Se riscontri problemi con la pipeline o il job Dataflow, questa pagina elenca i messaggi di errore che potresti visualizzare e fornisce suggerimenti su come correggere ogni errore.
Gli errori nei tipi di log dataflow.googleapis.com/worker-startup,
dataflow.googleapis.com/harness-startup e dataflow.googleapis.com/kubelet
indicano problemi di configurazione di un job. Possono anche indicare condizioni
che impediscono il funzionamento del normale percorso di logging.
La pipeline potrebbe generare eccezioni durante l'elaborazione dei dati. Alcuni di questi errori sono temporanei, ad esempio quando si verifica una difficoltà temporanea di accesso a un servizio esterno. Alcuni di questi errori sono permanenti, ad esempio quelli causati da dati di input danneggiati o non analizzabili o da puntatori nulli durante il calcolo.
Dataflow elabora gli elementi in bundle arbitrari e riprova a elaborare l'intero bundle quando viene generato un errore per qualsiasi elemento del bundle. Quando l'esecuzione avviene in modalità batch, i bundle che includono un elemento non riuscito vengono ritentati quattro volte. La pipeline non viene eseguita completamente quando un singolo bundle non viene eseguito quattro volte. Quando viene eseguito in modalità streaming, un bundle che include un elemento non riuscito viene ritentato indefinitamente, il che potrebbe causare l'arresto permanente della pipeline.
Le eccezioni nel codice utente, ad esempio le istanze DoFn, vengono
segnalate nell'interfaccia di monitoraggio Dataflow.
Se esegui la pipeline con BlockingDataflowPipelineRunner, vengono visualizzati anche
messaggi di errore stampati nella console o nella finestra del terminale.
Valuta la possibilità di proteggerti dagli errori nel codice aggiungendo gestori di eccezioni. Ad esempio, se vuoi eliminare gli elementi che non superano una convalida dell'input personalizzata eseguita in un ParDo, utilizza un blocco try/catch all'interno del ParDo per gestire l'eccezione e registrare ed eliminare l'elemento. Per i workload di produzione, implementa un
pattern di messaggi non elaborati. Per monitorare il conteggio degli errori, utilizza le
trasformazioni di aggregazione.
File di log mancanti
Se non vedi alcun log per i tuoi job, rimuovi eventuali filtri di esclusione contenenti
resource.type="dataflow_step" da tutti i sink del router dei log di Cloud Logging.
Per ulteriori dettagli sulla rimozione delle esclusioni dei log, consulta la guida Rimozione delle esclusioni.
Duplicati nell'output
Quando esegui un job Dataflow, l'output contiene record duplicati.
Questo problema può verificarsi quando il job Dataflow utilizza la modalità di streaming della pipeline at-least-once. Questa modalità garantisce che i record vengano elaborati almeno una volta. Tuttavia, in questa modalità sono possibili record duplicati.
Se il tuo flusso di lavoro non può tollerare record duplicati, utilizza la modalità di streaming exactly-once. Questa modalità contribuisce a garantire che i record non vengano eliminati o duplicati durante il trasferimento dei dati nella pipeline.
Per verificare la modalità di streaming utilizzata dal job, consulta Visualizzare la modalità di streaming di un job.
Per saperne di più sulle modalità di streaming, vedi Impostare la modalità di streaming della pipeline.
Errori della pipeline
Le sezioni seguenti contengono errori comuni della pipeline che potresti riscontrare e i passaggi per risolverli o risolverli.
Devono essere abilitate alcune API Cloud
Quando provi a eseguire un job Dataflow, si verifica il seguente errore:
Some Cloud APIs need to be enabled for your project in order for Cloud Dataflow to run this job.
Questo problema si verifica perché alcune API richieste non sono abilitate nel tuo progetto.
Per risolvere il problema ed eseguire un job Dataflow, abilita le seguenti APIGoogle Cloud nel tuo progetto:
- API Compute Engine (Compute Engine)
- API Cloud Logging
- Cloud Storage
- API Cloud Storage JSON
- API BigQuery
- Pub/Sub
- API Datastore
Per istruzioni dettagliate, consulta la sezione Guida introduttiva sull'attivazione delle API. Google Cloud
"@*" e "@N" sono specifiche di sharding riservate
Quando provi a eseguire un job, nei file di log viene visualizzato il seguente errore e il job non viene eseguito:
Workflow failed. Causes: "@*" and "@N" are reserved sharding specs. Filepattern must not contain any of them.
Questo errore si verifica se il nome file del percorso Cloud Storage per i file temporanei (tempLocation o temp_location) contiene una chiocciola (@) seguita da un numero o da un asterisco (*).
Per risolvere il problema, modifica il nome del file in modo che il simbolo @ sia seguito da un carattere supportato.
Richiesta errata
Quando esegui un job Dataflow, i log di Cloud Monitoring mostrano una serie di avvisi simili al seguente:
Unable to update setup work item STEP_ID error: generic::invalid_argument: Http(400) Bad Request
Update range task returned 'invalid argument'. Assuming lost lease for work with id LEASE_ID
with expiration time: TIMESTAMP, now: TIMESTAMP. Full status: generic::invalid_argument: Http(400) Bad Request
Gli avvisi di richiesta errata si verificano se le informazioni sullo stato del worker non sono aggiornate o non sono sincronizzate a causa di ritardi nell'elaborazione. Spesso, il job Dataflow ha esito positivo nonostante gli avvisi di richiesta errata. In questo caso, ignora gli avvisi.
Impossibile leggere e scrivere in località diverse
Quando esegui un job Dataflow, potresti visualizzare il seguente errore nei file di log:
message:Cannot read and write in different locations: source: SOURCE_REGION, destination: DESTINATION_REGION,reason:invalid
Questo errore si verifica quando l'origine e la destinazione si trovano in regioni diverse. Può
verificarsi anche quando la posizione di staging e la destinazione si trovano in regioni diverse. Ad esempio, se il job legge da Pub/Sub e poi scrive in un bucket Cloud Storage temp prima di scrivere in una tabella BigQuery, il bucket Cloud Storage temp e la tabella BigQuery devono trovarsi nella stessa regione.
Le località multiregionali sono considerate diverse dalle località monoregionali,
anche se la singola regione rientra nell'ambito della località multiregionale.
Ad esempio, us (multiple regions in the United States) e us-central1 sono
regioni diverse.
Per risolvere il problema, fai in modo che le posizioni di destinazione, origine e staging si trovino nella stessa regione. Le località dei bucket Cloud Storage non possono essere modificate, quindi potresti dover creare un nuovo bucket Cloud Storage nella regione corretta.
Timeout della connessione
Quando esegui un job Dataflow, potresti visualizzare il seguente errore nei file di log:
org.springframework.web.client.ResourceAccessException: I/O error on GET request for CONNECTION_PATH: Connection timed out (Connection timed out); nested exception is java.net.ConnectException: Connection timed out (Connection timed out)
Questo problema si verifica quando i worker Dataflow non riescono a stabilire o mantenere una connessione con l'origine dati o la destinazione.
Per risolvere il problema, segui questi passaggi:
- Verifica che l'origine dati sia in esecuzione.
- Verifica che la destinazione sia in esecuzione.
- Esamina i parametri di connessione utilizzati nella configurazione della pipeline Dataflow.
- Verifica che i problemi di rendimento non influiscano sull'origine o sulla destinazione.
- Assicurati che le regole firewall non blocchino la connessione.
Nessun oggetto di questo tipo
Quando esegui i job Dataflow, potresti visualizzare il seguente errore nei file di log:
..., 'server': 'UploadServer', 'status': '404'}>, <content <No such object:...
