Visão geral
O servidor de histórico permanente (PHS) do Dataproc oferece interfaces da Web para visualizar o histórico de jobs executados em clusters ativos e excluídos do Dataproc. Ele está disponível na versão de imagem 1.5 do Dataproc e posterior, e é executado em um cluster de nó único do Dataproc. Ele fornece interfaces da Web para os seguintes arquivos e dados:
Arquivos de histórico de jobs do MapReduce e do Spark
Arquivos de histórico de jobs do Flink. Consulte o componente opcional Flink do Dataproc para criar um cluster do Dataproc e executar jobs do Flink.
Arquivos de dados da linha do tempo do aplicativo criados pelo YARN Timeline Service v2 e armazenados em uma instância do Bigtable.
Registros de agregação do YARN
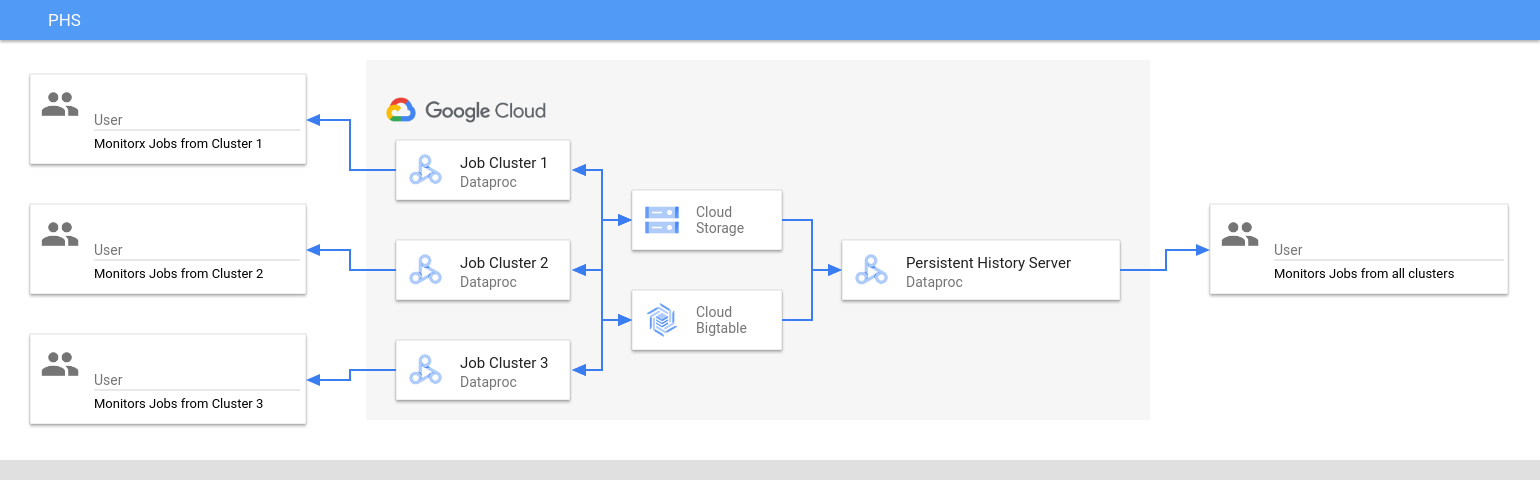
O servidor de histórico permanente acessa e mostra arquivos de histórico de jobs do Spark e do MapReduce, arquivos de histórico de jobs do Flink e arquivos de registros do YARN gravados no Cloud Storage durante o ciclo de vida dos clusters de jobs do Dataproc.
Limitações
A versão da imagem do cluster do PHS e a versão da imagem dos clusters de jobs do Dataproc precisam ser iguais. Por exemplo, é possível usar um cluster PHS da versão 2.0 da imagem do Dataproc para ver os arquivos de histórico de jobs executados em clusters de jobs da versão 2.0 da imagem do Dataproc localizados no projeto em que o cluster PHS está localizado.
