Apa itu penskalaan otomatis
Memperkirakan jumlah pekerja (node) cluster yang "tepat" untuk workload itu sulit, dan ukuran cluster tunggal untuk seluruh pipeline sering kali tidak ideal. Penskalaan Cluster yang dimulai pengguna sebagian mengatasi tantangan ini, tetapi memerlukan pemantauan pemanfaatan cluster dan intervensi manual.
AutoscalingPolicies API Dataproc menyediakan mekanisme untuk mengotomatiskan pengelolaan resource cluster serta memungkinkan penskalaan otomatis VM worker cluster. Autoscaling Policy adalah konfigurasi yang dapat digunakan kembali yang menjelaskan cara penskalaan pekerja cluster yang menggunakan kebijakan penskalaan otomatis. Kebijakan ini menentukan batas penskalaan, frekuensi, dan agresivitas untuk memberikan kontrol terperinci atas resource cluster selama masa berlaku cluster.
Kapan harus menggunakan penskalaan otomatis
Menggunakan penskalaan otomatis:
pada cluster yang menyimpan data di layanan eksternal, seperti Cloud Storage atau BigQuery
pada cluster yang memproses banyak tugas
untuk meningkatkan skala cluster tugas tunggal
dengan Mode Fleksibilitas yang Ditingkatkan untuk tugas batch Spark
Penskalaan otomatis tidak direkomendasikan dengan/untuk:
HDFS: Penskalaan otomatis tidak ditujukan untuk penskalaan HDFS dalam cluster karena:
- Penggunaan HDFS bukan merupakan sinyal untuk penskalaan otomatis.
- Data HDFS hanya dihosting di pekerja primer. Jumlah pekerja utama harus cukup untuk menghosting semua data HDFS.
- Menonaktifkan DataNode HDFS dapat menunda penghapusan pekerja. Datanode menyalin blok HDFS ke DataNode lain sebelum pekerja dihapus. Bergantung pada ukuran data dan faktor replikasi, proses ini dapat memerlukan waktu berjam-jam.
Label Node YARN: Penskalaan otomatis tidak mendukung Label Node YARN, atau properti
dataproc:am.primary_onlykarena YARN-9088. YARN salah melaporkan metrik cluster saat label node digunakan.Spark Structured Streaming: Penskalaan otomatis tidak mendukung Spark Structured Streaming (lihat Penskalaan otomatis dan Spark Structured Streaming).
Cluster Nonaktif: Penskalaan otomatis tidak direkomendasikan untuk tujuan penskalaan cluster ke ukuran minimum saat cluster tidak aktif. Karena membuat cluster baru sama cepatnya dengan mengubah ukurannya, pertimbangkan untuk menghapus cluster yang tidak ada aktivitas dan membuatnya kembali. Alat berikut mendukung model "sementara" ini:
Gunakan Alur Kerja Dataproc untuk menjadwalkan serangkaian tugas di cluster khusus, lalu hapus cluster saat tugas selesai. Untuk orkestrasi yang lebih canggih, gunakan Cloud Composer, yang berbasis pada Apache Airflow.
Untuk cluster yang memproses kueri ad-hoc atau beban kerja yang dijadwalkan secara eksternal, gunakan Penghapusan Terjadwal Cluster untuk menghapus cluster setelah periode atau durasi tidak aktif tertentu, atau pada waktu tertentu.
Workload berukuran berbeda: Saat tugas kecil dan besar berjalan di cluster, penurunan skala penonaktifan yang lancar akan menunggu hingga tugas besar selesai. Akibatnya, tugas yang berjalan lama akan menunda penskalaan otomatis resource untuk tugas yang lebih kecil yang berjalan di cluster hingga tugas yang berjalan lama selesai. Untuk menghindari hasil ini, kelompokkan tugas yang lebih kecil dengan ukuran serupa bersama-sama di satu cluster, dan pisahkan setiap tugas berdurasi panjang di cluster yang berbeda.
Aktifkan penskalaan otomatis
Untuk mengaktifkan penskalaan otomatis di cluster:
Salah satu:
Membuat kebijakan penskalaan otomatis
gcloud CLI
Anda dapat menggunakan perintah
gcloud dataproc autoscaling-policies import
untuk membuat kebijakan penskalaan otomatis. Membaca file
YAML
lokal yang menentukan kebijakan penskalaan otomatis. Format dan konten file
harus cocok dengan objek dan kolom konfigurasi yang ditentukan oleh
autoscalingPolicies
REST API.
Contoh YAML berikut menentukan kebijakan untuk cluster standar Dataproc, dengan semua kolom yang diperlukan. Selain itu, perintah ini juga memberikan nilai minInstances dan maxInstances untuk pekerja utama, nilai maxInstances untuk pekerja sekunder (dapat di-preempt), dan menentukan cooldownPeriod 4 menit (defaultnya adalah 2 menit). workerConfig mengonfigurasi
pekerja utama. Dalam contoh ini, minInstances dan
maxInstances ditetapkan ke nilai yang sama
untuk menghindari penskalaan pekerja utama.
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
maxInstances: 50
basicAlgorithm:
cooldownPeriod: 4m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
gracefulDecommissionTimeout: 1h
Contoh YAML berikut menentukan kebijakan untuk cluster standar Dataproc, dengan semua kolom kebijakan penskalaan otomatis wajib dan opsional.
clusterType: STANDARD
workerConfig:
minInstances: 10
maxInstances: 10
weight: 1
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Contoh YAML berikut menentukan kebijakan untuk cluster berskala nol.
Untuk cluster skala nol, jangan sertakanworkerConfig.
clusterType: ZERO_SCALE
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
weight: 1
basicAlgorithm:
cooldownPeriod: 2m
yarnConfig:
scaleUpFactor: 0.05
scaleDownFactor: 1.0
scaleUpMinWorkerFraction: 0.0
scaleDownMinWorkerFraction: 0.0
gracefulDecommissionTimeout: 1h
Jalankan perintah gcloud berikut dari terminal lokal atau di
Cloud Shell untuk membuat
kebijakan penskalaan otomatis. Berikan nama untuk kebijakan. Nama ini akan menjadi
id kebijakan, yang dapat Anda gunakan dalam perintah gcloud
selanjutnya untuk mereferensikan kebijakan. Gunakan flag --source untuk menentukan
jalur lokal dan nama file YAML kebijakan penskalaan otomatis yang akan diimpor.
gcloud dataproc autoscaling-policies import policy-name \ --source=filepath/filename.yaml \ --region=region
REST API
Buat kebijakan penskalaan otomatis dengan menentukan AutoscalingPolicy sebagai bagian dari permintaan autoscalingPolicies.create.
Konsol
Untuk membuat kebijakan penskalaan otomatis, pilih CREATE POLICY dari halaman Kebijakan penskalaan otomatis Dataproc menggunakan konsol Google Cloud . Di halaman Buat kebijakan, Anda dapat memilih panel rekomendasi kebijakan untuk mengisi kolom kebijakan penskalaan otomatis untuk jenis tugas atau tujuan penskalaan tertentu.