Questi errori si verificano in genere quando alcuni dei job Dataflow in esecuzione
utilizzano lo stesso temp_location per organizzare i file temporanei dei job creati durante
l'esecuzione della pipeline. Quando più job simultanei condividono lo stesso temp_location,
questi job potrebbero sovrascrivere i dati temporanei l'uno dell'altro e potrebbe verificarsi unarace conditione. Per evitare questo problema, ti consigliamo di utilizzare un temp_location univoco
per ogni job.
Dataflow non è in grado di determinare il backlog
Quando esegui una pipeline in modalità flusso da Pub/Sub, viene visualizzato il seguente avviso:
Dataflow is unable to determine the backlog for Pub/Sub subscription
Quando una pipeline Dataflow estrae dati da Pub/Sub, Dataflow deve richiedere ripetutamente informazioni a Pub/Sub. Queste informazioni includono la quantità di backlog dell'abbonamento e l'età del messaggio senza ACK meno recente. Occasionalmente, Dataflow non è in grado di recuperare queste informazioni da Pub/Sub a causa di problemi di sistema interni, che potrebbero causare un accumulo transitorio di backlog.
Per ulteriori informazioni, vedi Streaming con Cloud Pub/Sub.
DEADLINE_EXCEEDED o Server non risponde
Quando esegui i job, potresti riscontrare eccezioni di timeout RPC o uno dei seguenti errori:
DEADLINE_EXCEEDED
Oppure:
Server Unresponsive
Questi errori si verificano in genere per uno dei seguenti motivi:
Nella rete Virtual Private Cloud (VPC) utilizzata per il tuo job potrebbe mancare una regola firewall. La regola firewall deve abilitare tutto il traffico TCP tra le VM nella rete VPC che hai specificato nelle opzioni della pipeline. Per saperne di più, consulta Regole firewall per Dataflow.
In alcuni casi, i lavoratori non sono in grado di comunicare tra loro. Quando esegui un job Dataflow che non utilizza Dataflow Shuffle o Streaming Engine, i worker devono comunicare tra loro utilizzando le porte TCP
12345e12346all'interno della rete VPC. In questo scenario, l'errore include il nome dell'harness del worker e la porta TCP bloccata. L'errore è simile a uno dei seguenti esempi:DEADLINE_EXCEEDED: (g)RPC timed out when SOURCE_WORKER_HARNESS talking to DESTINATION_WORKER_HARNESS:12346.Rpc to WORKER_HARNESS:12345 completed with error UNAVAILABLE: failed to connect to all addresses Server unresponsive (ping error: Deadline Exceeded, UNKNOWN: Deadline Exceeded...)Per risolvere il problema, utilizza il flag rules
gcloud compute firewall-rules createper consentire il traffico di rete verso le porte12345e12346. Il seguente esempio mostra il comando Google Cloud CLI:gcloud compute firewall-rules create FIREWALL_RULE_NAME \ --network NETWORK \ --action allow \ --direction IN \ --target-tags dataflow \ --source-tags dataflow \ --priority 0 \ --rules tcp:12345-12346Sostituisci quanto segue:
FIREWALL_RULE_NAME: il nome della regola firewallNETWORK: il nome della tua rete
Il tuo lavoro è legato alla riproduzione casuale.
Per risolvere il problema, apporta una o più delle seguenti modifiche.
Java
- Se il job non utilizza lo shuffle basato su servizi, passa all'utilizzo di Dataflow Shuffle basato su servizi impostando
--experiments=shuffle_mode=service. Per dettagli e disponibilità, vedi Dataflow Shuffle. - Aggiungi altri worker. Prova a impostare
--numWorkerscon un valore più alto quando esegui la pipeline. - Aumenta le dimensioni del disco collegato per i worker. Prova a impostare
--diskSizeGbcon un valore più alto quando esegui la pipeline. - Utilizza un disco permanente basato su SSD. Prova a impostare
--workerDiskType="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"quando esegui la pipeline.
Python
- Se il job non utilizza lo shuffle basato su servizi, passa all'utilizzo di Dataflow Shuffle basato su servizi impostando
--experiments=shuffle_mode=service. Per dettagli e disponibilità, vedi Dataflow Shuffle. - Aggiungi altri worker. Prova a impostare
--num_workerscon un valore più alto quando esegui la pipeline. - Aumenta le dimensioni del disco collegato per i worker. Prova a impostare
--disk_size_gbcon un valore più alto quando esegui la pipeline. - Utilizza un disco permanente basato su SSD. Prova a impostare
--worker_disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"quando esegui la pipeline.
Vai
- Se il job non utilizza lo shuffle basato su servizi, passa all'utilizzo di Dataflow Shuffle basato su servizi impostando
--experiments=shuffle_mode=service. Per dettagli e disponibilità, vedi Dataflow Shuffle. - Aggiungi altri worker. Prova a impostare
--num_workerscon un valore più alto quando esegui la pipeline. - Aumenta le dimensioni del disco collegato per i worker. Prova a impostare
--disk_size_gbcon un valore più alto quando esegui la pipeline. - Utilizza un disco permanente basato su SSD. Prova a impostare
--disk_type="compute.googleapis.com/projects/PROJECT_ID/zones/ZONE/diskTypes/pd-ssd"quando esegui la pipeline.
- Se il job non utilizza lo shuffle basato su servizi, passa all'utilizzo di Dataflow Shuffle basato su servizi impostando
Errori di codifica, IOExceptions o comportamento imprevisto nel codice utente
Gli SDK Apache Beam e i worker Dataflow dipendono da componenti di terze parti comuni. Questi componenti importano dipendenze aggiuntive. Le collisioni di versioni possono causare un comportamento imprevisto nel servizio. Inoltre, alcune librerie non sono compatibili con le versioni successive. Potresti dover bloccare le versioni elencate che rientrano nell'ambito durante l'esecuzione. Dipendenze di SDK e nodi worker contiene un elenco di dipendenze e delle relative versioni richieste.
Errore durante l'esecuzione di LookupEffectiveGuestPolicies
Quando esegui un job Dataflow, potresti visualizzare il seguente errore nei file di log:
OSConfigAgent Error policies.go:49: Error running LookupEffectiveGuestPolicies:
error calling LookupEffectiveGuestPolicies: code: "Unauthenticated",
message: "Request is missing required authentication credential.
Expected OAuth 2 access token, login cookie or other valid authentication credential.
Questo errore si verifica se la gestione della configurazione del sistema operativo è abilitata per l'intero progetto.
Per risolvere il problema, disabilita le policy di VM Manager che si applicano all'intero progetto. Se non è possibile disattivare i criteri di VM Manager per l'intero progetto, puoi ignorare questo errore e filtrarlo dagli strumenti di monitoraggio dei log.
È stato rilevato un errore irreversibile da Java Runtime Environment
Durante l'avvio del worker si verifica il seguente errore:
A fatal error has been detected by the Java Runtime Environment
Questo errore si verifica se la pipeline utilizza Java Native Interface (JNI) per eseguire codice non Java e se questo codice o i binding JNI contengono un errore.
Errore della chiave dell'attributo googclient_deliveryattempt
Il job Dataflow non riesce a causa di uno dei seguenti errori:
The request contains an attribute key that is not valid (key=googclient_deliveryattempt). Attribute keys must be non-empty and must not begin with 'goog' (case-insensitive).
Oppure:
Invalid extensions name: googclient_deliveryattempt
Questo errore si verifica quando il job Dataflow presenta le seguenti caratteristiche:
- Il job Dataflow utilizza Streaming Engine.
- La pipeline ha un sink Pub/Sub.
- La pipeline utilizza una sottoscrizione pull.
- La pipeline utilizza una delle API di servizio Pub/Sub per pubblicare i messaggi anziché utilizzare il sink I/O Pub/Sub integrato.
- Pub/Sub utilizza la libreria client Java o C#.
- La sottoscrizione Pub/Sub ha un argomento messaggi non recapitabili.