Um cluster do PHS não é compatível com Kerberos e autenticação pessoal.
Criar um cluster do Dataproc PHS
É possível executar o seguinte comando
gcloud dataproc clusters create
em um terminal local ou no
Cloud Shell com as seguintes flags e
propriedades do cluster
para criar um cluster de nó único do servidor de histórico permanente do Dataproc.
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --single-node \ --enable-component-gateway \ --optional-components=COMPONENT \ --properties=PROPERTIES
- CLUSTER_NAME: especifique o nome do cluster do PHS.
- PROJECT: especifique o projeto a ser associado ao cluster do PHS. Esse projeto precisa ser o mesmo associado ao cluster que executa seus jobs. Consulte Criar um cluster de jobs do Dataproc.
- REGION: especifique uma região do Compute Engine em que o cluster do PHS será localizado.
--single-node: um cluster de PHS é um cluster de nó único do Dataproc.--enable-component-gateway: essa flag ativa as interfaces da Web do Gateway de componentes no cluster do PHS.- COMPONENT: use essa flag para instalar um ou mais
componentes opcionais
no cluster. Especifique o componente opcional
FLINKpara executar o serviço da Web do Flink HistoryServer no cluster do PHS e conferir os arquivos de histórico de jobs do Flink. - PROPERTIES. Especifique uma ou mais propriedades do cluster.
Se quiser, adicione a flag --image-version para especificar a versão da imagem do cluster do PHS. A versão da imagem do PHS precisa corresponder à versão da imagem dos clusters de job do Dataproc. Consulte Limitações.
Observações:
- Os exemplos de valores de propriedades nesta seção usam um caractere curinga "*" para permitir que o PHS corresponda a vários diretórios no bucket especificado gravado por diferentes clusters de jobs (mas consulte Considerações sobre a eficiência dos caracteres curinga).
- As flags
--propertiesseparadas são mostradas nos exemplos a seguir para facilitar a leitura. A prática recomendada ao usargcloud dataproc clusters createpara criar um cluster do Dataproc no Compute Engine é usar uma flag--propertiespara especificar uma lista de propriedades separadas por vírgulas (consulte formatação de propriedades do cluster).
Propriedades:
yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/*/yarn-logs: adicione essa propriedade para especificar o local do Cloud Storage em que o PHS vai acessar os registros do YARN gravados por clusters de jobs.spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history: adicione essa propriedade para ativar o histórico permanente de jobs do Spark. Essa propriedade especifica o local em que o PHS vai acessar os registros do histórico de jobs do Spark gravados por clusters de jobs.Nos clusters do Dataproc 2.0+, as duas propriedades a seguir também precisam ser definidas para ativar os registros de histórico do PHS Spark. Consulte Opções de configuração do servidor de histórico do Spark.
spark.history.custom.executor.log.urlé um valor literal que contém {{PLACEHOLDERS}} para variáveis que serão definidas pelo servidor de histórico permanente. Essas variáveis não são definidas pelos usuários. Transmita o valor da propriedade conforme mostrado.--properties=spark:spark.history.custom.executor.log.url.applyIncompleteApplication=false
--properties=spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}}mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done: adicione essa propriedade para ativar o histórico permanente de jobs do MapReduce. Essa propriedade especifica o local do Cloud Storage em que o PHS acessará os registros do histórico de jobs do MapReduce gravados por clusters de jobs.dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id: depois de configurar o serviço de linha do tempo do Yarn v2, adicione essa propriedade para usar o cluster do PHS e ver os dados da linha do tempo nas interfaces da Web do YARN Application Timeline Service V2 e do Tez. Consulte Interfaces da Web do Component Gateway.flink:historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs: use essa propriedade para configurar oHistoryServerdo Flink e monitorar uma lista de diretórios separada por vírgulas.
