선택적 구성요소 기능을 사용하여 Dataproc 클러스터를 만들 때 Flink와 같은 추가 구성요소를 활성화할 수 있습니다. 이 페이지에서는 Apache Flink 선택적 구성요소(Flink 클러스터)가 활성화된 Dataproc 클러스터를 만든 후 클러스터에서 Flink 작업을 실행하는 방법을 보여줍니다.
Flink 클러스터를 사용하여 다음을 수행할 수 있습니다.
Google Cloud 콘솔, Google Cloud CLI 또는 Dataproc API에서 Dataproc
Jobs리소스를 사용하여 Flink 작업 실행Flink 클러스터 마스터 노드에서 실행되는
flinkCLI를 사용하여 Flink 작업 실행
Dataproc Flink 클러스터 만들기
Google Cloud 콘솔, Google Cloud CLI 또는 Dataproc API를 사용하여 클러스터에서 Flink 구성요소가 활성화된 Dataproc 클러스터를 만들 수 있습니다.
권장사항: Flink 구성요소가 포함된 마스터 1개 표준 VM 클러스터를 사용하세요. Dataproc 고가용성 모드 클러스터(마스터 VM 3개)는 Flink 고가용성 모드를 지원하지 않습니다.
콘솔
Google Cloud 콘솔을 사용하여 Dataproc Flink 클러스터를 만들려면 다음 단계를 수행합니다.
Dataproc Compute Engine에서 클러스터 만들기 페이지를 엽니다.
- 클러스터 설정 패널이 선택되었습니다.
- 버전 관리 섹션에서 이미지 유형 및 버전을 확인하거나 변경합니다. 클러스터 이미지 버전에 따라 클러스터에 설치된 Flink 구성요소의 버전이 결정됩니다.
- 클러스터에서 Flink 구성요소를 활성화하려면 이미지 버전이 1.5 이상이어야 합니다(각 Dataproc 이미지 출시 버전에 포함된 구성요소 버전 목록을 보려면 지원되는 Dataproc 버전 참조).
- Dataproc Jobs API를 통해 Flink 작업을 실행하려면 이미지 버전이 [미정] 이상이어야 합니다(Dataproc Flink 작업 실행 참조).
- 구성요소 섹션에서 다음을 수행합니다.
- 구성요소 게이트웨이 아래에서 구성요소 게이트웨이 사용 설정을 선택합니다. Flink 기록 서버 UI에 대한 구성요소 게이트웨이 링크를 활성화하려면 구성요소 게이트웨이를 사용 설정해야 합니다. 구성요소 게이트웨이를 사용 설정하면 Flink 클러스터에서 실행되는 Flink 작업 관리자 웹 인터페이스에 액세스할 수 있습니다.
- 선택적 구성요소 아래에서 클러스터에서 활성화할 Flink 및 기타 선택적인 구성요소를 선택합니다.
- 버전 관리 섹션에서 이미지 유형 및 버전을 확인하거나 변경합니다. 클러스터 이미지 버전에 따라 클러스터에 설치된 Flink 구성요소의 버전이 결정됩니다.
클러스터 맞춤설정(선택사항) 패널을 클릭합니다.
클러스터 속성 섹션에서 선택적인 각 클러스터 속성에 대해 속성 추가를 클릭하여 클러스터에 추가합니다.
flink프리픽스가 있는 속성을 추가하여 클러스터에서 실행되는 Flink 애플리케이션의 기본값으로 작동하는/etc/flink/conf/flink-conf.yaml에 포함된 Flink 속성을 구성할 수 있습니다.예:
flink:historyserver.archive.fs.dir을 설정하여 Flink 작업 기록 파일을 작성할 Cloud Storage 위치를 지정합니다(이 위치는 Flink 클러스터에서 실행되는 Flink 기록 서버에서 사용됨).flink:taskmanager.numberOfTaskSlots=n으로 Flink 태스크 슬롯을 설정합니다.
