概览
Dataproc Persistent History Server (PHS) 提供了一个网页界面,可查看在活跃或已删除的 Dataproc 集群上运行的作业的作业历史记录。它适用于 Dataproc 映像版本 1.5 及更高版本,在单节点 Dataproc 集群上运行。它为以下文件和数据提供了网页界面:
MapReduce 和 Spark 作业历史记录文件
Flink 作业历史记录文件(如需创建用于运行 Flink 作业的 Dataproc 集群,请参阅 Dataproc 可选 Flink 组件)
由 YARN Timeline Service v2 创建并存储在 Bigtable 实例中的应用时间轴数据文件。
YARN 汇总日志
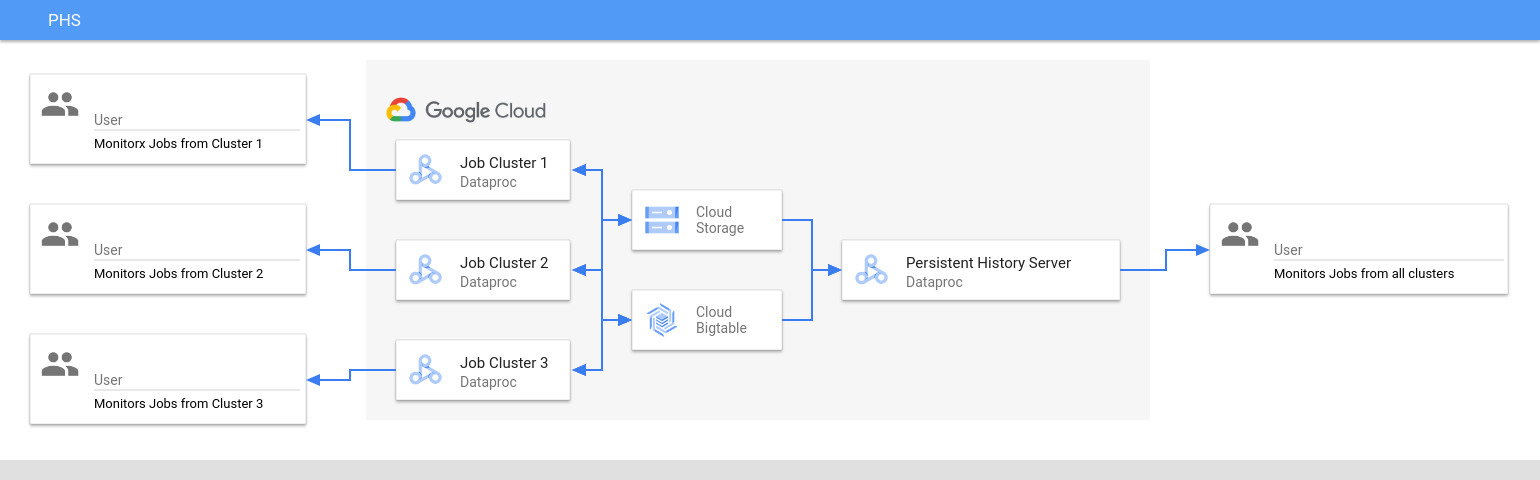
Persistent History Server 会访问并显示在 Dataproc 作业集群的生命周期内写入 Cloud Storage 的 Spark 和 MapReduce 作业历史记录文件、Flink 作业历史记录文件以及 YARN 日志文件。
限制
PHS 集群映像版本和 Dataproc 作业集群映像版本必须一致。例如,您可以使用 Dataproc 2.0 映像版本 PHS 集群查看在位于 PHS 集群所在项目中的 Dataproc 2.0 映像版本作业集群上运行的作业的作业历史记录文件。
创建 Dataproc PHS 集群
您可以在本地终端或 Cloud Shell 中运行以下 gcloud dataproc clusters create 命令并使用以下标志和集群属性来创建 Dataproc Persistent History Server 单节点集群。
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME:指定 PHS 集群的名称。
- PROJECT:指定要与 PHS 集群关联的项目。此项目应与运行作业的集群所关联的项目相同(请参阅创建 Dataproc 作业集群)。
- REGION:指定 PHS 集群所在的 Compute Engine 区域。
--single-node:PHS 集群是 Dataproc 单节点集群。--enable-component-gateway:此标志可在 PHS 集群上启用组件网关网页界面。- COMPONENT:使用此标志可在集群上安装一个或多个可选组件。您必须指定