Questo errore si verifica perché quando utilizzi la libreria client Java o C# Pub/Sub e un argomento messaggi non recapitabili per un abbonamento è abilitato, i tentativi di consegna si trovano nell'attributo del messaggio googclient_deliveryattempt anziché nel campo delivery_attempt. Per maggiori informazioni, consulta la pagina
Monitorare i tentativi di consegna
nella sezione "Gestire gli errori dei messaggi".
Per risolvere il problema, apporta una o più delle seguenti modifiche.
- Disabilita Streaming Engine.
- Utilizza il
connettore
PubSubIOApache Beam integrato anziché l'API del servizio Pub/Sub. - Utilizza un tipo di sottoscrizione Pub/Sub diverso.
- Rimuovi l'argomento di messaggi non recapitabili.
- Non utilizzare la libreria client Java o C# con l'abbonamento pull Pub/Sub. Per altre opzioni, consulta Esempi di codice delle librerie client.
- Nel codice della pipeline, quando le chiavi degli attributi iniziano con
goog, cancella gli attributi del messaggio prima di pubblicare i messaggi.
È stata rilevata una scorciatoia ...
Si verifica il seguente errore:
A hot key HOT_KEY_NAME was detected in...
Questi errori si verificano se i dati contengono un tasto di scelta rapida. Una chiave utilizzata di frequente è una chiave con elementi sufficienti a influire negativamente sulle prestazioni della pipeline. Queste chiavi limitano la capacità di Dataflow di elaborare gli elementi in parallelo, il che aumenta il tempo di esecuzione.
Per stampare la chiave leggibile dagli utenti nei log quando viene rilevata una hotkey nella pipeline, utilizza l'opzione della pipeline di hotkey.
Per risolvere il problema, verifica che i dati siano distribuiti in modo uniforme. Se una chiave ha un numero sproporzionato di valori, valuta le seguenti azioni:
- Riassegna le chiavi ai tuoi dati. Applica una
ParDotrasformazione per generare nuove coppie chiave-valore. - Per i job Java, utilizza la trasformazione
Combine.PerKey.withHotKeyFanout. - Per i job Python, utilizza la trasformazione
CombinePerKey.with_hot_key_fanout. - Attiva Dataflow Shuffle.
Per visualizzare le scorciatoie da tastiera nell'interfaccia di monitoraggio di Dataflow, vedi Risolvere i problemi relativi ai job batch in ritardo.
Specifica della tabella non valida in Data Catalog
Quando utilizzi Dataflow SQL per creare job Dataflow SQL, il job potrebbe non riuscire con il seguente errore nei file di log:
Invalid table specification in Data Catalog: Could not resolve table in Data Catalog
Questo errore si verifica se il account di servizio Dataflow non ha accesso all'API Data Catalog.
Per risolvere il problema, abilita l'API Data Catalog nel Google Cloud progetto che utilizzi per scrivere ed eseguire query.
In alternativa, assegna il ruolo roles/datacatalog.viewer all'account di servizio Dataflow.
Il grafico del job è troppo grande
Il job potrebbe non riuscire con il seguente errore:
The job graph is too large. Please try again with a smaller job graph,
or split your job into two or more smaller jobs.
Questo errore si verifica se le dimensioni del grafico del job superano i 10 MB. Determinate condizioni nella pipeline possono causare il superamento del limite del grafico dei job. Le condizioni più comuni includono:
- Una trasformazione
Createche include una grande quantità di dati in memoria. - Una grande istanza
DoFnserializzata per la trasmissione a lavoratori remoti. - Un
DoFncome istanza di classe interna anonima che (forse inavvertitamente) recupera una grande quantità di dati da serializzare. - Un grafo diretto aciclico (DAG) viene utilizzato come parte di un ciclo programmatico che enumera un elenco di grandi dimensioni.
Per evitare queste condizioni, valuta la possibilità di ristrutturare la pipeline.
Key Commit Too Large
Quando esegui un job di streaming, nei file di log del worker viene visualizzato il seguente errore:
KeyCommitTooLargeException
Questo errore si verifica negli scenari di streaming se una quantità molto grande di dati viene
raggruppata senza utilizzare una trasformazione Combine o se una grande quantità di dati viene
prodotta da un singolo elemento di input.
Per ridurre la possibilità di riscontrare questo errore, utilizza le seguenti strategie:
- Assicurati che l'elaborazione di un singolo elemento non possa comportare modifiche allo stato o agli output che superano il limite.
- Se più elementi sono stati raggruppati in base a una chiave, valuta la possibilità di aumentare lo spazio delle chiavi per ridurre gli elementi raggruppati per chiave.
- Se gli elementi per una chiave vengono emessi con una frequenza elevata in un breve periodo di tempo, ciò potrebbe comportare molti GB di eventi per quella chiave nelle finestre. Riscrivi la pipeline per rilevare chiavi come questa ed emetti solo un output che indichi che la chiave era presente frequentemente in quella finestra.
- Utilizza le trasformazioni dello spazio sublineare
Combineper operazioni commutative e associative. Non utilizzare un combinatore se non riduce lo spazio. Ad esempio, il combinatore per le stringhe che le accoda semplicemente è peggiore rispetto a non utilizzare il combinatore.
Rifiuto del messaggio superiore a 7168 K
Quando esegui un job Dataflow creato da un modello, il job potrebbe non riuscire e restituire il seguente errore:
Error: CommitWork failed: status: APPLICATION_ERROR(3): Pubsub publish requests are limited to 10MB, rejecting message over 7168K (size MESSAGE_SIZE) to avoid exceeding limit with byte64 request encoding.
Questo errore si verifica quando i messaggi scritti in una coda di messaggi non recapitabili superano il limite di dimensioni di 7168 K. Come soluzione alternativa, attiva Streaming Engine, che ha un limite di dimensioni più elevato. Per abilitare Streaming Engine, utilizza la seguente opzione della pipeline.
Java
--enableStreamingEngine=true
Python
--enable_streaming_engine=true
Request Entity Too Large (Dimensioni dell'entità richiesta eccessive)
Quando invii il job, nella console o nella finestra del terminale viene visualizzato uno dei seguenti errori:
413 Request Entity Too Large
The size of serialized JSON representation of the pipeline exceeds the allowable limit
Failed to create a workflow job: Invalid JSON payload received
Failed to create a workflow job: Request payload exceeds the allowable limit
Quando si verifica un errore relativo al payload JSON durante l'invio del job, la rappresentazione JSON della pipeline supera la dimensione massima della richiesta di 20 MB.
La dimensione del job è legata alla rappresentazione JSON della pipeline. Una pipeline più grande significa una richiesta più grande. Dataflow ha una limitazione che limita le richieste a 20 MB.
Per stimare le dimensioni della richiesta JSON della pipeline, esegui la pipeline con l'opzione seguente:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Vai
L'output del job in formato JSON non è supportato in Go.
Questo comando scrive una rappresentazione JSON del job in un file. Le dimensioni del file serializzato sono una buona stima delle dimensioni della richiesta. Le dimensioni effettive sono leggermente maggiori a causa di alcune informazioni aggiuntive incluse nella richiesta.
Determinate condizioni nella pipeline possono far sì che la rappresentazione JSON superi il limite. Le condizioni più comuni includono:
- Una trasformazione
Createche include una grande quantità di dati in memoria. - Una grande istanza
DoFnserializzata per la trasmissione a lavoratori remoti. - Un
DoFncome istanza di classe interna anonima che (forse inavvertitamente) recupera una grande quantità di dati da serializzare.
Per evitare queste condizioni, valuta la possibilità di ristrutturare la pipeline.
Le opzioni della pipeline SDK o l'elenco dei file di staging superano il limite di dimensioni
Durante l'esecuzione di una pipeline, si verifica uno dei seguenti errori:
SDK pipeline options or staging file list exceeds size limit.
Please keep their length under 256K Bytes each and 512K Bytes in total.