커스텀 클러스터 메타데이터 섹션에서 메타데이터 추가를 클릭하여 선택적 메타데이터를 추가합니다. 예를 들어
flink-start-yarn-sessiontrue를 추가하여 클러스터 마스터 노드의 백그라운드에서 Flink YARN 데몬(/usr/bin/flink-yarn-daemon)을 실행하면 Flink YARN 세션을 시작할 수 있습니다(Flink 세션 모드 참조).
Dataproc 이미지 버전 2.0 이하를 사용하는 경우 보안 관리(선택사항) 패널을 클릭하고 프로젝트 액세스에서
Enables the cloud-platform scope for this cluster를 선택합니다.cloud-platform범위는 Dataproc 이미지 버전 2.1 이상을 사용하는 클러스터를 만들 때 기본적으로 사용 설정됩니다.
- 클러스터 설정 패널이 선택되었습니다.
만들기를 클릭하여 클러스터를 만듭니다.
gcloud
gcloud CLI를 사용하여 Dataproc Flink 클러스터를 만들려면 gcloud dataproc clusters create 명령어를 터미널 창에서 로컬로 또는 Cloud Shell에서 다음과 같이 실행합니다.
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
참고:
- CLUSTER_NAME: 클러스터의 이름을 지정합니다.
- REGION: 클러스터가 위치할 Compute Engine 리전을 지정합니다.
DATAPROC_IMAGE_VERSION: 클러스터에 사용할 이미지 버전을 지정합니다(선택사항). 클러스터 이미지 버전에 따라 클러스터에 설치된 Flink 구성요소의 버전이 결정됩니다.
클러스터에서 Flink 구성요소를 활성화하려면 이미지 버전이 1.5 이상이어야 합니다(각 Dataproc 이미지 출시 버전에 포함된 구성요소 버전 목록을 보려면 지원되는 Dataproc 버전 참조).
Dataproc Jobs API를 통해 Flink 작업을 실행하려면 이미지 버전이 [미정] 이상이어야 합니다(Dataproc Flink 작업 실행 참조).
--optional-components: 클러스터에서 Flink 작업 및 Flink HistoryServer 웹 서비스를 실행하려면FLINK구성요소를 지정해야 합니다.--enable-component-gateway: Flink 기록 서버 UI에 대한 구성요소 게이트웨이 링크를 활성화하려면 구성요소 게이트웨이를 사용 설정해야 합니다. 구성요소 게이트웨이를 사용 설정하면 Flink 클러스터에서 실행되는 Flink 작업 관리자 웹 인터페이스에 액세스할 수 있습니다.PROPERTIES. 클러스터 속성을 한 개 이상 지정합니다(선택사항).
이미지 버전
2.0.67+ 및2.1.15+로 Dataproc 클러스터를 만들 때--properties플래그를 사용하여/etc/flink/conf/flink-conf.yaml에 포함된 클러스터에서 실행하는 Flink 애플리케이션의 기본값으로 작동할 Flink 속성을 구성할 수 있습니다.flink:historyserver.archive.fs.dir을 설정하여 Flink 작업 기록 파일을 작성할 Cloud Storage 위치를 지정할 수 있습니다(이 위치는 Flink 클러스터에서 실행되는 Flink 기록 서버에서 사용됨).여러 속성 예시:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2기타 플래그:
- 선택사항인
--metadata flink-start-yarn-session=true를 추가하여 클러스터 마스터 노드의 백그라운드에서 Flink YARN 데몬(/usr/bin/flink-yarn-daemon)을 실행하면 Flink YARN 세션을 시작할 수 있습니다(Flink 세션 모드 참조).
- 선택사항인
2.0 이하 이미지 버전을 사용할 때는 클러스터별로 Google Cloud API에 액세스할 수 있도록
--scopes=https://www.googleapis.com/auth/cloud-platform플래그를 추가할 수 있습니다(범위 권장사항 참고).cloud-platform범위는 Dataproc 이미지 버전 2.1 이상을 사용하는 클러스터를 만들 때 기본적으로 사용 설정됩니다.
API
Dataproc API를 사용하여 Dataproc Flink 클러스터를 만들려면 다음과 같이 clusters.create 요청을 제출합니다.
