오픈소스 Hive-BigQuery 커넥터를 사용하면 Apache Hive 워크로드가 BigQuery 및 BigLake 테이블에 데이터를 읽고 쓸 수 있습니다. 또한 데이터를 BigQuery 스토리지에 저장하거나 Cloud Storage의 오픈소스 데이터 형식으로 저장할 수 있습니다.
Hive-BigQuery 커넥터는 Hive Storage Handler API를 구현하여 Hive 워크로드가 BigQuery 및 BigLake 테이블과 통합되도록 합니다. Hive 실행 엔진은 집계 및 조인과 같은 컴퓨팅 작업을 처리하고, 커넥터는 BigQuery 또는 BigLake에 연결된 Cloud Storage 버킷에 저장된 데이터와의 상호작용을 관리합니다.
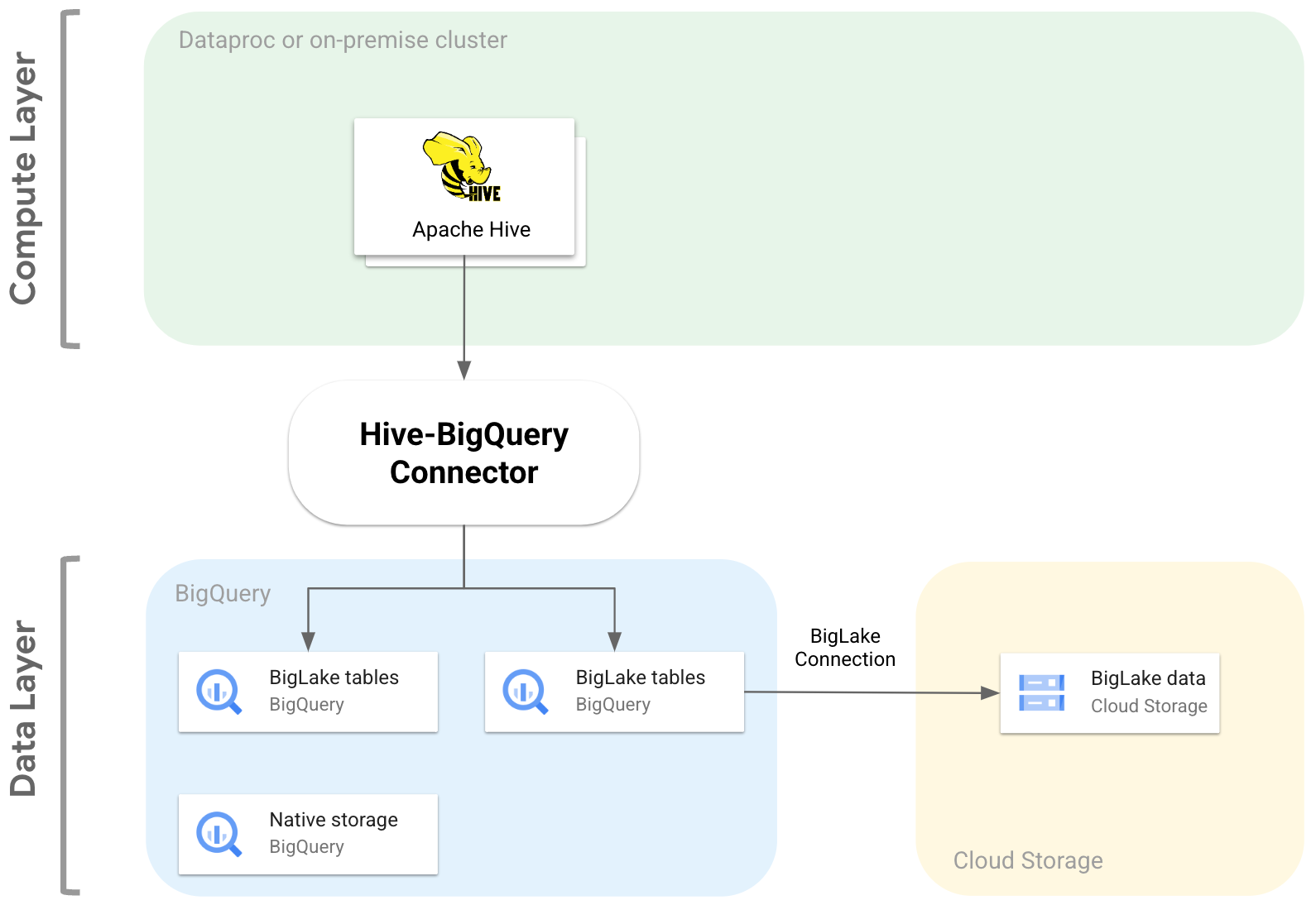
다음 다이어그램은 Hive-BigQuery 커넥터가 컴퓨팅 레이어와 데이터 레이어 간에 어떻게 적합한지 보여줍니다.
