Dataproc サービスを使用してクラスタを作成し、クラスタでジョブを実行すると、サービスはプロジェクトで必要な Dataproc ロールと権限を設定し、タスクの完了に必要な Google Cloud リソースにアクセスして使用します。ただし、複数のプロジェクトにわたって作業(たとえば、別のプロジェクトのデータにアクセスするなど)を行う場合、プロジェクトをまたぐリソースにアクセスするためのロールと権限を設定する必要があります。
複数のプロジェクトにわたる作業の実現に役立つように、このドキュメントでは、Dataproc サービスを使用するプリンシパルと、 Google Cloud リソースにアクセスして使用するためにプリンシパルが必要とする権限を含むロールを示します。
Dataproc にアクセスして使用するプリンシパル(ID)は 3 つあります。
- ユーザー ID
- コントロール プレーン ID
データプレーン ID
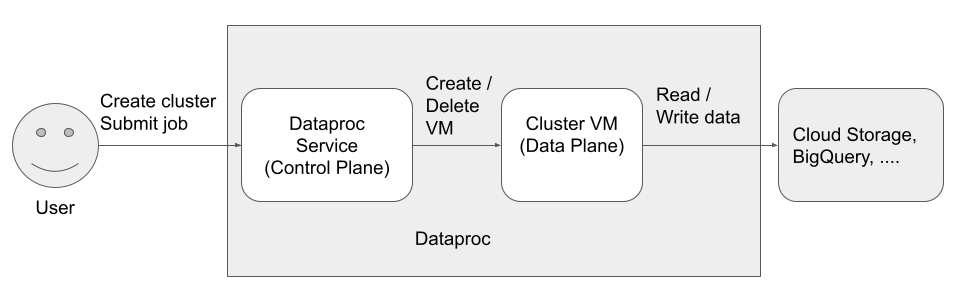
Dataproc API ユーザー(ユーザー ID)
例: username@example.com
これは、Dataproc サービスを呼び出してクラスタの作成、ジョブの送信、サービスに対する他のリクエストを行うユーザーです。通常、ユーザーは個人ですが、API クライアントや別のGoogle Cloud サービス(Compute Engine、Cloud Run functions、Cloud Composer など)から Dataproc を呼び出す場合にはサービス アカウントにすることもできます。
関連するロール
注
- Dataproc API が送信するジョブは、Linux で
rootとして実行されます。 クラスタの作成時に
--metadata=block-project-ssh-keys=trueを設定して明示的にブロックしない限り、Dataproc クラスタはプロジェクト全体で Compute Engine SSH メタデータを継承します(クラスタ メタデータを参照してください)。プロジェクト レベルの SSH ユーザーごとに HDFS ユーザー ディレクトリが作成されます。これらの HDFS ディレクトリはクラスタのデプロイ時に作成され、新しい(デプロイ後の)SSH ユーザーには、既存のクラスタの HDFS ディレクトリは指定されません。
Dataproc サービス エージェント(コントロール プレーン ID)
例: service-project-number@dataproc-accounts.iam.gserviceaccount.com
Dataproc サービス エージェント サービス アカウントは、Dataproc クラスタが作成されたプロジェクト内のリソースに対して、幅広いシステム オペレーションを実行するために使用されます。たとえば、次の場合に使用されます。
- VM インスタンス、インスタンス グループ、インスタンス テンプレートなどの Compute Engine リソースの作成
- イメージ、ファイアウォール、Dataproc 初期化アクション、Cloud Storage バケットなどのリソースの構成を確認する
getとlistのオペレーション - Dataproc ステージングバケットと一時バケットの自動作成(ユーザーによってステージング バケットまたは一時バケットが指定されていない場合)
- ステージング バケットへのクラスタ構成メタデータの書き込み
- ホスト プロジェクトの VPC ネットワークへのアクセス
関連するロール
Dataproc VM サービス アカウント(データプレーン ID)
例: project-number-compute@developer.gserviceaccount.com
アプリケーション コードは、Dataproc VM で VM サービス アカウントとして実行されます。ユーザージョブには、このサービス アカウントのロール(および関連付けられている権限)が付与されます。
VM サービス アカウントは次の処理を行います。
- Dataproc コントロール プレーンと通信します。
- Dataproc ステージング バケットと一時バケットとの間でデータを読み書きします。
- Dataproc ジョブで必要な場合は、Cloud Storage、BigQuery、Cloud Logging、その他の Google Cloud リソースとの間でデータの読み取りと書き込みを行います。
関連するロール
次のステップ
- Dataproc のロールと権限について確認する。
- Dataproc サービス アカウントの詳細を確認する。
- BigQuery アクセス制御を確認する。
- Cloud Storage のアクセス制御オプションを確認する。