Sie können zusätzliche Komponenten wie Flink aktivieren, wenn Sie einen Dataproc-Cluster mit dem Feature Optionale Komponenten erstellen. Auf dieser Seite wird beschrieben, wie Sie einen Dataproc-Cluster mit der optionalen Apache Flink-Komponente (ein Flink-Cluster) erstellen und dann Flink-Jobs im Cluster ausführen.
Sie können Ihren Flink-Cluster für Folgendes verwenden:
Flink-Jobs mit der Dataproc-Ressource
Jobsausführen – über die Google Cloud -Konsole, die Google Cloud CLI oder die Dataproc API.Flink-Jobs mit der
flink-Befehlszeile ausführen, die auf dem Masterknoten des Flink-Clusters ausgeführt wird.
Dataproc-Flink-Cluster erstellen
Sie können die Google Cloud -Konsole, die Google Cloud CLI oder die Dataproc API verwenden, um einen Dataproc-Cluster zu erstellen, auf dem die Flink-Komponente aktiviert ist.
Empfehlung:Verwenden Sie einen Standardcluster mit einer Master-VM und der Flink-Komponente. Dataproc-Cluster im Modus für hohe Verfügbarkeit (mit 3 Master-VMs) unterstützen den Flink-Modus für hohe Verfügbarkeit nicht.
Konsole
Führen Sie die folgenden Schritte aus, um einen Dataproc-Flink-Cluster mit der Google Cloud -Console zu erstellen:
Öffnen Sie die Dataproc-Seite Dataproc-Cluster in Compute Engine erstellen.
- Der Bereich Cluster einrichten ist ausgewählt.
- Bestätigen oder ändern Sie im Abschnitt Versionsverwaltung den Image-Typ und die Image-Version. Die Cluster-Image-Version bestimmt die Version der im Cluster installierten Flink-Komponente.
- Die Image-Version muss mindestens 1.5 sein, damit die Flink-Komponente im Cluster aktiviert werden kann. Informationen zu den Komponentenversionen, die im jeweiligen Dataproc-Image-Release enthalten sind, finden Sie im Abschnitt Unterstützte Dataproc-Versionen.
- Die Image-Version muss [TBD] oder höher sein, damit Flink-Jobs über die Dataproc Jobs API ausgeführt werden können (siehe Dataproc-Flink-Jobs ausführen).
- Im Bereich Komponenten:
- Wählen Sie unter Component Gateway die Option Component Gateway aktivieren aus. Sie müssen das Component Gateway aktivieren, um den Component Gateway-Link zur Flink History Server-Benutzeroberfläche zu aktivieren. Wenn Sie das Component Gateway aktivieren, können Sie auch auf die Flink Job Manager-Weboberfläche zugreifen, die im Flink-Cluster ausgeführt wird.
- Wählen Sie unter Optionale Komponenten Flink und andere optionale Komponenten aus, die auf Ihrem Cluster aktiviert werden sollen.
- Bestätigen oder ändern Sie im Abschnitt Versionsverwaltung den Image-Typ und die Image-Version. Die Cluster-Image-Version bestimmt die Version der im Cluster installierten Flink-Komponente.
Klicken Sie auf den Bereich Cluster anpassen (optional).
Klicken Sie im Bereich Cluster-Attribute für jedes optionale Cluster-Attribut, das Sie Ihrem Cluster hinzufügen möchten, auf Attribute hinzufügen. Sie können Attribute mit dem Präfix
flinkhinzufügen, um Flink-Attribute in/etc/flink/conf/flink-conf.yamlzu konfigurieren, die als Standardwerte für Flink-Anwendungen dienen, die Sie im Cluster ausführen.Beispiele:
- Legen Sie
flink:historyserver.archive.fs.dirfest, um den Cloud Storage-Speicherort anzugeben, an den Flink-Jobverlaufsdateien geschrieben werden sollen. Dieser Speicherort wird vom Flink History Server verwendet, der im Flink-Cluster ausgeführt wird. - Legen Sie Flink-Aufgabenslots mit
flink:taskmanager.numberOfTaskSlots=nfest.
- Legen Sie
Klicken Sie im Abschnitt Benutzerdefinierte Clustermetadaten auf Metadaten hinzufügen, um optionale Metadaten hinzuzufügen. Fügen Sie beispielsweise
flink-start-yarn-sessiontruehinzu, um den Flink YARN-Daemon (/usr/bin/flink-yarn-daemon) im Hintergrund auf dem Masterknoten des Clusters auszuführen und eine Flink YARN-Sitzung zu starten (siehe Flink-Sitzungsmodus).
