Auf dieser Seite wird erläutert, wie Sie Flexible Resource Scheduling (FlexRS) für automatisch skalierte Batchpipelines in Dataflow aktivieren.
FlexRS reduziert die Kosten für die Batchverarbeitung. Dazu werden erweiterte Planungsverfahren, der Dataflow Shuffle-Dienst sowie eine Kombination aus VM-Instanzen auf Abruf und normalen VMs verwendet. Durch die parallele Ausführung von VMs auf Abruf und regulären VMs verbessert Dataflow die Nutzerfreundlichkeit, wenn Compute Engine VM-Instanzen auf Abruf während eines Systemereignisses beendet. FlexRS gewährleistet, dass die Pipeline weiter verarbeitet wird und keine geleistete Arbeit verloren geht, wenn Ihre VMs auf Abruf von Compute Engine vorzeitig beendet werden.
Jobs mit FlexRS verwenden die dienstbasierte Dataflow Shuffle-Funktion für Join- und Gruppierungsvorgänge. Aus diesem Grund nutzen FlexRS-Jobs keine nichtflüchtigen Speicherressourcen zum Speichern von temporären Berechnungsergebnissen. Dank Dataflow Shuffle kann FlexRS besser mit dem vorzeitigen Beenden einer Worker-VM umgehen, da der Dataflow-Dienst keine Daten an die verbleibenden Worker umverteilen muss. Allerdings benötigt jeder Dataflow-Worker trotzdem ein kleines nichtflüchtiges Speicher-Volume mit 25 GB, um das Maschinen-Image und temporäre Logs zu speichern.
Unterstützung und Einschränkungen
- Batchpipelines werden unterstützt.
- Erfordert das Apache Beam SDK für Java 2.12.0 oder höher, das Apache Beam SDK für Python 2.12.0 oder höher oder das Apache Beam SDK für Go.
- Verwendet Dataflow Shuffle. Durch die Aktivierung von FlexRS wird Dataflow Shuffle automatisch aktiviert.
- Unterstützt keine GPUs.
- Compute Engine-Reservierungen werden nicht unterstützt.
- Bei der Planung von FlexRS-Jobs gibt es eine Verzögerung. Daher eignet sich FlexRS am besten für Arbeitslasten, die nicht zeitkritisch sind, beispielsweise tägliche oder wöchentliche Jobs, die innerhalb eines bestimmten Zeitraums abgeschlossen werden können.
Verzögerte Planung
Wenn Sie einen FlexRS-Job senden, wird er vom Dataflow-Dienst in eine Warteschlange gestellt und innerhalb von sechs Stunden nach der Joberstellung zur Ausführung gesendet. Dataflow ermittelt den besten Zeitpunkt für den Jobstart innerhalb dieses Zeitfensters, basierend auf der verfügbaren Kapazität und anderen Faktoren.
Nach dem Senden eines FlexRS-Jobs führt der Dataflow-Dienst folgende Schritte aus:
- Liefert unmittelbar nach dem Senden des Jobs eine Job-ID.
- Führt einen ersten Validierungslauf durch.
Verwendet das Ergebnis der ersten Validierung, um den nächsten Schritt zu bestimmen:
- Im Erfolgsfall wird der Job in eine Warteschlange gestellt, um auf den verzögerten Start zu warten.
- In allen anderen Fällen schlägt der Job fehl und der Dataflow-Dienst meldet die Fehler.