참고:
SoftwareConfig.Component를
FLINK로 설정합니다.선택적으로
SoftwareConfig.imageVersion을 설정하여 클러스터에서 사용할 이미지 버전을 지정할 수 있습니다. 클러스터 이미지 버전에 따라 클러스터에 설치된 Flink 구성요소의 버전이 결정됩니다.클러스터에서 Flink 구성요소를 활성화하려면 이미지 버전이 1.5 이상이어야 합니다(각 Dataproc 이미지 출시 버전에 포함된 구성요소 버전 목록을 보려면 지원되는 Dataproc 버전 참조).
Dataproc Jobs API를 통해 Flink 작업을 실행하려면 이미지 버전이 [미정] 이상이어야 합니다(Dataproc Flink 작업 실행 참조).
EndpointConfig.enableHttpPortAccess를
true로 설정하여 Flink 기록 서버 UI에 대한 구성요소 게이트웨이 링크를 사용 설정합니다. 구성요소 게이트웨이를 사용 설정하면 Flink 클러스터에서 실행되는 Flink 작업 관리자 웹 인터페이스에 액세스할 수 있습니다.필요에 따라
SoftwareConfig.properties를 설정하여 클러스터 속성을 한 개 이상 지정할 수 있습니다.- 클러스터에서 실행하는 Flink 애플리케이션의 기본값으로 작동하는 Flink 속성을 지정할 수 있습니다. 예를 들어
flink:historyserver.archive.fs.dir을 설정하여 Flink 작업 기록 파일을 작성할 Cloud Storage 위치를 지정할 수 있습니다(이 위치는 Flink 클러스터에서 실행되는 Flink 기록 서버에서 사용됨).
- 클러스터에서 실행하는 Flink 애플리케이션의 기본값으로 작동하는 Flink 속성을 지정할 수 있습니다. 예를 들어
선택적으로 다음을 설정할 수 있습니다.
GceClusterConfig.metadata. 예를 들어flink-start-yarn-sessiontrue를 추가하여 클러스터 마스터 노드의 백그라운드에서 Flink YARN 데몬(/usr/bin/flink-yarn-daemon)을 실행하면 Flink YARN 세션을 시작할 수 있습니다(Flink 세션 모드 참조).- 2.0 이전 이미지 버전을 사용하여 클러스터에서 Google CloudAPI에 액세스할 때는 GceClusterConfig.serviceAccountScopes를
https://www.googleapis.com/auth/cloud-platform(cloud-platform범위)으로 설정합니다(범위 권장사항 참조).cloud-platform범위는 Dataproc 이미지 버전 2.1 이상을 사용하는 클러스터를 만들 때 기본적으로 사용 설정됩니다.
Flink 클러스터를 만든 후
- 구성요소 게이트웨이의
Flink History Server링크를 사용하여 Flink 클러스터에서 실행되는 Flink 기록 서버를 확인합니다. - 구성요소 게이트웨이에서
YARN ResourceManager link를 사용하여 Flink 클러스터에서 실행되는 Flink 작업 관리자 웹 인터페이스를 확인합니다. - Dataproc 영구 기록 서버를 만들어 기존 및 삭제된 Flink 클러스터에서 작성한 Flink 작업 기록 파일을 확인합니다.
Dataproc Jobs 리소스를 사용하여 Flink 작업 실행
Google Cloud 콘솔, Google Cloud CLI 또는 Dataproc API에서 Dataproc Jobs 리소스를 사용하여 Flink 작업을 실행할 수 있습니다.
콘솔
콘솔에서 샘플 Flink 워드카운트 작업을 제출하려면 다음 안내를 따르세요.
브라우저의Google Cloud 콘솔에서 Dataproc 작업 제출 페이지를 엽니다.
작업 제출 페이지의 필드를 작성합니다.
- 클러스터 목록에서 클러스터 이름을 선택합니다.