Exemplos de propriedades:
--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/*/spark-job-history
--properties=mapred:mapreduce.jobhistory.read-only.dir-pattern=gs://bucket-name/*/mapreduce-job-history/done
--properties=flink:flink.historyserver.archive.fs.dir=gs://bucket-name/*/flink-job-history/completed-jobs
Criar um cluster de job do Dataproc
É possível executar o comando a seguir em um terminal local ou no Cloud Shell para criar um cluster de jobs do Dataproc que executa jobs e grava arquivos de histórico de jobs em um servidor de histórico permanente (PHS, na sigla em inglês).
gcloud dataproc clusters create CLUSTER_NAME \ --project=PROJECT \ --region=REGION \ --optional-components=COMPONENT \ --enable-component-gateway \ --properties=PROPERTIES \ other args ...
- CLUSTER_NAME: especifique o nome do cluster de jobs.
- PROJECT: especifique o projeto associado ao cluster de jobs.
- REGION: especifique a região do Compute Engine em que o cluster de jobs vai estar localizado.
--enable-component-gateway: essa flag ativa as interfaces da Web do Gateway de componentes no cluster de jobs.- COMPONENT: use essa flag para instalar um ou mais
componentes opcionais
no cluster. Especifique o componente opcional
FLINKpara executar jobs do Flink no cluster. PROPERTIES: adicione uma ou mais das seguintes propriedades do cluster para definir locais não padrão do Cloud Storage relacionados ao PHS e outras propriedades do cluster de jobs.
Observações:
- Os exemplos de valores de propriedades nesta seção usam um caractere curinga "*" para permitir que o PHS corresponda a vários diretórios no bucket especificado gravado por diferentes clusters de jobs (mas consulte Considerações sobre a eficiência dos caracteres curinga).
- As flags
--propertiesseparadas são mostradas nos exemplos a seguir para facilitar a leitura. A prática recomendada ao usargcloud dataproc clusters createpara criar um cluster do Dataproc no Compute Engine é usar uma flag--propertiespara especificar uma lista de propriedades separadas por vírgulas (consulte formatação de propriedades do cluster).
Propriedades:
yarn:yarn.nodemanager.remote-app-log-dir: por padrão, os registros agregados do YARN são ativados em clusters de jobs do Dataproc e gravados no bucket temporário do cluster. Adicione essa propriedade para especificar um local diferente do Cloud Storage em que o cluster vai gravar registros de agregação para acesso pelo servidor de histórico persistente.--properties=yarn:yarn.nodemanager.remote-app-log-dir=gs://bucket-name/directory-name/yarn-logs
spark:spark.history.fs.logDirectoryespark:spark.eventLog.dir: por padrão, os arquivos de histórico de jobs do Spark são salvos no clustertemp bucketno diretório/spark-job-history. É possível adicionar essas propriedades para especificar diferentes locais do Cloud Storage para esses arquivos. Se ambas as propriedades forem usadas, elas precisarão apontar para diretórios no mesmo bucket.--properties=spark:spark.history.fs.logDirectory=gs://bucket-name/directory-name/spark-job-history
--properties=spark:spark.eventLog.dir=gs://bucket-name/directory-name/spark-job-history
mapred:mapreduce.jobhistory.done-diremapred:mapreduce.jobhistory.intermediate-done-dir: por padrão, os arquivos de histórico de jobs do MapReduce são salvos no clustertemp bucketnos diretórios/mapreduce-job-history/donee/mapreduce-job-history/intermediate-done. O local intermediáriomapreduce.jobhistory.intermediate-done-diré o armazenamento temporário. Os arquivos intermediários são movidos para o localmapreduce.jobhistory.done-dirquando o job do MapReduce é concluído. É possível adicionar essas propriedades para especificar diferentes locais do Cloud Storage para esses arquivos. Se as duas propriedades forem usadas, elas precisarão apontar para diretórios no mesmo bucket.--properties=mapred:mapreduce.jobhistory.done-dir=gs://bucket-name/directory-name/mapreduce-job-history/done