Membuat cluster penskalaan otomatis
Setelah membuat kebijakan penskalaan otomatis, buat cluster yang akan menggunakan kebijakan penskalaan otomatis. Cluster harus berada di region yang sama dengan kebijakan penskalaan otomatis.
gcloud CLI
Jalankan perintah gcloud berikut dari terminal lokal atau di
Cloud Shell untuk membuat
cluster penskalaan otomatis. Berikan nama untuk cluster, lalu gunakan
flag --autoscaling-policy untuk menentukan policy ID
(nama kebijakan yang Anda tentukan saat
membuat kebijakan)
atau kebijakan
resource URI (resource name)
(lihat
kolom AutoscalingPolicy id dan name).
gcloud dataproc clusters create cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
Buat cluster penskalaan otomatis dengan menyertakan AutoscalingConfig sebagai bagian dari permintaan clusters.create.
Konsol
Anda dapat memilih kebijakan penskalaan otomatis yang ada untuk diterapkan ke cluster baru dari bagian Kebijakan penskalaan otomatis pada panel Siapkan cluster di halaman Buat cluster di konsol Google Cloud .
Mengaktifkan penskalaan otomatis di cluster yang ada
Setelah membuat kebijakan penskalaan otomatis, Anda dapat mengaktifkan kebijakan tersebut pada cluster yang ada di region yang sama.
gcloud CLI
Jalankan perintah gcloud berikut dari terminal lokal atau di
Cloud Shell untuk mengaktifkan
kebijakan penskalaan otomatis di cluster yang ada. Berikan nama cluster, lalu gunakan
flag --autoscaling-policy untuk menentukan policy ID
(nama kebijakan yang Anda tentukan saat
membuat kebijakan)
atau kebijakan
resource URI (resource name)
(lihat kolom
AutoscalingPolicy id dan name).
gcloud dataproc clusters update cluster-name \ --autoscaling-policy=policy id or resource URI \ --region=region
REST API
Untuk mengaktifkan kebijakan penskalaan otomatis di cluster yang ada, tetapkan
AutoscalingConfig.policyUri
kebijakan di updateMask dari
permintaan clusters.patch.
Konsol
Mengaktifkan kebijakan penskalaan otomatis di cluster yang sudah ada tidak didukung di konsol Google Cloud .
Penggunaan kebijakan multi-cluster
Kebijakan penskalaan otomatis menentukan perilaku penskalaan yang dapat diterapkan ke beberapa cluster. Kebijakan penskalaan otomatis paling baik diterapkan di beberapa cluster jika cluster akan berbagi workload serupa atau menjalankan tugas dengan pola penggunaan resource yang serupa.
Anda dapat memperbarui kebijakan yang digunakan oleh beberapa cluster. Pembaruan langsung memengaruhi perilaku penskalaan otomatis untuk semua cluster yang menggunakan kebijakan (lihat autoscalingPolicies.update). Jika Anda tidak ingin update kebijakan diterapkan ke cluster yang menggunakan kebijakan tersebut, nonaktifkan penskalaan otomatis di cluster sebelum mengupdate kebijakan.
gcloud CLI
Jalankan perintah gcloud berikut dari terminal lokal atau di
Cloud Shell untuk
menonaktifkan penskalaan otomatis pada cluster.
gcloud dataproc clusters update cluster-name --disable-autoscaling \ --region=region
REST API
Untuk menonaktifkan penskalaan otomatis pada cluster, tetapkan
AutoscalingConfig.policyUri
ke string kosong dan tetapkan
update_mask=config.autoscaling_config.policy_uri dalam
permintaan clusters.patch.
Konsol
Penonaktifan penskalaan otomatis di cluster tidak didukung di konsol Google Cloud .
- Kebijakan yang sedang digunakan oleh satu atau beberapa cluster tidak dapat dihapus (lihat autoscalingPolicies.delete).
Cara kerja penskalaan otomatis
Penskalaan otomatis memeriksa metrik Hadoop YARN cluster saat setiap periode "pendinginan" berakhir untuk menentukan apakah akan menskalakan cluster, dan jika ya, besarnya pembaruan.
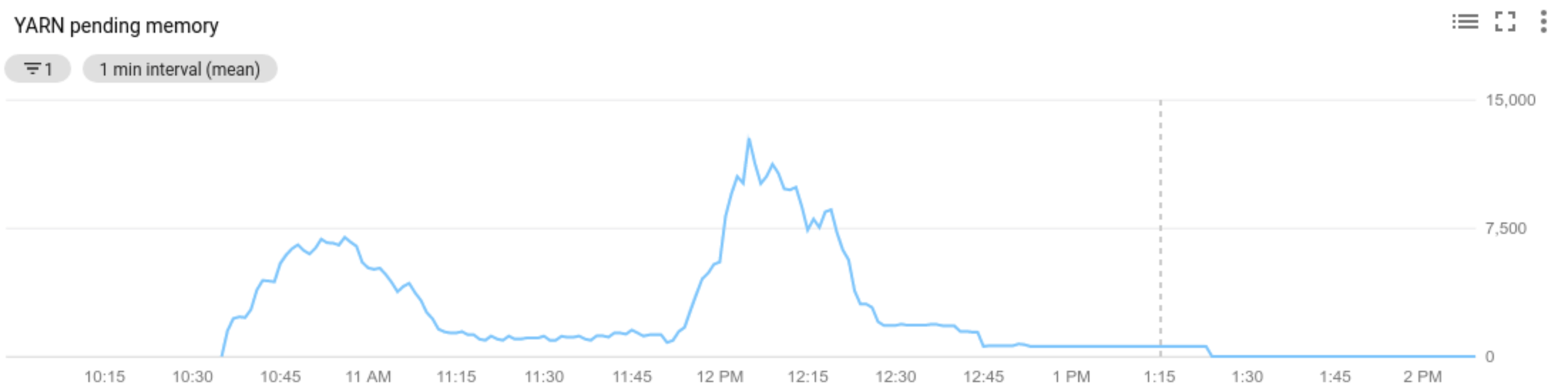
Nilai metrik resource tertunda YARN (Memori Tertunda atau Core Tertunda) menentukan apakah akan menaikkan atau menurunkan skala. Nilai yang lebih besar dari
0menunjukkan bahwa tugas YARN sedang menunggu sumber daya dan penskalaan mungkin diperlukan. Nilai0menunjukkan bahwa YARN memiliki sumber daya yang memadai sehingga penurunan skala atau perubahan lainnya mungkin tidak diperlukan.Jika resource yang menunggu keputusan > 0:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Pending + Available + Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Jika resource yang menunggu keputusan adalah 0:
$estimated\_worker\_count =$
\[ \Biggl \lceil AVERAGE\ during\ cooldown\ period\Big(\frac{Allocated + Reserved}{Resource\ per\ worker}\Big)\Biggr \rceil \]
Secara default, mulai dari image Dataproc 2.2, penskala otomatis memantau memori YARN dan core YARN sehingga
estimated_worker_countdievaluasi secara terpisah untuk memori dan core, dan jumlah pekerja yang lebih besar dipilih. Untuk versi image sebelumnya, autoscaler hanya memantau memori YARN, kecuali jika Anda mengaktifkan penskalaan otomatis berbasis core.$estimated\_worker\_count =$
\[ max(estimated\_worker\_count\_by\_memory,\ estimated\_worker\_count\_by\_cores) \]
\[ estimated\ \Delta worker = estimated\_worker\_count - current\_worker\_count \]
Mengingat perkiraan perubahan yang diperlukan pada jumlah pekerja, penskalaan otomatis menggunakan
scaleUpFactoratauscaleDownFactoruntuk menghitung perubahan sebenarnya pada jumlah pekerja:if estimated Δworkers > 0: actual Δworkers = ROUND_UP(estimated Δworkers * scaleUpFactor) # examples: # ROUND_UP(estimated Δworkers=5 * scaleUpFactor=0.5) = 3 # ROUND_UP(estimated Δworkers=0.8 * scaleUpFactor=0.5) = 1 else: actual Δworkers = ROUND_DOWN(estimated Δworkers * scaleDownFactor) # examples: # ROUND_DOWN(estimated Δworkers=-5 * scaleDownFactor=0.5) = -2 # ROUND_DOWN(estimated Δworkers=-0.8 * scaleDownFactor=0.5) = 0 # ROUND_DOWN(estimated Δworkers=-1.5 * scaleDownFactor=0.5) = 0
scaleUpFactor atau scaleDownFactor 1.0 berarti penskalaan otomatis akan menskalakan sehingga resource yang tertunda atau tersedia adalah 0 (penggunaan sempurna).