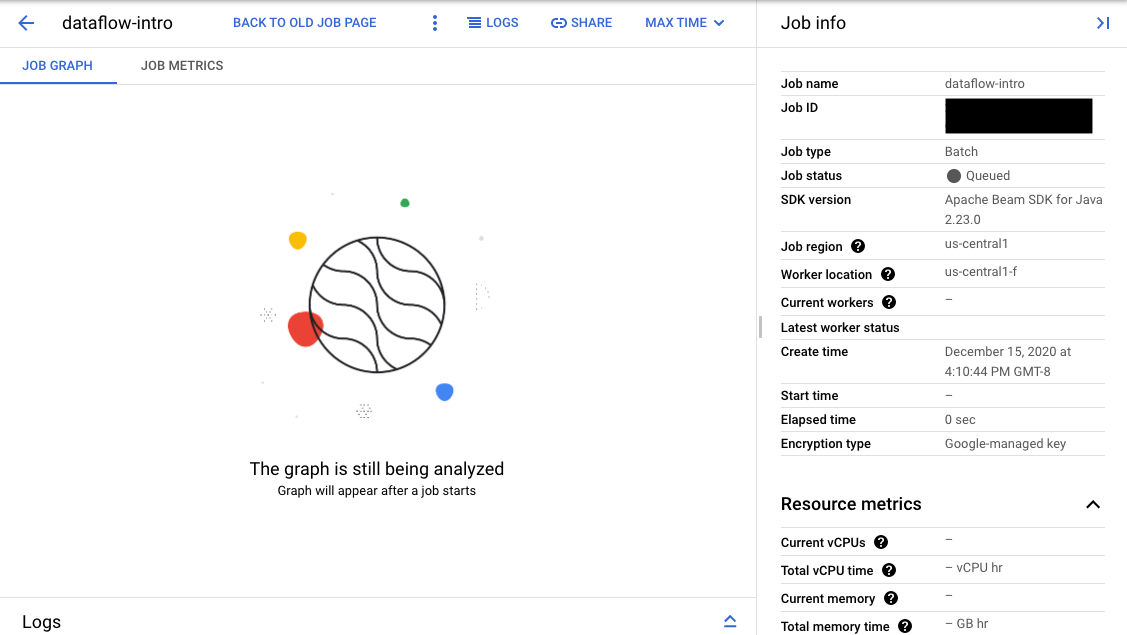
Wenn die Validierung erfolgreich ist, wird in der Dataflow-Monitoring-Oberfläche für Ihren Job eine ID und der Status
Queued angezeigt. Wenn die Validierung fehlschlägt, wird für Ihren Job der Status Failed angezeigt.
Erste Validierung
Nach dem Senden eines FlexRS-Jobs wird dieser nicht sofort gestartet. Während der ersten Validierung prüft der Dataflow-Dienst die Ausführungsparameter und dieGoogle Cloud -Umgebungseinstellungen, z. B. IAM-Rollen und Netzwerkkonfigurationen. An diesem Punkt validiert Dataflow den Job so weit wie möglich und meldet potenzielle Fehler. Diese erste Validierung wird Ihnen nicht in Rechnung gestellt.
Bei der ersten Validierung wird kein Nutzercode ausgeführt. Sie müssen Ihren Code mit dem Direct Runner von Apache Beam oder Jobs ohne FlexRS selbst auf Probleme prüfen. Wenn sich zwischen der Joberstellung und der verzögerten Planung des Jobs Änderungen an der Google Cloud Umgebung ergeben, kann die erste Validierung des Jobs erfolgreich verlaufen, der Job beim Start aber dennoch fehlschlagen.
FlexRS aktivieren
Wenn Sie einen FlexRS-Job erstellen, wird auch dann ein gleichzeitiges Kontingent akzeptiert, wenn sich der Job im Status In der Warteschlange befindet. Während der ersten Validierung werden keine anderen Kontingente überprüft oder reserviert. Prüfen Sie daher vor der Aktivierung von FlexRS, ob Sie genügend Kontingente für Google Cloud Projektressourcen haben, um den Job zu starten. Sie benötigen unter anderem ein zusätzliches Kontingent für CPUs auf Abruf, normale CPUs und IP-Adressen, sofern Sie nicht den Parameter für öffentliche IPs deaktivieren.
Wenn Ihr Kontingent nicht ausreicht, stehen Ihrem Konto unter Umständen nicht genügend Ressourcen zur Verfügung, wenn der FlexRS-Job bereitgestellt wird. Dataflow wählt standardmäßig für 90 % der Worker im Worker-Pool VMs auf Abruf aus. Achten Sie also beim Planen des CPU-Kontingents darauf, dass Ihr Kontingent für VMs auf Abruf ausreicht. Sie können das Kontingent für VMs auf Abruf explizit anfordern. Andernfalls fehlen dem FlexRS-Job die Ressourcen, um zeitnah ausgeführt zu werden.