FLINK可选组件,才能在 PHS 集群上运行 Flink HistoryServer Web 服务,以查看 Flink 作业历史记录文件。 - PROPERTIES。指定一个或多个集群属性。
(可选)添加 --image-version 标志以指定 PHS 集群映像版本。PHS 映像版本必须与 Dataproc 作业集群的映像版本一致。请参阅限制。
注意:
- 本部分中的属性值示例使用“*”通配符,以允许 PHS 匹配由不同作业集群写入的指定存储桶中的多个目录(但请参阅通配符效率注意事项)。
- 以下示例中显示了不同的
--properties标志,以提高可读性。使用gcloud dataproc clusters create创建 Dataproc on Compute Engine 集群时,建议的实践是使用一个--properties标志来指定以英文逗号分隔的属性列表(请参阅集群属性格式)。
属性:
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs:添加此属性可指定 PHS 访问作业集群写入的 YARN 日志所在的 Cloud Storage 位置。spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history:添加此属性可启用永久性 Spark 作业历史记录。此属性用于指定 PHS 访问作业集群写入的 Spark 作业历史记录日志所在的位置。在 Dataproc 2.0+ 集群中,还必须设置以下两个属性以启用 PHS Spark 历史记录日志(请参阅 Spark 历史记录服务器配置选项)。
spark.history.custom.executor.log.url值是字面量值,包含由永久性历史记录服务器设置的变量的 {{PLACEHOLDERS}}。这些变量不是由用户设置的;传入如下所示的属性值。--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done:添加此属性可启用永久性 MapReduce 作业历史记录。此属性用于指定 PHS 访问作业集群写入的 MapReduce 作业历史记录日志所在的 Cloud Storage 位置。dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id:配置 Yarn Timeline Service v2 后,添加此属性以使用 PHS 集群在 YARN Application Timeline Service V2 和 Tez 网页界面上查看时间轴数据(请参阅组件网关网页界面)。flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs:使用此属性可将 FlinkHistoryServer配置为监控以英文逗号分隔的目录列表。
属性示例:
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
创建 Dataproc 作业集群
您可以在本地终端或 Cloud Shell 中运行以下命令,以创建用于运行作业并将作业历史记录文件写入 Persistent History Server (PHS) 的 Dataproc 作业集群。
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME:指定作业集群的名称。
- PROJECT:指定与作业集群关联的项目。
- REGION:指定作业集群所在的 Compute Engine 区域。
--enable-component-gateway:此标志可在作业集群上启用组件网关网页界面。- COMPONENT:使用此标志可在集群上安装一个或多个可选组件。指定
FLINK可选组件,以在集群上运行 Flink 作业。 PROPERTIES:添加以下一个或多个集群属性,以设置与 PHS 相关的非默认 Cloud Storage 位置和其他作业集群属性。
注意:
- 本部分中的属性值示例使用“*”通配符,以允许 PHS 匹配由不同作业集群写入的指定存储桶中的多个目录(但请参阅通配符效率注意事项)。
- 以下示例中显示了不同的
--properties标志,以提高可读性。使用gcloud dataproc clusters create创建 Dataproc on Compute Engine 集群时,建议的实践是使用一个--properties标志来指定以英文逗号分隔的属性列表(请参阅集群属性格式)。
属性:
yarn:yarn.nodemanager.remote-app-log-dir:默认情况下,汇总的 YARN 日志会在 Dataproc 作业集群上启用,并写入集群临时存储桶。添加此属性可指定不同的 Cloud Storage 位置,集群会在该位置写入汇总日志,以供 Persistent History Server 访问。--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectory和spark:spark.eventLog.dir:默认情况下,Spark 作业历史记录文件会保存在集群temp bucket的/spark-job-history目录中。您可以添加这些属性,为这些文件指定不同的 Cloud Storage 位置。如果同时使用这两个属性,它们必须指向同一存储桶中的目录。--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-dir和mapred:mapreduce.jobhistory.intermediate-done-dir:默认情况下,MapReduce 作业历史记录文件会保存在集群temp bucket的/mapreduce-job-history/done和/mapreduce-job-history/intermediate-done目录中。中间mapreduce.jobhistory.intermediate-done-dir位置是临时存储;MapReduce 作业完成后,中间文件会移至mapreduce.jobhistory.done-dir位置。您可以添加这些属性,为这些文件指定不同的 Cloud Storage 位置。如果同时使用这两个属性,它们必须指向同一存储桶中的目录。--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.type:此属性适用于使用 Cloud Storage 连接器版本2.0.x(2.0和2.1映像版本集群的默认连接器版本)的2.0和2.1映像版本集群。此属性控制 Spark 作业如何将数据发送到 Cloud Storage。默认设置为BASIC,系统在作业完成后将数据发送到 Cloud Storage。如果设置为FLUSHABLE_COMPOSITE,则系统会在作业运行期间按照spark:spark.history.fs.gs.outputstream.sync.min.interval.ms的设置,定期将数据复制到 Cloud Storage。--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
