Dataproc ジョブを送信すると、Dataproc によってジョブ出力が自動的に収集され、利用できるようになります。つまり、クラスタへの接続を維持しなくてもジョブ出力を速やかに確認し、その一方でジョブを実行したり、複雑なログファイルに目を通したりできます。
Spark ログ
Spark ログには、Spark ドライバログと Spark エグゼキュータ ログの 2 種類があります。Spark のドライバログにはジョブの出力が含まれます。Spark エグゼキュータのログには、spark-submit 「送信されたアプリケーション xxx」メッセージなどのジョブ実行可能ファイルやランチャー出力が含まれています。これはジョブの失敗のデバッグに役立ちます。
Dataproc ジョブドライバは、Spark ドライバとは異なり、多くのジョブタイプのランチャーです。Spark ジョブを起動すると、基盤となる spark-submit 実行可能ファイルでラッパーとして実行され、Spark ドライバが起動されます。Spark ドライバは、Spark の client モードまたは cluster モードで Dataproc クラスタでジョブを実行します。
clientモード: Spark ドライバはspark-submitプロセスでジョブを実行し、Spark ログは Dataproc ジョブドライバに送信されます。clusterモード: Spark ドライバは YARN コンテナでジョブを実行します。Spark ドライバのログは、Dataproc ジョブドライバでは使用できません。
Dataproc と Spark のジョブ プロパティの概要
| プロパティ | 値 | デフォルト | 説明 |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
true または false | false | クラスタの作成時に設定する必要があります。true の場合、ジョブドライバ出力はジョブリソースに関連付けられている Logging にあります。false の場合、ジョブドライバ出力は Logging にありません。注: 次のクラスタ プロパティ設定は、Logging でジョブドライバのログを有効にするためにも必要です。クラスタの作成時にはデフォルトで設定されます。 dataproc:dataproc.logging.stackdriver.enable=true と dataproc:jobs.file-backed-output.enable=true です。 |
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
true または false | false | クラスタの作成時に設定する必要があります。true の場合、ジョブの YARN コンテナログがジョブリソースに関連付けられます。false の場合、ジョブの YARN コンテナログがクラスタ リソースに関連付けられます。 |
spark:spark.submit.deployMode |
クライアントまたはクラスタ | クライアント | Spark の client モードまたは cluster モードを制御します。 |
Dataproc jobs API を使用して送信された Spark ジョブ
このセクションの表には、Dataproc jobs API を介してジョブを送信する際の、Dataproc ジョブドライバ出力の宛先に対するさまざまなプロパティ設定の影響が一覧表示されています。これには、Google Cloud コンソールからのジョブ送信も含まれます。gcloud CLI、Cloud クライアント ライブラリなどが用意されています。
一覧表示された Dataproc プロパティと Spark プロパティは、クラスタの作成時に --properties フラグで設定できます。これは、クラスタで実行されるすべての Spark ジョブに適用されます。Spark のプロパティは、ジョブが Dataproc jobs API に送信されるときに --properties フラグ(「spark」接頭辞なし)で設定することもでき、そのジョブにのみ適用されます。
Dataproc ジョブドライバの出力