Wenn Sie die Dataproc-Image-Version 2.0 oder früher verwenden, klicken Sie auf den Bereich Sicherheit verwalten (optional) und wählen Sie dann unter Projektzugriff die Option
Enables the cloud-platform scope for this clusteraus. Dercloud-platform-Bereich ist standardmäßig aktiviert, wenn Sie einen Cluster erstellen, der die Dataproc-Image-Version 2.1 oder höher verwendet.
- Der Bereich Cluster einrichten ist ausgewählt.
Klicken Sie auf Erstellen, um den Cluster zu erstellen.
gcloud
Führen Sie zum Erstellen eines Dataproc-Flink-Clusters mit der gcloud CLI den folgenden Befehl gcloud dataproc clusters create lokal in einem Terminalfenster oder in Cloud Shell aus:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
Hinweise:
- CLUSTER_NAME: Geben Sie den Namen des Clusters an.
- REGION: Geben Sie eine Compute Engine-Region an, in der sich der Cluster befinden soll.
DATAPROC_IMAGE_VERSION: Optional können Sie die Image-Version angeben, die im Cluster verwendet werden soll. Die Cluster-Image-Version bestimmt die Version der im Cluster installierten Flink-Komponente.
Die Image-Version muss mindestens 1.5 sein, damit die Flink-Komponente im Cluster aktiviert werden kann. Informationen zu den Komponentenversionen, die im jeweiligen Dataproc-Image-Release enthalten sind, finden Sie im Abschnitt Unterstützte Dataproc-Versionen.
Die Image-Version muss [TBD] oder höher sein, damit Flink-Jobs über die Dataproc Jobs API ausgeführt werden können (siehe Dataproc-Flink-Jobs ausführen).
--optional-components: Sie müssen dieFLINK-Komponente angeben, um Flink-Jobs und den Flink HistoryServer-Webdienst auf dem Cluster auszuführen.--enable-component-gateway: Sie müssen das Component Gateway aktivieren, um den Component Gateway-Link zur Flink History Server-Benutzeroberfläche zu aktivieren. Wenn Sie das Component Gateway aktivieren, können Sie auch auf die Flink Job Manager-Weboberfläche zugreifen, die im Flink-Cluster ausgeführt wird.PROPERTIES. Optional können Sie ein oder mehrere Clusterattribute angeben.
Wenn Sie Dataproc-Cluster mit den Image-Versionen
2.0.67+ und2.1.15+ erstellen, können Sie das Flag--propertiesverwenden, um Flink-Attribute in/etc/flink/conf/flink-conf.yamlzu konfigurieren, die als Standardwerte für Flink-Anwendungen dienen, die Sie im Cluster ausführen.Sie können
flink:historyserver.archive.fs.dirfestlegen, um den Cloud Storage-Speicherort anzugeben, an den Flink-Jobverlaufsdateien geschrieben werden sollen. Dieser Speicherort wird vom Flink History Server verwendet, der im Flink-Cluster ausgeführt wird.Beispiel mit mehreren Properties:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2Weitere Flags:
- Sie können das optionale Flag
--metadata flink-start-yarn-session=truehinzufügen, um den Flink YARN-Daemon (/usr/bin/flink-yarn-daemon) im Hintergrund auf dem Masterknoten des Clusters auszuführen und eine Flink YARN-Sitzung zu starten (siehe Flink-Sitzungsmodus).
- Sie können das optionale Flag
Wenn Sie Image-Versionen 2.0 oder früher verwenden, können Sie das Flag
--scopes=https://www.googleapis.com/auth/cloud-platformhinzufügen, um den Zugriff auf Google Cloud -APIs durch Ihren Cluster zu ermöglichen (siehe Best Practices für Bereiche). Dercloud-platform-Bereich ist standardmäßig aktiviert, wenn Sie einen Cluster erstellen, der die Dataproc-Image-Version 2.1 oder höher verwendet.