Oppure:
Value for field 'resource.properties.metadata' is too large: maximum size
Questi errori si verificano se la pipeline non è stata avviata perché sono stati superati i limiti dei metadati di Compute Engine. Questi limiti non possono essere modificati. Dataflow utilizza i metadati di Compute Engine per le opzioni della pipeline. Il limite è documentato nelle limitazioni dei metadati personalizzati di Compute Engine.
I seguenti scenari possono causare il superamento del limite della rappresentazione JSON:
- Ci sono troppi file JAR da preparare.
- Il campo della richiesta
sdkPipelineOptionsè troppo grande.
Per stimare le dimensioni della richiesta JSON della pipeline, esegui la pipeline con l'opzione seguente:
Java
--dataflowJobFile=PATH_TO_OUTPUT_FILE
Python
--dataflow_job_file=PATH_TO_OUTPUT_FILE
Vai
L'output del job in formato JSON non è supportato in Go.
Le dimensioni del file di output di questo comando devono essere inferiori a 256 KB. I 512 KB nel messaggio di errore si riferiscono alla dimensione totale del file di output e alle opzioni di metadati personalizzati per l'istanza VM di Compute Engine.
Puoi ottenere una stima approssimativa dell'opzione dei metadati personalizzati per l'istanza VM eseguendo job Dataflow nel progetto. Scegli un job Dataflow in esecuzione. Prendi un'istanza VM e vai alla pagina dei dettagli dell'istanza VM Compute Engine per quella VM per verificare la presenza della sezione dei metadati personalizzati. La lunghezza totale dei metadati personalizzati e del file deve essere inferiore a 512 KB. Non è possibile una stima accurata per il job non riuscito, perché le VM non vengono avviate per i job non riusciti.
Se l'elenco JAR raggiunge il limite di 256 KB, rivedilo e riduci i file JAR non necessari. Se è ancora troppo grande, prova a eseguire il job Dataflow utilizzando un uber JAR. Per un esempio che mostra come creare e utilizzare un uber JAR, consulta Compila e implementa un uber JAR.
Se il campo della richiesta sdkPipelineOptions è troppo grande, includi la seguente opzione
quando esegui la pipeline. L'opzione della pipeline è la stessa per Java, Python e Go.
--experiments=no_display_data_on_gce_metadata
Chiave di riproduzione casuale troppo grande
Nei file di log del worker viene visualizzato il seguente errore:
Shuffle key too large
Questo errore si verifica se la chiave serializzata emessa per un determinato (Co-)GroupByKey è troppo grande dopo l'applicazione del codificatore corrispondente. Dataflow ha un limite per le chiavi di rimescolamento serializzate.
Per risolvere il problema, riduci le dimensioni delle chiavi o utilizza codificatori più efficienti in termini di spazio.
Per maggiori informazioni, consulta Limiti di produzione per Dataflow.
Il numero totale di oggetti BoundedSource ... è superiore al limite consentito
Quando esegui job con Java, potrebbe verificarsi uno dei seguenti errori:
Total number of BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Oppure:
Total size of the BoundedSource objects generated by splitIntoBundles() operation is larger than the allowable limit
Java
Questo errore può verificarsi se leggi un numero molto elevato di file utilizzando
TextIO, AvroIO, BigQueryIO tramite EXPORT o un'altra origine
basata su file. Il limite specifico dipende dai dettagli dell'origine, ma
è dell'ordine di decine di migliaia di file in una pipeline. Ad esempio,
l'incorporamento dello schema in AvroIO.Read consente un numero inferiore di file.
Questo errore può verificarsi anche se hai creato una sorgente dati personalizzata per la pipeline e il metodo splitIntoBundles della sorgente ha restituito un elenco di oggetti BoundedSource che occupano più di 20 MB quando vengono serializzati.
Il limite consentito per le dimensioni totali degli oggetti BoundedSource
generati dall'operazione splitIntoBundles() della tua origine personalizzata è
20 MB.
Per ovviare a questo limite, apporta una delle seguenti modifiche:
Attiva Runner V2. Runner v2 converte le origini in DoFn divisibili che non hanno questo limite di divisione delle origini.
Modifica la sottoclasse
BoundedSourcepersonalizzata in modo che la dimensione totale degli oggettiBoundedSourcegenerati sia inferiore al limite di 20 MB. Ad esempio, la tua origine potrebbe generare inizialmente meno suddivisioni e fare affidamento al ribilanciamento dinamico del lavoro per suddividere ulteriormente gli input su richiesta.
Le dimensioni del payload della richiesta superano il limite: 20971520 byte
Quando esegui una pipeline, il job potrebbe non riuscire con il seguente errore:
com.google.api.client.googleapis.json.GoogleJsonResponseException: 400 Bad Request
POST https://dataflow.googleapis.com/v1b3/projects/PROJECT_ID/locations/REGION/jobs/JOB_ID/workItems:reportStatus
{
"code": 400,
"errors": [
{
"domain": "global",
"message": "Request payload size exceeds the limit: 20971520 bytes.",
"reason": "badRequest"
}
],
"message": "Request payload size exceeds the limit: 20971520 bytes.",
"status": "INVALID_ARGUMENT"
}
Questo errore può verificarsi quando un job che utilizza il runner Dataflow ha un grafico del job molto grande. Un grafico dei job di grandi dimensioni può generare un numero elevato di metriche che devono essere segnalate al servizio Dataflow. Se le dimensioni di queste metriche superano il limite di 20 MB per le richieste API, il job non va a buon fine.
Per risolvere il problema, esegui la migrazione della pipeline per utilizzare Dataflow Runner v2. Runner v2 utilizza un metodo più efficiente per la generazione di report sulle metriche e non presenta questa limitazione di 20 MB.
NameError
Quando esegui la pipeline utilizzando il servizio Dataflow, si verifica il seguente errore:
NameError
Questo errore non si verifica quando esegui localmente, ad esempio quando esegui
utilizzando DirectRunner.
Questo errore si verifica se i tuoi DoFn utilizzano valori nello spazio dei nomi globale che
non sono disponibili sul worker Dataflow.
Per impostazione predefinita, le importazioni, le funzioni e le variabili globali definite nella sessione principale non vengono salvate durante la serializzazione di un job Dataflow.
Per risolvere il problema, utilizza uno dei seguenti metodi. Se i tuoi DoFn sono
definiti nel file principale e fanno riferimento a importazioni e funzioni nello spazio dei nomi globale, imposta l'opzione della pipeline --save_main_session su True. Questa modifica
serializza lo stato dello spazio dei nomi globale e lo carica sul
worker Dataflow.
Se nello spazio dei nomi globale sono presenti oggetti che non possono essere serializzati, si verifica un errore di serializzazione. Se l'errore riguarda un modulo che dovrebbe essere disponibile nella distribuzione Python, importa il modulo localmente, dove viene utilizzato.
Ad esempio, invece di:
import re … def myfunc(): # use re module
Utilizzo:
def myfunc(): import re # use re module
In alternativa, se i tuoi DoFns si estendono su più file, utilizza
un approccio diverso per il packaging del flusso di lavoro e
la gestione delle dipendenze.
L'oggetto è soggetto al criterio di conservazione del bucket
Quando hai un job Dataflow che scrive in un bucket Cloud Storage, il job non va a buon fine e viene visualizzato il seguente errore:
Object 'OBJECT_NAME' is subject to bucket's retention policy or object retention and cannot be deleted or overwritten
Potresti anche visualizzare il seguente errore:
Unable to rename "gs://BUCKET"
Il primo errore si verifica quando la conservazione degli oggetti è abilitata nel bucket Cloud Storage in cui scrive il job Dataflow. Per saperne di più, vedi Attivare e utilizzare le configurazioni di conservazione degli oggetti.
