Qu'est-ce que l'autoscaling ?
Il est difficile d'estimer le nombre "correct" de nœuds de calcul du cluster pour une charge de travail ; la plupart du temps, une taille de cluster unique pour un pipeline entier n'est pas la solution idéale. Le scaling du cluster déclenché par l'utilisateur résout partiellement ce problème, mais nécessite de surveiller l'utilisation du cluster et une intervention manuelle.
L'API AutoscalingPolicies de Dataproc fournit un mécanisme permettant d'automatiser la gestion des ressources de cluster, et permet d'activer l'autoscaling des VM de nœud de calcul du cluster. Une règle d'autoscaling (Autoscaling Policy) est une configuration réutilisable qui décrit la façon dont les nœuds de calcul du cluster qui utilisent cette règle doivent effectuer leur scaling. Elle définit des limites de scaling, des paramètres de fréquence et d'agressivité afin de fournir un contrôle ultraprécis sur les ressources du cluster tout au long de son existence.
Quand utiliser l'autoscaling
Utiliser l'autoscaling :
pour des clusters qui stockent des données dans des services externes, tels que Cloud Storage ou BigQuery
pour des clusters qui traitent de nombreuses tâches
pour faire effectuer un scaling à la hausse des clusters de tâches uniques
avec le mode de flexibilité améliorée pour les tâches par lot Spark
L'autoscaling n'est pas recommandé avec les éléments suivants :
HDFS : l'autoscaling n'est pas conçu pour effectuer le scaling HDFS sur le cluster pour les raisons suivantes :
- L'utilisation de HDFS n'est pas un signal pour l'autoscaling.
- Les données HDFS ne sont hébergées que sur les nœuds de calcul principaux. Le nombre de nœuds de calcul principaux doit être suffisant pour héberger toutes les données HDFS.
- La mise hors service des DataNodes HDFS peut retarder la suppression des nœuds de calcul. Les DataNodes copient les blocs HDFS vers d'autres DataNodes avant la suppression d'un nœud de calcul. En fonction de la taille des données et du facteur de réplication, ce processus peut prendre plusieurs heures.
Libellés des nœuds YARN : l'autoscaling n'est pas compatible avec les libellés de nœuds YARN, ni la propriété
dataproc:am.primary_onlyen raison de YARN-9088. YARN signale incorrectement les métriques de cluster lorsque des libellés de nœuds sont utilisés.Spark Structured Streaming : l'autoscaling n'est pas compatible avec Spark Structured Streaming (consultez la section Autoscaling et Spark Structured Streaming).
Clusters inactifs : l'autoscaling n'est pas recommandé pour la réduction de la taille d'un cluster à sa taille minimale lorsqu'il est inactif. La création d'un cluster étant aussi rapide que son redimensionnement, envisagez de supprimer les clusters inactifs et de les recréer au besoin. Les outils suivants facilitent ce modèle "éphémère" :
Utilisez les workflows Dataproc pour planifier un ensemble de tâches sur un cluster dédié, puis supprimez le cluster lorsque les tâches sont terminées. Pour une orchestration plus avancée, utilisez le service Cloud Composer qui est basé sur Apache Airflow.
Pour les clusters qui traitent des requêtes adhoc ou des flux de travail planifiés en externe, utilisez la suppression planifiée du cluster pour supprimer le cluster après une période d'inactivité ou une durée spécifiée, ou à une heure spécifique.
Charges de travail de différentes tailles : lorsque des tâches de petite et de grande taille s'exécutent sur un cluster, la réduction de taille avec arrêt progressif attend la fin des tâches de grande taille. Par conséquent, un job de longue durée retardera l'autoscaling des ressources pour les jobs plus petits exécutés sur le cluster jusqu'à ce que le job de longue durée soit terminé. Pour éviter ce résultat, regroupez les petits jobs de taille similaire sur un cluster et isolez chaque job de longue durée sur un cluster distinct.
Activer l'autoscaling
Pour activer l'autoscaling sur un cluster :
L'une des options ci-dessous :
Créer une règle d'autoscaling
gcloud CLI
Vous pouvez utiliser la commande gcloud dataproc autoscaling-policies import pour créer une règle d'autoscaling. Elle lit un fichier YAML local qui définit une règle d'autoscaling. Le format et le contenu du fichier doivent correspondre aux objets de configuration et aux champs définis par l'API REST autoscalingPolicies.
L'exemple YAML suivant définit une règle pour les clusters standards Dataproc, avec tous les champs obligatoires. Il fournit également les valeurs minInstances et maxInstances pour les nœuds de calcul principaux, ainsi que la valeur maxInstances pour les nœuds de calcul (préemptifs) secondaires, et définit la valeur cooldownPeriod sur 4 minutes (la valeur par défaut est de 2 minutes). La workerConfig configure les nœuds de calcul principaux. Dans cet exemple, minInstances et maxInstances sont définis sur la même valeur pour éviter le scaling des nœuds de calcul principaux.
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
L'exemple YAML suivant définit une règle pour les clusters Dataproc standards, avec tous les champs de règles d'autoscaling obligatoires et facultatifs.
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
L'exemple YAML suivant définit une règle pour les clusters à zéro nœud.
Pour les clusters à scaling à zéro instance, n'incluez pasworkerConfig.
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Exécutez la commande gcloud suivante à partir d'un terminal local ou dans Cloud Shell pour créer la règle d'autoscaling. Nommez la règle. Ce nom deviendra la règle id, que vous pourrez utiliser dans les commandes gcloud ultérieures pour faire référence à la règle. Utilisez l'option --source pour spécifier le chemin d'accès au fichier local et le nom du fichier YAML de la règle d'autoscaling à importer.
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
API REST
Créez une règle d'autoscaling en définissant AutoscalingPolicy dans le cadre d'une requête autoscalingPolicies.create.
Console
Pour créer une règle d'autoscaling, sélectionnez l'option "CRÉER UNE RÈGLE" sur la page Règles d'autoscaling de Dataproc à l'aide de la console Google Cloud . Sur la page Créer une règle, vous pouvez sélectionner un panneau de recommandation de règle pour remplir les champs des règles d'autoscaling pour un type de tâche ou un objectif de scaling spécifique.
Créer un cluster d'autoscaling
Après avoir créé une règle d'autoscaling, créez un cluster qui utilisera la règle d'autoscaling. Le cluster doit se trouver dans la même région que la règle d'autoscaling.
gcloud CLI
Exécutez la commande gcloud suivante à partir d'un terminal local ou dans Cloud Shell pour créer un cluster d'autoscaling. Attribuez un nom au cluster et utilisez l'option --autoscaling-policy pour spécifier policy ID (nom de la règle que vous avez spécifiée lors de la création de la règle) ou de la règle resource URI (resource name) (voir les champs AutoscalingPolicy id et name).