spark:spark.history.fs.gs.outputstream.sync.min.interval.ms:此属性适用于使用 Cloud Storage 连接器版本2.0.x(2.0和2.1映像版本集群的默认连接器版本)的2.0和2.1映像版本集群。当spark:spark.history.fs.gs.outputstream.type设置为FLUSHABLE_COMPOSITE时,此属性用于控制数据传输到 Cloud Storage 的频率(以毫秒为单位)。默认时间间隔为5000ms。您可以指定毫秒时间间隔值(添加或不添加ms后缀)。--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=INTERVALms
spark:spark.history.fs.gs.outputstream.sync.min.interval:此属性适用于使用 Cloud Storage 连接器版本3.0.x(2.2映像版本集群的默认连接器版本)的2.2及更高映像版本的集群。此属性取代了之前的spark:spark.history.fs.gs.outputstream.sync.min.interval.ms属性,并支持带时间后缀的值,例如ms、s和m。当spark:spark.history.fs.gs.outputstream.type设置为FLUSHABLE_COMPOSITE时,此属性用于控制数据传输到 Cloud Storage 的频率。--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval=INTERVAL
dataproc:yarn.atsv2.bigtable.instance:配置 Yarn Timeline Service v2 后,添加此属性以将 YARN 时间轴数据写入指定的 Bigtable 实例,以便在 PHS 集群 YARN Application Timeline Service V2 和 Tez 网页界面上进行查看。注意:如果 Bigtable 实例不存在,集群创建会失败。