- 작업 유형을
Flink로 설정합니다. - 기본 클래스 또는 jar을
org.apache.flink.examples.java.wordcount.WordCount로 설정합니다. - JAR 파일을
file:///usr/lib/flink/examples/batch/WordCount.jar로 설정합니다.file:///은 클러스터에 있는 파일을 나타냅니다. Flink 클러스터를 만들 때 Dataproc이WordCount.jar을 설치했습니다.- 이 필드는 Cloud Storage 경로(
gs://BUCKET/JARFILE) 또는 Hadoop 분산 파일 시스템(HDFS) 경로(hdfs://PATH_TO_JAR)도 허용합니다.
제출을 클릭합니다.
- 작업 드라이버 출력은 작업 세부정보 페이지에 표시됩니다.
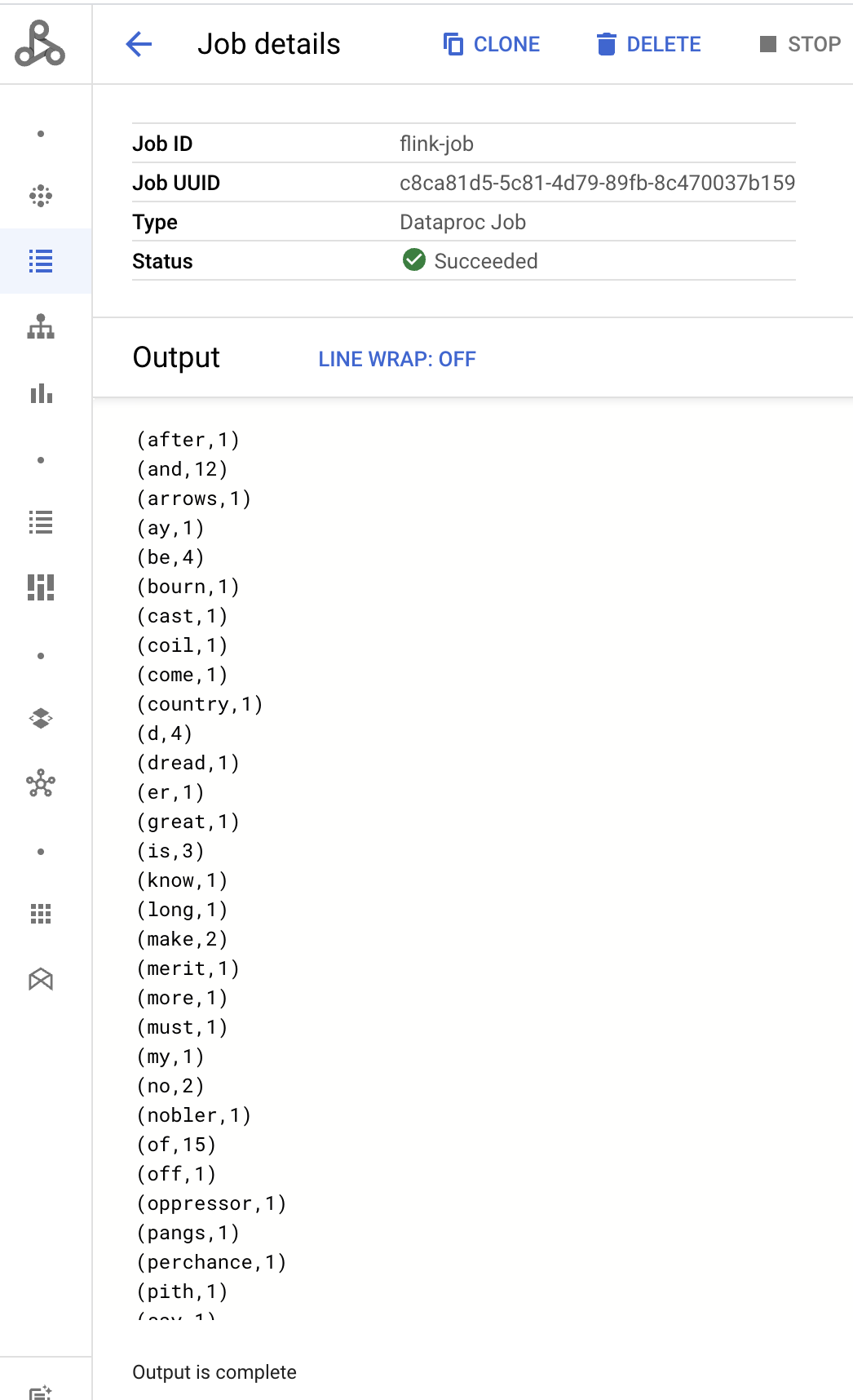
- Flink 작업은 Google Cloud 콘솔의 Dataproc 작업 페이지에 나열됩니다.