Setelah perubahan jumlah pekerja dihitung,
scaleUpMinWorkerFractiondanscaleDownMinWorkerFractionakan bertindak sebagai nilai minimum untuk menentukan apakah penskalaan otomatis akan menskalakan cluster. Pecahan kecil menandakan bahwa penskalaan otomatis harus melakukan penskalaan meskipunΔworkerskecil. Pecahan yang lebih besar berarti penskalaan hanya boleh terjadi jikaΔworkersbesar.IF (Δworkers > scaleUpMinWorkerFraction * current_worker_count) then scale up
IF (abs(Δworkers) > scaleDownMinWorkerFraction * current_worker_count), THEN scale down.
Jika jumlah pekerja yang akan diskalakan cukup besar untuk memicu penskalaan, penskalaan otomatis akan menggunakan batas
minInstancesmaxInstancesdariworkerConfigdansecondaryWorkerConfigdanweight(rasio pekerja primer terhadap sekunder) untuk menentukan cara membagi jumlah pekerja di seluruh grup instance pekerja primer dan sekunder. Hasil penghitungan ini adalah perubahan penskalaan otomatis akhir pada cluster untuk periode penskalaan.Permintaan pengecilan skala penskalaan otomatis akan dibatalkan di cluster yang dibuat dengan versi image 2.0.57+, 2.1.5+, dan versi image yang lebih baru jika:
- penyusutan sedang berlangsung dengan nilai waktu tunggu penghentian tuntas bukan nol, dan
jumlah worker YARN AKTIF ("worker aktif") ditambah perubahan jumlah total worker yang direkomendasikan oleh penskala otomatis (
Δworkers) sama dengan atau lebih besar dariDECOMMISSIONINGworker YARN ("worker yang dihentikan"), seperti yang ditunjukkan dalam formula berikut:IF (active workers + Δworkers ≥ active workers + decommissioning workers) THEN cancel the scaledown operation
Untuk contoh pembatalan penurunan skala, lihat Kapan penskalaan otomatis membatalkan operasi penurunan skala?.
Rekomendasi konfigurasi penskalaan otomatis
Bagian ini berisi rekomendasi untuk membantu Anda mengonfigurasi penskalaan otomatis.
Menghindari penskalaan pekerja primer
Pekerja primer menjalankan Datanode HDFS, sedangkan pekerja sekunder hanya melakukan komputasi.
Penggunaan pekerja sekunder memungkinkan Anda menskalakan resource komputasi secara efisien tanpa
perlu menyediakan penyimpanan, sehingga menghasilkan kemampuan penskalaan yang lebih cepat.
Namenode HDFS dapat memiliki beberapa kondisi persaingan yang menyebabkan HDFS menjadi rusak sehingga penonaktifan tertunda tanpa batas waktu. Untuk
menghindari masalah ini, hindari penskalaan pekerja primer. Contoh:
none
workerConfig:
minInstances: 10
maxInstances: 10
secondaryWorkerConfig:
minInstances: 0
maxInstances: 100
Ada beberapa modifikasi yang perlu dilakukan pada perintah pembuatan cluster:
- Tetapkan
--num-workers=10agar sesuai dengan ukuran grup pekerja utama kebijakan penskalaan otomatis. - Tetapkan
--secondary-worker-type=non-preemptibleuntuk mengonfigurasi pekerja sekunder agar tidak dapat di-preempt. (Kecuali jika preemptible VM diinginkan). - Menyalin konfigurasi hardware dari pekerja utama ke pekerja sekunder. Misalnya, tetapkan
--secondary-worker-boot-disk-size=1000GBagar cocok dengan--worker-boot-disk-size=1000GB.
Menggunakan Mode Fleksibilitas yang Ditingkatkan untuk tugas batch Spark
Gunakan Mode Fleksibilitas yang Ditingkatkan (EFM) dengan penskalaan otomatis untuk:
memungkinkan penurunan skala cluster yang lebih cepat saat tugas sedang berjalan
mencegah gangguan pada tugas yang sedang berjalan karena penyusutan skala cluster
meminimalkan gangguan pada tugas yang sedang berjalan karena preempti pekerja sekunder yang dapat di-preempt
Jika EFM diaktifkan, waktu tunggu penghentian tuntas kebijakan penskalaan otomatis harus ditetapkan ke 0s. Kebijakan penskalaan otomatis hanya boleh menskalakan otomatis pekerja sekunder.
Memilih waktu tunggu penghentian tuntas
Penskalaan otomatis mendukung penonaktifan normal YARN saat menghapus node dari cluster. Penonaktifan yang benar memungkinkan aplikasi menyelesaikan pengacakan data antar-tahap untuk menghindari kemunduran progres tugas. Waktu tunggu penonaktifan yang benar yang diberikan dalam kebijakan penskalaan otomatis adalah batas atas durasi YARN akan menunggu aplikasi yang sedang berjalan (aplikasi yang sedang berjalan saat penonaktifan dimulai) sebelum menghapus node.
Jika proses tidak selesai dalam periode waktu tunggu penonaktifan yang ditentukan, node pekerja akan dimatikan secara paksa, sehingga berpotensi menyebabkan kehilangan data atau gangguan layanan. Untuk membantu menghindari kemungkinan ini, tetapkan waktu tunggu penghentian tuntas ke nilai yang lebih lama dari
tugas terlama yang akan diproses cluster. Misalnya, jika Anda memperkirakan tugas terlama Anda akan berjalan selama satu jam, tetapkan waktu tunggu minimal satu jam (1h).
Pertimbangkan untuk memigrasikan tugas yang memerlukan waktu lebih dari 1 jam ke cluster sementara mereka sendiri untuk menghindari pemblokiran penonaktifan yang lancar.
Setelan scaleUpFactor
scaleUpFactor mengontrol seberapa agresif autoscaler meningkatkan skala cluster.
Tentukan angka antara 0.0 dan 1.0 untuk menetapkan nilai pecahan
dari sumber daya tertunda YARN yang menyebabkan penambahan node.