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
API REST
Créez un cluster d'autoscaling en incluant AutoscalingConfig dans le cadre d'une requête clusters.create.
Console
Vous pouvez sélectionner une règle d'autoscaling existante à appliquer à un nouveau cluster à partir de la section "Règles d'autoscaling" du panneau "Configurer le cluster" sur la page Dataproc Créer un cluster de la console Google Cloud .
Activer l'autoscaling sur un cluster existant
Après avoir créé une règle d'autoscaling, vous pouvez l'activer sur un cluster existant dans la même région.
gcloud CLI
Exécutez la commande gcloud suivante à partir d'un terminal local ou dans Cloud Shell pour activer une règle d'autoscaling sur un cluster existant. Attribuez un nom au cluster et utilisez l'option --autoscaling-policy pour spécifier policy ID (nom de la règle que vous avez spécifiée lors de la création de la règle) ou de la règle resource URI (resource name) (voir les champs AutoscalingPolicy id et name ).
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
API REST
Pour activer une règle d'autoscaling sur un cluster existant, définissez l'élément AutoscalingConfig.policyUri de la règle dans le paramètre updateMask d'une requête clusters.patch.
Console
L'activation d'une règle d'autoscaling sur un cluster existant n'est pas possible dans la console Google Cloud .
Utilisation des règles multi-cluster
Une règle d'autoscaling définit un comportement de scaling pouvant être appliqué à plusieurs clusters. Une règle d'autoscaling est mieux appliquée à plusieurs clusters lorsque ceux-ci partagent des charges de travail similaires ou exécutent des tâches avec des modèles d'utilisation des ressources similaires.
Vous pouvez mettre à jour une règle utilisée par plusieurs clusters. Les mises à jour affectent immédiatement le comportement de l'autoscaling pour tous les clusters utilisant la règle (voir autoscalingPolicies.update). Si vous ne souhaitez pas qu'une mise à jour de règle s'applique à un cluster qui utilise cette règle, désactivez l'autoscaling sur le cluster avant de mettre à jour la règle.
gcloud CLI
Exécutez la commande gcloud suivante depuis un terminal local ou dans Cloud Shell pour désactiver l'autoscaling sur un cluster.
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
API REST
Pour désactiver l'autoscaling sur un cluster, définissez AutoscalingConfig.policyUri sur la chaîne vide et définissez update_mask=config.autoscaling_config.policy_uri dans une requête clusters.patch.
Console
La désactivation de l'autoscaling sur un cluster n'est pas possible dans la console Google Cloud .
- Une règle utilisée par un ou plusieurs clusters ne peut pas être supprimée (voir autoscalingPolicies.delete).
Fonctionnement de l'autoscaling
L'autoscaling vérifie les métriques Hadoop YARN du cluster à la fin de l'intervalle entre chaque période d'autoscaling pour déterminer si le cluster doit être redimensionné et, le cas échéant, l'ampleur de la mise à jour.
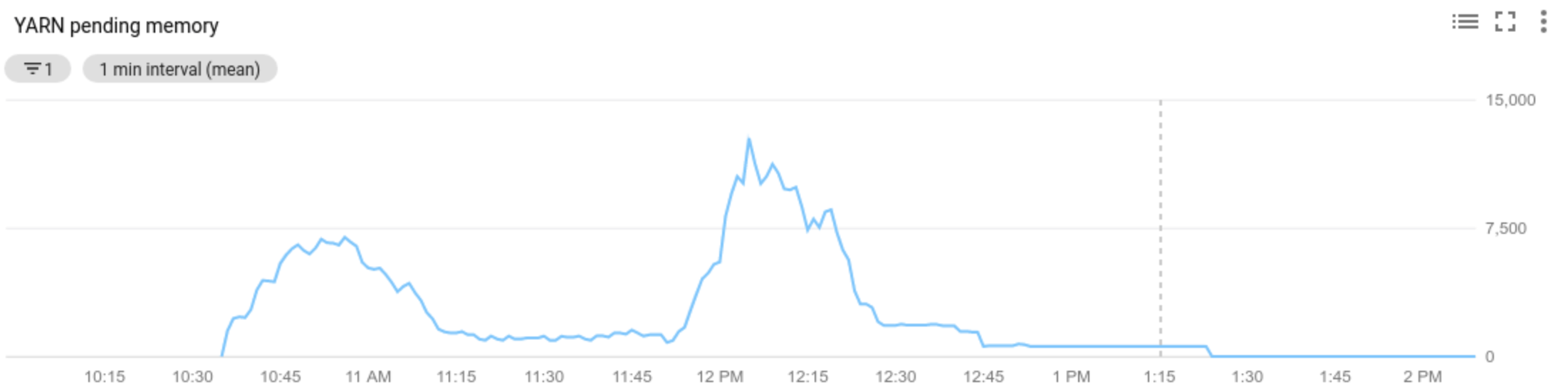
La valeur de la métrique de ressources YARN en attente (mémoire ou cœurs en attente) détermine si le scaling doit être effectué vers le haut ou vers le bas. Une valeur supérieure à
0indique que les jobs YARN attendent des ressources et qu'une mise à l'échelle peut être nécessaire. Une valeur0indique que YARN dispose de ressources suffisantes et qu'une réduction ou d'autres modifications ne sont peut-être pas nécessaires.Si la ressource en attente est > 0 :
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Si la ressource en attente est définie sur 0 :
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Par défaut, l'autoscaler surveille la ressource de mémoire YARN. Si vous activez l'autoscaling basé sur les cœurs, la mémoire et les cœurs YARN sont surveillés :
estimated_worker_countest évalué séparément pour la mémoire et les cœurs, et le nombre de nœuds de calcul le plus élevé est sélectionné.$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
Compte tenu de la modification estimée du nombre de nœuds de calcul, l'autoscaling utilise une valeur
scaleUpFactorouscaleDownFactorpour calculer la modification réelle du nombre de nœuds de calcul :if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
Une valeur scaleUpFactor ou scaleDownFactor définie sur 1.0 signifie que l'autoscaling est exécuté de manière à ce que la ressource en attente ou disponible soit égale à 0 (utilisation parfaite).