--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir:Flink JobManager 通过将已归档的作业信息上传到文件系统目录,来归档已完成的 Flink 作业。使用此属性可在flink-conf.yaml中设置归档目录。--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
将 PHS 与 Spark 批处理工作负载搭配使用
如需将 Persistent History Server 与 Dataproc Serverless for Spark 批量工作负载搭配使用,请执行以下操作:
在提交 Spark 批量工作负载时选择或指定 PHS 集群。
将 PHS 与 Dataproc on Google Kubernetes Engine 搭配使用
如需将 Persistent History Server 与 Dataproc on GKE 搭配使用,请执行以下操作:
在创建 Dataproc on GKE 虚拟集群时选择或指定 PHS 集群。
组件网关网页界面
在 API 控制台的 Dataproc 集群页面中,点击 PHS 集群名称以打开集群详情页面。在网页界面标签页下,选择组件网关链接,以打开在 PHS 集群上运行的网页界面。

Spark 历史记录服务器网页界面
以下屏幕截图展示了 Spark 历史记录服务器网页界面,其中显示了设置作业集群的 spark.history.fs.logDirectory 和 spark:spark.eventLog.dir 以及 PHS 集群的 spark.history.fs.logDirectory 位置后,在 job-cluster-1 和 job-cluster-2 上运行的 Spark 作业的链接:
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |
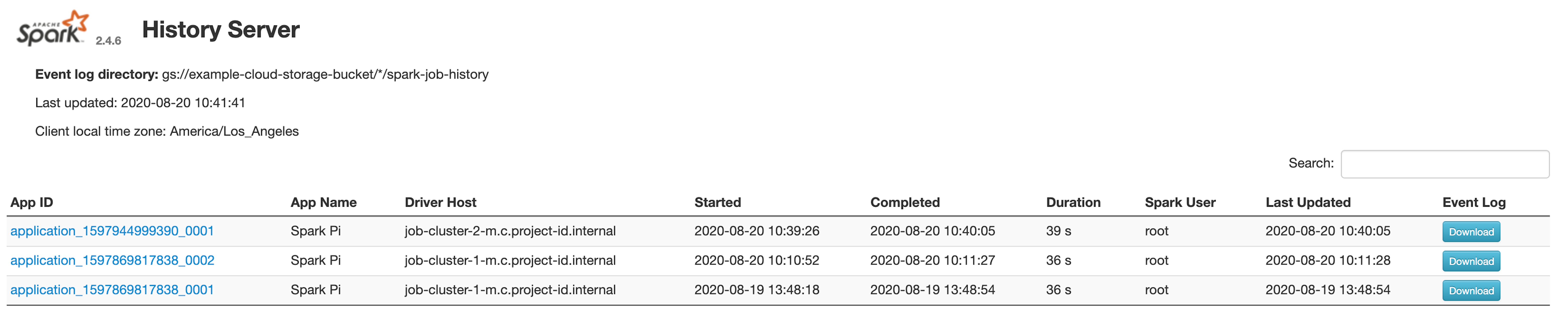
应用名称搜索
您可以在搜索框中输入应用名称,以在 Spark 历史记录服务器网页界面中按应用名称列出作业。应用名称可以通过以下方式之一进行设置(按优先级列出):
- 创建 Spark 上下文时在应用代码内设置
- 提交作业时由 spark.app.name 属性设置
- 由 Dataproc 设置为作业的完整 REST 资源名称 (