Misalnya, jika ada 100 container tertunda yang masing-masing meminta 512 MB, maka ada 50 GB memori YARN yang tertunda. Jika scaleUpFactor adalah 0.5, autoscaler akan menambahkan node yang cukup untuk menambahkan memori YARN sebesar 25 GB. Demikian pula, jika
0.1, autoscaler akan menambahkan node yang cukup untuk 5 GB. Perhatikan bahwa nilai ini
sesuai dengan memori YARN, bukan total memori yang tersedia secara fisik di VM.
Titik awal yang baik adalah 0.05 untuk tugas MapReduce dan tugas Spark dengan alokasi dinamis diaktifkan. Untuk tugas Spark dengan jumlah eksekutor tetap dan tugas Tez, gunakan
1.0. scaleUpFactor 1.0 berarti penskalaan otomatis akan menskalakan sehingga resource yang tertunda atau tersedia adalah 0 (penggunaan sempurna).
Setelan scaleDownFactor
scaleDownFactor mengontrol seberapa agresif autoscaler menurunkan skala cluster. Tentukan angka antara 0.0 dan 1.0 untuk menetapkan nilai pecahan
dari resource yang tersedia di YARN yang menyebabkan penghapusan node.
Biarkan nilai ini di 1.0 untuk sebagian besar cluster multi-pekerjaan yang perlu menskalakan naik dan turun secara sering. Sebagai hasil dari penghentian tuntas, operasi penurunan skala jauh lebih lambat daripada operasi peningkatan skala. Menetapkan scaleDownFactor=1.0 akan menetapkan
laju penurunan skala yang agresif, yang meminimalkan jumlah operasi penurunan skala
yang diperlukan untuk mencapai ukuran cluster yang sesuai.
Untuk cluster yang memerlukan stabilitas lebih tinggi, tetapkan scaleDownFactor yang lebih rendah untuk laju pengurangan skala yang lebih lambat.
Tetapkan nilai ini ke 0.0 untuk mencegah penurunan skala cluster, misalnya, saat
menggunakan cluster sementara atau tugas tunggal.
Menetapkan scaleUpMinWorkerFraction dan scaleDownMinWorkerFraction
scaleUpMinWorkerFraction dan scaleDownMinWorkerFraction digunakan
dengan scaleUpFactor atau scaleDownFactor dan memiliki nilai
default 0.0. Nilai ini merepresentasikan nilai minimum peningkatan atau penurunan fraksional ukuran cluster yang diperlukan untuk mengeluarkan permintaan naik atau turun skala.
Contoh: Autoscaler tidak akan mengeluarkan permintaan update untuk menambahkan 5 pekerja ke cluster 100 node kecuali jika scaleUpMinWorkerFraction kurang dari atau sama dengan 0.05
(5%). Jika disetel ke 0.1, autoscaler tidak akan mengeluarkan permintaan untuk meningkatkan skala cluster.
Demikian pula, jika scaleDownMinWorkerFraction adalah 0.05, autoscaler tidak akan
menghapus setidaknya 5 node.
Nilai default 0.0 menandakan tidak ada nilai minimum.
Menetapkan
scaleDownMinWorkerFractionthresholds yang lebih tinggi pada cluster besar
(> 100 node) untuk menghindari operasi penskalaan kecil yang tidak perlu
sangat direkomendasikan.
Pilih periode pendinginan
cooldownPeriod menetapkan jangka waktu saat autoscaler tidak akan mengeluarkan permintaan untuk mengubah ukuran cluster. Anda dapat menggunakannya
untuk membatasi frekuensi perubahan autoscaler pada ukuran cluster.
cooldownPeriod minimum dan default
adalah dua menit. Jika cooldownPeriod yang lebih pendek ditetapkan dalam kebijakan, perubahan workload akan lebih cepat memengaruhi ukuran cluster, tetapi cluster dapat melakukan penskalaan naik dan turun secara tidak perlu. Praktik yang direkomendasikan adalah menetapkan
scaleUpMinWorkerFraction dan scaleDownMinWorkerFraction
kebijakan ke nilai selain nol saat menggunakan cooldownPeriod yang lebih pendek. Hal ini memastikan bahwa
cluster hanya di-scale up atau down jika perubahan penggunaan resource cukup
untuk menjamin pembaruan cluster.
Jika workload Anda sensitif terhadap perubahan ukuran cluster, Anda dapat memperpanjang periode cooldown. Misalnya, jika Anda menjalankan tugas pemrosesan batch, Anda dapat menyetel periode cooldown menjadi 10 menit atau lebih. Bereksperimenlah dengan periode jeda yang berbeda untuk menemukan nilai yang paling sesuai untuk workload Anda.
Batas jumlah pekerja dan bobot grup
Setiap grup pekerja memiliki minInstances dan maxInstances yang mengonfigurasi batas ketat pada ukuran setiap grup.
Setiap grup juga memiliki parameter yang disebut weight yang mengonfigurasi target
keseimbangan antara kedua grup. Perhatikan bahwa parameter ini hanya merupakan petunjuk, dan jika
grup mencapai ukuran minimum atau maksimumnya, node hanya akan ditambahkan atau dihapus
dari grup lain. Jadi, weight hampir selalu dapat dibiarkan pada 1 default.
Menggunakan penskalaan otomatis berbasis core
Untuk aplikasi yang intensif CPU, praktik terbaiknya adalah menggunakan Dominant Resource Calculator untuk alokasi resource. Ini adalah konfigurasi YARN default mulai dari versi image Dataproc 2.2. Dengan versi image sebelumnya, Dataproc mengonfigurasi YARN untuk menggunakan metrik memori untuk alokasi resource kecuali jika Anda menyetel properti berikut saat membuat cluster untuk mengonfigurasi YARN agar menggunakan Dominant Resource Calculator:
capacity-scheduler:yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator
Metrik dan log penskalaan otomatis
Resource dan alat berikut dapat membantu Anda memantau operasi penskalaan otomatis dan pengaruhnya terhadap cluster dan tugasnya.
Cloud Monitoring
Gunakan Cloud Monitoring untuk:
- melihat metrik yang digunakan oleh penskalaan otomatis
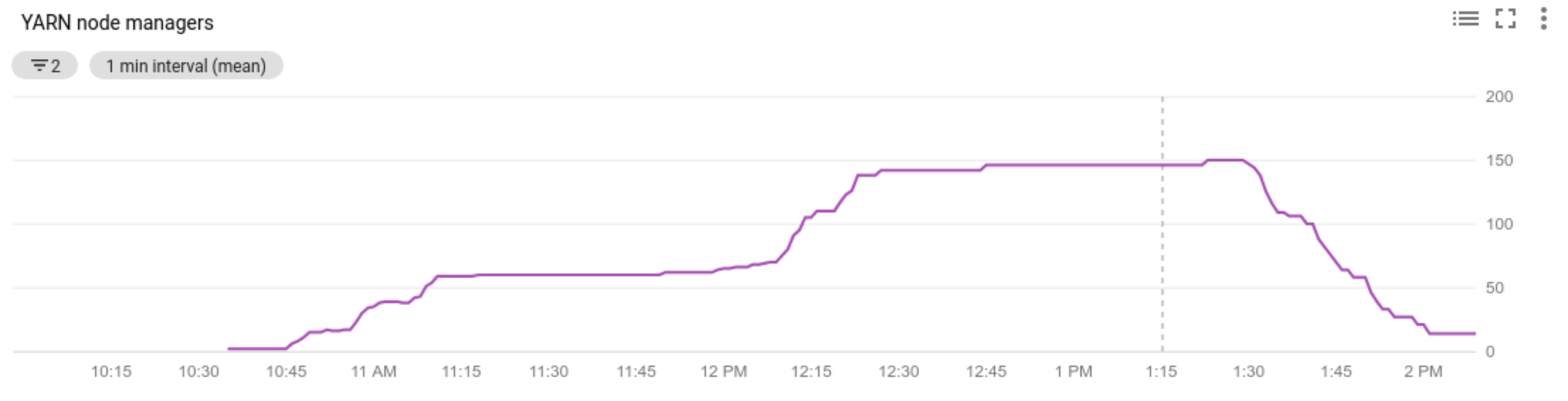
- melihat jumlah Pengelola Node di cluster Anda
- memahami alasan penskalaan otomatis melakukan atau tidak melakukan penskalaan cluster Anda
Cloud Logging
Gunakan Cloud Logging untuk melihat log dari Penskala Otomatis Dataproc.