Une fois que la modification du nombre de nœuds de calcul est calculée, une fraction
scaleUpMinWorkerFractionouscaleDownMinWorkerFractionagit en tant que seuil pour déterminer si l'autoscaling du cluster doit être exécuté. Une fraction de valeur faible signifie que l'autoscaling doit être exécuté même si l'élémentΔworkersa une valeur faible. Une fraction de valeur plus importante signifie que l'autoscaling ne doit être exécuté que lorsque l'élémentΔworkersatteint une valeur plus importante.IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
Si le nombre de nœuds de calcul est suffisant pour déclencher le processus de scaling, l'autoscaling utilise les limites
minInstancesmaxInstancesdeworkerConfigainsi quesecondaryWorkerConfigetweight(ratio des nœuds de calcul principaux à secondaires) pour déterminer comment diviser le nombre de nœuds de calcul entre les groupes d'instances primaires et secondaires. Le résultat de ces calculs représente la modification finale de l'autoscaling du cluster pour la période de scaling.Les demandes de réduction d'échelle de l'autoscaling seront annulées sur les clusters créés avec les versions d'image 2.0.57+, 2.1.5+ et ultérieures si :
- une réduction est en cours avec une valeur de délai de mise hors service concertée différente de zéro ;
Le nombre de nœuds de calcul YARN actifs ("nœuds de calcul actifs") plus la variation du nombre total de nœuds de calcul recommandée par l'autoscaler (
Δworkers) est supérieur ou égal àDECOMMISSIONINGnœuds de calcul YARN ("nœuds de calcul à mettre hors service"), comme indiqué dans la formule suivante :IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
Pour obtenir un exemple d'annulation de scaling à la baisse, consultez Quand l'autoscaling annule-t-il une opération de scaling à la baisse ?.
Recommandations de configuration de l'autoscaling
Cette section contient des recommandations pour vous aider à configurer l'autoscaling.
Éviter le scaling des nœuds de calcul principaux
Les nœuds de calcul principaux exécutent des Datanodes HDFS, tandis que les nœuds de calcul secondaires sont des nœuds de calcul dédiés.
L'utilisation de nœuds de calcul secondaires vous permet de faire évoluer efficacement les ressources de calcul sans avoir à provisionner de stockage, ce qui accélère le scaling.
Les nœuds Namenode HDFS peuvent présenter plusieurs conditions de concurrence qui entraînent la corruption de HDFS et le blocage indéfini de la mise hors service. Pour éviter ce problème, évitez de procéder à un scaling des nœuds de calcul principaux. Par exemple : none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
Quelques modifications doivent être apportées à la commande de création de cluster :
- Définissez
--num-workers=10pour qu'il corresponde à la taille du groupe de nœuds de calcul principal de la règle d'autoscaling. - Définissez
--secondary-worker-type=non-preemptiblede sorte que les nœuds de calcul secondaires ne soient pas préemptifs (à moins que vous n'ayez besoin de VM préemptives). - Copiez la configuration matérielle des nœuds de calcul primaires vers les nœuds de calcul secondaires. Par exemple, définissez
--secondary-worker-boot-disk-size=1000GBde sorte que ses valeurs correspondent à celle de--worker-boot-disk-size=1000GB.
Utiliser le mode de flexibilité améliorée pour les tâches par lot Spark
Utilisez le mode de flexibilité améliorée (EFM) avec l'autoscaling pour :
activer le scaling à la baisse plus rapide du cluster pendant l'exécution des jobs ;
éviter toute interruption des tâches en cours en raison du scaling à la baisse du cluster ;
minimiser les perturbations des jobs en cours d'exécution dues à la préemption des nœuds de calcul secondaires préemptifs
Lorsque le mode de flexibilité améliorée est activé, le délai avant expiration de la mise hors service concertée d'une règle d'autoscaling doit être défini sur 0s. La règle d'autoscaling doit entraîner l'autoscaling des nœuds de calcul secondaires uniquement.
Choisir un délai avant expiration de la mise hors service concertée
L'autoscaling est compatible avec la mise hors service concertée YARN lors de la suppression des nœuds d'un cluster. La mise hors service concertée permet aux applications de terminer le brassage des données entre les étapes pour éviter de retarder la progression de la tâche. Le délai de mise hors service concertée indiqué dans une règle d'autoscaling correspond à la limite supérieure de la durée pendant laquelle YARN attend que les applications en cours d'exécution au début de la mise hors service se terminent avant de supprimer des nœuds.
Lorsqu'un processus ne se termine pas dans le délai d'arrêt progressif spécifié, le nœud de calcul est arrêté de force, ce qui peut entraîner une perte de données ou une interruption de service. Pour éviter cela, définissez le délai avant expiration de la mise hors service concertée sur une valeur supérieure à la tâche la plus longue que le cluster va traiter. Par exemple, si vous prévoyez que votre job le plus long s'exécutera pendant une heure, définissez le délai avant expiration sur au moins une heure (1h).
Envisagez de migrer des tâches qui prennent plus d'une heure vers leurs propres clusters éphémères afin d'éviter le blocage de la mise hors service concertée.
Configurer scaleUpFactor
scaleUpFactor contrôle l'intensité de scaling à la hausse d'un cluster par l'autoscaler.
Spécifiez un nombre compris entre 0.0 et 1.0 pour définir la valeur fractionnaire de la ressource YARN en attente qui entraîne l'ajout de nœuds.
Par exemple, si 100 conteneurs en attente demandent 512 Mo chacun, il y a 50 Go de mémoire YARN en attente. Si le champ scaleUpFactor est défini sur 0.5, l'autoscaler ajoute suffisamment de nœuds pour ajouter 25 Go de mémoire YARN. De même, s'il est défini sur 0.1, l'autoscaler ajoute suffisamment de nœuds pour 5 Go. Notez que ces valeurs correspondent à la mémoire YARN, et non à la mémoire totale disponible sur une VM.
Un bon point de départ est 0.05 pour les tâches MapReduce et les tâches Spark avec l'allocation dynamique activée. Pour les tâches Spark avec un nombre d'exécuteurs fixes et pour les tâches Tez, utilisez 1.0. Une valeur scaleUpFactor de 1.0 signifie que l'autoscaling est exécuté de manière à ce que la ressource en attente ou disponible soit égale à 0 (utilisation parfaite).
Configurer scaleDownFactor
scaleDownFactor contrôle l'intensité de scaling vers le bas d'un cluster par l'autoscaler. Indiquez un nombre compris entre 0.0 et 1.0 pour définir la valeur fractionnaire de la ressource YARN disponible qui entraîne la suppression des nœuds.
Laissez cette valeur définie sur 1.0 pour la plupart des clusters multitâches qui doivent être mis à l'échelle de manière fréquente. En raison de la mise hors service concertée, les opérations de scaling à la baisse sont considérablement ralenties par rapport aux opérations de scaling à la hausse. La définition de scaleDownFactor=1.0 définit un taux de scaling à la baisse agressif, ce qui entraîne une réduction du nombre d'opérations de scaling à la baisse nécessaires pour atteindre la taille de cluster appropriée.