Preise
Für FlexRS-Jobs werden folgende Ressourcen in Rechnung gestellt:
- Normale CPUs und CPUs auf Abruf
- Arbeitsspeicherressourcen
- Dataflow Shuffle-Ressourcen
- 25 GB nichtflüchtige Speicherressourcen pro Worker
Obwohl Dataflow zum Ausführen des FlexRS-Jobs sowohl Worker auf Abruf als auch normale Worker verwendet, wird Ihnen unabhängig vom Worker-Typ ein einheitlicher ermäßigter Preis im Vergleich zu den regulären Dataflow-Preisen berechnet. Dataflow Shuffle und nichtflüchtige Speicherressourcen werden nicht ermäßigt.
Weitere Informationen finden Sie auf der Seite Dataflow-Preisdetails.
Pipelineoptionen
Java
Verwenden Sie die folgende Pipelineoption, um einen FlexRS-Job zu aktivieren:
--flexRSGoal=COST_OPTIMIZED, wobei der Dataflow-Dienst alle verfügbaren ermäßigten Ressourcen auswählt.--flexRSGoal=SPEED_OPTIMIZED, wobei für eine niedrigere Ausführungszeit optimiert wird. Wenn nicht angegeben, wird für das Feld--flexRSGoalstandardmäßigSPEED_OPTIMIZEDverwendet. Dies entspricht dem Weglassen dieses Flags.
FlexRS-Jobs wirken sich auf folgende Ausführungsparameter aus:
numWorkerslegt nur die anfängliche Anzahl der Worker fest. Allerdings können Sie zur Kostenkontrolle den ParametermaxNumWorkersfestlegen.- Die Option
autoscalingAlgorithmkann nicht mit FlexRS-Jobs verwendet werden. - Das Flag
zonekann für FlexRS-Jobs nicht angegeben werden. Der Dataflow-Dienst wählt die Zone für alle FlexRS-Jobs in der Region aus, die Sie mit dem Parameterregionangegeben haben. - Sie müssen einen Dataflow-Speicherort als Ihre
regionauswählen. - Sie können die Maschinenserien M2, M3 oder H3 nicht für Ihre
workerMachineTypeverwenden.
Das folgende Beispiel zeigt, wie Sie Ihre normalen Pipelineparameter um Parameter für die Verwendung von FlexRS ergänzen:
--flexRSGoal=COST_OPTIMIZED \
--region=europe-west1 \
--maxNumWorkers=10 \
--workerMachineType=n1-highmem-16
Wenn Sie region, maxNumWorkers und workerMachineType weglassen, bestimmt der Dataflow-Dienst den Standardwert.
Python
Verwenden Sie die folgende Pipelineoption, um einen FlexRS-Job zu aktivieren:
--flexrs_goal=COST_OPTIMIZED, wobei der Dataflow-Dienst alle verfügbaren ermäßigten Ressourcen auswählt.--flexrs_goal=SPEED_OPTIMIZED, wobei für eine niedrigere Ausführungszeit optimiert wird. Wenn nicht angegeben, wird für das Feld--flexrs_goalstandardmäßigSPEED_OPTIMIZEDverwendet. Dies entspricht dem Weglassen dieses Flags.
FlexRS-Jobs wirken sich auf folgende Ausführungsparameter aus:
num_workerslegt nur die anfängliche Anzahl der Worker fest. Allerdings können Sie zur Kostenkontrolle den Parametermax_num_workersfestlegen.- Die Option
autoscalingAlgorithmkann nicht mit FlexRS-Jobs verwendet werden. - Das Flag
zonekann für FlexRS-Jobs nicht angegeben werden. Der Dataflow-Dienst wählt die Zone für alle FlexRS-Jobs in der Region aus, die Sie mit dem Parameterregionangegeben haben. - Sie müssen einen Dataflow-Speicherort als Ihre
regionauswählen. - Sie können die Maschinenserien M2, M3 oder H3 nicht für Ihre
machine_typeverwenden.
Das folgende Beispiel zeigt, wie Sie Ihre normalen Pipelineparameter um Parameter für die Verwendung von FlexRS ergänzen:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Wenn Sie region, max_num_workers und machine_type weglassen, bestimmt der Dataflow-Dienst den Standardwert.
