您可以透過 Dataproc API jobs.submit HTTP 或程式輔助要求,在本機終端機視窗或在 Cloud Shell 中使用 Google Cloud CLI gcloud 指令列工具,或從本機瀏覽器開啟的 Google Cloud 主控台,向現有 Dataproc 叢集提交工作。您也可以使用 SSH 連結叢集中的主要執行個體,然後直接從執行個體執行工作,無需使用 Dataproc 服務。
如何提交工作
控制台
在瀏覽器中開啟 Google Cloud 控制台的 Dataproc「Submit a job」(提交工作) 頁面。
Spark 工作範例
如要提交範例 Spark 工作,請依照下列說明填寫「Submit a job」(提交工作) 頁面中的欄位:
- 從叢集清單選取您的「Cluster」(叢集) 名稱。
- 將「Job type」(工作類型) 設為
Spark。 - 將「Main class or jar」(主要類別或 jar) 設為
org.apache.spark.examples.SparkPi。 - 將「Arguments」(引數) 設為單一引數
1000。 - 在「Jar files」(Jar 檔案) 中加入
file:///usr/lib/spark/examples/jars/spark-examples.jar:file:///表示 Hadoop LocalFileSystem 配置。Dataproc 會在建立叢集時,將/usr/lib/spark/examples/jars/spark-examples.jar安裝在叢集的主要節點上。- 或者,您也可以指定其中一個 JAR 的 Cloud Storage 路徑 (
gs://your-bucket/your-jarfile.jar) 或 Hadoop 分散式檔案系統路徑 (hdfs://path-to-jar.jar)。
按一下 [Submit] (提交) 以啟動工作。工作啟動後,即會加入「Jobs」[工作] 清單中。
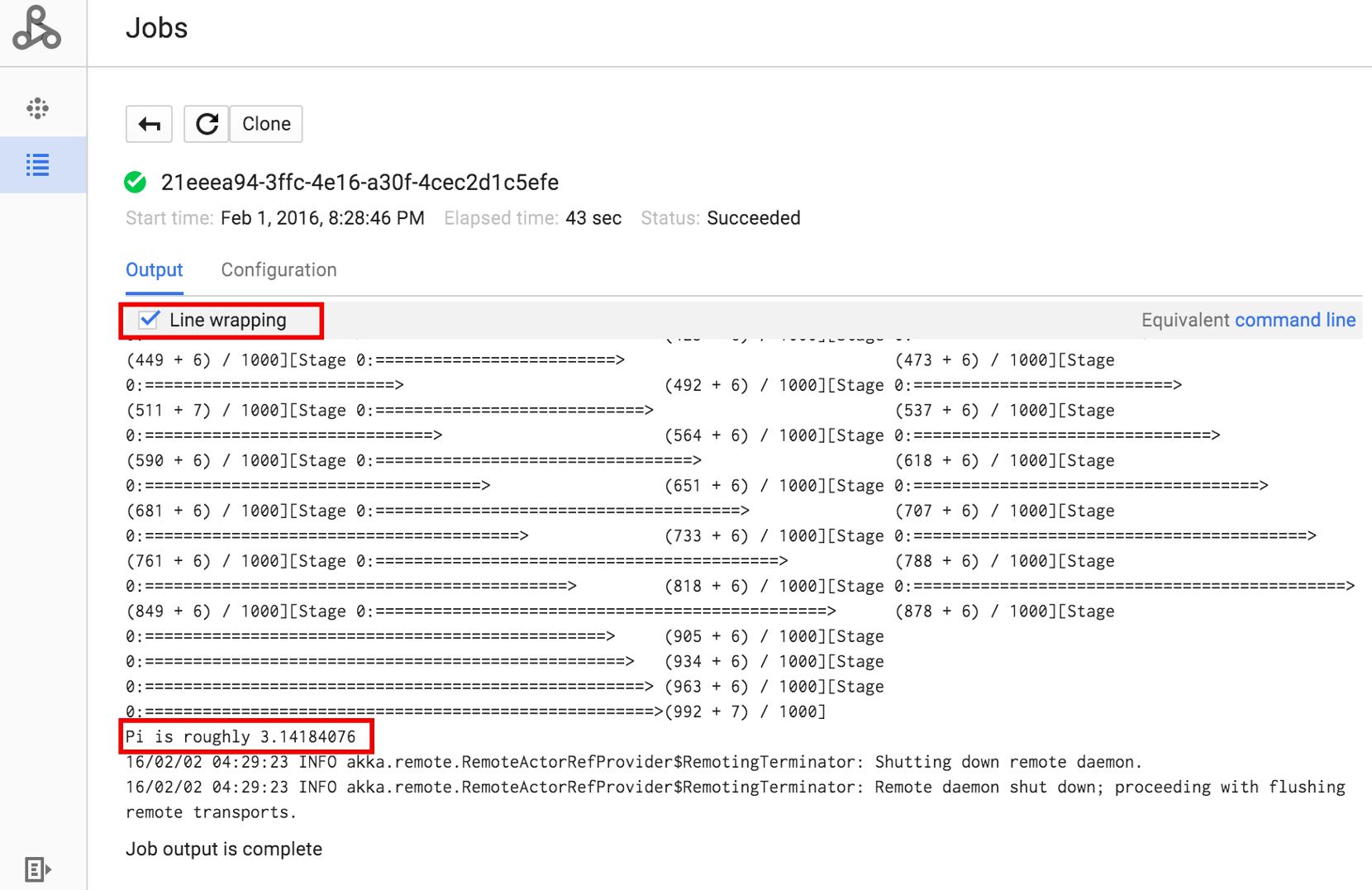
按一下工作 ID 以開啟「Jobs」(工作) 頁面,您可以在此頁面查看工作的驅動程式輸出。因為這項工作產生的輸出行長度超過瀏覽器視窗的寬度,您可以勾選「Line wrapping」(換行) 方塊,在視圖中顯示所有輸出文字,就可以顯示計算後的 pi 結果。
您可以使用下方顯示的 gcloud dataproc jobs wait 指令,從指令列查看工作的驅動程式輸出 (詳情請參閱查看工作輸出內容 - GCLOUD 指令)。複製專案 ID 並貼上做為 --project 標記的值;複製工作 ID (顯示在工作清單上) 並貼上做為最後一個引數的值。
gcloud dataproc jobs wait job-id \ --project=project-id \ --region=region
下列程式碼片段取自上方提交的範例 SparkPi 工作的驅動程式輸出:
... 2015-06-25 23:27:23,810 INFO [dag-scheduler-event-loop] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Stage 0 (reduce at SparkPi.scala:35) finished in 21.169 s 2015-06-25 23:27:23,810 INFO [task-result-getter-3] cluster.YarnScheduler (Logging.scala:logInfo(59)) - Removed TaskSet 0.0, whose tasks have all completed, from pool 2015-06-25 23:27:23,819 INFO [main] scheduler.DAGScheduler (Logging.scala:logInfo(59)) - Job 0 finished: reduce at SparkPi.scala:35, took 21.674931 s Pi is roughly 3.14189648 ... Job [c556b47a-4b46-4a94-9ba2-2dcee31167b2] finished successfully. driverOutputUri: gs://sample-staging-bucket/google-cloud-dataproc-metainfo/cfeaa033-749e-48b9-... ...
gcloud
如要向 Dataproc 叢集提交工作,請在本機的終端機視窗或在 Cloud Shell 中執行 gcloud CLI gcloud dataproc jobs submit 指令。
gcloud dataproc jobs submit job-command \ --cluster=cluster-name \ --region=region \ other dataproc-flags \ -- job-args
- 列出位於 Cloud Storage 中可公開存取的
hello-world.py。gcloud storage cat gs://dataproc-examples/pyspark/hello-world/hello-world.py
#!/usr/bin/python import pyspark sc = pyspark.SparkContext() rdd = sc.parallelize(['Hello,', 'world!']) words = sorted(rdd.collect()) print(words)
- 將 Pyspark 工作提交至 Dataproc。
gcloud dataproc jobs submit pyspark \ gs://dataproc-examples/pyspark/hello-world/hello-world.py \ --cluster=cluster-name \ --region=region
Waiting for job output... … ['Hello,', 'world!'] Job finished successfully.