Pour les clusters qui ont besoin de plus de stabilité, définissez une valeur scaleDownFactor plus faible pour un taux de réduction plus lent.
Définissez cette valeur sur 0.0 pour éviter un scaling à la baisse du cluster, par exemple lorsque vous utilisez des clusters éphémères ou de tâches uniques.
Définir scaleUpMinWorkerFraction et scaleDownMinWorkerFraction
scaleUpMinWorkerFraction et scaleDownMinWorkerFraction sont utilisés avec scaleUpFactor ou scaleDownFactor et ont des valeurs par défaut de 0.0. Elles représentent les seuils auxquels l'autoscaler choisit d'effectuer un scaling du cluster à la hausse ou à la baisse : la valeur fractionnaire minimale d'augmentation ou de diminution de la taille du cluster nécessaire pour émettre des requêtes de scaling à la hausse ou à la baisse.
Exemples : L'autoscaler n'enverra pas de demande de mise à jour pour ajouter cinq nœuds de calcul à un cluster de 100 nœuds, sauf si scaleUpMinWorkerFraction est inférieur ou égal à 0.05 (5 %). Si la valeur est définie sur 0.1, l'autoscaler n'enverra pas la requête de scaling à la hausse du cluster.
De même, si scaleDownMinWorkerFraction est 0.05, l'autoscaler n'envoie pas de mise à jour, sauf si au moins cinq nœuds ont besoin d'être supprimés.
La valeur par défaut 0.0 désigne l'absence de seuil.
Il est vivement recommandé de définir une valeur scaleDownMinWorkerFractionthresholds plus élevée sur les grands clusters (> 100 nœuds) pour éviter les opérations de scaling mineures et inutiles.
Choisir un intervalle entre chaque période d'autoscaling
cooldownPeriod définit une période pendant laquelle l'autoscaler n'émettra pas de demandes de modification de la taille du cluster. Vous pouvez l'utiliser pour limiter la fréquence des modifications de l'autoscaler apportées à la taille du cluster.
La valeur minimale et la valeur par défaut de cooldownPeriod est de deux minutes. Si une valeur cooldownPeriod plus courte est définie dans une règle, les modifications apportées à la charge de travail affecteront plus rapidement la taille du cluster, mais les clusters risquent d'effectuer un scaling à la hausse ou à la baisse inutilement. Il est recommandé de définir les paramètres scaleUpMinWorkerFraction et scaleDownMinWorkerFraction d'une règle sur une valeur différente de zéro si vous utilisez une valeur période d'intervalle (cooldownPeriod) plus courte. Cela garantit que le cluster ne fait pas de scaling à la hausse ou à la baisse lorsque la modification de l'utilisation des ressources est suffisante pour justifier une mise à jour du cluster.
Si votre charge de travail est sensible aux modifications de la taille du cluster, vous pouvez augmenter la période de refroidissement. Par exemple, si vous exécutez un job de traitement par lot, vous pouvez définir la période de refroidissement sur 10 minutes ou plus. Testez différentes périodes de refroidissement pour trouver la valeur qui convient le mieux à votre charge de travail.
Limites de nombre de nœuds de calcul et pondérations du groupe
Chaque groupe de nœuds de calcul a des minInstances et maxInstances qui configurent une limite stricte sur la taille de chaque groupe.
Chaque groupe comprend également un paramètre appelé weight qui configure l'équilibre cible entre les deux groupes. Notez que ce paramètre n'est qu'un indicateur. Si un groupe atteint sa taille minimale ou maximale, les nœuds ne sont ajoutés ou supprimés que de l'autre groupe. Par conséquent, le paramètre weight peut presque toujours être maintenu sur la valeur par défaut 1.
Activer l'autoscaling basé sur les cœurs
Par défaut, YARN utilise des métriques de mémoire pour l'allocation des ressources. Pour les applications gourmandes en ressources de processeur, il est recommandé de configurer YARN pour qu'il utilise le calculateur de ressources dominantes. Pour ce faire, définissez la propriété suivante lorsque vous créez un cluster :
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
Métriques et journaux de l'autoscaling
Les ressources et les outils suivants peuvent vous aider à surveiller les opérations d'autoscaling et leurs effets sur le cluster et ses tâches.
Cloud Monitoring
Utilisez Cloud Monitoring pour :
- Afficher les métriques utilisées par l'autoscaling
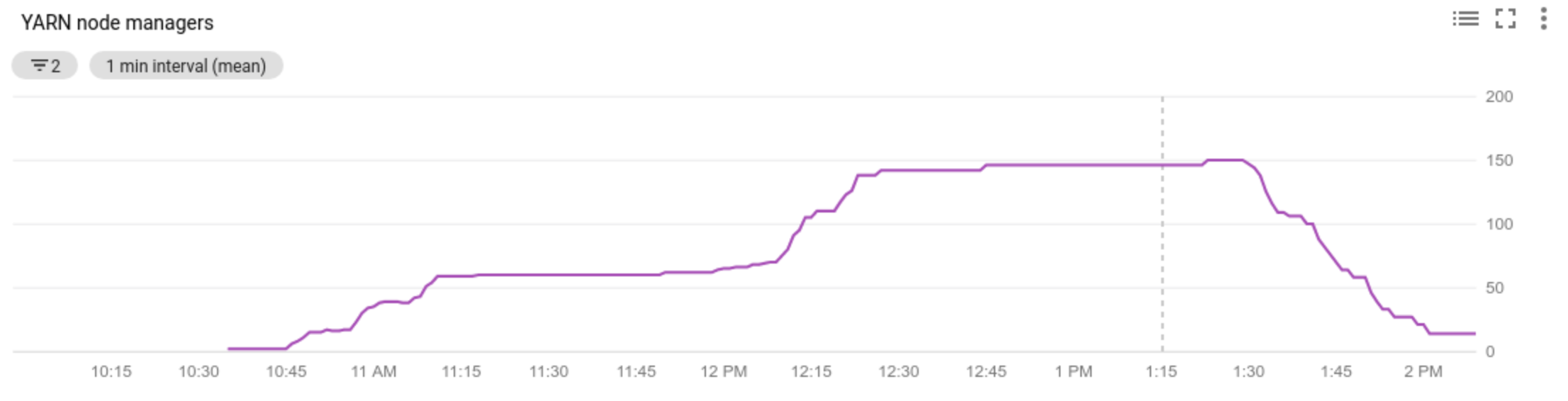
- Afficher le nombre de gestionnaires de nœuds dans votre cluster
- Comprendre pourquoi l'autoscaling a été exécuté ou non sur votre cluster
Cloud Logging
Utilisez Cloud Logging pour afficher les journaux de l'autoscaler Dataproc.