사용 사례
다음은 Hive-BigQuery 커넥터가 일반적인 데이터 기반 시나리오에서 도움이 되는 몇 가지 방법입니다.
데이터 마이그레이션 Hive 데이터 웨어하우스를 BigQuery로 이동한 다음 Hive 쿼리를 BigQuery SQL 언어로 점진적으로 변환할 계획이라고 합시다. 데이터 웨어하우스 크기 및 연결된 애플리케이션의 많은 수로 인해 마이그레이션에 상당한 시간이 걸릴 것으로 예상되며 마이그레이션 작업 중에 연속성을 보장해야 합니다. 워크플로는 다음과 같습니다.
- BigQuery로 데이터 이동합니다.
- Hive 쿼리를 BigQuery ANSI 호환 SQL 언어로 점진적으로 변환하는 동안, 커넥터를 사용하여 원래 Hive 쿼리에 액세스하여 실행합니다.
- 마이그레이션과 변환을 완료한 후 Hive를 중단합니다.
Hive 및 BigQuery 워크플로 일부 작업에는 Hive를, BigQuery BI Engine 또는 BigQuery ML과 같은 기능을 활용하는 워크로드에는 BigQuery를 사용할 계획이라고 합시다. 커넥터를 사용하여 Hive 테이블을 BigQuery 테이블에 조인하세요.
오픈소스 소프트웨어 (OSS) 스택에 의존. 공급업체 종속을 방지하기 위해 데이터 웨어하우스에 전체 OSS 스택을 사용합니다. 데이터 요금제는 다음과 같습니다.
BigLake 연결을 사용하여 Avro, Parquet, ORC 등 원래 OSS 형식의 데이터를 Cloud Storage 버킷으로 마이그레이션합니다.
Hive SQL 언어 쿼리를 실행하고 처리하는 데 계속 Hive를 사용합니다.
필요에 따라 커넥터를 사용하여 BigQuery에 연결하면 다음 기능을 활용할 수 있습니다.
- 쿼리 성능을 위한 메타데이터 캐싱
- 데이터 손실 방지
- 열 수준 액세스 제어
- 대규모 보안 및 거버넌스를 위한 동적 데이터 마스킹
기능
Hive-BigQuery 커넥터를 사용하면 BigQuery 데이터로 작업하고 다음 태스크를 수행할 수 있습니다.
- 맵리듀스 및 Tez 실행 엔진으로 쿼리를 실행합니다.
- Hive에서 BigQuery 테이블을 만들고 삭제합니다.
- Hive 테이블을 사용하여 BigQuery 및 BigLake 테이블을 조인합니다.
- Storage Read API 스트림과 Apache Arrow 형식을 사용하여 BigQuery 테이블에서 빠른 읽기를 수행합니다.
- 다음 방법을 사용하여 BigQuery에 데이터를 씁니다.
- BigQuery Storage Write API 대기 모드를 사용하는 직접 쓰기. 짧은 새로 고침 기간이 있는 실시간에 가까운 대시보드와 같이 낮은 쓰기 지연 시간이 필요한 워크로드에 이 방법을 사용하세요.
- 임시 Avro 파일을 Cloud Storage에 스테이징한 후 Load Job API를 사용하여 대상 테이블에 파일을 로드하여 간접 쓰기. 이 방법은 BigQuery 로드 작업에 요금이 부과되지 않으므로 직접 방법보다 비용이 낮습니다. 이 방법은 속도가 느리기 때문에 시간이 중요하지 않은 워크로드에 가장 적합합니다.
BigQuery 시간으로 파티션을 나눈 테이블 및 클러스터링된 테이블에 액세스합니다. 다음 예에서는 Hive 테이블과 BigQuery에서 파티션을 나누고 클러스터링된 테이블 간의 관계를 정의합니다.
CREATE TABLE my_hive_table (int_val BIGINT, text STRING, ts TIMESTAMP) STORED BY 'com.google.cloud.hive.bigquery.connector.BigQueryStorageHandler' TBLPROPERTIES ( 'bq.table'='myproject.mydataset.mytable', 'bq.time.partition.field'='ts', 'bq.time.partition.type'='MONTH', 'bq.clustered.fields'='int_val,text' );
데이터 영역에서 불필요한 열을 검색하지 않도록 열을 가지치기합니다.
서술어 푸시다운을 사용하여 BigQuery 스토리지 레이어에서 데이터 행을 사전 필터링합니다. 이 기법을 사용하면 네트워크를 통과하는 데이터의 양을 줄여 전체 쿼리 성능을 크게 개선할 수 있습니다.
Hive 데이터 유형을 BigQuery 데이터 유형으로 자동으로 변환합니다.
Spark SQL과 통합합니다.
Apache Pig 및 HCatalog와 통합합니다.
시작하기
Hive 클러스터에 Hive-BigQuery 커넥터를 설치하고 구성하는 방법에 관한 안내를 참조하세요.