このページでは、Dataproc ジョブのモニタリングとデバッグ、Dataproc ジョブのエラー メッセージの理解に役立つ情報を提供します。
ジョブのモニタリングとデバッグ
Google Cloud CLI、Dataproc REST API、Google Cloud コンソールを使用して Dataproc ジョブを分析しデバッグします。
gcloud CLI
実行中のジョブの状態を調査するには:
gcloud dataproc jobs describe job-id \ --region=region
ジョブドライバ出力を表示するには、ジョブ出力を表示するをご覧ください。
REST API
jobs.get を呼び出して、ジョブの JobStatus.State、JobStatus.Substate、JobStatus details、YarnApplication の各フィールドを調べます。
Console
ジョブドライバ出力を表示するには、ジョブ出力を表示するをご覧ください。
Logging で dataproc エージェント ログを表示するには、ログエクスプローラーのクラスタ セレクタから [Dataproc クラスタ] → [クラスタ名] → [クラスタの UUID] を選択します。
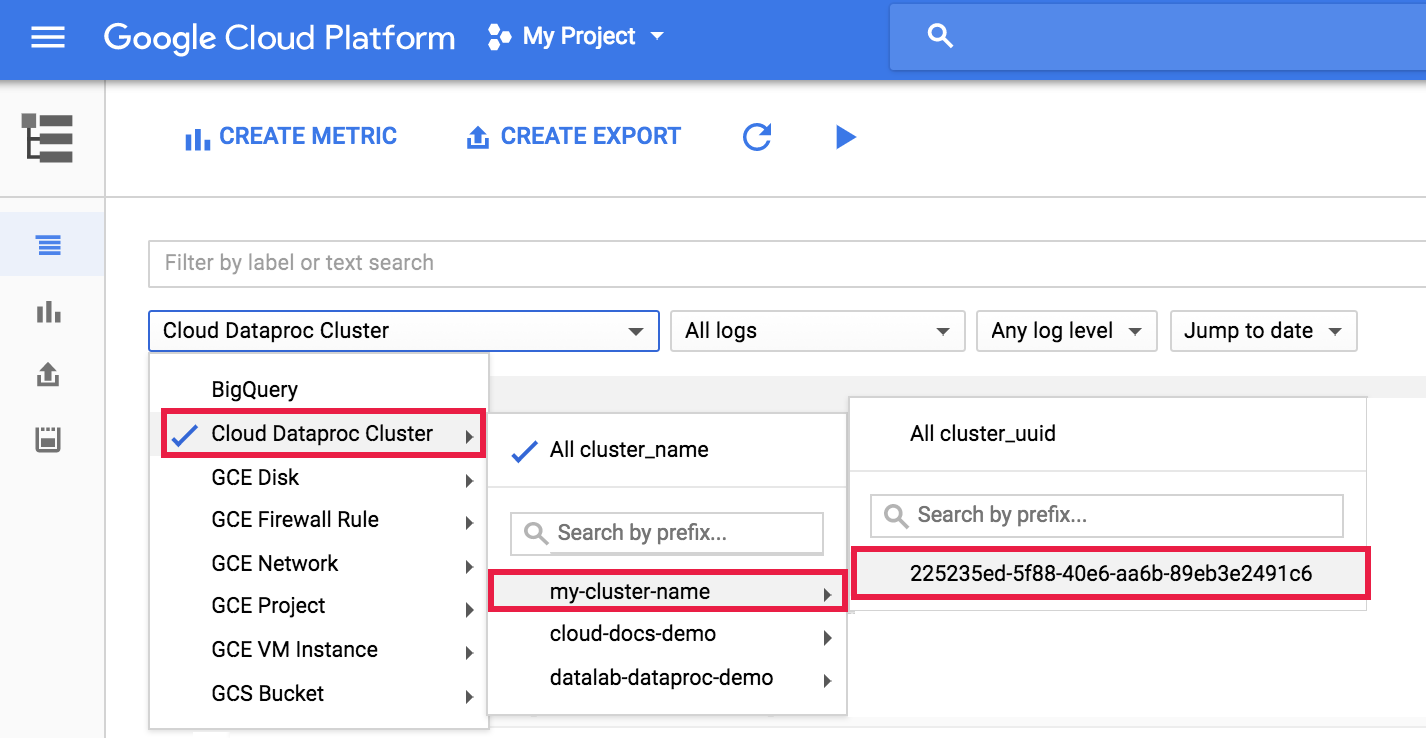
次にログセレクタを使用して google.dataproc.agent ログを選択します。
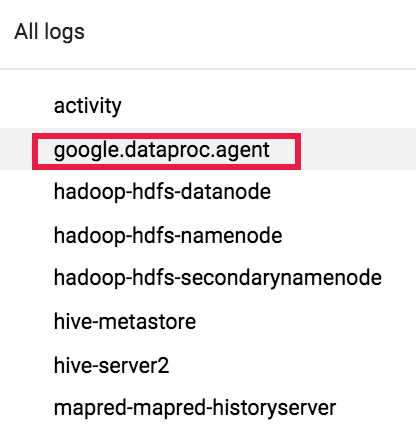
Logging でジョブログを表示する
ジョブが失敗した場合、Logging のジョブログにアクセスできます。
誰がジョブを送信したかを判別する
ジョブの詳細を検索すると、submittedBy 項目に誰がジョブを送信したかが表示されます。たとえば、このジョブ出力には、user@domain がクラスタにサンプル ジョブを送信したことが示されています。
... placement: clusterName: cluster-name clusterUuid: cluster-uuid reference: jobId: job-uuid projectId: project status: state: DONE stateStartTime: '2018-11-01T00:53:37.599Z' statusHistory: - state: PENDING stateStartTime: '2018-11-01T00:33:41.387Z' - state: SETUP_DONE stateStartTime: '2018-11-01T00:33:41.765Z' - details: Agent reported job success state: RUNNING stateStartTime: '2018-11-01T00:33:42.146Z' submittedBy: user@domain