1) Recherchez les journaux de votre cluster.
2) Sélectionnez dataproc.googleapis.com/autoscaler.
3) Développez les messages de journal pour afficher le champ status. Les journaux sont au format JSON, un format lisible par un ordinateur.
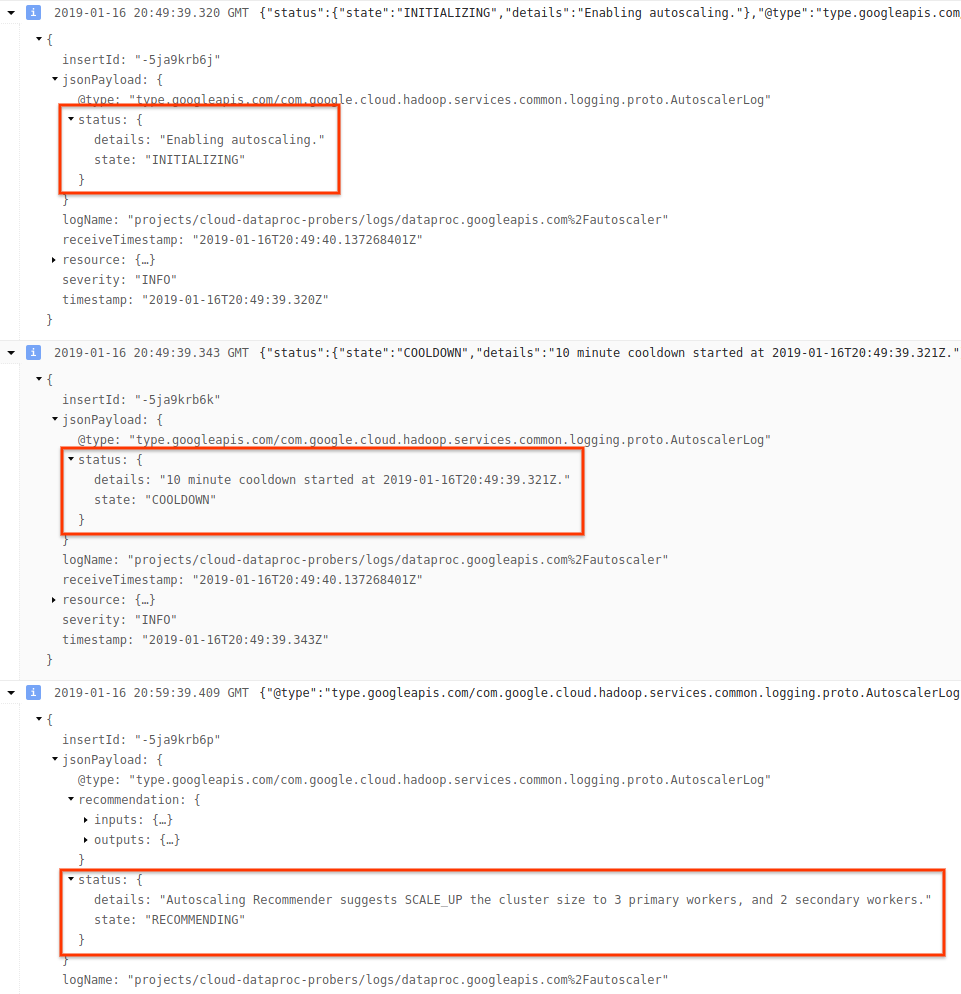
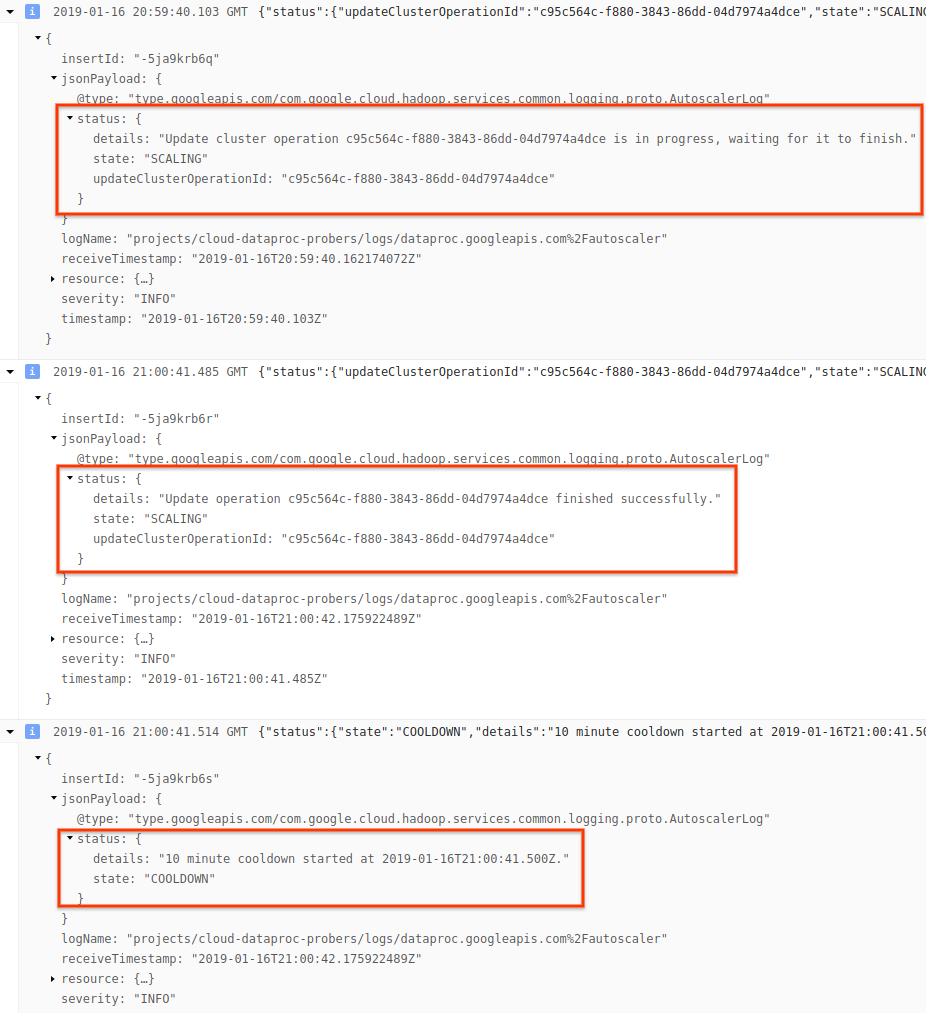
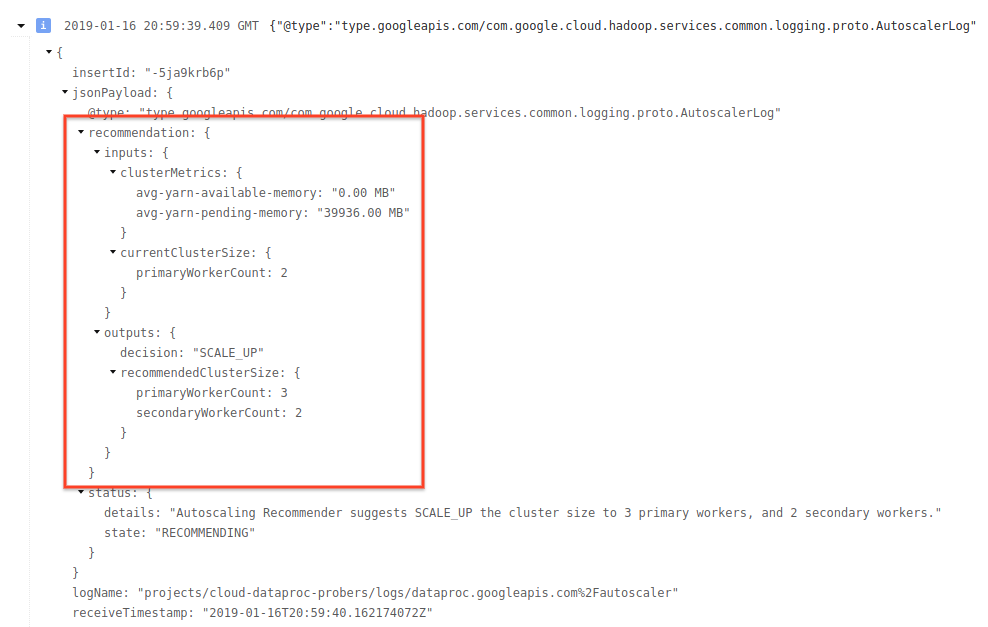
4) Développez le message de journal pour afficher les recommandations de scaling, les métriques utilisées pour les décisions de scaling, la taille du cluster d'origine et la nouvelle taille du cluster cible.
Contexte : Autoscaling avec Apache Hadoop et Apache Spark
Les sections suivantes expliquent comment l'autoscaling interagit (ou non) avec Hadoop YARN et Hadoop Mapreduce, et Apache Spark, Spark Streaming et Spark Structured Streaming.
Métriques Hadoop YARN
L'autoscaling s'articule autour des métriques Hadoop YARN suivantes :
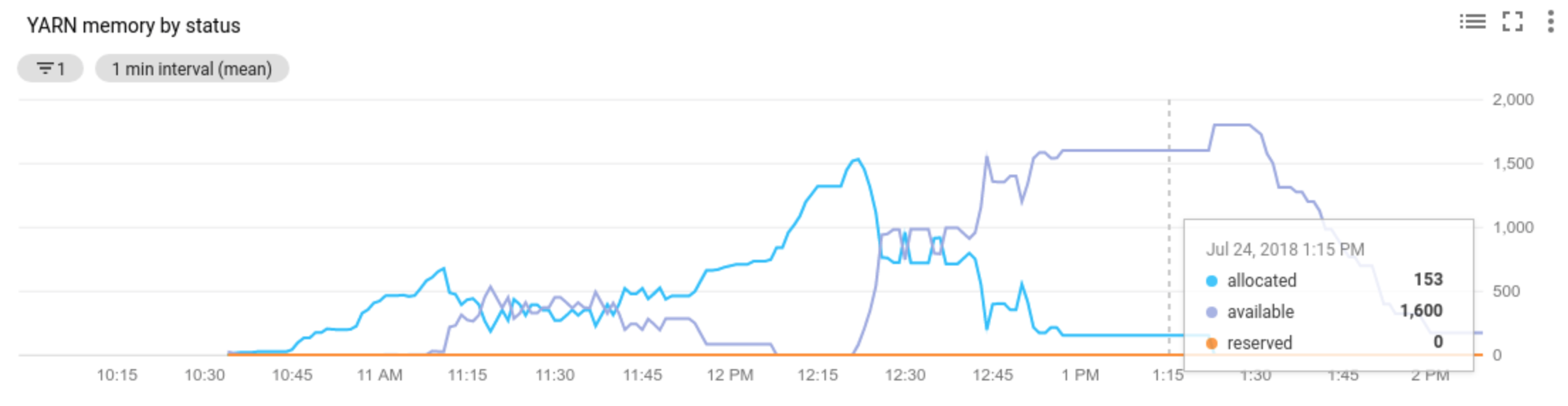
Allocated resourcecorrespond à la quantité totale de ressources YARN utilisée par l'exécution de conteneurs sur l'ensemble du cluster. Si 6 conteneurs en cours d'exécution peuvent utiliser jusqu'à 1 unité de ressource, cela signifie que 6 ressources sont allouées.Available resourcecorrespond à la ressource YARN du cluster qui n'est pas utilisée par les conteneurs alloués. Si 10 unités de ressources sont disponibles sur tous les gestionnaires de nœuds et que 6 d'entre