--properties=mapred:mapreduce.jobhistory.intermediate-done-dir=gs://bucket-name/directory-name/mapreduce-job-history/intermediate-done
spark:spark.history.fs.gs.outputstream.type: essa propriedade se aplica a clusters de versão de imagem2.0e2.1que usam a versão2.0.xdo conector do Cloud Storage (a versão padrão do conector para clusters de versão de imagem2.0e2.1). Ele controla como os jobs do Spark enviam dados para o Cloud Storage. A configuração padrão éBASIC, que envia dados para o Cloud Storage após a conclusão do job. Quando definido comoFLUSHABLE_COMPOSITE, os dados são copiados para o Cloud Storage em intervalos regulares enquanto o job está em execução, conforme definido porspark:spark.history.fs.gs.outputstream.sync.min.interval.ms.--properties=spark:spark.history.fs.gs.outputstream.type=FLUSHABLE_COMPOSITE
spark:spark.history.fs.gs.outputstream.sync.min.interval.ms: Essa propriedade se aplica a clusters de versão de imagem2.0e2.1que usam a versão2.0.xdo conector do Cloud Storage (a versão padrão do conector para clusters de versão de imagem2.0e2.1). Ele controla a frequência em milissegundos com que os dados são transferidos para o Cloud Storage quandospark:spark.history.fs.gs.outputstream.typeé definido comoFLUSHABLE_COMPOSITE. O intervalo de tempo padrão é5000ms. O valor do intervalo de tempo em milissegundos pode ser especificado com ou sem o sufixoms.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval.ms=INTERVALms
spark:spark.history.fs.gs.outputstream.sync.min.interval: essa propriedade se aplica a clusters de versão de imagem2.2e mais recentes que usam a versão3.0.xdo conector do Cloud Storage (a versão padrão do conector para clusters de versão de imagem2.2). Ela substitui a propriedadespark:spark.history.fs.gs.outputstream.sync.min.interval.msanterior e aceita valores com sufixo de tempo, comoms,sem. Ela controla a frequência com que os dados são transferidos para o Cloud Storage quandospark:spark.history.fs.gs.outputstream.typeestá definido comoFLUSHABLE_COMPOSITE.--properties=spark:spark.history.fs.gs.outputstream.sync.min.interval=INTERVAL
dataproc:yarn.atsv2.bigtable.instance: depois de configurar o serviço de linha do tempo do Yarn v2, adicione essa propriedade para gravar dados da linha do tempo do YARN na instância especificada do Bigtable e visualizar nas interfaces da Web Serviço de linha do tempo do aplicativo YARN V2 e Tez. Observação: a criação do cluster vai falhar se a instância do Bigtable não existir.--properties=dataproc:yarn.atsv2.bigtable.instance=projects/project-id/instance_id/bigtable-instance-id
flink:jobhistory.archive.fs.dir: o Flink JobManager arquiva jobs concluídos do Flink fazendo upload das informações de jobs arquivados para um diretório do sistema de arquivos. Use essa propriedade para definir o diretório de arquivo emflink-conf.yaml.--properties=flink:jobmanager.archive.fs.dir=gs://bucket-name/job-cluster-1/flink-job-history/completed-jobs
Usar o PHS com cargas de trabalho em lote do Spark
Para usar o servidor de histórico permanente com cargas de trabalho em lote do Dataproc sem servidor para Spark:
Selecione ou especifique o cluster do PHS ao enviar uma carga de trabalho em lote do Spark.
Usar o PHS com o Dataproc no Google Kubernetes Engine
Para usar o servidor de histórico permanente com o Dataproc no GKE:
Selecione ou especifique o cluster do PHS ao criar um cluster virtual do Dataproc no GKE.