API
Wenn Sie einen Dataproc-Flink-Cluster mit der Dataproc API erstellen möchten, senden Sie eine clusters.create-Anfrage, wie unten beschrieben:
Hinweise:
Legen Sie SoftwareConfig.Component auf
FLINKfest.Optional können Sie
SoftwareConfig.imageVersionfestlegen, um die Image-Version anzugeben, die im Cluster verwendet werden soll. Die Cluster-Image-Version bestimmt die Version der im Cluster installierten Flink-Komponente.Die Image-Version muss mindestens 1.5 sein, damit die Flink-Komponente im Cluster aktiviert werden kann. Informationen zu den Komponentenversionen, die im jeweiligen Dataproc-Image-Release enthalten sind, finden Sie im Abschnitt Unterstützte Dataproc-Versionen.
Die Image-Version muss [TBD] oder höher sein, damit Flink-Jobs über die Dataproc Jobs API ausgeführt werden können (siehe Dataproc-Flink-Jobs ausführen).
Legen Sie EndpointConfig.enableHttpPortAccess auf
truefest, um den Component Gateway-Link zur Flink History Server-UI zu aktivieren. Wenn Sie das Component Gateway aktivieren, können Sie auch auf die Flink Job Manager-Weboberfläche zugreifen, die im Flink-Cluster ausgeführt wird.Optional können Sie
SoftwareConfig.propertiesfestlegen, um ein oder mehrere Clusterattribute anzugeben.- Sie können Flink-Attribute angeben, die als Standardwerte für Flink-Anwendungen dienen, die Sie im Cluster ausführen. Sie können beispielsweise
flink:historyserver.archive.fs.dirfestlegen, um den Cloud Storage-Speicherort anzugeben, an den Flink-Jobverlaufsdateien geschrieben werden sollen. Dieser Speicherort wird vom Flink History Server verwendet, der im Flink-Cluster ausgeführt wird.
- Sie können Flink-Attribute angeben, die als Standardwerte für Flink-Anwendungen dienen, die Sie im Cluster ausführen. Sie können beispielsweise
Optional können Sie Folgendes festlegen:
GceClusterConfig.metadata>, um beispielsweiseflink-start-yarn-sessiontrueanzugeben, damit der Flink YARN-Daemon (/usr/bin/flink-yarn-daemon) im Hintergrund auf dem Masterknoten des Clusters ausgeführt wird, um eine Flink YARN-Sitzung zu starten (siehe Flink-Sitzungsmodus).- GceClusterConfig.serviceAccountScopes auf
https://www.googleapis.com/auth/cloud-platform(cloud-platform-Bereich) festlegen, wenn Sie Image-Versionen 2.0 oder früher verwenden, um den Zugriff Ihres Clusters auf Google Cloud-APIs zu ermöglichen (siehe Best Practices für Bereiche). Dercloud-platform-Bereich ist standardmäßig aktiviert, wenn Sie einen Cluster erstellen, der die Dataproc-Image-Version 2.1 oder höher verwendet.
Nachdem Sie einen Flink-Cluster erstellt haben
- Verwenden Sie den
Flink History Server-Link im Component Gateway, um den Flink-Verlaufsserver aufzurufen, der im Flink-Cluster ausgeführt wird. - Verwenden Sie
YARN ResourceManager linkim Component Gateway, um die Flink Job Manager-Weboberfläche auf dem Flink-Cluster aufzurufen . - Erstellen Sie einen Dataproc Persistent History Server, um Flink-Jobverlaufsdateien aufzurufen, die von vorhandenen und gelöschten Flink-Clustern geschrieben wurden.
Flink-Jobs mit der Dataproc-Ressource Jobs ausführen
Sie können Flink-Jobs mit der Dataproc-Ressource Jobs über dieGoogle Cloud Console, die Google Cloud CLI oder die Dataproc API ausführen.
Konsole
So reichen Sie einen Flink-Beispieljob für die Wortzählung über die Console ein:
Öffnen Sie die Dataproc-Seite Job senden in derGoogle Cloud Console in Ihrem Browser.
Füllen Sie die Felder auf der Seite Job senden aus:
- Wählen Sie den Namen des Clusters aus der Clusterliste aus.
- Legen Sie für Job type (Jobtyp) den Wert
Flinkfest. - Legen Sie für Main class or jar (Hauptklasse oder JAR-Datei) den Wert
org.apache.flink.examples.java.wordcount.WordCountfest. - Legen Sie für Jar-Dateien den Wert
file:///usr/lib/flink/examples/batch/WordCount.jarfest.file:///steht für eine Datei, die sich im Cluster befindet.WordCount.jarwurde von Dataproc installiert, als der Flink-Cluster erstellt wurde.- In diesem Feld kann auch ein Cloud Storage-Pfad (
gs://BUCKET/JARFILE) oder ein Hadoop Distributed File System-Pfad (HDFS-Pfad) (hdfs://PATH_TO_JAR) angegeben werden.