- 작업 또는 작업 세부정보 페이지에서 중지 또는 삭제를 클릭하여 작업을 중지하거나 삭제합니다.
gcloud
Dataproc Flink 클러스터에 Flink 작업을 제출하려면 gcloud CLI gcloud dataproc jobs submit 명령어를 터미널 창에서 로컬로 또는Cloud Shell에서 실행합니다.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
참고:
- CLUSTER_NAME: 작업을 제출할 Dataproc Flink 클러스터의 이름을 지정합니다.
- REGION: 클러스터가 있는 Compute Engine 리전을 지정합니다.
- MAIN_CLASS: Flink 애플리케이션의
main클래스를 지정합니다. 예를 들면 다음과 같습니다.org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE: Flink 애플리케이션 jar 파일을 지정합니다. 다음 항목을 지정할 수 있습니다.
- file:///` 프리픽스를 사용하여 클러스터에 설치된 jar 파일:
file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- Cloud Storage의 jar 파일:
gs://BUCKET/JARFILE - HDFS의 jar 파일:
hdfs://PATH_TO_JAR
- file:///` 프리픽스를 사용하여 클러스터에 설치된 jar 파일:
JOB_ARGS: 선택적으로 이중 대시(
--) 뒤에 작업 인수를 추가합니다.작업을 제출하면 작업 드라이버 출력이 로컬 또는 Cloud Shell 터미널에 표시됩니다.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
이 섹션에서는 Dataproc jobs.submit API를 사용하여 Dataproc Flink 클러스터에 Flink 작업을 제출하는 방법을 보여줍니다.
요청 데이터를 사용하기 전에 다음을 바꿉니다.
- PROJECT_ID: Google Cloud 프로젝트 ID입니다.
- REGION: 클러스터 리전입니다.
- CLUSTER_NAME: 작업을 제출할 Dataproc Flink 클러스터의 이름을 지정합니다.
HTTP 메서드 및 URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
JSON 요청 본문:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
요청을 보내려면 다음 옵션 중 하나를 펼칩니다.
다음과 비슷한 JSON 응답이 표시됩니다.
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- Flink 작업은 Google Cloud 콘솔의 Dataproc 작업 페이지에 나열됩니다.
- Google Cloud 콘솔의 작업 또는 작업 세부정보 페이지에서 중지 또는 삭제를 클릭하여 작업을 중지하거나 삭제할 수 있습니다.
flink CLI를 사용하여 Flink 작업 실행
Dataproc Jobs 리소스를 사용하여 Flink 작업을 실행하는 대신 flink CLI를 사용하여 Flink 클러스터의 마스터 노드에서 Flink 작업을 실행할 수 있습니다.
다음 섹션에서는 Dataproc Flink 클러스터에서 flink CLI 작업을 실행하는 다양한 방법을 설명합니다.
마스터 노드에 SSH로 연결: SSH 유틸리티를 사용하여 클러스터 마스터 VM의 터미널 창을 엽니다.
classpath 설정: Flink 클러스터 마스터 VM의 SSH 터미널 창에서 Hadoop 클래스 경로를 초기화합니다.
export HADOOP_CLASSPATH=$(hadoop classpath)Flink 작업 실행: 애플리케이션, 작업별, 세션 모드 등 다양한 YARN 배포 모드에서 Flink 작업을 실행할 수 있습니다.
