Cloud Profiler ist ein statistischer Profiler mit geringem Overhead, der kontinuierlich Informationen zur CPU-Nutzung und Arbeitsspeicherzuweisung aus Ihren Produktionsanwendungen sammelt. Weitere Informationen finden Sie unter Profilerstellungskonzepte. Verwenden Sie die Dataflow-Integration in Cloud Profiler, um die Pipelineleistung zu debuggen oder zu überwachen, um die Teile zu ermitteln, die die meisten Ressourcen beanspruchen.
Tipps und Strategien zur Fehlerbehebung zum Erstellen oder Ausführen einer Dataflow-Pipeline finden Sie unter Fehlerbehebung und Pipelines zur Fehlerbehebung.
Hinweis
Machen Sie sich mit den Konzepten der Profilerstellung sowie mit der Profiler-Oberfläche vertraut. Weitere Informationen zu den ersten Schritten mit der Profiler-Oberfläche finden Sie unter Profile für die Analyse auswählen.
Die Cloud Profiler API muss für Ihr Projekt aktiviert sein, bevor der Job gestartet wird.
Sie wird automatisch aktiviert, wenn Sie die Profilseite aufrufen.
Alternativ können Sie die Cloud Profiler API mithilfe des gcloud-Befehlszeilentools der Google Cloud CLI oder der Cloud Console aktivieren.
Damit Sie Cloud Profiler verwenden können, muss Ihr Projekt ein Kontingent haben.
Darüber hinaus muss das Worker-Dienstkonto für den Dataflow-Job die entsprechenden Berechtigungen für Profiler haben. Beispiel: Das Worker-Dienstkonto muss die Berechtigung cloudprofiler.profiles.create haben, um Profile zu erstellen, die in der IAM-Rolle des Cloud Profiler-Agents (roles/cloudprofiler.agent) enthalten ist.
Weitere Informationen finden Sie unter Zugriffssteuerung mit IAM.
Cloud Profiler für Dataflow-Pipelines aktivieren
Cloud Profiler ist für Dataflow-Pipelines verfügbar, die im Apache Beam SDK für Java und Python ab Version 2.33.0 geschrieben sind. Python-Pipelines müssen Dataflow Runner v2 verwenden. Cloud Profiler kann beim Start der Pipeline aktiviert werden. Der amortisierte CPU- und Speicheraufwand wird für Ihre Pipelines voraussichtlich weniger als 1 % betragen.
Java
Starten Sie die Pipeline mit der folgenden Option, um die CPU-Profilerstellung zu aktivieren.
--dataflowServiceOptions=enable_google_cloud_profiler
Starten Sie die Pipeline mit den folgenden Optionen, um die Heap-Profilerstellung zu aktivieren. Die Heap-Profilerstellung erfordert Java 11 oder höher.
--dataflowServiceOptions=enable_google_cloud_profiler
--dataflowServiceOptions=enable_google_cloud_heap_sampling
Python
Ihre Python-Pipeline muss mit Dataflow Runner v2 ausgeführt werden, um Cloud Profiler zu verwenden.
Starten Sie die Pipeline mit der folgenden Option, um die CPU-Profilerstellung zu aktivieren. Die Heap-Profilerstellung wird für Python noch nicht unterstützt.
--dataflow_service_options=enable_google_cloud_profiler
Go
Starten Sie die Pipeline mit der folgenden Option, um die CPU- und Heap-Profilerstellung zu aktivieren.
--dataflow_service_options=enable_google_cloud_profiler
Wenn Sie Ihre Pipelines aus Dataflow-Vorlagen bereitstellen und Cloud Profiler aktivieren möchten, geben Sie die Flags enable_google_cloud_profiler und enable_google_cloud_heap_sampling als zusätzliche Experimente an.
Console
Wenn Sie eine von Google bereitgestellte Vorlage nutzen, können Sie die Flags auf der Dataflow-Seite Job aus Vorlage erstellen im Feld Zusätzliche Tests angeben.
gcloud
Wenn Sie Google Cloud CLI zum Ausführen von Vorlagen verwenden, können Sie je nach Vorlagentyp über das Feld --additional-experiments der Laufzeitumgebung das Flag gcloud
dataflow jobs run oder gcloud dataflow flex-template run angeben.
API
Wenn Sie die REST API zum Ausführen von Vorlagen verwenden, können Sie je nach Vorlagentyp über das Feld additionalExperiments der Laufzeitumgebung das Flag RuntimeEnvironment oder FlexTemplateRuntimeEnvironment angeben.