1) Temukan log untuk cluster Anda.
2) Pilih dataproc.googleapis.com/autoscaler.
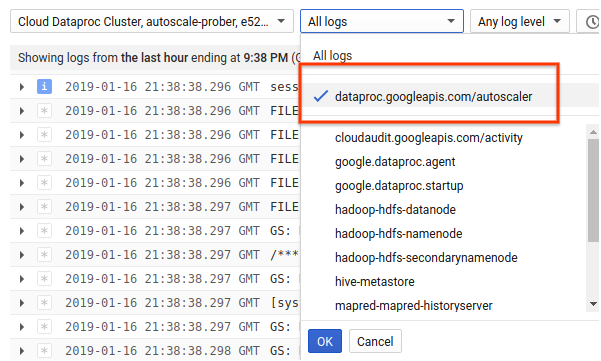
3) Luaskan pesan log untuk melihat kolom status. Log dalam format JSON yang dapat dibaca mesin.
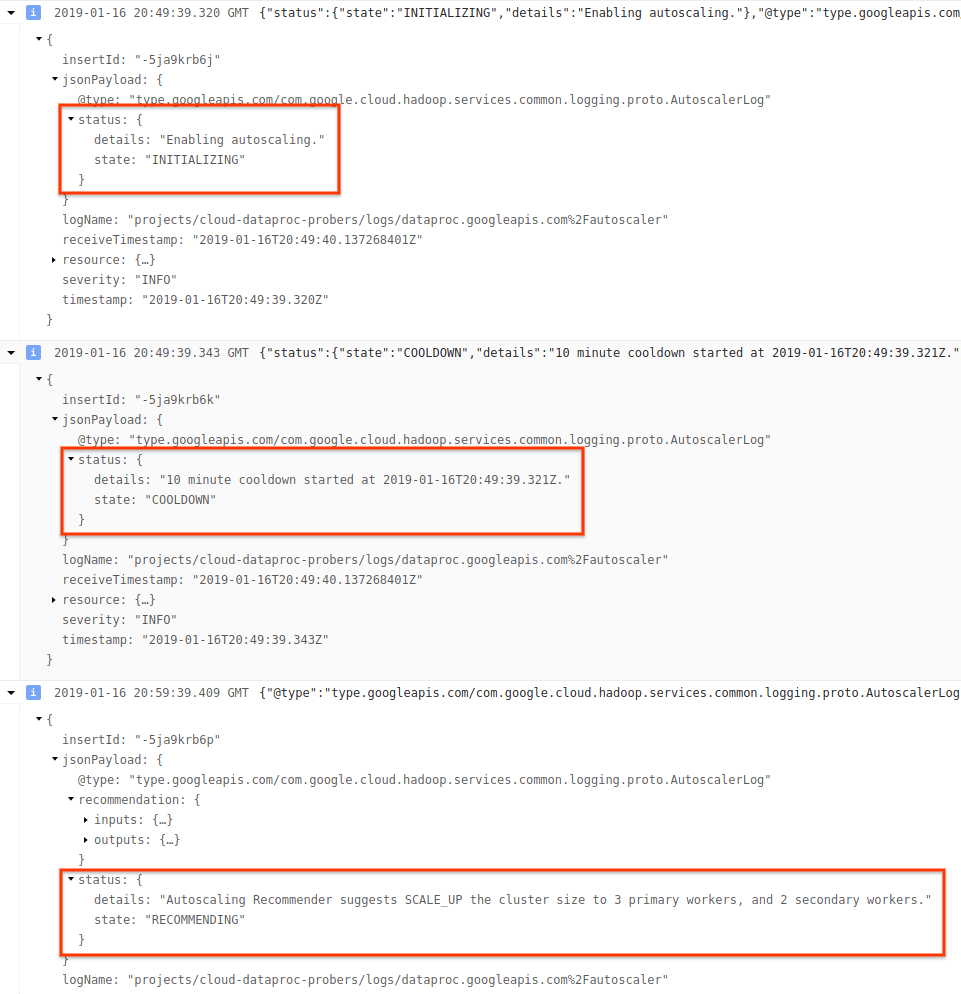
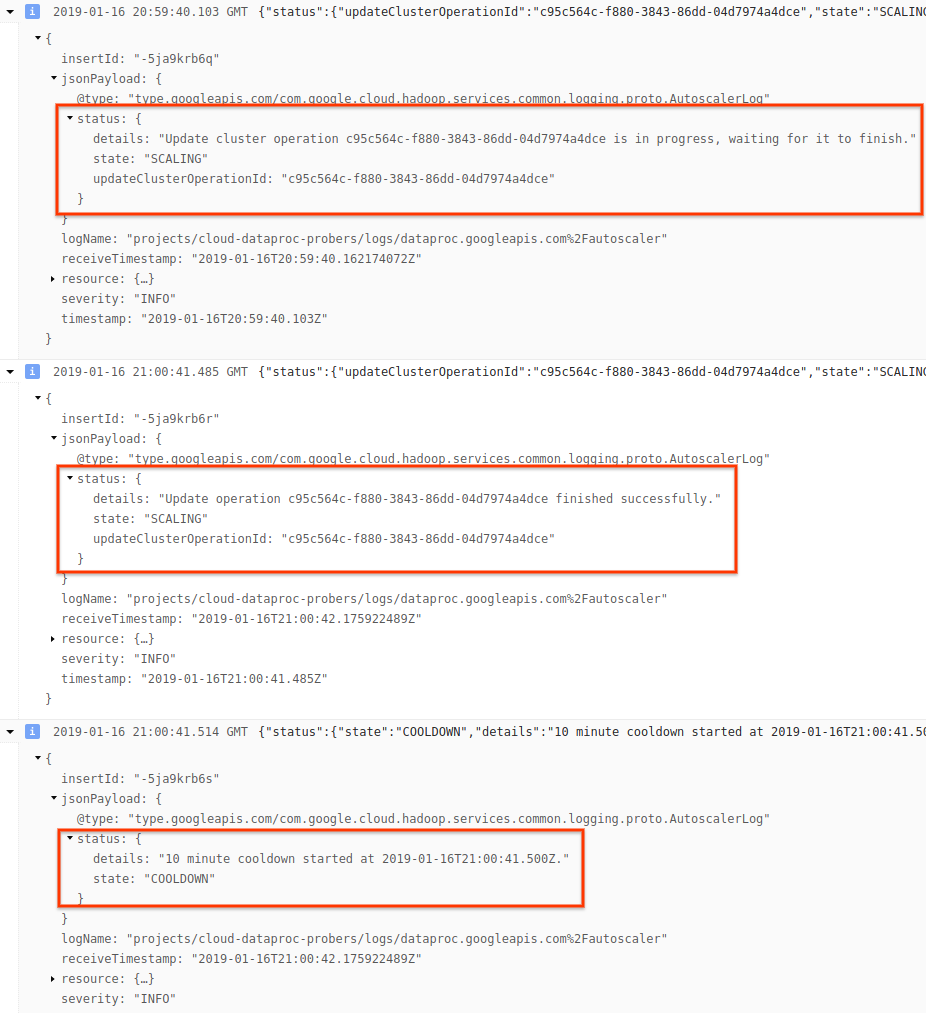
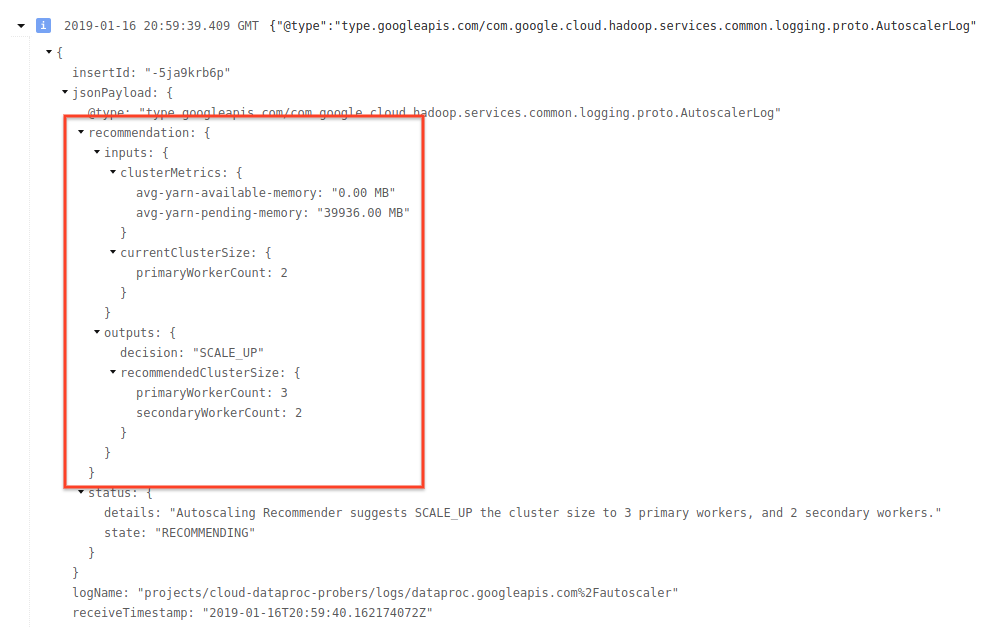
4) Perluas pesan log untuk melihat rekomendasi penskalaan, metrik yang digunakan untuk keputusan penskalaan, ukuran cluster asli, dan ukuran cluster target baru.
Latar belakang: Penskalaan otomatis dengan Apache Hadoop dan Apache Spark
Bagian berikut membahas cara penskalaan otomatis beroperasi (atau tidak beroperasi) dengan Hadoop YARN dan Hadoop MapReduce, serta dengan Apache Spark, Spark Streaming, dan Spark Structured Streaming.
Metrik Hadoop YARN
Penskalaan otomatis berpusat pada metrik Hadoop YARN berikut:
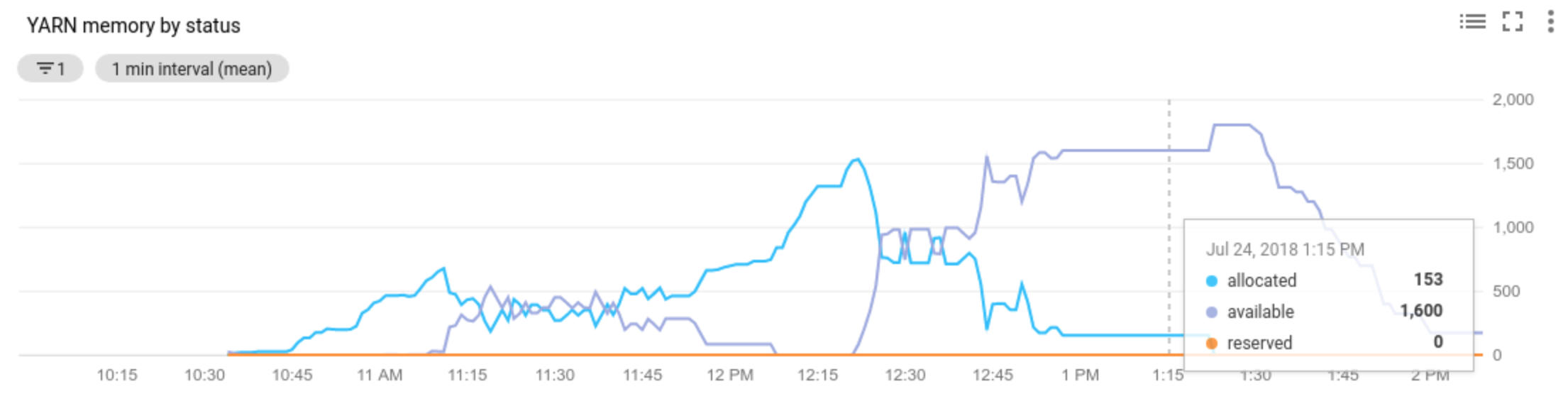
Allocated resourcemengacu pada total resource YARN yang digunakan dengan menjalankan kontainer di seluruh cluster. Jika ada 6 container yang berjalan yang dapat menggunakan hingga 1 unit resource, ada 6 resource yang dialokasikan.Available resourceadalah resource YARN di cluster yang tidak digunakan oleh container yang dialokasikan. Jika ada 10 unit resource di semua pengelola node dan 6 di antaranya dialokasikan, berarti ada 4 resource yang tersedia. Jika ada resource yang tersedia (tidak digunakan) di cluster, penskalaan otomatis dapat menghapus pekerja dari cluster.Pending resourceadalah jumlah permintaan resource YARN untuk container yang tertunda. Container yang tertunda menunggu ruang untuk berjalan di YARN. Resource yang tertunda tidak nol hanya jika resource yang tersedia nol atau terlalu kecil untuk dialokasikan ke container berikutnya. Jika ada penampung yang tertunda, penskalaan otomatis dapat menambahkan pekerja ke cluster.
Anda dapat melihat metrik ini di Cloud Monitoring. Secara default, memori YARN adalah 0,8 * total memori di cluster, dengan sisa memori yang dicadangkan untuk penggunaan daemon dan sistem operasi lainnya, seperti cache halaman. Anda dapat mengganti nilai default dengan setelan konfigurasi YARN "yarn.nodemanager.resource.memory-mb" (lihat Apache Hadoop YARN, HDFS, Spark, dan properti terkait).