Klicken Sie auf Senden.
- Die Job-Treiberausgabe wird auf der Seite Jobdetails angezeigt.
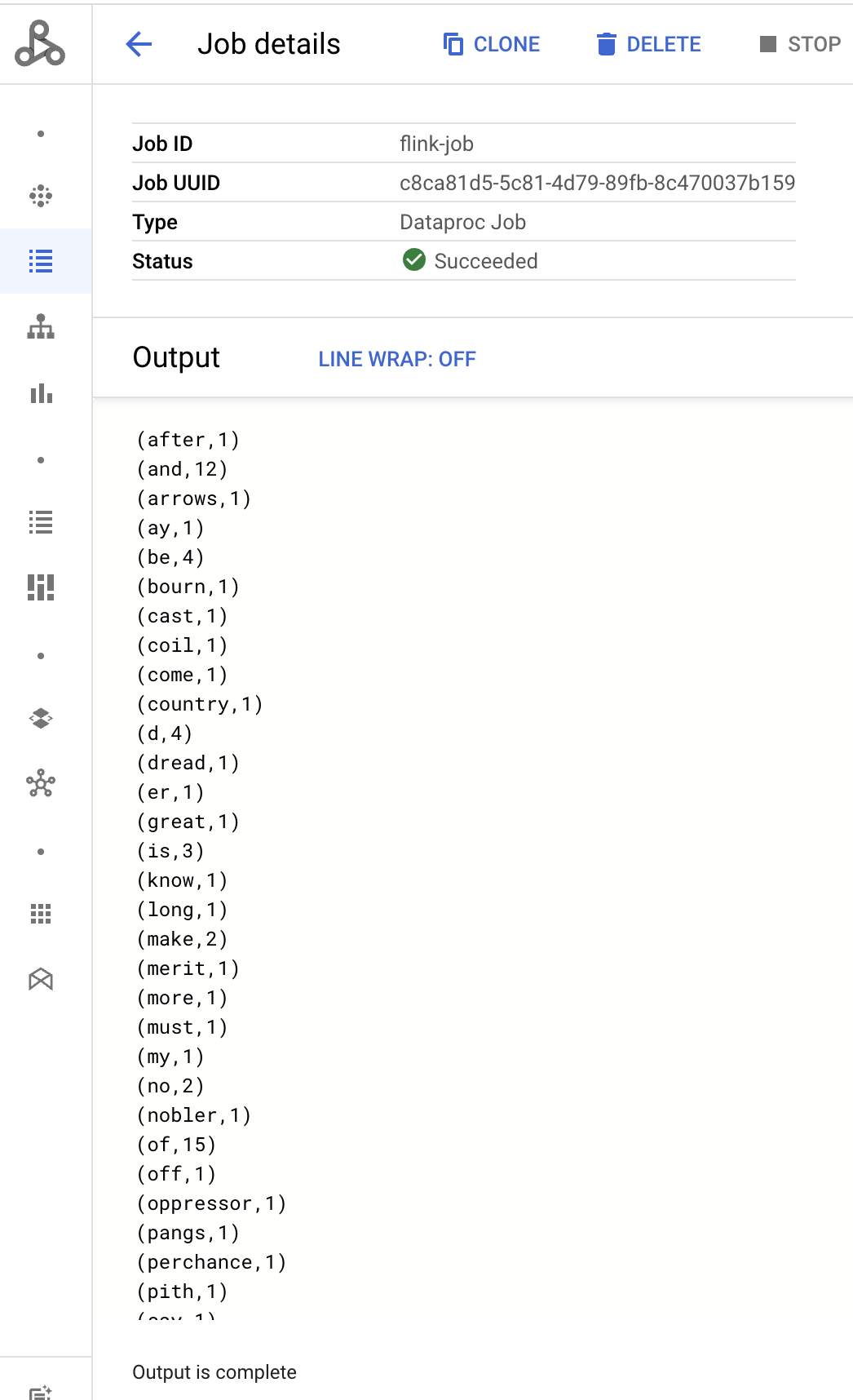
- Flink-Jobs werden in der Google Cloud -Console auf der Dataproc-Seite Jobs aufgeführt.