Profildaten ansehen
Wenn Cloud Profiler aktiviert ist, wird ein Link zur Profiler-Seite auf der Jobseite angezeigt.
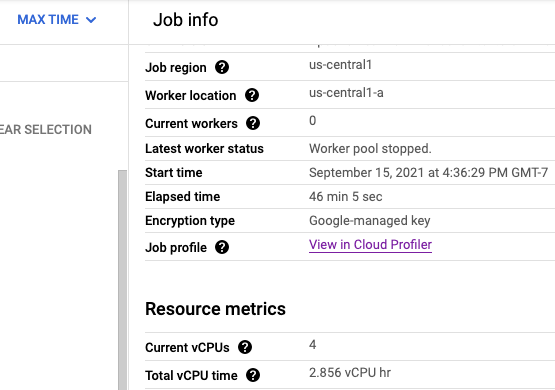
Auf der Profiler-Seite finden Sie auch die Profildaten für Ihre Dataflow-Pipeline. Der Dienst ist Ihr Jobname und die Version Ihre Job-ID.

Cloud Profiler verwenden
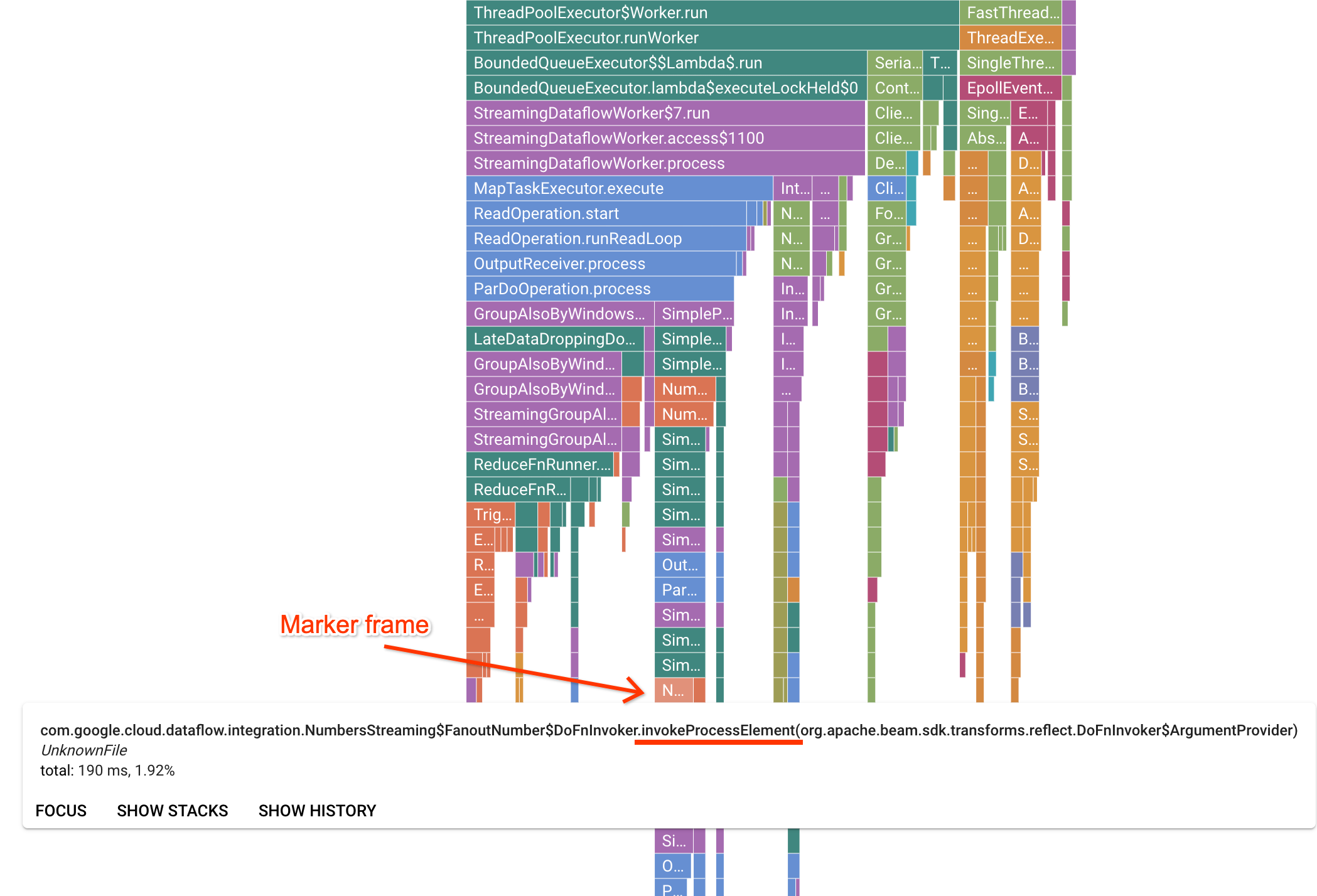
Die Seite "Profiler" enthält ein Flame-Diagramm, in dem Statistiken für jeden Frame angezeigt werden, der auf einem Worker ausgeführt wird. In der horizontalen Richtung können Sie sehen, wie lange die Ausführung jedes Frames in Bezug auf die CPU-Zeit dauert. In der vertikalen Richtung können Sie Stacktraces und parallel ausgeführten Code sehen. Die Stacktraces werden vom Runner-Infrastrukturcode dominiert. Für die Fehlerbehebung sind wir in der Regel an der Ausführung von Nutzercode interessiert, der in der Regel in der Nähe der unteren Spitzen des Diagramms zu finden ist. Nutzercode kann durch die Suche nach Markierungsframes identifiziert