Go
Verwenden Sie die folgende Pipelineoption, um einen FlexRS-Job zu aktivieren:
--flexrs_goal=COST_OPTIMIZED, wobei der Dataflow-Dienst alle verfügbaren ermäßigten Ressourcen auswählt.--flexrs_goal=SPEED_OPTIMIZED, wobei für eine niedrigere Ausführungszeit optimiert wird. Wenn nicht angegeben, wird für das Feld--flexrs_goalstandardmäßigSPEED_OPTIMIZEDverwendet. Dies entspricht dem Weglassen dieses Flags.
FlexRS-Jobs wirken sich auf folgende Ausführungsparameter aus:
num_workerslegt nur die anfängliche Anzahl der Worker fest. Allerdings können Sie zur Kostenkontrolle den Parametermax_num_workersfestlegen.- Die Option
autoscalingAlgorithmkann nicht mit FlexRS-Jobs verwendet werden. - Das Flag
zonekann für FlexRS-Jobs nicht angegeben werden. Der Dataflow-Dienst wählt die Zone für alle FlexRS-Jobs in der Region aus, die Sie mit dem Parameterregionangegeben haben. - Sie müssen einen Dataflow-Speicherort als Ihre
regionauswählen. - Sie können die Maschinenserien M2, M3 oder H3 nicht für Ihre
worker_machine_typeverwenden.
Das folgende Beispiel zeigt, wie Sie Ihre normalen Pipelineparameter um Parameter für die Verwendung von FlexRS ergänzen:
--flexrs_goal=COST_OPTIMIZED \
--region=europe-west1 \
--max_num_workers=10 \
--machine_type=n1-highmem-16
Wenn Sie region, max_num_workers und machine_type weglassen, bestimmt der Dataflow-Dienst den Standardwert.
Dataflow-Vorlagen
Einige Dataflow-Vorlagen unterstützen die FlexRS-Pipelineoption nicht. Alternativ können Sie die folgende Pipelineoption verwenden.
--additional-experiments=flexible_resource_scheduling,shuffle_mode=service,delayed_launch
FlexRS-Jobs überwachen
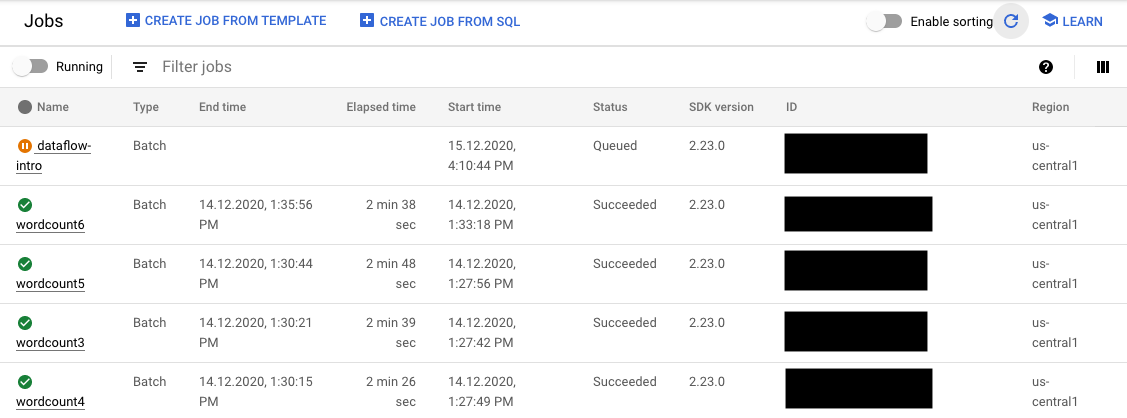
Sie können den Status Ihres FlexRS-Jobs in der Google Cloud Console an zwei Stellen verfolgen:
- Auf der Seite Jobs, auf der alle Ihre Jobs angezeigt werden
- Die Monitoring-Oberfläche des von Ihnen gesendeten Jobs.
Auf der Seite Jobs haben Jobs, die noch nicht gestartet wurden, den Status In der Warteschlange.
Auf der Seite Monitoring-Oberfläche wird für Jobs, die sich in der Warteschlange befinden, auf dem Tab Jobgrafik die Meldung "Grafik wird nach dem Start eines Jobs angezeigt" angezeigt.