- Klicken Sie auf der Seite Jobs oder Jobdetails auf Beenden oder Löschen, um einen Job zu beenden oder zu löschen.
gcloud
Zum Senden eines Flink-Jobs an einen Dataproc-Flink-Cluster führen Sie den gcloud CLI-Befehl gcloud dataproc jobs submit lokal in einem Terminalfenster oder in Cloud Shell aus.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
Hinweise:
- CLUSTER_NAME: Geben Sie den Namen des Dataproc Flink-Clusters an, an den der Job gesendet werden soll.
- REGION: Geben Sie eine Compute Engine-Region an, in der sich der Cluster befindet.
- MAIN_CLASS: Geben Sie die
main-Klasse Ihrer Flink-Anwendung an, z. B.:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE: Geben Sie die JAR-Datei der Flink-Anwendung an. Sie können Folgendes angeben:
- Eine JAR-Datei, die auf dem Cluster installiert ist, mit dem Präfix
file:///` :file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- Eine JAR-Datei in Cloud Storage:
gs://BUCKET/JARFILE - Eine JAR-Datei in HDFS:
hdfs://PATH_TO_JAR
- Eine JAR-Datei, die auf dem Cluster installiert ist, mit dem Präfix
JOB_ARGS: Optional können Sie nach dem doppelten Bindestrich (
--) Jobargumente hinzufügen.Nachdem Sie den Job gesendet haben, wird die Jobtreiberausgabe im lokalen oder Cloud Shell-Terminal angezeigt.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
In diesem Abschnitt wird gezeigt, wie Sie einen Flink-Job an einen Dataproc-Flink-Cluster senden. Dazu verwenden Sie die Dataproc API jobs.submit.
Ersetzen Sie diese Werte in den folgenden Anfragedaten:
- PROJECT_ID: Google Cloud Projekt-ID
- REGION: Cluster-Region
- CLUSTER_NAME: Geben Sie den Namen des Dataproc Flink-Clusters an, an den der Job gesendet werden soll.
HTTP-Methode und URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
JSON-Text anfordern:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
Wenn Sie die Anfrage senden möchten, maximieren Sie eine der folgenden Optionen:
Sie sollten eine JSON-Antwort ähnlich wie diese erhalten:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- Flink-Jobs werden in der Google Cloud -Console auf der Dataproc-Seite Jobs aufgeführt.
- Sie können einen Job beenden oder löschen, indem Sie in der Google Cloud -Konsole auf der Seite Jobs oder Jobdetails auf Beenden oder Löschen klicken.
Flink-Jobs mit der flink-CLI ausführen
Anstatt Flink-Jobs mit der Dataproc-Ressource Jobs auszuführen, können Sie Flink-Jobs auf dem Masterknoten Ihres Flink-Clusters mit der flink-Befehlszeile ausführen.
In den folgenden Abschnitten werden verschiedene Möglichkeiten beschrieben, einen flink-CLI-Job in Ihrem Dataproc Flink-Cluster auszuführen.
SSH-Verbindung zum Masterknoten herstellen:Verwenden Sie das SSH-Tool, um ein Terminalfenster auf der Master-VM des Clusters zu öffnen.
Classpath festlegen:Initialisieren Sie den Hadoop-Classpath über das SSH-Terminalfenster auf der Master-VM des Flink-Clusters:
export HADOOP_CLASSPATH=$(hadoop classpath)Flink-Jobs ausführen:Sie können Flink-Jobs in verschiedenen Bereitstellungsmodi in YARN ausführen: Anwendungs-, Job- und Sitzungsmodus.
Anwendungsmodus:Der Flink-Anwendungsmodus wird von Dataproc-Image-Version 2.0 und höher unterstützt. In diesem Modus wird die Methode
main()des Jobs im YARN Job Manager ausgeführt. Der Cluster wird nach Abschluss des Jobs heruntergefahren.Beispiel für das Senden von Jobs:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jarLaufende Jobs auflisten:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YYSo brechen Sie einen laufenden Job ab:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>Per-Job-Modus:In diesem Flink-Modus wird die Methode
main()des Jobs auf der Clientseite ausgeführt.Beispiel für das Senden von Jobs:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jarSitzungsmodus:Starten Sie eine lang andauernde Flink-YARN-Sitzung und senden Sie dann einen oder mehrere Jobs an die Sitzung.