elles sont allouées, il reste 4 ressources disponibles. Si le cluster contient des ressources disponibles (inutilisées), l'autoscaling peut supprimer des nœuds de calcul du cluster.Pending resourcecorrespond à la somme des requêtes de ressources YARN pour les conteneurs en attente. Ces conteneurs attendent que de l'espace soit disponible dans YARN. La ressource en attente n'est une valeur non nulle que si la ressource disponible est nulle ou trop petite pour être allouée au conteneur suivant. Si des conteneurs sont en attente, l'autoscaling peut ajouter des nœuds de calcul au cluster.
Vous pouvez afficher ces métriques dans Cloud Monitoring. Par défaut, la mémoire YARN correspond à 0,8 x mémoire totale sur le cluster, la mémoire restante étant réservée à d'autres daemons et systèmes d'exploitation, tels que le cache de pages. Vous pouvez remplacer la valeur par défaut par le paramètre de configuration YARN "yarn.nodemanager.resource.memory-mb" (voir Apache Hadoop YARN, HDFS, Spark et les propriétés associées).
Autoscaling et Hadoop MapReduce
MapReduce exécute chaque tâche de mappage et réduction en tant que conteneur YARN distinct. Lorsqu'une tâche commence, MapReduce soumet des requêtes de conteneur pour chaque tâche de mappage, ce qui entraîne un pic important dans la mémoire YARN en attente. Au fur et à mesure que les tâches de mappage se terminent, la mémoire en attente diminue.
