擴充 (額外) 記錄 |
knox gateway-audit zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
符合下列條件的 /var/log/ 子目錄中的所有記錄:knox (包括 gateway-audit.log) zeppelin ranger-usersync jupyter_notebook jupyter_kernel_gateway spark-history-server |
| VM 系統記錄 |
syslog |
叢集主要節點和工作站節點的系統記錄 |
在 Cloud Logging 中存取叢集記錄
您可以使用 記錄探索工具、gcloud logging 指令或 Logging API,存取 Dataproc 叢集記錄。
控制台
選取下列查詢,在記錄檔探索工具中查看叢集記錄:
- 資源:
Cloud Dataproc Cluster - 記錄檔名稱: log name

gcloud
您可以使用 gcloud logging read 指令讀取叢集記錄項目。資源引數必須以引號括住 ("...")。 下列指令會使用叢集標籤篩選傳回的記錄檔項目。
gcloud logging read <<'EOF' "resource.type=cloud_dataproc_cluster resource.labels.region=cluster-region resource.labels.cluster_name=cluster-name resource.labels.cluster_uuid=cluster-uuid" EOF
輸出範例 (部分):
jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-cluster-name-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager --- jsonPayload: class: org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService filename: hadoop-yarn-resourcemanager-component-gateway-cluster-m.log ... logName: projects/project-id/logs/hadoop-yarn-resourcemanager
REST API
您可以使用 Logging REST API 列出記錄項目 (請參閱 entries.list)。
權限
如要將記錄寫入 Logging,Dataproc VM 服務帳戶必須具備 logging.logWriter 身分與存取權管理角色。預設的 Dataproc 服務帳戶具備這個角色。如果您使用自訂服務帳戶,請務必將這個角色指派給服務帳戶。
保護記錄
根據預設,記錄服務中的記錄會經過靜態資料加密處理。您可以啟用客戶自行管理的加密金鑰 (CMEK) 來加密記錄。如要進一步瞭解 CMEK 支援,請參閱「管理保護記錄檔路由器資料的金鑰」和「管理保護記錄檔儲存空間資料的金鑰」。