エラー メッセージ
タスクが取得されませんでした
これは、マスターノードの Dataproc エージェントがコントロール プレーンからタスクを取得できなかったことを示します。これは、多くの場合、メモリ不足(OOM)またはネットワークの問題が原因で発生します。以前はジョブが正常に実行されており、その後ネットワーク構成を変更していない場合、OOM が原因である可能性が高いです。多くの場合、多数の同時実行ジョブ、またはドライバが大量のメモリを消費するジョブ(大規模なデータセットをメモリに読み込むジョブなど)を送信すると、このような状態になります。
マスターノードにアクティブなエージェントが見つかりませんでした
これは、マスターノードの Dataproc エージェントがアクティブではなく、新しいジョブを受け入れることができないことを示します。これは、多くの場合、メモリ不足(OOM)やネットワークの問題、またはマスターノード VM が異常な場合に発生します。以前はジョブが正常に実行されており、その後ネットワーク構成を変更していない場合、OOM が原因である可能性が高いです。多くの場合、多数の同時実行ジョブ、またはドライバが大量のメモリを消費するジョブ(大規模なデータセットをメモリに読み込むジョブなど)を送信すると、このような状態になります。この問題は、Dataproc クラスタを再起動(停止してから開始)するか、後でジョブの送信を再試行することで解決できます。注: クラスタを停止すると、実行中のすべてのジョブは失敗します。
タスクが見つかりませんでした
このエラーは、ジョブの実行中にクラスタが削除されたことを示します。次の操作を行うと、削除を実行したプリンシパルを特定し、ジョブの実行中にクラスタの削除が発生したことを確認できます。
Dataproc 監査ログを表示して、削除オペレーションを実行したプリンシパルを確認します。
Logging または gcloud CLI を使用して、YARN アプリケーションの最後の既知の状態が RUNNING であることを確認します。
- Logging で次のフィルタを使用します。
resource.type="cloud_dataproc_cluster" resource.labels.cluster_name="CLUSTER_NAME" resource.labels.cluster_uuid="CLUSTER_UUID" "YARN_APPLICATION_ID State change from"
gcloud dataproc jobs describe job-id --region=REGIONを実行し、出力でyarnApplications: > STATEを確認します。
Task not found エラーを回避するには、自動化を使用して、実行中のすべてのジョブが完了する前にクラスタが削除されないようにします。