Lorsque la tâche mapreduce.job.reduce.slowstart.completedmaps se termine (95 % par défaut sur Dataproc), MapReduce met en file d'attente les requêtes de conteneur pour tous les réducteurs, ce qui entraîne un nouveau pic dans la mémoire en attente.
Ne définissez pas scaleUpFactor sur une valeur élevée, à moins que les tâches de mappage et de réduction prennent plusieurs minutes ou plus. L'ajout de nœuds de calcul au cluster prend au moins une minute et demie. Assurez-vous qu'il reste suffisamment de tâches en attente pour utiliser le nouveau nœud de calcul pendant plusieurs minutes. Un bon point de départ consiste à définir scaleUpFactor sur 0,05 (5 %) ou 0,1 (10 %) de la quantité de mémoire en attente.
Autoscaling et Spark
Spark ajoute une couche supplémentaire de planification en plus de YARN. Plus précisément, l'allocation dynamique de Spark Core envoie des requêtes à YARN pour que les conteneurs exécutent les exécuteurs Spark, puis planifie les tâches Spark sur les fils d'exécution de ces exécuteurs. Les clusters Dataproc activent l'allocation dynamique par défaut. Ainsi, les exécuteurs sont ajoutés et supprimés si nécessaire.
Spark demande toujours des conteneurs à YARN, mais sans allocation dynamique, il ne demande des conteneurs qu'au début de la tâche. L'allocation dynamique permet de supprimer les conteneurs ou en demander de nouveaux, au besoin.
Spark commence à partir d'un petit nombre d'exécuteurs (deux sur des clusters d'autoscaling) et continue à doubler le nombre d'exécuteurs tant qu'il y a des tâches en attente.
Cela permet de réguler la quantité de mémoire en attente (moins de pics de mémoire en attente). Il est recommandé de définir le facteur d'autoscaling scaleUpFactor sur un nombre élevé, tel que 1 (100 %), pour les tâches Spark.
Désactiver l'allocation dynamique Spark
Si vous exécutez des tâches Spark distinctes ne bénéficiant pas de l'allocation dynamique Spark, vous pouvez désactiver l'allocation dynamique Spark en définissant spark.dynamicAllocation.enabled=false et spark.executor.instances.
Vous pouvez toujours utiliser l'autoscaling sur des clusters pendant que les tâches Spark distinctes sont exécutées.
Tâches Spark avec données en cache
Définissez spark.dynamicAllocation.cachedExecutorIdleTimeout ou annulez la mise en cache des ensembles de données lorsqu'ils ne sont plus nécessaires. Par défaut, Spark ne supprime pas les exécuteurs ayant mis en cache des données, ce qui empêcherait le scaling du cluster à la baisse.
Autoscaling et Spark Streaming
Spark Streaming possède sa propre version d'allocation dynamique qui utilise des signaux spécifiques au streaming pour ajouter et supprimer des exécuteurs. Définissez ainsi
spark.streaming.dynamicAllocation.enabled=trueet désactivez l'allocation dynamique de Spark Core en définissantspark.dynamicAllocation.enabled=false.N'utilisez pas la mise hors service concertée (autoscaling
gracefulDecommissionTimeout) avec les tâches Spark Streaming. À la place, pour supprimer les nœuds de calcul avec autoscaling en toute sécurité, configurez les points de contrôle pour la tolérance aux pannes.
Vous pouvez également utiliser Spark Streaming sans l'autoscaling :
- Désactivez l'allocation dynamique de Spark Core (
spark.dynamicAllocation.enabled=false), et - Définissez le nombre d'exécuteurs (
spark.executor.instances) pour votre tâche. Consultez la section Propriétés du cluster.
Autoscaling et Spark Structured Streaming
L'autoscaling n'est pas compatible avec Spark Structured Streaming, car Spark Structured Streaming ne gère pas l'allocation dynamique (consultez la page SPARK-24815: Structured Streaming should support dynamic allocation).
Contrôler l'autoscaling par partitionnement et parallélisme
Tandis que le parallélisme est généralement défini ou déterminé par les ressources du cluster (par exemple, le nombre de blocs HDFS est contrôlé par le nombre de tâches), l'inverse s'applique avec l'autoscaling. L'autoscaling définit le nombre de nœuds de calcul en fonction du parallélisme des tâches. Vous trouverez ci-dessous des instructions pour vous aider à définir le parallélisme des tâches :
- Bien que Dataproc définisse le nombre par défaut de tâches de réduction MapReduce en fonction de la taille initiale de votre cluster, vous pouvez définir
mapreduce.job.reducespour augmenter le parallélisme de la phase de réduction. - Le parallélisme Spark SQL et DataFrame est déterminé par
spark.sql.shuffle.partitions, dont la valeur par défaut est 200. - Les fonctions RDD de Spark sont définies par défaut sur
spark.default.parallelism, qui est défini sur le nombre de cœurs sur les nœuds de calcul au démarrage de la tâche. Cependant, toutes les fonctions RDD qui créent des brassages utilisent un paramètre pour le nombre de partitions, qui remplacespark.default.parallelism.
Vous devez vous assurer que vos données sont partitionnées de manière égale. En cas de décalage important, une ou plusieurs tâches peuvent prendre beaucoup plus de temps que d'autres, ce qui entraîne une faible utilisation.
Autoscaling des paramètres de propriété Spark et Hadoop par défaut
Les clusters d'autoscaling ont des valeurs de propriété de cluster par défaut qui permettent d'éviter l'échec de tâches lorsque des nœuds de calcul primaires sont supprimés ou des nœuds de calcul secondaires sont préemptés. Vous pouvez remplacer ces valeurs par défaut lorsque vous créez un cluster avec autoscaling (voir Propriétés du cluster).
Paramètres par défaut pour augmenter le nombre maximal de tentatives pour les tâches, les applications maîtres et les étapes :
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
Paramètres par défaut pour réinitialiser les compteurs de nouvelles tentatives (utiles pour les travaux Spark Streaming de longue durée) :
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
Paramètres par défaut pour procéder au démarrage lent du mécanisme d'allocation dynamique Spark à partir d'une petite taille :
spark:spark.executor.instances=2
Questions fréquentes
Cette section contient des questions et réponses fréquentes sur l'autoscaling.
L'autoscaling peut-il être activé sur les clusters à haute disponibilité et les clusters à nœud unique ?
L'autoscaling peut être activé sur les clusters à haute disponibilité, mais pas sur les clusters à nœud unique (les clusters à nœud unique ne sont pas compatibles avec le redimensionnement).
Un cluster d'autoscaling peut-il être redimensionné manuellement ?
Oui. Vous pouvez décider de redimensionner manuellement un cluster en tant que mesure provisoire lorsque vous ajustez une règle d'autoscaling. Toutefois, ces modifications n'auront qu'un effet temporaire et l'autoscaling réduira finalement le cluster.