Per risolvere il problema, utilizza una delle seguenti soluzioni alternative:
Scrivi in un bucket Cloud Storage che non ha una policy di conservazione nella cartella
temp.Rimuovi il criterio di conservazione dal bucket in cui viene scritto il job. Per ulteriori informazioni, vedi Impostare la configurazione della conservazione di un oggetto.
Il secondo errore può indicare che la conservazione degli oggetti è abilitata nel bucket Cloud Storage oppure che il account di servizio worker Dataflow non dispone dell'autorizzazione per scrivere nel bucket Cloud Storage.
Se visualizzi il secondo errore e la conservazione degli oggetti è attivata nel bucket Cloud Storage, prova le soluzioni alternative descritte in precedenza. Se la conservazione degli oggetti non è abilitata nel bucket Cloud Storage, verifica se iaccount di serviziont worker Dataflow dispone dell'autorizzazione di scrittura sul bucket Cloud Storage. Per maggiori informazioni, consulta Accedere ai bucket Cloud Storage.
Elaborazione bloccata o operazione in corso
Se Dataflow impiega più tempo per eseguire un DoFn rispetto al tempo
specificato in TIME_INTERVAL senza restituire un risultato, viene visualizzato il seguente messaggio.
Java
Uno dei due seguenti messaggi di log, a seconda della versione:
Processing stuck in step STEP_NAME for at least TIME_INTERVAL
Operation ongoing in bundle BUNDLE_ID for at least TIME_INTERVAL without outputting or completing: at STACK_TRACE
Python
Operation ongoing for over TIME_INTERVAL in state STATE in step STEP_ID without returning. Current Traceback: TRACEBACK
Vai
Operation ongoing in transform TRANSFORM_ID for at least TIME_INTERVAL without outputting or completing in state STATE
Questo comportamento ha due possibili cause:
- Il codice
DoFnè lento o in attesa del completamento di un'operazione esterna lenta. - Il codice
DoFnpotrebbe essere bloccato, in stallo o anormalmente lento da elaborare.
Per determinare quale sia il caso, espandi la voce di log di Cloud Monitoring per visualizzare una analisi dello stack. Cerca messaggi che indicano che il codice DoFn è bloccato
o che si verificano problemi. Se non sono presenti messaggi, il problema potrebbe essere
la velocità di esecuzione del codice DoFn. Prendi in considerazione l'utilizzo di
Cloud Profiler o di un altro strumento per
analizzare le prestazioni del tuo codice.
Se la pipeline è basata sulla JVM (utilizzando Java o Scala), puoi analizzare la causa del codice bloccato. Esegui un dump completo del thread dell'intera JVM (non solo del thread bloccato) seguendo questi passaggi:
- Prendi nota del nome del worker dalla voce di log.
- Nella sezione Compute Engine della console Google Cloud , trova l'istanza Compute Engine con il nome del worker che hai annotato.
- Utilizza SSH per connetterti all'istanza con quel nome.
Esegui questo comando:
curl http://localhost:8081/threadz
Operazione in corso nel bundle
Quando esegui una pipeline di lettura da
JdbcIO,
le letture partizionate da JdbcIO sono lente e nel file di log del worker viene visualizzato il seguente messaggio:
Operation ongoing in bundle process_bundle-[0-9-]* for PTransform{id=Read from JDBC with Partitions\/JdbcIO.Read\/JdbcIO.ReadAll\/ParDo\(Read\)\/ParMultiDo\(Read\).*, state=process} for at least (0[1-9]h[0-5][0-9]m[0-5][0-9]s) without outputting or completing:
Per risolvere il problema, apporta una o più delle seguenti modifiche alla pipeline:
Utilizza le partizioni per aumentare il parallelismo dei job. Lettura con partizioni più numerose e più piccole per una migliore scalabilità.
Controlla se la colonna di partizionamento è una colonna di indice o una colonna di partizionamento effettiva nell'origine. Attiva l'indicizzazione e il partizionamento in questa colonna nel database di origine per ottenere le prestazioni migliori.
Utilizza i parametri
lowerBoundeupperBoundper saltare la ricerca dei limiti.
Errori di quota di Pub/Sub
Quando esegui una pipeline di streaming da Pub/Sub, si verificano i seguenti errori:
429 (rateLimitExceeded)
Oppure:
Request was throttled due to user QPS limit being reached
Questi errori si verificano se il tuo progetto ha una quota Pub/Sub insufficiente.
Per scoprire se il tuo progetto ha una quota insufficiente, segui questi passaggi per verificare la presenza di errori del client:
- Vai alla consoleGoogle Cloud .
- Nel menu a sinistra, seleziona API e servizi.
- Nella casella di ricerca, cerca Cloud Pub/Sub.
- Fai clic sulla scheda Utilizzo.
- Controlla Codici di risposta e cerca i codici di errore del client
(4xx).
La richiesta è vietata dalla policy dell'organizzazione
Quando esegui una pipeline, si verifica il seguente errore:
Error trying to get gs://BUCKET_NAME/FOLDER/FILE:
{"code":403,"errors":[{"domain":"global","message":"Request is prohibited by organization's policy","reason":"forbidden"}],
"message":"Request is prohibited by organization's policy"}
Questo errore si verifica se il bucket Cloud Storage si trova al di fuori del tuo perimetro di servizio.
Per risolvere il problema, crea una regola di uscita che consenta l'accesso al bucket al di fuori del perimetro di servizio.
Il pacchetto di gestione temporanea...non è accessibile
I job che prima venivano eseguiti correttamente potrebbero non riuscire con il seguente errore:
Staged package...is inaccessible
Per risolvere il problema:
- Verifica che il bucket Cloud Storage utilizzato per lo staging non abbia impostazioni TTL che causano l'eliminazione dei pacchetti di staging.
Verifica che il account di servizio worker del tuo progetto Dataflow disponga dell'autorizzazione per accedere al bucket Cloud Storage utilizzato per lo staging. Le lacune nelle autorizzazioni possono essere dovute a uno dei seguenti motivi:
- Il bucket Cloud Storage utilizzato per la gestione temporanea si trova in un progetto diverso.
- Il bucket Cloud Storage utilizzato per la gestione temporanea è stato migrato dall'accesso granulare all'accesso uniforme a livello di bucket. A causa dell'incoerenza tra i criteri IAM e ACL, la migrazione del bucket di staging all'accesso uniforme a livello di bucket non consente gli ACL per le risorse Cloud Storage. Gli elenchi di controllo degli accessi includono le autorizzazioni detenute dall'account di servizio worker del tuo progetto Dataflow sul bucket di staging.
Per maggiori informazioni, vedi Accesso ai bucket Cloud Storage in diversi Google Cloud Platform Cloud.
Un elemento di lavoro non è riuscito 4 volte
Quando un job batch non va a buon fine, si verifica il seguente errore:
The job failed because a work item has failed 4 times.
Questo errore si verifica se una singola operazione in un job batch causa l'errore del codice worker quattro volte. Dataflow non riesce a eseguire il job e viene visualizzato questo messaggio.
Quando viene eseguito in modalità streaming, un bundle che include un elemento non riuscito viene ritentato indefinitamente, il che potrebbe causare l'arresto permanente della pipeline.
Non puoi configurare questa soglia di errore. Per maggiori dettagli, consulta Gestione di errori ed eccezioni della pipeline.
Per risolvere il problema, cerca nei log di Cloud Monitoring del job i quattro errori individuali. Nei log del worker, cerca voci di log di livello Error o livello Fatal che mostrano eccezioni o errori. L'eccezione o l'errore deve essere visualizzato almeno quattro volte. Se i log contengono solo errori di timeout generici relativi all'accesso a risorse esterne, come MongoDB, verifica che il account di servizio worker disponga dell'autorizzazione per accedere alla subnet della risorsa.
Timeout nel file dei risultati del polling
Per informazioni complete sulla risoluzione dell'errore "Timeout nel file di risultati del polling", consulta Risoluzione dei problemi relativi ai modelli Flex.