projects/project-id/regions/region/jobs/job-id)
用户可以在搜索框中输入应用或资源名称,以查找和列出作业。
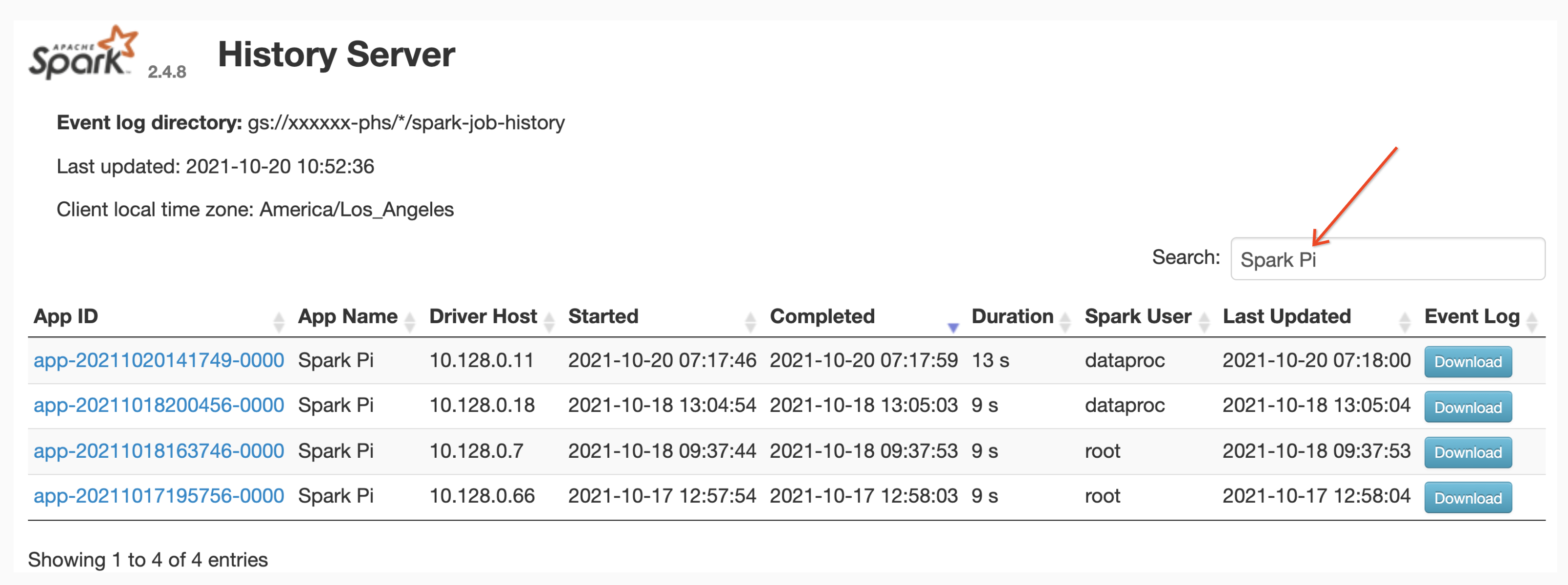
事件日志
Spark 历史记录服务器网页界面提供了一个事件日志按钮,您可以点击该按钮来下载 Spark 事件日志。这些日志适用于检查 Spark 应用的生命周期。
Spark 作业
Spark 应用分为多个作业,这些作业进一步分为多个阶段。每个阶段可能有多个任务,这些任务在执行程序节点(工作器)上运行。
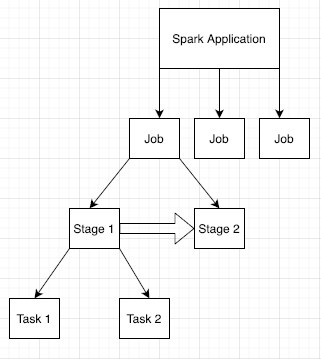
点击网页界面中的 Spark 应用 ID 以打开“Spark 作业”页面,该页面提供了应用中的作业的事件时间轴和摘要。
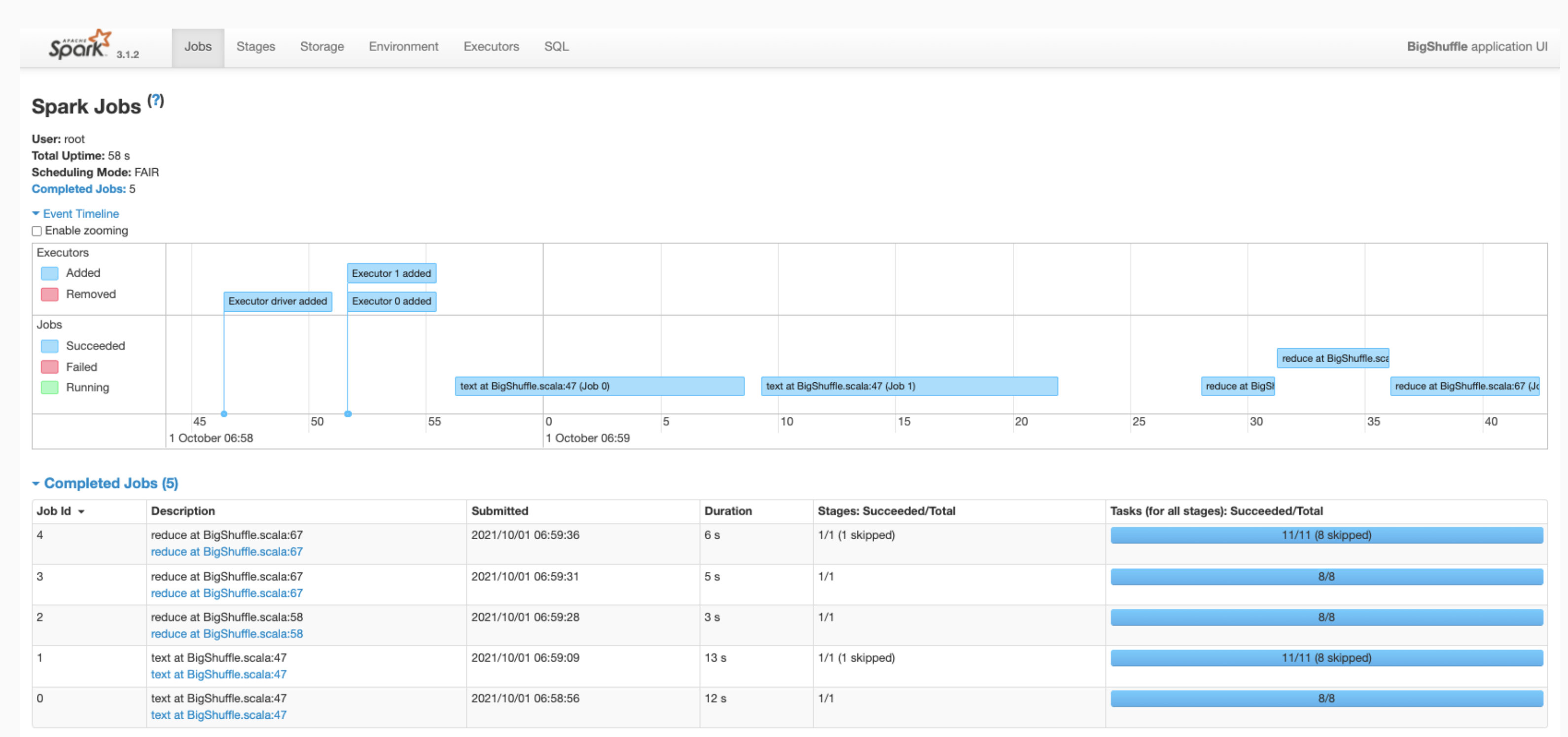
点击某个作业即可打开“作业详情”页面,其中包含有向无环图 (DAG) 以及作业阶段的摘要。
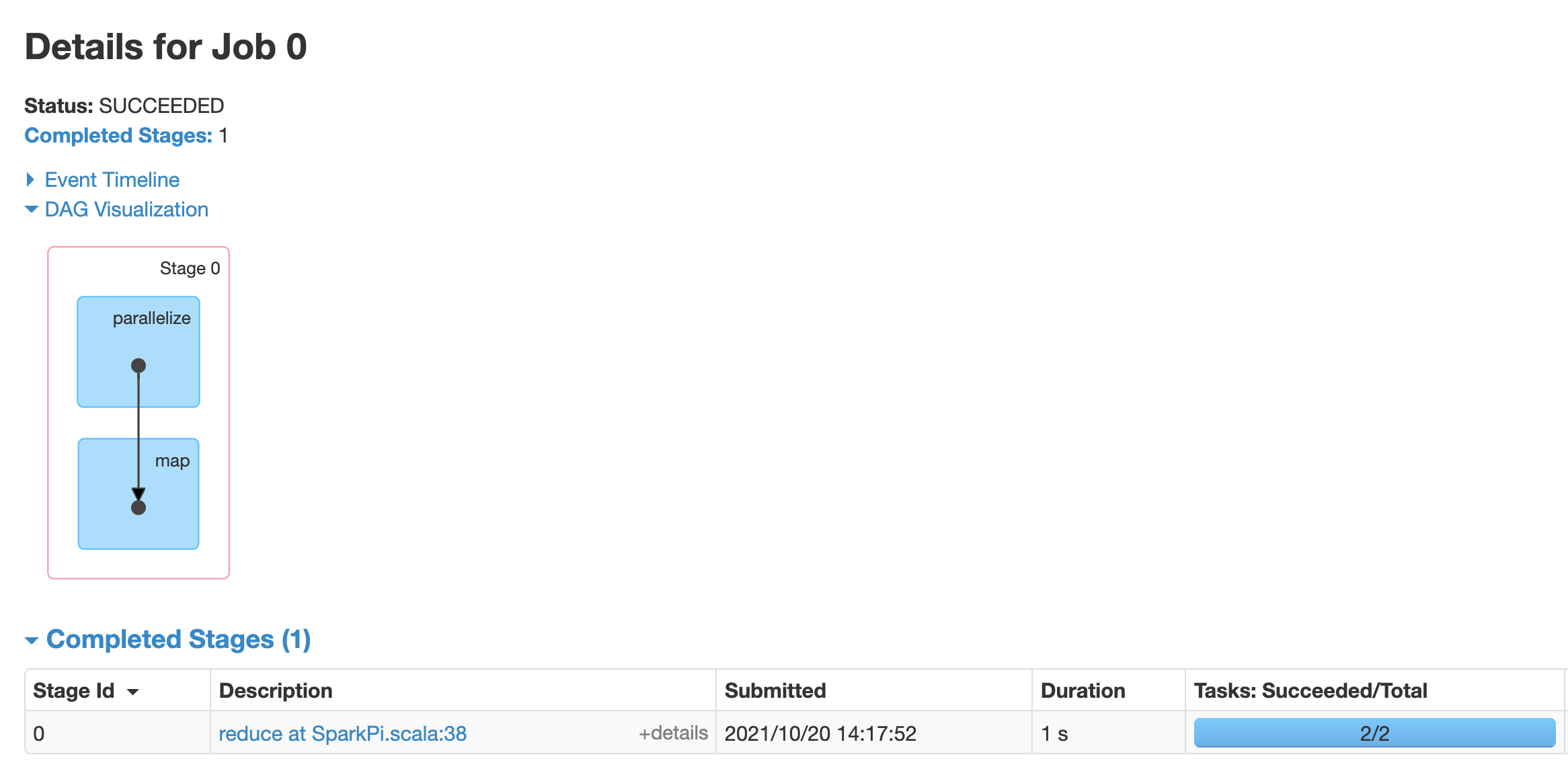
点击阶段或使用“阶段”标签页选择某个阶段即可打开“阶段详情”页面。
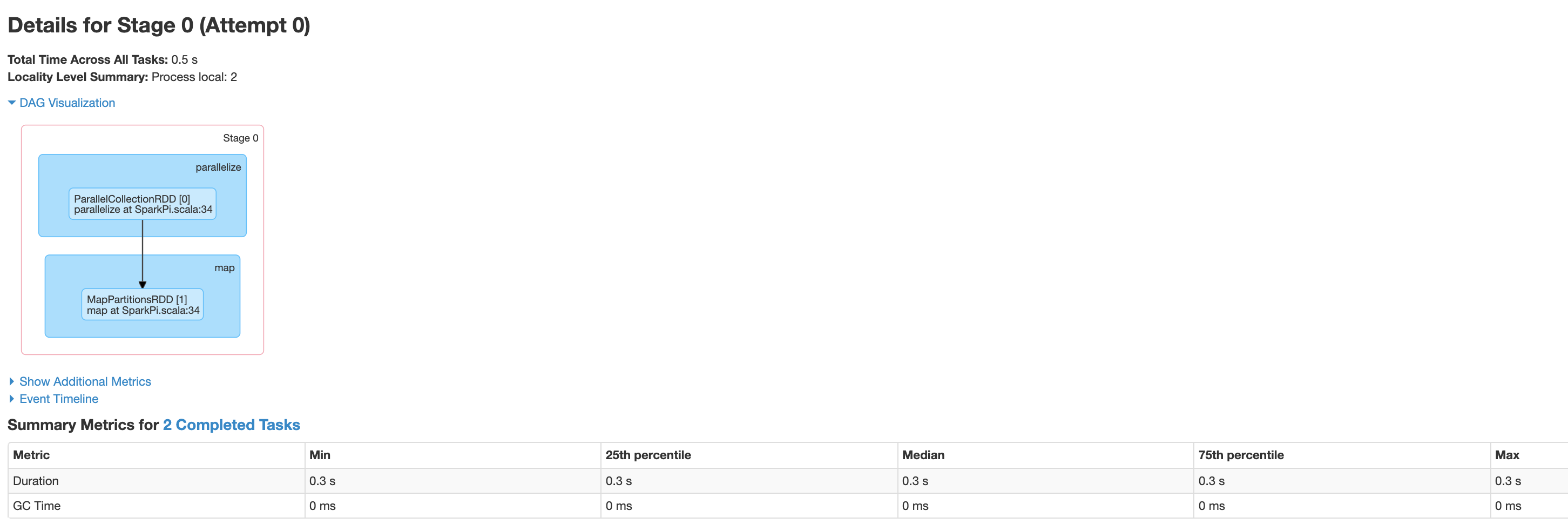
“阶段详情”包括阶段内任务的 DAG 可视化、事件时间轴和指标。您可以使用此页面排查与绞杀任务、调度程序延迟时间和内存不足错误相关的问题。DAG 可视化工具会显示从中派生阶段的代码行,从而帮助您追踪发生问题的代码。
点击“执行器”标签页,以了解 Spark 应用的驱动程序和执行器节点。
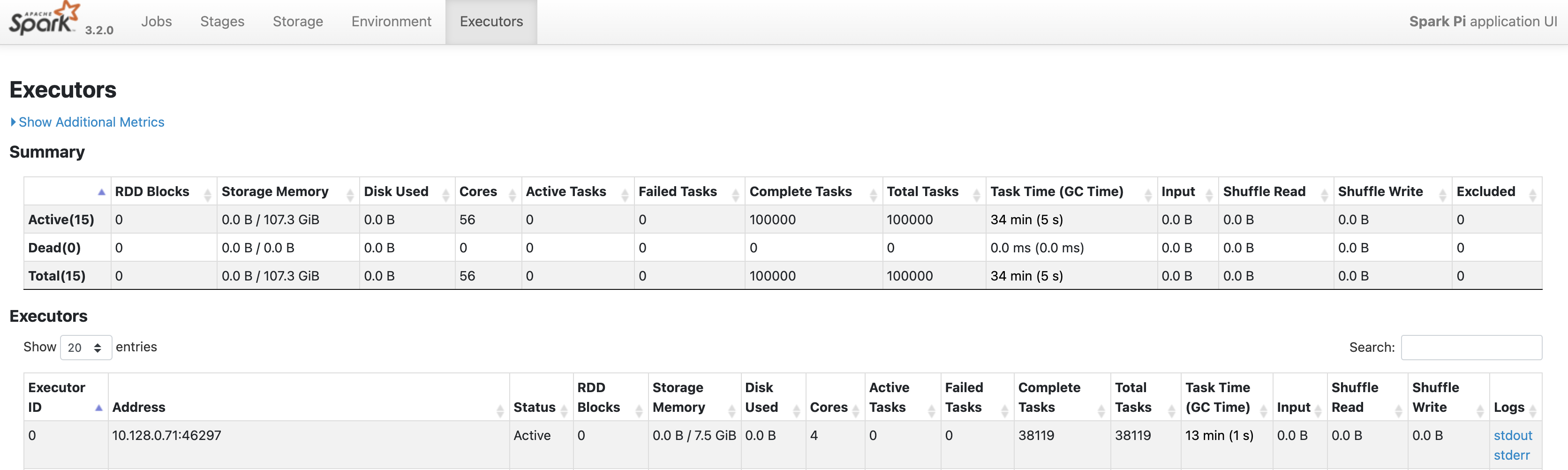
本页面上的重要信息包括核心数和每个执行程序上运行的任务数。
Tez 网页界面
Tez 是 Dataproc 上的 Hive 和 Pig 的默认执行引擎。在 Dataproc 作业集群上提交 Hive 作业会启动 Tez 应用。
如果您配置了 Yarn Timeline Service v2,并在创建 PHS 和 Dataproc 作业集群时设置了 dataproc:yarn.atsv2.bigtable.instance 属性,则 YARN 会将生成的 Hive 和 Pig 作业时间轴数据写入指定的 Bigtable 实例,以便在 PHS 服务器上运行的 Tez 网页界面上进行检索和显示。