次の表に、Dataproc ジョブドライバ出力の宛先に対するさまざまなプロパティ設定の影響を示します。
dataproc: |
出力 |
|---|---|
| false(デフォルト) |
|
| true |
|
Spark ドライバのログ
次の表に、Spark ドライバログのエクスポート先でのさまざまなプロパティ設定の影響を示します。
spark: |
dataproc: |
dataproc: |
ドライバ出力 |
|---|---|---|---|
| クライアント | false(デフォルト) | true または false |
|
| クライアント | true | true または false |
|
| クラスタ | false(デフォルト) | false |
|
| クラスタ | true | true |
|
Spark エグゼキュータのログ
次の表に、Spark エグゼキュータ ログのエクスポート先でのさまざまなプロパティ設定の影響を示します。
dataproc: |
エグゼキュータ ログ |
|---|---|
| false(デフォルト) | Logging の場合: クラスタ リソースの yarn-userlogs |
| true | Logging の場合: ジョブリソースの下の dataproc.job.yarn.container |
Dataproc jobs API を使用せずに送信された Spark ジョブ
このセクションでは、Dataproc jobs API を使用せずにジョブを送信した場合(たとえば、spark-submit を使用するか、Jupyter または Zeppelin ノートブックを使用してクラスタノードでジョブを直接送信した場合)の、Spark ジョブのログのエクスポート先での異なるプロパティ設定の影響を説明します。これらのジョブには Dataproc ジョブ ID やドライバがありません。
Spark ドライバのログ
次の表に、Dataproc jobs API を使用しないで送信されるジョブの Spark ドライバログのエクスポート先での、異なるプロパティ設定の影響を示します。
spark: |
ドライバ出力 |
|---|---|
| クライアント |
|
| クラスタ |
|
Spark エグゼキュータのログ
Spark ジョブが Dataproc jobs API を使用しないで送信される場合、エグゼキュータのログはクラスタ リソースの下の Logging yarn-userlogs にあります。
ジョブ出力を表示する
Dataproc ジョブの出力には、 Google Cloud コンソール、gcloud CLI、Cloud Storage、Logging からアクセスできます。
コンソール
ジョブ出力を表示するには、プロジェクトで Dataproc の [ジョブ] セクションに移動し、ジョブ出力を表示するジョブ ID をクリックします。
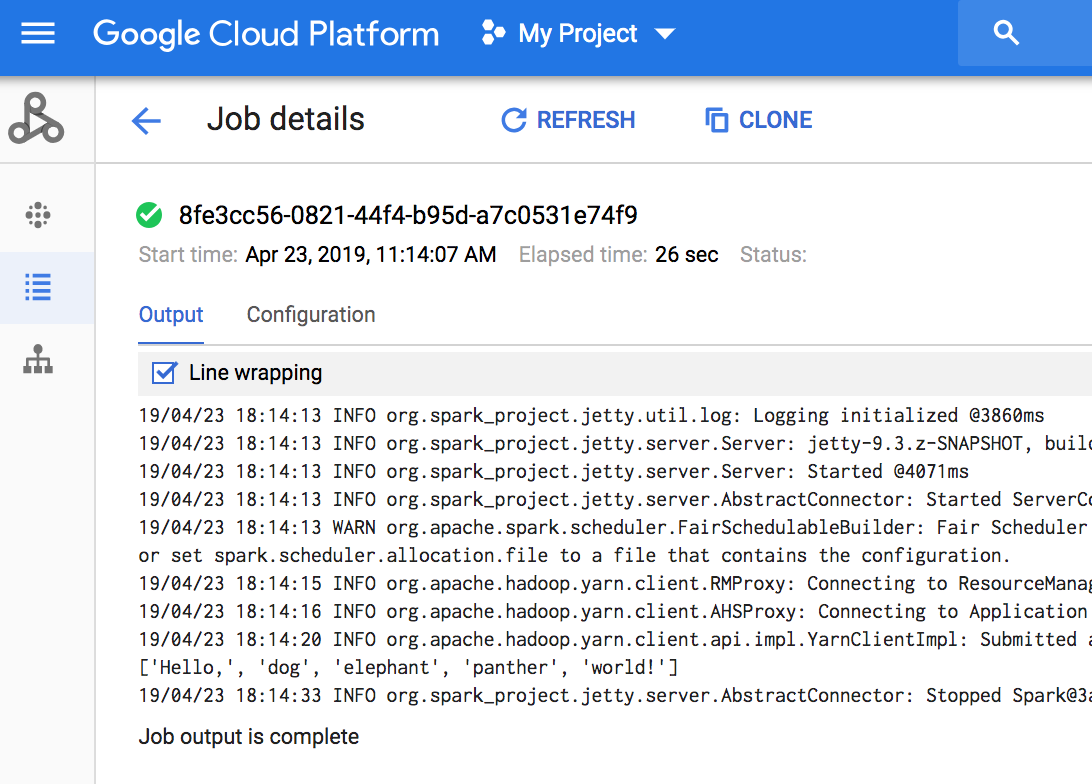
ジョブが実行中の場合は、ジョブ出力が新しい内容で定期的にリフレッシュされます。
gcloud コマンド
gcloud dataproc jobs submit コマンドでジョブを送信すると、ジョブ出力がコンソールに表示されます。ジョブ ID を gcloud dataproc jobs wait コマンドに渡すと、出力を後の時間、別のパソコン、または新しいウィンドウで「再結合」できます。ジョブ ID は、5c1754a5-34f7-4553-b667-8a1199cb9cab などの GUID です。次に例を示します。
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
ジョブ出力は、Cloud Storage のステージング バケットまたはクラスタの作成時に指定したバケットに格納されます。以下によって返される Job.driverOutputResourceUri フィールドに、Cloud Storage のジョブ出力へのリンクが示されます。
- jobs.get API リクエスト。
- gcloud dataproc jobs describe job-id コマンド。
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...