- 執行預先安裝在 Dataproc 叢集主要節點上的 SparkPi 範例。
gcloud dataproc jobs submit spark \ --cluster=cluster-name \ --region=region \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Job [54825071-ae28-4c5b-85a5-58fae6a597d6] submitted. Waiting for job output… … Pi is roughly 3.14177148 … Job finished successfully. …
REST
本節說明如何使用 Dataproc jobs.submit API 提交 Spark 工作,計算 pi 的近似值。
使用任何要求資料之前,請先替換以下項目:
- project-id: Google Cloud 專案 ID
- region:叢集區域
- clusterName:叢集名稱
HTTP 方法和網址:
POST https://dataproc.googleapis.com/v1/projects/project-id/regions/region/jobs:submit
JSON 要求主體:
{
"job": {
"placement": {
"clusterName": "cluster-name"
},
"sparkJob": {
"args": [
"1000"
],
"mainClass": "org.apache.spark.examples.SparkPi",
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
}
}
}
如要傳送要求,請展開以下其中一個選項:
您應該會收到如下的 JSON 回應:
{
"reference": {
"projectId": "project-id",
"jobId": "job-id"
},
"placement": {
"clusterName": "cluster-name",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "job-Uuid"
}
Java
- 安裝用戶端程式庫
- 設定應用程式預設憑證
- 執行程式碼
Python
- 安裝用戶端程式庫
- 設定應用程式預設憑證
- 執行程式碼
Go
- 安裝用戶端程式庫
- 設定應用程式預設憑證
- 執行程式碼
Node.js
- 安裝用戶端程式庫
- 設定應用程式預設憑證
- 執行程式碼
直接在叢集中提交工作
如果您想在叢集中直接執行工作而不使用 Dataproc 服務,請使用 SSH 連結叢集的主要節點,然後在主要節點上執行工作。
建立連結 VM 主要執行個體的 SSH 連線後,請在叢集主要節點的終端機視窗中執行指令以完成下列步驟:
- 開啟 Spark 殼層。
- 執行簡單的 Spark 工作,計算位於可公開存取的 Cloud Storage 檔案中,Python「hello-world」檔案的行數 (共七行)。
結束殼層。
user@cluster-name-m:~$ spark-shell ... scala> sc.textFile("gs://dataproc-examples" + "/pyspark/hello-world/hello-world.py").count ... res0: Long = 7 scala> :quit
在 Dataproc 上執行 Bash 工作
您可能想將 Bash 指令碼做為 Dataproc 工作執行,原因可能是您使用的引擎不支援做為頂層 Dataproc 工作類型,或是您需要先完成額外設定或計算引數,再使用指令碼中的 hadoop 或 spark-submit 啟動工作。
Pig 範例
假設您已將 hello.sh Bash 指令碼複製到 Cloud Storage:
gcloud storage cp hello.sh gs://${BUCKET}/hello.sh由於 pig fs 指令使用 Hadoop 路徑,請將指令碼從 Cloud Storage 複製到指定為 file:/// 的目的地,確保指令碼位於本機檔案系統而非 HDFS。後續的 sh 指令會自動參照本機檔案系統,不需要 file:/// 前置字串。
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
-e='fs -cp -f gs://${BUCKET}/hello.sh file:///tmp/hello.sh; sh chmod 750 /tmp/hello.sh; sh /tmp/hello.sh'或者,由於 Dataproc jobs submit --jars 引數會將檔案暫存到為工作生命週期建立的暫時目錄中,因此您可以將 Cloud Storage Shell 指令碼指定為 --jars 引數:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=gs://${BUCKET}/hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'請注意,--jars 引數也可以參照本機指令碼:
gcloud dataproc jobs submit pig --cluster=${CLUSTER} --region=${REGION} \
--jars=hello.sh \
-e='sh chmod 750 ${PWD}/hello.sh; sh ${PWD}/hello.sh'