YARN Application Timeline V2 网页界面
如果您配置了 Yarn Timeline Service v2,并在创建 PHS 和 Dataproc 作业集群时设置了 dataproc:yarn.atsv2.bigtable.instance 属性,则 YARN 会将生成的作业时间轴数据写入指定的 Bigtable 实例,以便在 PHS 服务器上运行的 YARN Application Timeline Service 网页界面上进行检索和显示。Dataproc 作业列在网页界面中的 Flow Activity 标签页下。
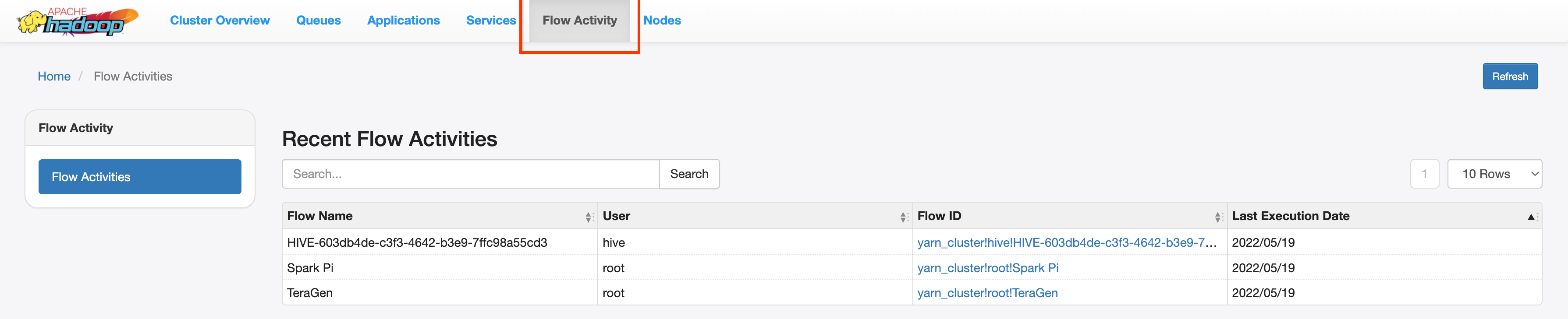
配置 Yarn Timeline Service v2
如需配置 Yarn Timeline Service v2,请设置 Bigtable 实例,如有需要,检查服务账号角色,如下所示:
如有需要,检查服务账号角色。Dataproc 集群虚拟机使用的默认虚拟机服务账号具有为 YARN Timeline Service 创建和配置 Bigtable 实例所需的权限。如果您使用自定义虚拟机服务账号创建作业或 PHS 集群,则该账号必须具有 Bigtable
Administrator或Bigtable User角色。
必需的表架构
Dataproc PHS 对 YARN Timeline Service v2 的支持需要在 Bigtable 实例中创建的特定架构。在创建作业集群或 PHS 集群时,如果将 dataproc:yarn.atsv2.bigtable.instance 属性设置为指向 Bigtable 实例,Dataproc 会创建所需的架构。
以下是必需的 Bigtable 实例架构:
| 表 | 列族 |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Bigtable 垃圾回收
您可以为 ATSv2 表配置基于存在时间的 Bigtable 垃圾回收:
安装 cbt(包括创建
.cbrtc file)。创建 ATSv2 基于年龄的垃圾回收政策:
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
注意:
NUMBER_OF_DAYS:天数上限为 30d。