Sitzung starten:Sie haben folgende Möglichkeiten, eine Flink-Sitzung zu starten:
Erstellen Sie einen Flink-Cluster und fügen Sie dem Befehl
gcloud dataproc clusters createdas Flag--metadata flink-start-yarn-session=truehinzu (siehe Dataproc-Flink-Cluster erstellen). Wenn dieses Flag aktiviert ist, führt Dataproc nach dem Erstellen des Clusters/usr/bin/flink-yarn-daemonaus, um eine Flink-Sitzung im Cluster zu starten.Die YARN-Anwendungs-ID der Sitzung wird in
/tmp/.yarn-properties-${USER}gespeichert. Sie können die ID mit dem Befehlyarn application -listauflisten.Führen Sie das Flink-Skript
yarn-session.shaus, das auf der Master-VM des Clusters vorinstalliert ist, und verwenden Sie benutzerdefinierte Einstellungen:Beispiel mit benutzerdefinierten Einstellungen:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detachedFühren Sie das Wrapper-Skript
/usr/bin/flink-yarn-daemonfür Flink mit den Standardeinstellungen aus:. /usr/bin/flink-yarn-daemon
Job an eine Sitzung senden:Führen Sie den folgenden Befehl aus, um einen Flink-Job an die Sitzung zu senden.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL: Die URL, einschließlich Host und Port, der Flink-Master-VM, auf der Jobs ausgeführt werden.
Entfernen Sie
http:// prefixaus der URL. Diese URL wird in der Befehlsausgabe aufgeführt, wenn Sie eine Flink-Sitzung starten. Mit dem folgenden Befehl können Sie diese URL im FeldTracking-URLauflisten:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL: Die URL, einschließlich Host und Port, der Flink-Master-VM, auf der Jobs ausgeführt werden.
Entfernen Sie
Jobs in einer Sitzung auflisten:Führen Sie einen der folgenden Schritte aus, um Flink-Jobs in einer Sitzung aufzulisten:
Führen Sie
flink listohne Argumente aus. Der Befehl sucht in/tmp/.yarn-properties-${USER}nach der YARN-Anwendungs-ID der Sitzung.Rufen Sie die YARN-Anwendungs-ID der Sitzung aus
/tmp/.yarn-properties-${USER}oder der Ausgabe vonyarn application -listab und führen Sie dann<code>flink list -yid YARN_APPLICATION_ID aus.Führen Sie
flink list -m FLINK_MASTER_URLaus.
Sitzung beenden:Rufen Sie zum Beenden der Sitzung die YARN-Anwendungs-ID der Sitzung aus
/tmp/.yarn-properties-${USER}oder der Ausgabe vonyarn application -listab und führen Sie dann einen der folgenden Befehle aus:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
Apache Beam-Jobs in Flink ausführen
Sie können Apache Beam-Jobs in Dataproc mit dem FlinkRunner ausführen.
Sie können Beam-Jobs auf Flink auf folgende Weise ausführen:
- Java Beam-Jobs
- Portierbare Beam-Jobs
Java Beam-Jobs
Verpacken Sie Ihre Beam-Jobs in eine JAR-Datei. Geben Sie die gebündelte JAR-Datei mit den Abhängigkeiten an, die zum Ausführen des Jobs erforderlich sind.
Im folgenden Beispiel wird ein Java Beam-Job vom Masterknoten des Dataproc-Clusters ausgeführt.
Erstellen Sie einen Dataproc-Cluster mit aktivierter Flink-Komponente.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components: Flink.--image-version: Die Image-Version des Clusters, die die auf dem Cluster installierte Flink-Version bestimmt (Beispiel: Siehe die aufgelisteten Apache Flink-Komponentenversionen für die neueste und vorherige Version von vier 2.0.x-Image-Releaseversionen).--region: eine unterstützte Dataproc-Region.--enable-component-gateway: Aktiviert den Zugriff auf die Benutzeroberfläche des Flink Job Manager.--scopes: Ermöglichen Sie den Zugriff auf Google Cloud APIs durch Ihren Cluster (siehe Best Practices für Bereiche). Der Bereichcloud-platformist standardmäßig aktiviert. Sie müssen diese Flageinstellung nicht angeben, wenn Sie einen Cluster erstellen, der die Dataproc-Image-Version 2.1 oder höher verwendet.
Verwenden Sie das SSH-Dienstprogramm, um ein Terminalfenster auf dem Master-Knoten des Flink-Clusters zu öffnen.