애플리케이션 모드: Flink 애플리케이션 모드는 Dataproc 이미지 버전 2.0 이상에서 지원됩니다. 이 모드는 YARN 작업 관리자에서 작업의
main()메서드를 실행합니다. 작업이 완료되면 클러스터가 종료됩니다.작업 제출 예시:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jar실행 중인 작업 나열:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY실행 중인 작업 취소:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>작업별 모드: 이 Flink 모드는 클라이언트 측에서 작업의
main()메서드를 실행합니다.작업 제출 예시:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jar세션 모드: 장기 실행 Flink YARN 세션을 시작한 후 하나 이상의 작업을 세션에 제출합니다.
세션 시작: 다음 방법 중 하나로 Flink 세션을 시작할 수 있습니다.
Flink 클러스터를 만들고
gcloud dataproc clusters create명령어에--metadata flink-start-yarn-session=true플래그를 추가합니다(Dataproc Flink 클러스터 만들기 참조). 이 플래그를 사용 설정하면 클러스터가 생성된 후 Dataproc이/usr/bin/flink-yarn-daemon을 실행하여 클러스터에서 Flink 세션을 시작합니다.세션의 YARN 애플리케이션 ID가
/tmp/.yarn-properties-${USER}에 저장됩니다.yarn application -list명령어를 사용하여 ID를 나열할 수 있습니다.커스텀 설정으로 클러스터 마스터 VM에 사전 설치된
yarn-session.sh스크립트를 실행합니다.커스텀 설정의 예시:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detached기본 설정으로 Flink
/usr/bin/flink-yarn-daemon래퍼 스크립트를 실행합니다.. /usr/bin/flink-yarn-daemon
세션에 작업 제출: 다음 명령어를 실행하여 Flink 작업을 세션에 제출합니다.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL: 호스팅과 포팅을 포함한 작업이 실행되는 Flink 마스터 VM의 URL입니다.
URL에서
http:// prefix를 삭제합니다. 이 URL은 Flink 세션을 시작할 때 명령어 출력에 나열됩니다. 다음 명령어를 실행하여 이 URL을Tracking-URL필드에 나열할 수 있습니다.
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL: 호스팅과 포팅을 포함한 작업이 실행되는 Flink 마스터 VM의 URL입니다.
URL에서
세션에서 작업 나열: 세션에서 Flink 작업을 나열하려면 다음 중 하나를 수행합니다.
인수 없이
flink list를 실행합니다. 이 명령어는/tmp/.yarn-properties-${USER}에서 세션의 YARN 애플리케이션 ID를 찾습니다./tmp/.yarn-properties-${USER}또는yarn application -list의 출력에서 세션의 YARN 애플리케이션 ID를 가져온 다음<code>flink 목록 -yid YARN_APPLICATION_ID를 실행합니다.flink list -m FLINK_MASTER_URL를 실행합니다.
세션 중지: 세션을 중지하려면
/tmp/.yarn-properties-${USER}또는yarn application -list출력에서 세션의 YARN 애플리케이션 ID를 가져온 후 다음 명령어 중 하나를 실행합니다.echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
Flink에서 Apache Beam 작업 실행
Dataproc에서 FlinkRunner를 사용하여 Apache Beam을 실행할 수 있습니다.
다음과 같은 방법으로 Flink에서 Beam 작업을 실행할 수 있습니다.
- 자바 Beam 작업
- 포터블 Beam 작업
자바 Beam 작업
Beam 작업을 JAR 파일로 패키징합니다. 작업을 실행하는 데 필요한 종속 항목이 포함된 번들 JAR 파일을 제공하세요.
다음 예시에서는 Dataproc 클러스터의 마스터 노드에서 자바 Beam 작업을 실행합니다.
Flink 구성요소를 사용 설정하여 Dataproc 클러스터를 만듭니다.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components: Flink.--image-version: 클러스터에 설치된 Flink 버전을 결정하는 클러스터의 이미지 버전. 예를 들어 최신 및 이전 2.0.x 이미지 출시 버전 4개에 대하여 나열된 Apache Flink 구성요소 버전을 참조하세요.--region: 지원되는 Dataproc 리전--enable-component-gateway: Flink Job Manager UI에 대한 액세스 사용 설정--scopes: 클러스터별로 Google Cloud API에 대한 액세스를 사용 설정합니다(범위 권장사항 참고). Dataproc 이미지 버전 2.1 이상을 사용하는 클러스터를 만들 때cloud-platform범위가 기본적으로 사용 설정됩니다(이 플래그 설정을 포함하지 않아도 됨).