Interfaces da Web do gateway de componentes
No console do Google Cloud , na página Clusters do Dataproc, clique no nome do cluster de PHS para abrir a página Detalhes do cluster. Na guia Interfaces da Web, selecione os links do gateway de componentes para abrir as interfaces da Web em execução no cluster do PHS.

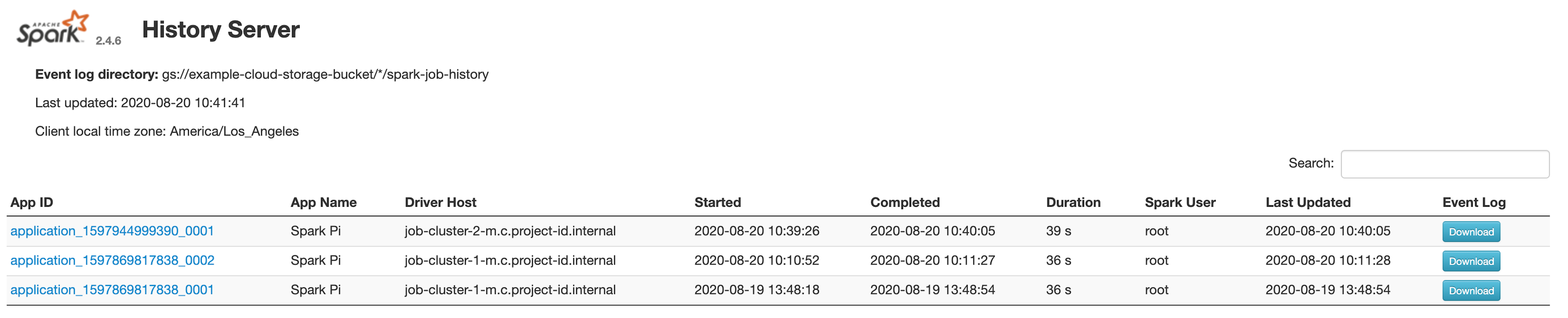
Interface da Web do servidor de histórico do Spark
A captura de tela a seguir mostra a interface da Web do servidor de histórico do Spark exibindo links
para jobs do Spark executados em job-cluster-1 e job-cluster-2 após configurar
spark.history.fs.logDirectory e spark:spark.eventLog.dir de clusters de jobs
e os locais spark.history.fs.logDirectory do cluster de PHS da seguinte maneira:
| job-cluster-1 | gs://example-cloud-storage-bucket/job-cluster-1/spark-job-history |
| job-cluster-2 | gs://example-cloud-storage-bucket/job-cluster-2/spark-job-history |
| phs-cluster | gs://example-cloud-storage-bucket/*/spark-job-history |
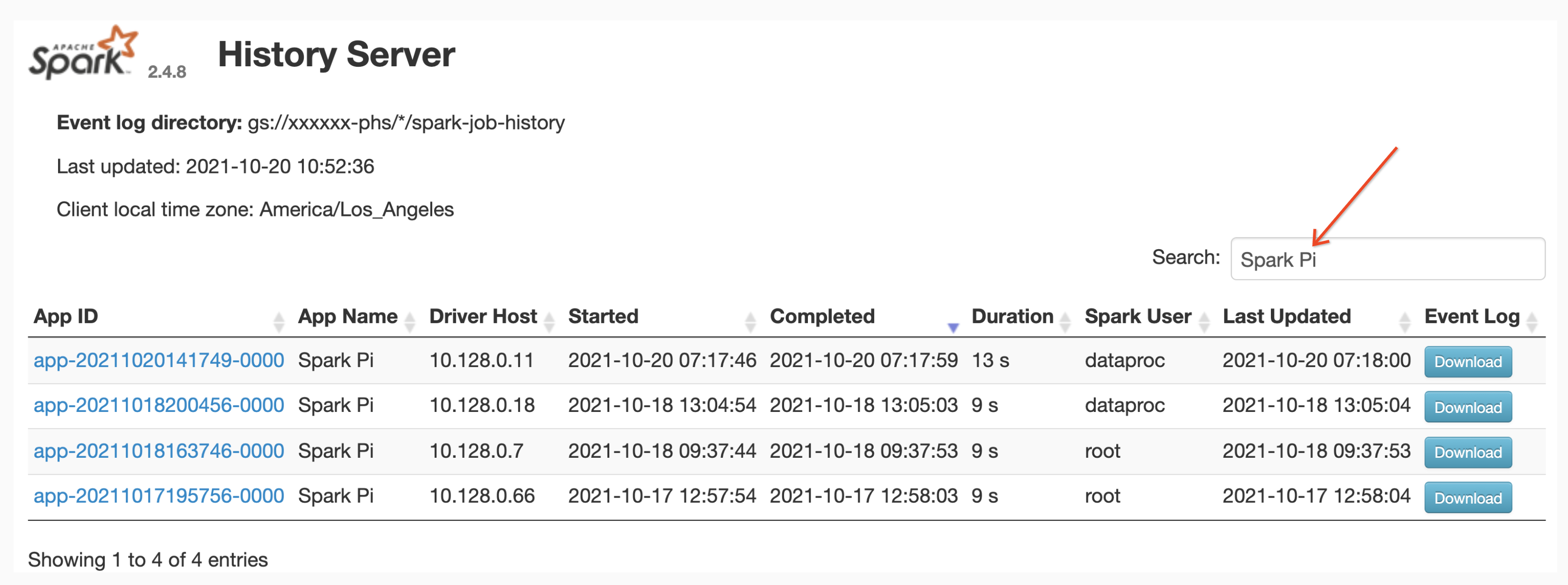
Pesquisa de nomes de apps
É possível listar jobs por nome do app na interface da Web do servidor de histórico do Spark inserindo o nome na caixa de pesquisa. O nome do app pode ser definido das seguintes maneiras (listadas por prioridade):