werden, die einen Runner-Code darstellen, der bekanntermaßen nur Nutzercode aufruft. Für den Beam ParDo-Runner wird eine dynamische Adapterschicht erstellt, um die vom Nutzer bereitgestellte Signatur der DoFn-Methode aufzurufen. Diese Ebene kann als Frame mit dem Suffix invokeProcessElement identifiziert werden. In der folgenden Abbildung sehen Sie, wie ein Markierungsframe gefunden wird.
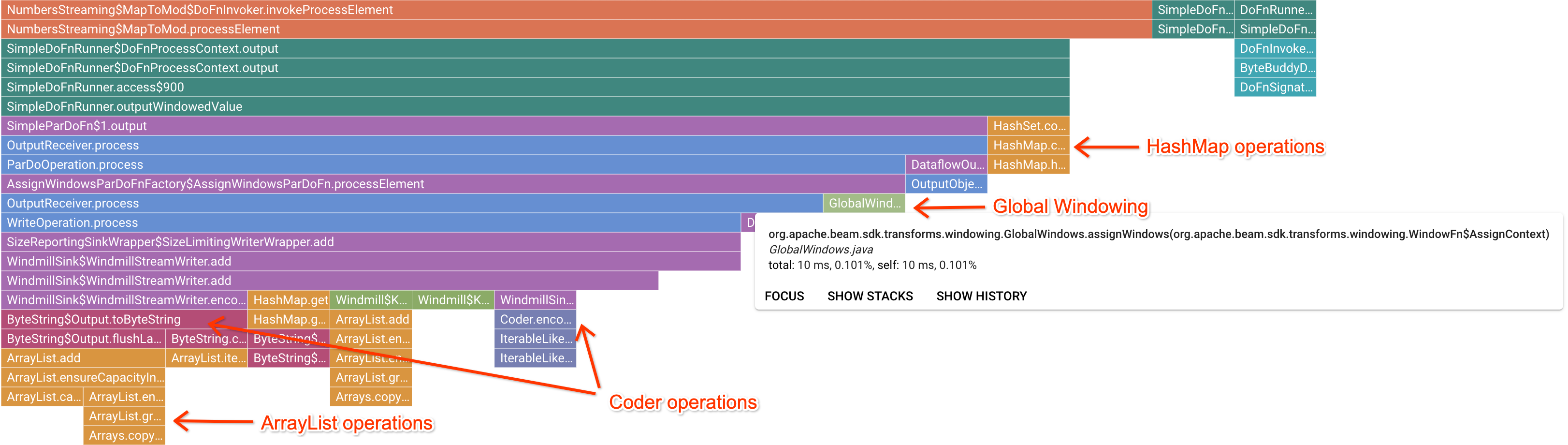
Nachdem auf einen interessanten Markierungsframe geklickt wurde, konzentriert sich das Flame-Diagramm auf diesen Stacktrace. Dadurch erhalten Sie einen guten Überblick über den lange laufenden Nutzercode. Die langsamsten Vorgänge können darauf hinweisen, wo sich Engpässe befinden und Optimierungsmöglichkeiten darstellen. Im folgenden Beispiel ist zu sehen, dass das globale Windowing mit einem ByteArrayCoder verwendet wird. In diesem Fall könnte der Coder ein guter Optimierungsbereich sein, da er im Vergleich zu ArrayList- und HashMap-Vorgängen viel CPU-Zeit in Anspruch nimmt.