Write Correct File/Write/WriteImpl/PreFinalize failed
Quando esegui un job, questo non va a buon fine in modo intermittente e si verifica il seguente errore:
Workflow failed. Causes: S27:Write Correct File/Write/WriteImpl/PreFinalize failed., Internal Issue (ID): ID:ID, Unable to expand file pattern gs://BUCKET_NAME/temp/FILE
Questo errore si verifica quando la stessa sottocartella viene utilizzata come posizione di archiviazione temporanea per più job eseguiti contemporaneamente.
Per risolvere il problema, non utilizzare la stessa sottocartella come posizione di archiviazione temporanea per più pipeline. Per ogni pipeline, fornisci una sottocartella univoca da utilizzare come posizione di archiviazione temporanea.
L'elemento supera le dimensioni massime del messaggio protobuf
Quando esegui job Dataflow e la pipeline contiene elementi di grandi dimensioni, potresti visualizzare errori simili agli esempi seguenti:
Exception serializing message!
ValueError: Message org.apache.beam.model.fn_execution.v1.Elements exceeds maximum protobuf size of 2GB
Oppure:
Buffer size ... exceeds GRPC limit 2147483548. This is likely due to a single element that is too large.
Potresti anche visualizzare un avviso simile al seguente esempio:
Data output stream buffer size ... exceeds 536870912 bytes. This is likely due to a large element in a PCollection.
Questi errori si verificano quando la pipeline contiene elementi di grandi dimensioni.
Per risolvere il problema, se utilizzi l'SDK Python, esegui l'upgrade ad Apache Beam versione 2.57.0 o successive. Le versioni 2.57.0 e successive dell'SDK Python migliorano l'elaborazione di elementi di grandi dimensioni e aggiungono la registrazione pertinente.
Se gli errori persistono dopo l'upgrade o se non utilizzi l'SDK Python, identifica il passaggio del job in cui si verifica l'errore e prova a ridurre le dimensioni degli elementi in quel passaggio.
Quando gli oggetti PCollection nella pipeline contengono elementi di grandi dimensioni, i requisiti di RAM per la pipeline aumentano.
Gli elementi di grandi dimensioni possono anche causare errori di runtime,
soprattutto quando superano i limiti delle fasi unite.
Gli elementi di grandi dimensioni possono verificarsi quando una pipeline materializza inavvertitamente un iterabile di grandi dimensioni. Ad esempio, una pipeline che passa l'output di
un'operazione GroupByKey a un'operazione Reshuffle non necessaria
materializza gli elenchi come singoli elementi. Questi elenchi potrebbero contenere
un numero elevato di valori per ogni chiave.
Se l'errore si verifica in un passaggio che utilizza un input laterale, tieni presente che l'utilizzo di input laterali può introdurre una barriera di fusione. Controlla se la trasformazione che produce un elemento di grandi dimensioni e quella che lo utilizza appartengono alla stessa fase.
Quando crei la pipeline, segui queste best practice:
- In
PCollectionsutilizza più elementi piccoli anziché un unico elemento grande. - Archivia blob di grandi dimensioni in sistemi di archiviazione esterni. Utilizza
PCollectionsper trasmettere i metadati oppure utilizza un codificatore personalizzato che riduce le dimensioni dell'elemento. - Se devi passare una PCollection che può superare i 2 GB come input aggiuntivo, utilizza viste iterabili, come
AsIterableeAsMultiMap.
La dimensione massima per un singolo elemento in un job Dataflow è limitata a 2 GB. Per ulteriori informazioni, consulta Quote e limiti.
Dataflow non è in grado di elaborare le trasformazioni gestite...
Le pipeline che utilizzano I/O gestito potrebbero non riuscire a causa di questo errore se Dataflow non riesce a eseguire l'upgrade automatico delle trasformazioni I/O all'ultima versione supportata. L'URN e i nomi dei passaggi forniti nell'errore devono specificare quali trasformazioni esatte Dataflow non è riuscito ad aggiornare.
Potresti trovare ulteriori dettagli su questo errore in
Esplora log in
Nomi dei log di Dataflow managed-transforms-worker e
managed-transforms-worker-startup.
Se Esplora log non fornisce informazioni sufficienti per risolvere il problema dell'errore, contatta l'assistenza clienti Google Cloud.
Errori relativi ai job di archiviazione
Le sezioni seguenti contengono errori comuni che potresti riscontrare quando tenti di archiviare un job Dataflow utilizzando l'API.
Nessun valore fornito
Quando provi ad archiviare un job Dataflow utilizzando l'API, potrebbe verificarsi il seguente errore:
The field mask specifies an update for the field job_metadata.user_display_properties.archived in job JOB_ID, but no value is provided. To update a field, please provide a field for the respective value.
Questo errore si verifica per uno dei seguenti motivi:
Il percorso specificato per il campo
updateMasknon segue il formato corretto. Questo problema può verificarsi a causa di errori di battitura.JobMetadatanon è specificato correttamente. Nel campoJobMetadata, peruserDisplayProperties, utilizza la coppia chiave-valore"archived":"true".
Per risolvere questo errore, verifica che il comando che passi all'API corrisponda al formato richiesto. Per maggiori dettagli, vedi Archiviare un lavoro.
L'API non riconosce il valore
Quando provi ad archiviare un job Dataflow utilizzando l'API, potrebbe verificarsi il seguente errore:
The API does not recognize the value VALUE for the field job_metadata.user_display_properties.archived for job JOB_ID. REASON: Archived display property can only be set to 'true' or 'false'
Questo errore si verifica quando il valore fornito nella coppia chiave-valore dei job di archiviazione non è un valore supportato. I valori supportati per la coppia chiave-valore dei job di archiviazione sono
"archived":"true" e "archived":"false".
Per risolvere questo errore, verifica che il comando che passi all'API corrisponda al formato richiesto. Per maggiori dettagli, vedi Archiviare un lavoro.
Impossibile aggiornare sia lo stato che la maschera
Quando provi ad archiviare un job Dataflow utilizzando l'API, potrebbe verificarsi il seguente errore:
Cannot update both state and mask.
Questo errore si verifica quando tenti di aggiornare sia lo stato del job sia lo stato dell'archivio nella stessa chiamata API. Non puoi apportare aggiornamenti sia allo stato del job sia al parametro di query updateMask nella stessa chiamata API.
Per risolvere questo errore, aggiorna lo stato del job in una chiamata API separata. Apporta aggiornamenti allo stato del job prima di aggiornare lo stato dell'archivio dei job.
Modifica del workflow non riuscita
Quando provi ad archiviare un job Dataflow utilizzando l'API, potrebbe verificarsi il seguente errore:
Workflow modification failed.
Questo errore si verifica in genere quando tenti di archiviare un job in esecuzione.
Per risolvere questo errore, attendi il completamento del job prima di archiviarlo. I job completati hanno uno dei seguenti stati del job:
JOB_STATE_CANCELLEDJOB_STATE_DRAINEDJOB_STATE_DONEJOB_STATE_FAILEDJOB_STATE_UPDATED
Per saperne di più, consulta Rilevare il completamento del job Dataflow.
Errori relativi alle immagini container
Le sezioni seguenti contengono errori comuni che potresti riscontrare quando utilizzi i container personalizzati e i passaggi per risolvere o risolvere i problemi relativi agli errori. Gli errori sono in genere preceduti dal seguente messaggio:
Unable to pull container image due to error: DETAILED_ERROR_MESSAGE
Autorizzazione "containeranalysis.occurrences.list" negata
Nei file di log viene visualizzato il seguente errore:
Error getting old patchz discovery occurrences: generic::permission_denied: permission "containeranalysis.occurrences.list" denied for project "PROJECT_ID", entity ID "" [region="REGION" projectNum=PROJECT_NUMBER projectID="PROJECT_ID"]
L'API Container Analysis è necessaria per l'analisi delle vulnerabilità.