- Dentro do código do aplicativo ao criar o contexto do Spark.
- Definido pela propriedade spark.app.name quando o job é enviado
- Definido pelo Dataproc para o nome completo do recurso REST do
job (
projects/project-id/regions/region/jobs/job-id)
Os usuários podem inserir um termo de nome de app ou recurso na caixa Pesquisar para encontrar e listar jobs.
Logs de eventos
A interface da Web do servidor de histórico do Spark fornece um botão Log de eventos em que você pode clicar para fazer o download dos logs de eventos do Spark. Esses registros são úteis para examinar o ciclo de vida do aplicativo Spark.
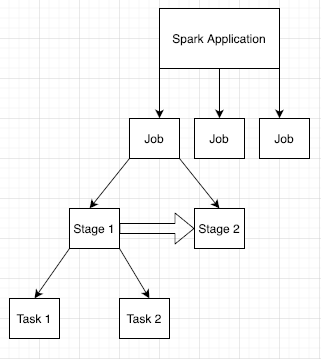
Jobs do Spark
Os aplicativos do Spark são divididos em vários jobs, que são divididos em vários estágios. Cada estágio pode ter várias tarefas, que são executadas em nós de executor (workers).
Clique em um ID do app do Spark na interface da Web para abrir a página de jobs do Spark. Ela fornece um cronograma de eventos e um resumo dos jobs no aplicativo.

Clique em um job para abrir a página "Detalhes do job" com um gráfico acíclico dirigido (DAG, na sigla em inglês) e um resumo dos estágios do job.

Clique em um estágio ou use a guia "Etapas" para selecionar uma etapa que será aberta na página "Detalhes da etapa".