SSH 유틸리티를 사용하여 Flink 클러스터 마스터 노드에서 터미널 창을 엽니다.
Dataproc 클러스터 마스터 노드에서 Flink YARN 세션을 시작합니다.
. /usr/bin/flink-yarn-daemonDataproc 클러스터의 Flink 버전을 기록합니다.
flink --version로컬 머신에서 자바의 표준 Beam 단어 수 예시를 생성합니다.
Dataproc 클러스터의 Flink 버전과 호환되는 Beam 버전을 선택합니다. Beam-Flink 버전 호환성이 나열된 Flink 버전 호환성 표를 참조하세요.
생성된 POM 파일을 엽니다.
<flink.artifact.name>태그로 지정된 Beam Flink 실행기 버전을 확인합니다. Flink 아티팩트 이름의 Beam Flink 실행기 버전이 클러스터의 Flink 버전과 일치하지 않으면 일치하도록 버전 번호를 업데이트합니다.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=false단어 수 예시를 패키징합니다.
mvn package -Pflink-runner패키징된 uber JAR 파일
word-count-beam-bundled-0.1.jar(135MB 이하)를 Dataproc 클러스터의 마스터 노드에 업로드합니다.gcloud storage cp를 사용하면 Cloud Storage에서 Dataproc 클러스터로 파일을 더 빠르게 전송할 수 있습니다.로컬 터미널에서 Cloud Storage 버킷을 만들고 uber JAR을 업로드합니다.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/Dataproc의 마스터 노드에서 uber JAR을 다운로드합니다.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
Dataproc 클러스터의 마스터 노드에서 자바 Beam 작업을 실행합니다.
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-out결과가 Cloud Storage 버킷에 기록되었는지 확인합니다.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDFlink YARN 세션을 중지합니다.
yarn application -listyarn application -kill YARN_APPLICATION_ID
포터블 Beam 작업
Python, Go, 기타 지원되는 언어로 Beam 작업을 실행하려면 Beam의 Flink Runner에 설명된 대로 FlinkRunner 및 PortableRunner를 사용하면 됩니다. 이동성 프레임워크 로드맵도 참조하세요.
다음 예시에서는 Dataproc 클러스터의 마스터 노드에서 이동 가능한 Beam 작업을 Python으로 실행합니다.
Flink 및 Docker 구성요소가 모두 사용 설정된 Dataproc 클러스터를 만듭니다.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform참고:
--optional-components: Flink 및 Docker--image-version: 클러스터에 설치된 Flink 버전을 결정하는 클러스터의 이미지 버전. 예를 들어 최신 및 이전 2.0.x 이미지 출시 버전 4개에 대하여 나열된 Apache Flink 구성요소 버전을 참조하세요.--region: 사용 가능한 Dataproc 리전--enable-component-gateway: Flink Job Manager UI에 대한 액세스 사용 설정--scopes: 클러스터별로 Google Cloud API에 대한 액세스를 사용 설정합니다(범위 권장사항 참고). Dataproc 이미지 버전 2.1 이상을 사용하는 클러스터를 만들 때cloud-platform범위가 기본적으로 사용 설정됩니다(이 플래그 설정을 포함하지 않아도 됨).
로컬 또는 Cloud Shell에서 gcloud CLI를 사용하여 Cloud Storage 버킷을 만듭니다. 샘플 WordCount 프로그램을 실행할 때 BUCKET_NAME을 지정합니다.
gcloud storage buckets create BUCKET_NAME클러스터 VM의 터미널 창에서 Flink YARN 세션을 시작합니다. 작업이 실행되는 Flink 마스터의 주소인 Flink 마스터 URL을 확인합니다. 샘플 WordCount 프로그램을 실행할 때 FLINK_MASTER_URL을 지정합니다.