Per saperne di più, consulta le sezioni Panoramica della scansione del sistema operativo e Configurazione del controllo dell'accesso nella documentazione di Artifact Analysis.
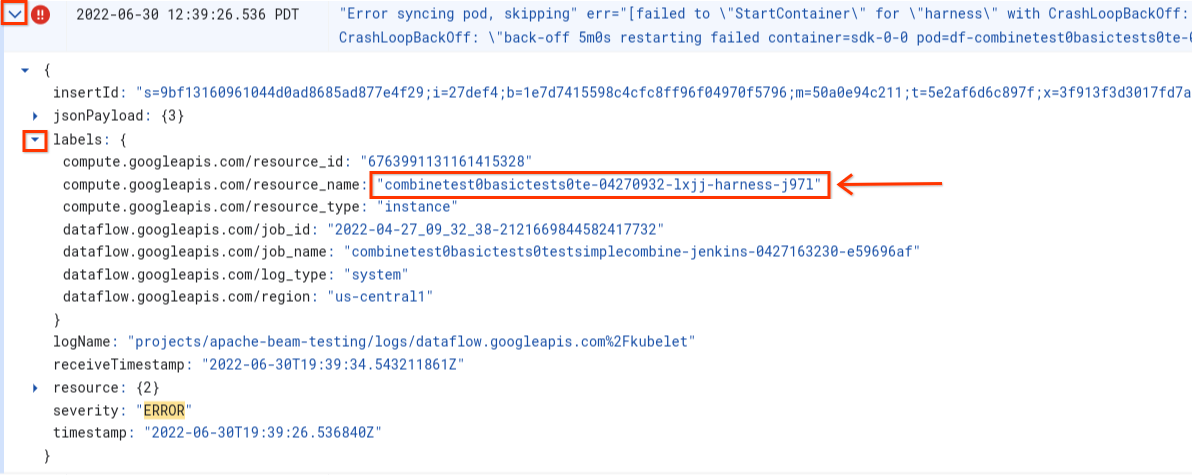
Errore durante la sincronizzazione del pod… impossibile avviare il container
Durante l'avvio del worker si verifica il seguente errore:
Error syncing pod POD_ID, skipping: [failed to "StartContainer" for CONTAINER_NAME with CrashLoopBackOff: "back-off 5m0s restarting failed container=CONTAINER_NAME pod=POD_NAME].
Un pod è un gruppo di container Docker collocati insieme in esecuzione su un worker Dataflow. Questo errore si verifica quando l'avvio di uno dei container Docker nel pod non va a buon fine. Se l'errore non è recuperabile, il worker Dataflow non è in grado di avviarsi e i job batch Dataflow alla fine non vanno a buon fine con errori come i seguenti:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Questo errore si verifica in genere quando uno dei container si arresta in modo anomalo continuamente durante l'avvio.
Per comprendere la causa principale, cerca i log acquisiti immediatamente prima dell'errore. Per analizzare i log, utilizza Esplora log. In Esplora log, limita i file di log alle voci di log emesse dal worker con errori di avvio del container. Per limitare le voci di log, completa i seguenti passaggi:
- In Esplora log, individua la voce di log
Error syncing pod. - Per visualizzare le etichette associate alla voce di log, espandila.
- Fai clic sull'etichetta associata a
resource_name, poi su Mostra voci corrispondenti.
In Esplora log, i log di Dataflow sono organizzati in
diversi stream di log. Il messaggio Error syncing pod viene emesso nel log denominato
kubelet. Tuttavia, i log del container non riuscito potrebbero trovarsi in un flusso di log diverso. Ogni contenitore ha un nome. Utilizza la seguente tabella per determinare
quale flusso di log potrebbe contenere log pertinenti al container non riuscito.
| Nome container | Nomi log |
|---|---|
| sdk, sdk0, sdk1, sdk-0-0 e simili | docker |
| harness | harness, harness-startup |
| python, java-batch, java-streaming | worker-startup, worker |
| artefatto | artefatto |
Quando esegui una query in Esplora log, assicurati che la query includa i nomi dei log pertinenti nell'interfaccia del generatore di query o non abbia restrizioni sul nome del log.
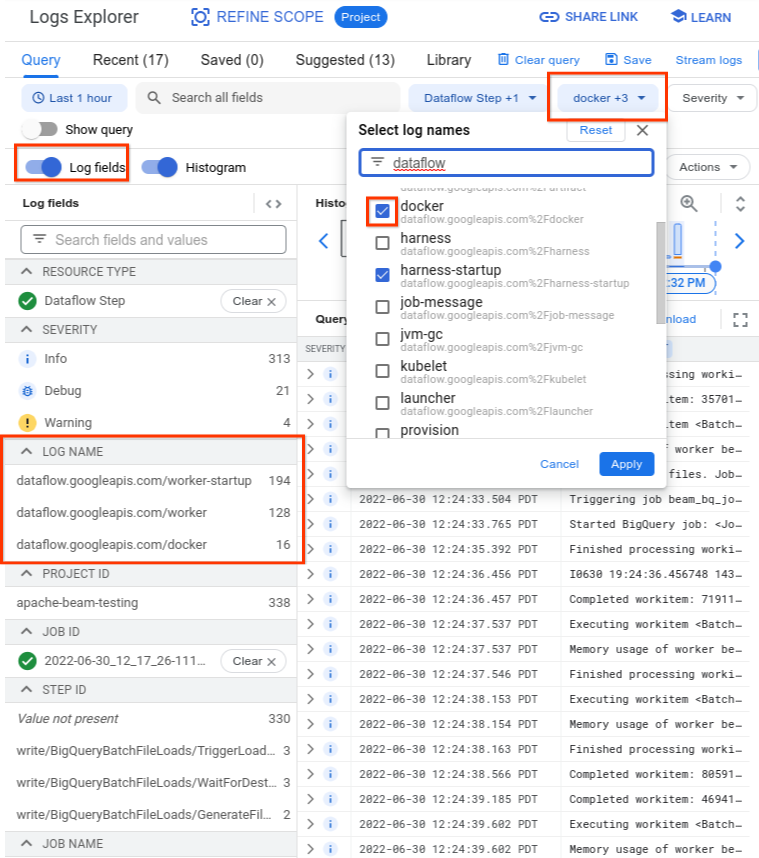
Dopo aver selezionato i log pertinenti, il risultato della query potrebbe essere simile all'esempio seguente:
resource.type="dataflow_step"
resource.labels.job_id="2022-06-29_08_02_54-JOB_ID"
labels."compute.googleapis.com/resource_name"="testpipeline-jenkins-0629-DATE-cyhg-harness-8crw"
logName=("projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fdocker"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker-startup"
OR
"projects/apache-beam-testing/logs/dataflow.googleapis.com%2Fworker")
Poiché i log che segnalano il sintomo dell'errore del contenitore a volte
vengono segnalati come INFO, includi i log INFO nell'analisi.
Le cause tipiche degli errori del contenitore includono:
- La pipeline Python ha dipendenze aggiuntive installate al runtime e l'installazione non va a buon fine. Potresti visualizzare errori come
pip install failed with error. Questo problema potrebbe verificarsi a causa di requisiti in conflitto o di una configurazione di rete con limitazioni che impedisce a un worker Dataflow di estrarre una dipendenza esterna da un repository pubblico su internet. Un worker non funziona correttamente a metà dell'esecuzione della pipeline a causa di un errore di esaurimento della memoria. Potresti visualizzare un errore simile a uno dei seguenti:
java.lang.OutOfMemoryError: Java heap spaceShutting down JVM after 8 consecutive periods of measured GC thrashing. Memory is used/total/max = 24453/42043/42043 MB, GC last/max = 58.97/99.89 %, #pushbacks=82, gc thrashing=true. Heap dump not written.