Starten Sie eine Flink YARN-Sitzung auf dem Masterknoten des Dataproc-Clusters.
. /usr/bin/flink-yarn-daemonNotieren Sie sich die Flink-Version auf Ihrem Dataproc-Cluster.
flink --versionErstellen Sie auf Ihrem lokalen Computer das Beispiel für die kanonische Beam-Zählung in Java.
Wählen Sie eine Beam-Version aus, die mit der Flink-Version auf Ihrem Dataproc-Cluster kompatibel ist. In der Tabelle Kompatibilität mit der Flink-Version sind die Versionen der Beam-Flink-Version aufgeführt.
Öffnen Sie die generierte POM-Datei. Prüfen Sie die Version des Beam-Flink-Runners, die mit dem Tag
<flink.artifact.name>angegeben wird. Wenn die Beam-Flink-Runner-Version im Flink-Artefaktnamen nicht mit der Flink-Version auf Ihrem Cluster übereinstimmt, aktualisieren Sie die Versionsnummer entsprechend.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=falseBeispiel für das Verpacken der Wortzahl.
mvn package -Pflink-runnerLaden Sie die Uber-JAR-Paketdatei,
word-count-beam-bundled-0.1.jar, (ca. 135 MB) auf den Masterknoten des Dataproc-Clusters hoch. Sie könnengcloud storage cpfür eine schnellere Dateiübertragung von Cloud Storage zu Ihrem Dataproc-Cluster verwenden.Erstellen Sie auf Ihrem lokalen Terminal einen Cloud Storage-Bucket und laden Sie die Uber-JAR-Datei hoch.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/Laden Sie auf dem Masterknoten von Dataproc die Uber-JAR-Datei herunter.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
Führen Sie den Java Beam-Job auf dem Masterknoten des Dataproc-Clusters aus.
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-outPrüfen Sie, ob die Ergebnisse in Ihren Cloud Storage-Bucket geschrieben wurden.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDBeenden Sie die Flink YARN-Sitzung.
yarn application -listyarn application -kill YARN_APPLICATION_ID
Portierbare Beam-Jobs
Zum Ausführen von in Python, Go und anderen unterstützten Sprachen geschriebenen Beam-Jobs können Sie FlinkRunner und PortableRunner verwenden, wie im Flink-Runner des Beams beschrieben (siehe auch Portability Framework Roadmap).
Im folgenden Beispiel wird ein portabler Beam-Job in Python aus dem Masterknoten des Dataproc-Clusters ausgeführt.
Erstellen Sie einen Dataproc-Cluster, bei dem sowohl die Flink- als auch die Docker-Komponenten aktiviert sind.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platformHinweise:
--optional-components: Flink und Docker--image-version: Die Image-Version des Clusters, die die auf dem Cluster installierte Flink-Version bestimmt (Beispiel: Siehe die aufgelisteten Apache Flink-Komponentenversionen für die neueste und vorherige Version von vier 2.0.x-Image-Releaseversionen).--region: Eine verfügbare Dataproc-Region.--enable-component-gateway: Aktiviert den Zugriff auf die Benutzeroberfläche des Flink Job Manager.--scopes: Ermöglichen Sie den Zugriff auf Google Cloud APIs durch Ihren Cluster (siehe Best Practices für Bereiche). Der Bereichcloud-platformist standardmäßig aktiviert. Sie müssen diese Flageinstellung nicht angeben, wenn Sie einen Cluster erstellen, der die Dataproc-Image-Version 2.1 oder höher verwendet.
Verwenden Sie die gcloud CLI lokal oder in Cloud Shell, um einen Cloud Storage-Bucket zu erstellen. Sie geben BUCKET_NAME an, wenn Sie ein Beispielprogramm für die Wortzählung ausführen.
gcloud storage buckets create BUCKET_NAMEStarten Sie in einem Terminalfenster auf der Cluster-VM eine Flink YARN-Sitzung. Notieren Sie sich die Flink-Master-URL, die Adresse des Flink-Masters, auf dem Jobs ausgeführt werden. Sie geben FLINK_MASTER_URL an, wenn Sie ein Beispielprogramm für die Wortzählung ausführen.