Penskalaan otomatis dan Hadoop MapReduce
MapReduce menjalankan setiap tugas peta dan pengurangan sebagai container YARN terpisah. Saat pekerjaan dimulai, MapReduce mengirimkan permintaan container untuk setiap tugas peta, sehingga terjadi lonjakan besar dalam memori YARN yang tertunda. Saat tugas peta selesai, memori yang menunggu proses akan berkurang.
Setelah mapreduce.job.reduce.slowstart.completedmaps selesai (95% secara default di Dataproc), MapReduce mengantrekan permintaan penampung untuk semua pereduksi, sehingga menyebabkan lonjakan lain dalam memori yang tertunda.
Kecuali jika tugas map dan reduce Anda memerlukan waktu beberapa menit atau lebih, jangan
menetapkan nilai tinggi untuk penskalaan otomatis scaleUpFactor. Menambahkan pekerja ke cluster memerlukan waktu setidaknya 1,5 menit, jadi pastikan ada pekerjaan tertunda yang cukup untuk memanfaatkan pekerja baru selama beberapa menit. Titik awal yang baik adalah menyetel scaleUpFactor ke 0,05 (5%) atau 0,1 (10%) dari memori yang menunggu keputusan.
Penskalaan Otomatis dan Spark
Spark menambahkan lapisan penjadwalan tambahan di atas YARN. Secara khusus, alokasi dinamis Spark Core membuat permintaan ke YARN untuk menjalankan eksekutor Spark di penampung, kemudian menjadwalkan tugas Spark di thread pada eksekutor tersebut. Cluster Dataproc mengaktifkan alokasi dinamis secara default, sehingga eksekutor ditambahkan dan dihapus sesuai kebutuhan.
Spark selalu meminta container ke YARN, tetapi tanpa alokasi dinamis, Spark hanya meminta container di awal tugas. Dengan alokasi dinamis, aplikasi akan menghapus container, atau meminta container baru, sesuai kebutuhan.
Spark dimulai dari sejumlah kecil eksekutor – 2 di cluster penskalaan otomatis – dan
terus menggandakan jumlah eksekutor selama ada tugas yang tertunda.
Hal ini memperlancar memori yang tertunda (lebih sedikit lonjakan memori yang tertunda). Sebaiknya tetapkan
scaleUpFactor penskalaan otomatis ke angka yang besar, seperti 1,0 (100%), untuk tugas Spark.
Menonaktifkan alokasi dinamis Spark
Jika Anda menjalankan tugas Spark terpisah yang tidak diuntungkan dari alokasi dinamis Spark, Anda dapat menonaktifkan alokasi dinamis Spark dengan menyetel
spark.dynamicAllocation.enabled=false dan menyetel spark.executor.instances.
Anda tetap dapat menggunakan penskalaan otomatis untuk menskalakan cluster naik dan turun saat tugas Spark yang terpisah berjalan.
Tugas Spark dengan data yang di-cache
Tetapkan spark.dynamicAllocation.cachedExecutorIdleTimeout atau hapus cache set data jika tidak diperlukan lagi. Secara default, Spark tidak menghapus eksekutor yang telah
meng-cache data, yang akan mencegah penskalaan cluster.
Penskalaan otomatis dan Spark Streaming
Karena Spark Streaming memiliki versi alokasi dinamis sendiri yang menggunakan sinyal khusus streaming untuk menambahkan dan menghapus eksekutor, tetapkan
spark.streaming.dynamicAllocation.enabled=truedan nonaktifkan alokasi dinamis Spark Core dengan menetapkanspark.dynamicAllocation.enabled=false.Jangan gunakan Penghentian tuntas (penskalaan otomatis
gracefulDecommissionTimeout) dengan tugas Spark Streaming. Sebagai gantinya, untuk menghapus pekerja dengan aman menggunakan penskalaan otomatis, konfigurasi pembuatan titik pemeriksaan untuk toleransi kesalahan.
Atau, untuk menggunakan Spark Streaming tanpa penskalaan otomatis:
- Menonaktifkan alokasi dinamis Spark Core (
spark.dynamicAllocation.enabled=false), dan - Tetapkan jumlah eksekutor (
spark.executor.instances) untuk tugas Anda. Lihat Properti cluster.
Penskalaan Otomatis dan Spark Structured Streaming
Penskalaan otomatis tidak kompatibel dengan Spark Structured Streaming karena Spark Structured Streaming tidak mendukung alokasi dinamis (lihat SPARK-24815: Structured Streaming should support dynamic allocation).
Mengontrol penskalaan otomatis melalui partisi dan paralelisme
Meskipun paralelisme biasanya ditetapkan atau ditentukan oleh resource cluster (misalnya, jumlah blok HDFS dikontrol oleh jumlah tugas), dengan penskalaan otomatis, hal sebaliknya berlaku: penskalaan otomatis menetapkan jumlah pekerja sesuai dengan paralelisme tugas. Berikut adalah panduan untuk membantu Anda menyetel paralelisme tugas:
- Meskipun Dataproc menetapkan jumlah tugas reduce MapReduce default berdasarkan ukuran cluster awal cluster Anda, Anda dapat menetapkan
mapreduce.job.reducesuntuk meningkatkan paralelisme fase reduce. - Paralelisme Spark SQL dan Dataframe ditentukan oleh
spark.sql.shuffle.partitions, yang secara default adalah 200. - Fungsi RDD Spark secara default adalah
spark.default.parallelism, yang ditetapkan ke jumlah core pada node pekerja saat tugas dimulai. Namun, semua fungsi RDD yang membuat pengacakan menggunakan parameter untuk jumlah partisi, yang menggantikanspark.default.parallelism.
Anda harus memastikan data Anda dipartisi secara merata. Jika ada kemiringan kunci yang signifikan, satu atau beberapa tugas mungkin memerlukan waktu yang jauh lebih lama daripada tugas lain, sehingga menyebabkan pemanfaatan yang rendah.
Setelan properti Spark dan Hadoop default penskalaan otomatis
Cluster penskalaan otomatis memiliki nilai properti cluster default yang membantu menghindari kegagalan tugas saat pekerja utama dihapus atau pekerja sekunder di-preempt. Anda dapat mengganti nilai default ini saat membuat cluster dengan penskalaan otomatis (lihat Properti Cluster).
Default untuk meningkatkan jumlah maksimum upaya mencoba ulang untuk tugas, master aplikasi, dan tahap:
yarn:yarn.resourcemanager.am.max-attempts=10 mapred:mapreduce.map.maxattempts=10 mapred:mapreduce.reduce.maxattempts=10 spark:spark.task.maxFailures=10 spark:spark.stage.maxConsecutiveAttempts=10
Default untuk mereset penghitung percobaan ulang (berguna untuk tugas Spark Streaming yang berjalan lama):
spark:spark.yarn.am.attemptFailuresValidityInterval=1h spark:spark.yarn.executor.failuresValidityInterval=1h
Secara default, mekanisme alokasi dinamis mulai lambat Spark dimulai dari ukuran kecil:
spark:spark.executor.instances=2
Pertanyaan Umum (FAQ)
Bagian ini berisi pertanyaan dan jawaban umum tentang penskalaan otomatis.
Dapatkah penskalaan otomatis diaktifkan di cluster ketersediaan tinggi dan cluster node tunggal?