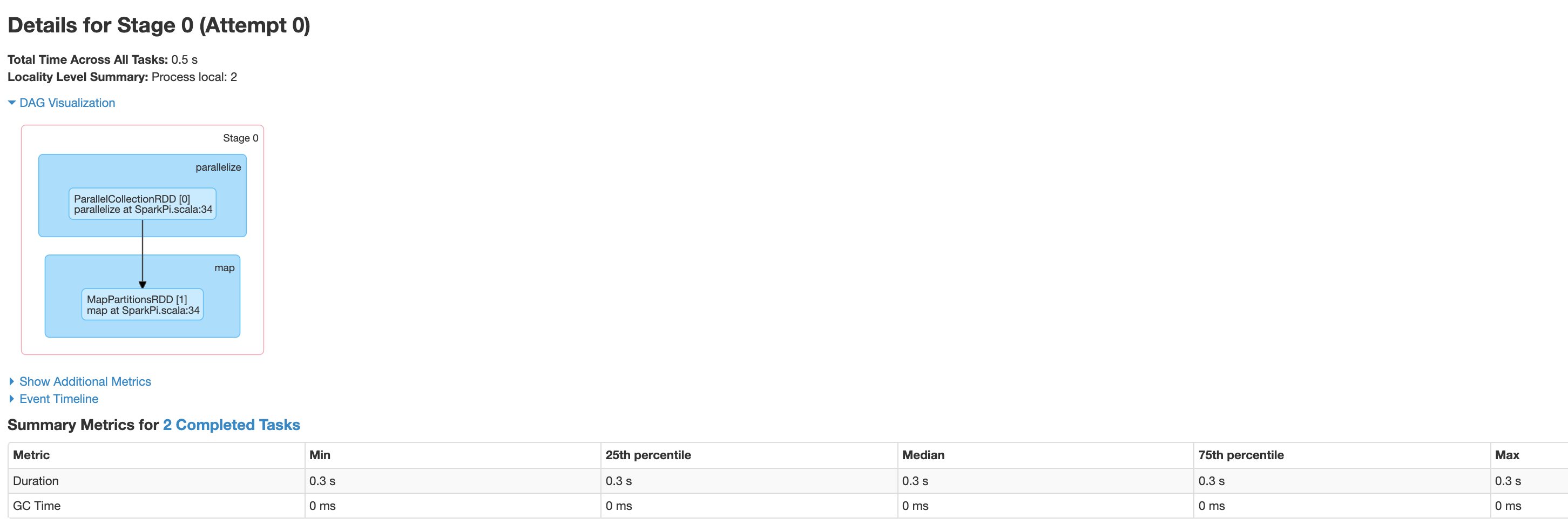
A etapa inclui uma visualização do DAG, um cronograma do evento e métricas das tarefas na etapa. Use esta página para solucionar problemas relacionados a tarefas substituídas, atrasos no programador e erros de falta de memória. O visualizador do DAG mostra a linha de código derivada da etapa, ajudando a rastrear os problemas no código.
Clique na guia "Executores" para ver informações sobre os nós do driver e do executor do aplicativo Spark.

Informações importantes nesta página incluem o número de núcleos e o número de tarefas executadas em cada executor.
Interface da Web do Tez
O Tez é o mecanismo de execução padrão para Hive e Pig no Dataproc. Enviar um job do Hive em um cluster de jobs do Dataproc inicia um aplicativo Tez.
Se você configurou o serviço de linha do tempo do Yarn v2 e definiu a propriedade dataproc:yarn.atsv2.bigtable.instance ao criar o PHS e os clusters de jobs do Dataproc, o YARN grava os dados da linha do tempo do job do Hive e do Pig gerados na instância especificada do Bigtable para recuperação e exibição na interface da Web do Tez em execução no servidor PHS.