Fehlerbehebung bei Cloud Profiler
Wenn Sie Cloud Profiler aktivieren und Ihre Pipeline keine Profildaten generiert, könnte eine der folgenden Bedingungen die Ursache sein.
Ihre Pipeline verwendet eine ältere Apache Beam SDK-Version. Zur Verwendung von Cloud Profiler benötigen Sie das Apache Beam SDK in der Version 2.33.0 oder höher. Sie können die Apache Beam SDK-Version Ihrer Pipeline auf der Jobseite aufrufen. Wenn Ihr Job aus Dataflow-Vorlagen erstellt wird, müssen die Vorlagen die unterstützten SDK-Versionen verwenden.
Ihr Cloud Profiler-Kontingent ist aufgebraucht. Sie können die Kontingentnutzung auf der Kontingentseite Ihres Projekts einsehen. Ein Fehler wie
Failed to collect and upload profile whose profile type is WALLkann auftreten, wenn das Cloud Profiler-Kontingent überschritten wird. Der Cloud Profiler-Dienst lehnt die Profildaten ab, wenn Sie Ihr Kontingent erreicht haben. Weitere Informationen zu Cloud Profiler-Kontingenten finden Sie unter Kontingente und Limits.Ihr Job wurde nicht lange genug ausgeführt, um Daten für Cloud Profiler zu generieren. Jobs, die für kurze Zeitdauer ausgeführt werden, z. B. weniger als fünf Minuten, stellen möglicherweise nicht genügend Profildaten bereit, damit Cloud Profiler keine Ergebnisse generieren kann.
Der Cloud Profiler-Agent wird beim Start des Dataflow-Workers installiert. Von Cloud Profiler generierte Lognachrichten sind in den Logtypen dataflow.googleapis.com/worker-startup verfügbar.
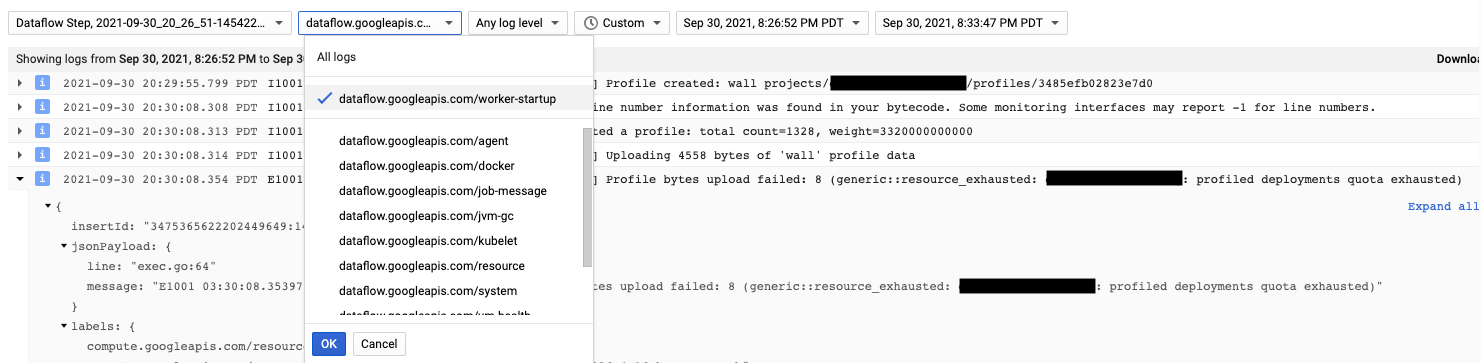
Manchmal sind Profildaten vorhanden, aber Cloud Profiler zeigt keine Ausgabe an. Der Profiler zeigt eine Nachricht ähnlich der folgenden an: There were
profiles collected for the specified time range, but none match the current
filters.
Versuchen Sie Folgendes, um dieses Problem zu beheben:
Achten Sie darauf, dass die Zeitspanne und die Endzeit im Profiler die verstrichene Zeit einschließen.
Prüfen Sie, ob im Profiler der richtige Job ausgewählt ist. Der Dienst ist Ihr Jobname.
Prüfen Sie, ob die Pipelineoption
job_namedenselben Wert wie der Jobname auf der Dataflow-Jobseite hat.Wenn Sie beim Laden des Profiler-Agents ein Servicename-Argument angegeben haben, prüfen Sie, ob der Dienstname richtig konfiguriert ist.