Penskalaan otomatis dapat diaktifkan di cluster ketersediaan tinggi, tetapi tidak di cluster node tunggal (Cluster node tunggal tidak mendukung pengubahan ukuran).
Dapatkah Anda mengubah ukuran cluster penskalaan otomatis secara manual?
Ya. Anda dapat memutuskan untuk mengubah ukuran cluster secara manual sebagai tindakan sementara saat menyesuaikan kebijakan penskalaan otomatis. Namun, perubahan ini hanya akan memberikan efek sementara, dan Penskalaan Otomatis pada akhirnya akan menskalakan kembali cluster.
Daripada mengubah ukuran cluster penskalaan otomatis secara manual, pertimbangkan:
Memperbarui kebijakan penskalaan otomatis. Setiap perubahan yang dilakukan pada kebijakan penskalaan otomatis akan memengaruhi semua cluster yang saat ini menggunakan kebijakan tersebut (lihat Penggunaan kebijakan multi-cluster).
Melepaskan kebijakan dan menskalakan cluster secara manual ke ukuran yang diinginkan.
Mendapatkan dukungan Dataproc.
Apa perbedaan Dataproc dengan penskalaan otomatis Dataflow?
Lihat penskalaan otomatis horizontal Dataflow dan penskalaan otomatis vertikal Dataflow Prime.
Dapatkah tim developer Dataproc mereset status cluster dari ERROR kembali ke RUNNING?
Secara umum, tidak. Tindakan ini memerlukan upaya manual untuk memverifikasi apakah aman untuk mereset status cluster, dan sering kali cluster tidak dapat direset tanpa langkah-langkah manual lainnya, seperti memulai ulang HDFS NameNode.
Dataproc menyetel status cluster ke ERROR jika tidak dapat menentukan status cluster setelah operasi gagal. Cluster di
ERROR tidak diskalakan otomatis. Penyebab umumnya meliputi:
Error yang ditampilkan dari Compute Engine API, sering kali selama gangguan Compute Engine.
HDFS mengalami kerusakan karena bug dalam penonaktifan HDFS.
Error Dataproc Control API seperti "Task lease expired".
Hapus dan buat ulang cluster yang statusnya ERROR.
Kapan penskalaan otomatis membatalkan operasi penurunan skala?
Grafik berikut adalah ilustrasi yang menunjukkan kapan penskalaan otomatis akan membatalkan operasi pengecilan skala (lihat juga Cara kerja penskalaan otomatis).
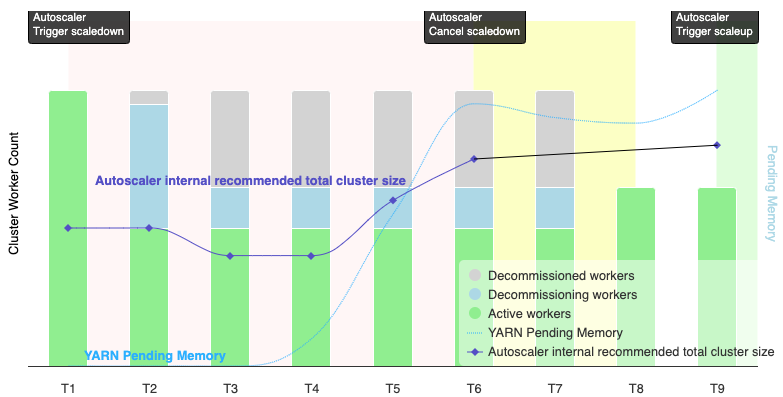
Catatan:
- Cluster mengaktifkan penskalaan otomatis hanya berdasarkan metrik memori YARN (default).
- T1-T9 merepresentasikan interval jeda saat autoscaler mengevaluasi jumlah pekerja (waktu peristiwa telah disederhanakan).
- Diagram batang bertumpuk menunjukkan jumlah pekerja YARN cluster yang aktif, dalam proses penonaktifan, dan telah dinonaktifkan.
- Jumlah pekerja yang direkomendasikan autoscaler (garis hitam) didasarkan pada metrik memori YARN, jumlah pekerja aktif YARN, dan setelan kebijakan penskalaan otomatis (lihat Cara kerja penskalaan otomatis).
- Area latar belakang merah menunjukkan periode saat operasi penurunan skala sedang berjalan.
- Area latar belakang kuning menunjukkan periode saat operasi pengecilan dibatalkan.
- Area latar belakang hijau menunjukkan periode operasi penskalaan.
Operasi berikut terjadi pada waktu berikut:
T1: Autoscaler memulai operasi penurunan skala penghentian normal untuk menurunkan skala sekitar setengah dari pekerja cluster saat ini.
T2: Autoscaler terus memantau metrik cluster. Rekomendasi pengurangan skala tidak berubah, dan operasi pengurangan skala berlanjut. Beberapa pekerja telah dihentikan, dan pekerja lainnya sedang dihentikan (Dataproc akan menghapus pekerja yang dihentikan).
T3: Autoscaler menghitung bahwa jumlah pekerja dapat diturunkan lebih lanjut, kemungkinan karena memori YARN tambahan tersedia. Namun, karena jumlah pekerja aktif ditambah perubahan jumlah pekerja yang direkomendasikan tidak sama dengan atau lebih besar dari jumlah pekerja aktif ditambah pekerja yang dihentikan, kriteria pembatalan pengurangan skala tidak terpenuhi, dan penskala otomatis tidak membatalkan operasi pengurangan skala.
T4: YARN melaporkan peningkatan memori tertunda. Namun, autoscaler tidak mengubah rekomendasi jumlah pekerja. Seperti pada T3, kriteria pembatalan penyusutan skala tetap tidak terpenuhi, dan penskalaan otomatis tidak membatalkan operasi penyusutan skala.
T5: Memori tertunda YARN meningkat, dan perubahan jumlah pekerja yang direkomendasikan oleh penskala otomatis meningkat. Namun, karena jumlah pekerja aktif ditambah perubahan jumlah pekerja yang direkomendasikan kurang dari jumlah pekerja aktif ditambah pekerja yang akan dihentikan, kriteria pembatalan tetap tidak terpenuhi, dan operasi pengurangan skala tidak dibatalkan.
T6: Memori tertunda YARN meningkat lebih lanjut. Jumlah pekerja aktif ditambah perubahan jumlah pekerja yang direkomendasikan oleh autoscaler kini lebih besar daripada jumlah pekerja aktif ditambah pekerja yang dihentikan. Kriteria pembatalan terpenuhi, dan autoscaler membatalkan operasi pengecilan.
T7: Autoscaler sedang menunggu pembatalan operasi pengurangan skala selesai. Autoscaler tidak mengevaluasi dan merekomendasikan perubahan jumlah pekerja selama interval ini.
T8: Pembatalan operasi pengurangan skala selesai. Worker yang dihentikan ditambahkan ke cluster dan menjadi aktif. Autoscaler mendeteksi penyelesaian pembatalan operasi pengurangan skala, dan menunggu periode evaluasi berikutnya (T9) untuk menghitung jumlah pekerja yang direkomendasikan.
T9: Tidak ada operasi yang aktif pada waktu T9. Berdasarkan kebijakan penskalaan otomatis dan metrik YARN, autoscaler merekomendasikan operasi peningkatan skala.