. /usr/bin/flink-yarn-daemonDataproc 클러스터를 실행하는 Flink 버전을 표시합니다. 샘플 WordCount 프로그램을 실행할 때 FLINK_VERSION을 지정합니다.
flink --version작업에 필요한 Python 라이브러리를 클러스터 마스터 노드에 설치합니다.
클러스터의 Flink 버전과 호환되는 Beam 버전을 설치합니다.
python -m pip install apache-beam[gcp]==BEAM_VERSION클러스터 마스터 노드에서 워드 수 예시를 실행합니다.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-out참고:
--runner:FlinkRunner.--flink_version: FLINK_VERSION, 앞서 언급됨--flink_master: FLINK_MASTER_URL, 앞서 언급됨--flink_submit_uber_jar: uber JAR을 사용하여 Beam 작업 실행--output: BUCKET_NAME, 앞서 생성됨
버킷에 결과가 기록되었는지 확인합니다.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDFlink YARN 세션을 중지합니다.
- 애플리케이션 ID를 가져옵니다.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
Kerberized 클러스터에서 Flink 실행
Dataproc Flink 구성요소는 Kerberized 클러스터를 지원합니다. Flink 작업을 제출하고 유지하거나 Flink 클러스터를 시작하려면 유효한 Kerberos 티켓이 필요합니다. 기본적으로 Kerberos 티켓은 7일 동안 유효합니다.
Flink 작업 관리자 UI 액세스
Flink 작업 또는 Flink 세션 클러스터를 실행하는 동안 Flink 작업 관리자 웹 인터페이스를 사용할 수 있습니다. 웹 인터페이스를 사용하려면 다음 단계를 따르세요.
- Dataproc Flink 클러스터를 만듭니다.
- 클러스터를 만든 후 Google Cloud 콘솔의 클러스터 세부정보 페이지에 있는 웹 인터페이스 탭에서 구성요소 게이트웨이 YARN ResourceManager 링크를 클릭합니다.
- YARN Resource Manager UI에서 Flink 클러스터 애플리케이션 항목을 식별합니다. 작업의 완료 상태에 따라 ApplicationMaster 또는 기록 링크가 나열됩니다.
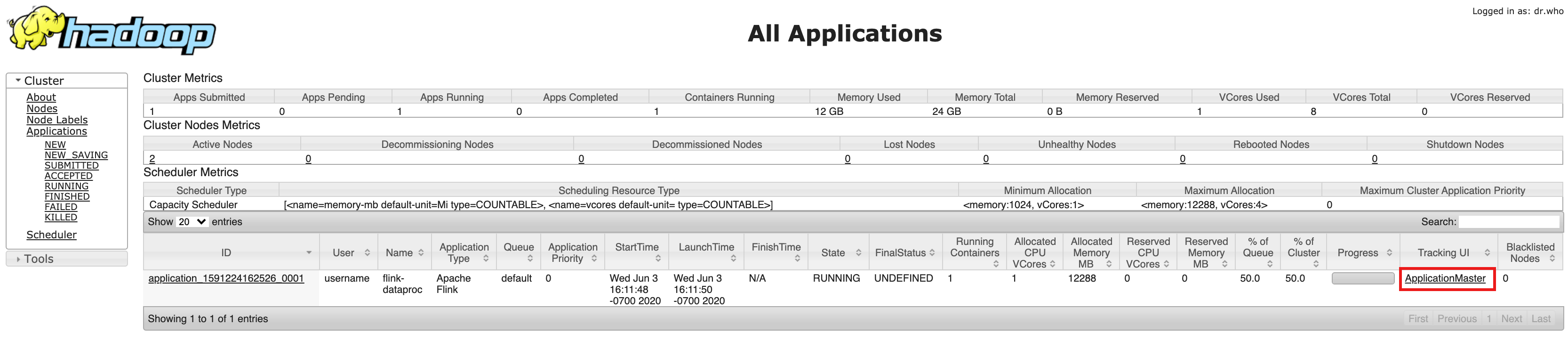
- 장기 실행 스트리밍 작업의 경우 ApplicationManager 링크를 클릭하여 Flink 대시보드를 엽니다. 완료된 작업의 경우 기록 링크를 클릭하여 작업 세부정보를 확인합니다.