. /usr/bin/flink-yarn-daemonLassen Sie sich die Flink-Version anzeigen, die auf dem Dataproc-Cluster ausgeführt wird, und notieren Sie sie sich. Sie geben FLINK_VERSION an, wenn Sie ein Beispielprogramm für die Wortzählung ausführen.
flink --versionInstallieren Sie die für den Job erforderlichen Python-Bibliotheken auf dem Masterknoten des Clusters.
Installieren Sie eine Beam-Version, die mit der Flink-Version auf dem Cluster kompatibel ist.
python -m pip install apache-beam[gcp]==BEAM_VERSIONFühren Sie das Beispiel für die Wortzählung auf dem Masterknoten des Clusters aus.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-outHinweise:
--runner:FlinkRunner.--flink_version: FLINK_VERSION, wie oben beschrieben.--flink_master: FLINK_MASTER_URL, wie oben beschrieben.--flink_submit_uber_jar: Verwenden Sie die Uber-JAR-Datei, um den Beam-Job auszuführen.--output: BUCKET_NAME, die zuvor erstellt wurde.
Prüfen Sie, ob die Ergebnisse in Ihren Bucket geschrieben wurden.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDBeenden Sie die Flink YARN-Sitzung.
- Rufen Sie die Anwendungs-ID ab.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
Flink auf einem kerberisierten Cluster ausführen
Die Dataproc Flink-Komponente unterstützt mit Kerberos gesicherte Cluster. Ein Kerberos-Ticket ist erforderlich, um einen Flink-Job zu senden und beizubehalten oder einen Flink-Cluster zu starten. Standardmäßig bleibt ein Kerberos-Ticket sieben Tage lang gültig.
Auf die Benutzeroberfläche von Flink Job Manager zugreifen
Die Flink Job Manager-Weboberfläche ist verfügbar, während ein Flink-Job oder ein Flink-Sitzungscluster ausgeführt wird. So verwenden Sie die Weboberfläche:
- Dataproc-Flink-Cluster erstellen.
- Nach der Clustererstellung klicken Sie in der Google Cloud Console auf der Seite Clusterdetails auf den Tab der Web-Benutzeroberfläche und auf das Component Gateway YARN ResourceManager-Link.
- Ermitteln Sie auf der Benutzeroberfläche von YARN Resource Manager den Anwendungseintrag des Flink-Clusters. Je nach Abschlussstatus des Jobs wird ein Link zu ApplicationMaster oder History angezeigt.
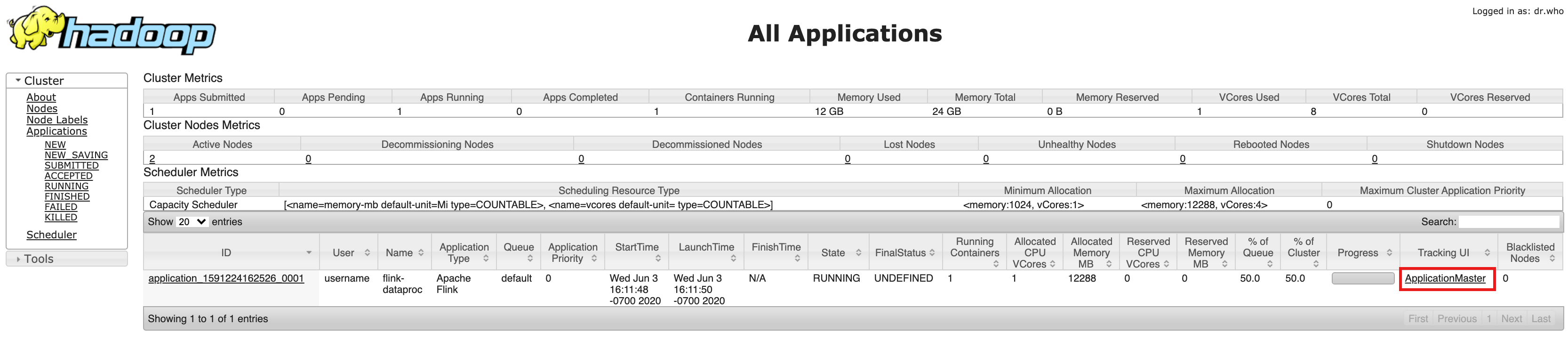
- Bei einem Streamingjob mit langer Ausführungszeit klicken Sie auf den Link ApplicationManager, um das Flink-Dashboard zu öffnen. Klicken Sie für einen abgeschlossenen Job auf den Link History (Verlauf), um Jobdetails aufzurufen.
