Lorsque vous créez des clusters et y exécutez des tâches à l'aide de Dataproc, le service configure les autorisations et rôles Dataproc requis dans votre projet pour accéder aux ressources Google Cloud nécessaires à la réalisation de ces tâches et les utiliser. Notez toutefois que si vous travaillez avec plusieurs projets (afin d'accéder aux données d'un autre projet, par exemple), vous devez configurer les rôles et autorisations nécessaires pour accéder aux ressources des différents projets.
Pour vous aider à travailler efficacement sur plusieurs projets, ce document répertorie les diverses entités principales qui utilisent le service Dataproc, ainsi que les rôles contenant les autorisations nécessaires pour que ces entités puissent accéder aux ressources Google Cloud et les utiliser.
Trois entités principales (identités) peuvent accéder à Dataproc et l'utiliser :
- Identité des utilisateurs
- Identité du plan de contrôle
Identité du plan de données
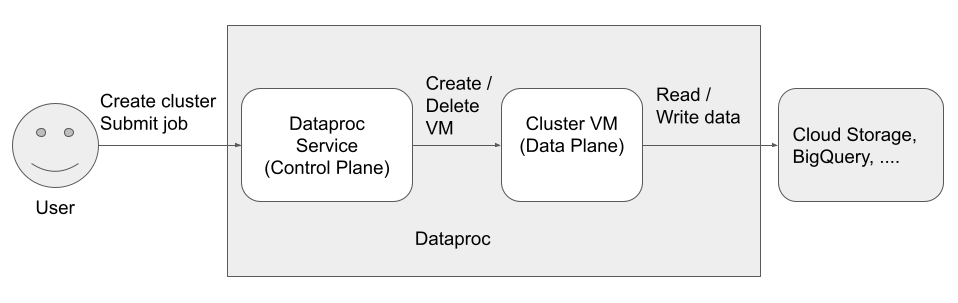
Utilisateur de l'API Dataproc (identité d'utilisateur)
Exemple : nom_utilisateur@example.com
Il s'agit de l'utilisateur qui appelle le service Dataproc pour créer des clusters, envoyer des jobs et effectuer d'autres requêtes au service. L'utilisateur est généralement un individu, mais il peut également s'agir d'un compte de service si Dataproc est appelé via un client API ou un autre serviceGoogle Cloud tel que Compute Engine, les fonctions Cloud Run ou Cloud Composer.
Rôles associés
Remarques
- Les tâches Dataproc envoyées par l'API s'exécutent sous le compte
rootsous Linux. Les clusters Dataproc héritent des métadonnées SSH Compute Engine à l'échelle du projet, sauf s'ils sont explicitement bloqués en définissant
--metadata=block-project-ssh-keys=truelorsque vous créez votre cluster (consultez la section Métadonnées du cluster).Les répertoires d'utilisateurs HDFS sont créés pour chaque utilisateur SSH au niveau du projet. Ces répertoires HDFS sont créés au moment du déploiement du cluster, et un nouvel utilisateur SSH (après le déploiement) ne se verra pas attribuer un répertoire HDFS sur les clusters existants.
Agent de service Dataproc (identité de plan de contrôle)
Exemple : service-project-number@dataproc-accounts.iam.gserviceaccount.com
Le compte de service de l'agent de service Dataproc permet d'effectuer un grand nombre d'opérations système sur les ressources situées dans le projet où un cluster Dataproc est créé, y compris les suivantes :
- Créer des ressources Compute Engine, telles que des instances de VM, des groupes d'instances et des modèles d'instances
- Les opérations
getetlistpour confirmer la configuration des ressources telles que les images, les pare-feu, les actions d'initialisation Dataproc et les buckets Cloud Storage - Créer automatiquement les buckets de préproduction et temporaire Dataproc s'ils ne sont pas spécifiés par l'utilisateur
- Écrire des métadonnées de configuration de cluster dans le bucket de préproduction
- Accéder aux réseaux VPC dans un projet hôte
Rôles associés
Compte de service de VM Dataproc (identité de plan de données)
Exemple : project-number-compute@developer.gserviceaccount.com
Votre code d'application s'exécute en tant que compte de service de la VM sur les VM Dataproc. Les tâches utilisateur bénéficient des rôles (avec leurs autorisations associées) de ce compte de service.
Le compte de service de VM effectue les opérations suivantes :
- communique avec le plan de contrôle Dataproc ;
- Lit et écrit des données depuis et vers les buckets de préproduction et les buckets temporaires Dataproc.
- Si nécessaire, vos tâches Dataproc lisent et écrivent des données depuis et vers Cloud Storage, BigQuery, Cloud Logging et d'autres ressources Google Cloud .
Rôles associés
Étapes suivantes
- En savoir plus sur les rôles et autorisations Dataproc
- En savoir plus sur les comptes de service Dataproc
- Consultez Contrôle des accès BigQuery.
- Consultez les options de contrôle des accès dans Cloud Storage.