Au lieu de redimensionner manuellement un cluster d'autoscaling, envisagez de :
Mettre à jour de la règle d'autoscaling. Toute modification apportée à la règle d'autoscaling affectera tous les clusters qui l'utilisent actuellement (voir la section Utilisation des règles multi-cluster).
Dissocier la règle et faire un scaling manuel du cluster à la taille souhaitée.
Demander l'assistance Dataproc.
En quoi Dataproc est-il différent de l'autoscaling Dataflow ?
Consultez Autoscaling horizontal Dataflow et Autoscaling vertical Dataflow Prime.
L'équipe de développement de Dataproc peut-elle réinitialiser l'état d'un cluster de ERROR à RUNNING ?
En général, non. Cette démarche nécessite une intervention manuelle pour vérifier s'il est sûr de réinitialiser l'état du cluster. En outre, souvent, un cluster ne peut pas être réinitialisé sans d'autres étapes manuelles, comme le redémarrage du NameNode HDFS.
Dataproc définit l'état d'un cluster sur ERROR lorsqu'il ne peut pas déterminer l'état d'un cluster après l'échec d'une opération. Les clusters de ERROR ne sont pas soumis à l'autoscaling. Les causes les plus courantes sont les suivantes :
Erreurs renvoyées par l'API Compute Engine, souvent lors des pannes de Compute Engine.
L'exécution de HDFS se retrouve dans un état corrompu en raison de bugs liés à la mise hors service de HDFS.
Erreurs dans l'API Dataproc Control, telles que "Location de tâche expirée".
Supprimez et recréez les clusters dont l'état est ERROR.
Quand l'autoscaling annule-t-il une opération de réduction de la taille ?
Le graphique suivant illustre les cas où l'autoscaling annule une opération de réduction (voir aussi Fonctionnement de l'autoscaling).
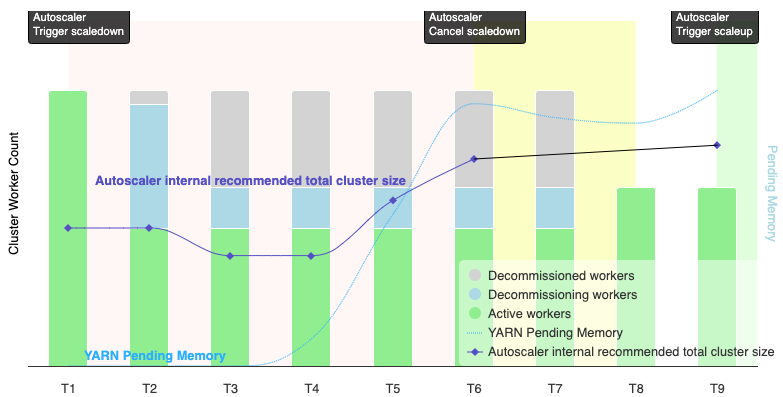
Remarques :
- L'autoscaling est activé dans le cluster en fonction des métriques de mémoire YARN uniquement (par défaut).
- T1 à T9 représentent les intervalles de refroidissement lorsque l'autoscaler évalue le nombre de nœuds de calcul (le timing des événements a été simplifié).
- Les barres empilées représentent le nombre de nœuds de calcul YARN actifs, en cours de mise hors service et mis hors service.
- Le nombre de nœuds de calcul recommandé par l'autoscaler (ligne noire) est basé sur les métriques de mémoire YARN, le nombre de nœuds de calcul actifs YARN et les paramètres de la règle d'autoscaling (voir Fonctionnement de l'autoscaling).
- La zone rouge indique la période pendant laquelle l'opération de réduction est en cours.
- La zone jaune indique la période pendant laquelle l'opération de réduction est annulée.
- La zone verte en arrière-plan indique la période de l'opération de scale-up.
Les opérations suivantes se produisent aux moments suivants :
T1 : L'autoscaler lance une opération de scaling à la baisse avec mise hors service concertée pour réduire d'environ la moitié le nombre de nœuds de calcul du cluster actuel.
T2 : L'autoscaler continue de surveiller les métriques du cluster. Elle ne modifie pas sa recommandation de réduction et l'opération de réduction se poursuit. Certains nœuds de calcul ont été mis hors service, et d'autres sont en cours de mise hors service (Dataproc supprimera les nœuds de calcul mis hors service).
T3 : L'autoscaler calcule que le nombre de nœuds de calcul peut encore être réduit, peut-être en raison de la disponibilité de mémoire YARN supplémentaire. Toutefois, comme le nombre de nœuds de calcul actifs plus la modification recommandée du nombre de nœuds de calcul n'est pas égal ou supérieur au nombre de nœuds de calcul actifs plus les nœuds de calcul mis hors service, les critères d'annulation du scaling à la baisse ne sont pas remplis et l'autoscaler n'annule pas l'opération de scaling à la baisse.
T4 : YARN signale une augmentation de la mémoire en attente. Toutefois, le scaler automatique ne modifie pas sa recommandation concernant le nombre de nœuds de calcul. Comme dans T3, les critères d'annulation du scaling à la baisse ne sont toujours pas remplis, et l'autoscaler n'annule pas l'opération de scaling à la baisse.
T5 : La mémoire YARN en attente augmente, et la variation du nombre de nœuds de calcul recommandée par le scaler automatique augmente. Toutefois, comme le nombre de nœuds de calcul actifs plus la modification recommandée du nombre de nœuds de calcul est inférieur au nombre de nœuds de calcul actifs plus les nœuds de calcul à mettre hors service, les critères d'annulation ne sont pas remplis et l'opération de réduction n'est pas annulée.
T6 : la mémoire YARN en attente augmente encore. Le nombre de nœuds de calcul actifs plus la variation du nombre de nœuds de calcul recommandée par le scaler automatique est désormais supérieur au nombre de nœuds de calcul actifs plus les nœuds de calcul mis hors service. Les critères d'annulation sont remplis et l'autoscaler annule l'opération de réduction.
T7 : L'autoscaler attend la fin de l'opération de réduction. L'autoscaler n'évalue pas et ne recommande pas de modifier le nombre de nœuds de calcul pendant cet intervalle.
T8 : L'annulation de l'opération de réduction est terminée. Les nœuds de calcul à mettre hors service sont ajoutés au cluster et deviennent actifs. L'autoscaler détecte la fin de l'annulation de l'opération de réduction et attend la prochaine période d'évaluation (T9) pour calculer le nombre de nœuds de calcul recommandé.
T9 : aucune opération n'est active à l'heure T9. En fonction des règles de l'autoscaler et des métriques YARN, l'autoscaler recommande une opération de scale-up.