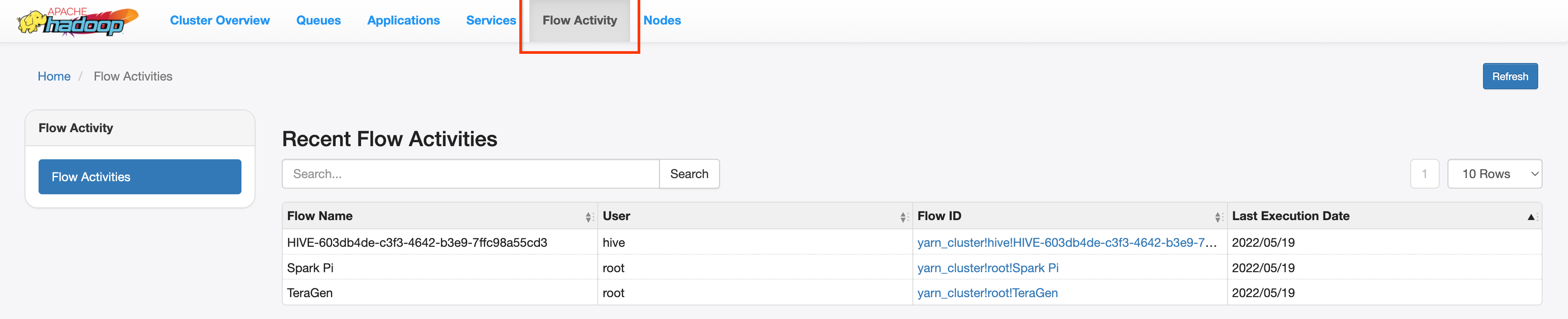
Interface da Web da linha do tempo do aplicativo YARN V2
Se você configurou o serviço de linha do tempo do YARN v2
e definiu a propriedade dataproc:yarn.atsv2.bigtable.instance ao
criar os clusters de jobs do PHS e do Dataproc, o YARN vai gravar
os dados gerados da linha do tempo do job na instância especificada do Bigtable para recuperação e
exibição na interface da Web do serviço de linha do tempo do aplicativo YARN em execução no
servidor PHS. Os jobs do Dataproc estão listados na guia Atividade de fluxo da interface da Web.
Configurar o serviço de linha do tempo do Yarn v2
Para configurar o serviço de linha do tempo do Yarn v2, configure uma instância do Bigtable e, se necessário, verifique os papéis da conta de serviço da seguinte maneira:
Verifique os papéis da conta de serviço, se necessário. A conta de serviço da VM padrão usada pelas VMs do cluster do Dataproc tem as permissões necessárias para criar e configurar a instância do Bigtable para o serviço de linha do tempo do YARN. Se você criar o job ou o cluster do PHS com uma conta de serviço da VM personalizada, a conta precisará ter o papel
AdministratorouBigtable Userdo Bigtable.
Esquema de tabela obrigatório
O suporte do PHS do Dataproc para o
YARN Timeline Service v2
requer um esquema específico criado na
instância do Bigtable. O Dataproc cria o esquema necessário quando um cluster de jobs ou do PHS é criado com a propriedade dataproc:yarn.atsv2.bigtable.instance definida para apontar para a instância do Bigtable.
Este é o esquema de instância do Bigtable necessário:
| Tabelas | Grupos de colunas |
|---|---|
| prod.timelineservice.application | c,i,m |
| prod.timelineservice.app_flow | m |
| prod.timelineservice.entity | c,i,m |
| prod.timelineservice.flowactivity | i |
| prod.timelineservice.flowrun | i |
| prod.timelineservice.subapplication | c,i,m |
Coleta de lixo do Bigtable
É possível configurar a coleta de lixo do Bigtable com base na idade para tabelas do ATSv2:
Instale cbt, (incluindo a criação do
.cbrtc file).Crie a política de coleta de lixo com base na idade do ATSv2:
export NUMBER_OF_DAYS = number \
cbt setgcpolicy prod.timelineservice.application c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.application m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.app_flow m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.entity m maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowactivity i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.flowrun i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication c maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication i maxage=${NUMBER_OF_DAYS} \
cbt setgcpolicy prod.timelineservice.subapplication m maxage=${NUMBER_OF_DAYS}
Observações:
NUMBER_OF_DAYS: o número máximo de dias é 30d.