Per eseguire il debug di un problema di memoria insufficiente, consulta Risolvere gli errori di memoria insufficiente di Dataflow.
Dataflow non riesce a eseguire il pull dell'immagine container. Per ulteriori informazioni, consulta Richiesta di pull dell'immagine non riuscita con errore.
Il container utilizzato non è compatibile con l'architettura della CPU della VM worker. Nei log di avvio dell'harness potresti visualizzare un errore simile al seguente:
exec /opt/apache/beam/boot: exec format error. Per controllare l'architettura dell'immagine del container, eseguidocker image inspect $IMAGE:$TAGe cerca la parola chiaveArchitecture. Se viene visualizzatoError: No such image: $IMAGE:$TAG, potresti dover prima estrarre l'immagine eseguendodocker pull $IMAGE:$TAG. Per informazioni sulla creazione di immagini multiarchitettura, vedi Crea un'immagine container multiarchitettura.
Dopo aver identificato l'errore che causa l'interruzione del container, prova a risolverlo e invia di nuovo la pipeline.
Richiesta di pull dell'immagine non riuscita con errore
Durante l'avvio del worker, nei log del worker o del job viene visualizzato uno dei seguenti errori:
Image pull request failed with error
pull access denied for IMAGE_NAME
manifest for IMAGE_NAME not found: manifest unknown: Failed to fetch
Get IMAGE_NAME: Service Unavailable
Questi errori si verificano se un worker non riesce ad avviarsi perché non riesce a eseguire il pull di un'immagine container Docker. Questo problema si verifica nei seguenti scenari:
- L'URL dell'immagine del contenitore SDK personalizzato non è corretto
- Il lavoratore non dispone delle credenziali o dell'accesso alla rete per l'immagine remota
Per risolvere il problema:
- Se utilizzi un'immagine container personalizzata con il tuo job, verifica che l'URL dell'immagine sia corretto e che abbia un tag o un digest valido. I worker Dataflow devono accedere anche all'immagine.
- Verifica che le immagini pubbliche possano essere estratte localmente eseguendo
docker pull $imageda una macchina non autenticata.
Per immagini private o lavoratori privati:
- Se utilizzi Container Registry per ospitare l'immagine container, ti consigliamo di utilizzare Artifact Registry. A partire dal 15 maggio 2023, Container Registry è deprecato. Se utilizzi Container Registry, puoi eseguire la transizione ad Artifact Registry. Se le immagini si trovano in un progetto diverso da quello utilizzato per eseguire il job Google Cloud Platform, configura il controllo dell'accesso per l'account di servizio Google Cloud Platform predefinito.
- Se utilizzi Virtual Private Cloud (VPC) condiviso, assicurati che i worker possano accedere all'host del repository di container personalizzati.
- Utilizza
sshper connetterti a una VM worker del job in esecuzione ed eseguidocker pull $imageper verificare direttamente che il worker sia configurato correttamente.
Se i worker non riescono a eseguire più volte di seguito un job a causa di questo errore e il lavoro è iniziato, il job può non riuscire con un errore simile al seguente messaggio:
Job appears to be stuck.
Se rimuovi l'accesso all'immagine durante l'esecuzione del job, rimuovendo l'immagine stessa o revocando le credenziali del service account worker Dataflow o l'accesso a internet per accedere alle immagini, Dataflow registra solo gli errori. Dataflow non genera errori nel job. Dataflow evita inoltre l'interruzione delle pipeline di streaming a lunga esecuzione per evitare la perdita dello stato della pipeline.
Altri possibili errori possono derivare da problemi di quota o interruzioni del repository. Se riscontri problemi di superamento della quota di Docker Hub per il pull di immagini pubbliche o interruzioni generali dei repository di terze parti, valuta la possibilità di utilizzare Artifact Registry come repository di immagini.
SystemError: unknown opcode
La pipeline del container personalizzato Python potrebbe non riuscire a essere eseguita con il seguente errore subito dopo l'invio del job:
SystemError: unknown opcode
Inoltre, la analisi dello stack potrebbe includere
apache_beam/internal/pickler.py
Per risolvere il problema, verifica che la versione di Python che utilizzi localmente corrisponda alla versione nell'immagine container fino alla versione principale e secondaria. La differenza nella versione della patch, ad esempio 3.6.7 rispetto a 3.6.8, non crea problemi di compatibilità. La differenza nella versione secondaria, ad esempio 3.6.8 rispetto a 3.8.2, può causare errori della pipeline.
Errori di upgrade della pipeline di streaming
Per informazioni su come risolvere gli errori durante l'upgrade di una pipeline di streaming utilizzando funzionalità come l'esecuzione di un job di sostituzione parallela, vedi Risoluzione dei problemi relativi agli upgrade delle pipeline di streaming.
Aggiornamento dell'imbracatura Runner v2
Il seguente messaggio informativo viene visualizzato nei log dei job di un job Runner v2
The Dataflow RunnerV2 container image of this job's workers will be ready for update in 7 days.
Ciò significa che la versione del processo di runner harness verrà aggiornata automaticamente 7 giorni dopo la consegna iniziale del messaggio, con conseguente breve pausa nell'elaborazione. Se vuoi controllare quando si verifica questa pausa, consulta Aggiornare una pipeline esistente per avviare un job di sostituzione che avrà la versione più recente dell'infrastruttura di esecuzione.
Errori del worker
Le sezioni seguenti contengono errori comuni dei worker che potresti riscontrare e i passaggi per risolverli o risolverli.
La chiamata dall'infrastruttura di lavoro Java a Python DoFn non riesce e viene visualizzato un errore
Se una chiamata dall'harness worker Java a un DoFn Python non va a buon fine, viene visualizzato un messaggio di errore pertinente.
Per esaminare l'errore, espandi la voce del log degli errori di Cloud Monitoring ed esamina il messaggio di errore e la traccia dello stack. Ti mostra il codice che non è stato eseguito correttamente, in modo che tu possa correggerlo se necessario. Se ritieni che l'errore sia un bug di Apache Beam o Dataflow, segnala il bug.
EOFError: marshal data too short
Nei log del worker viene visualizzato il seguente errore:
EOFError: marshal data too short
Questo errore si verifica a volte quando i worker della pipeline Python esauriscono lo spazio su disco.
Per risolvere il problema, consulta Nessuno spazio libero sul dispositivo.
Impossibile collegare il disco
Quando tenti di avviare un job Dataflow che utilizza VM C3� con Persistent Disk, il job non riesce e viene visualizzato uno o entrambi i seguenti errori:
Failed to attach disk(s), status: generic::invalid_argument: One or more operations had an error
Can not allocate sha384 (reason: -2), Spectre V2 : WARNING: Unprivileged eBPF is enabled with eIBRS on...
Questi errori si verificano quando utilizzi le VM C3 con un tipo di Persistent Disk non supportato. Per saperne di più, consulta Tipi di dischi supportati per la serie C3.
Per utilizzare le VM C3 con il job Dataflow, scegli il tipo di disco worker pd-ssd. Per saperne di più, vedi
Opzioni a livello di lavoratore.
Java
--workerDiskType=pd-ssd
Python
--worker_disk_type=pd-ssd
Vai
disk_type=pd-ssd
Spazio esaurito sul dispositivo
Quando un job esaurisce lo spazio su disco, nei log del worker potrebbe essere visualizzato il seguente errore:
No space left on device
Questo errore può verificarsi per uno dei seguenti motivi:
- Lo spazio libero dell'archiviazione permanente del worker si esaurisce, il che può verificarsi per
uno dei seguenti motivi:
- Un job scarica dipendenze di grandi dimensioni al runtime
- Un job utilizza container personalizzati di grandi dimensioni
- Un job scrive molti dati temporanei sul disco locale
- Quando utilizzi Dataflow Shuffle, Dataflow imposta dimensioni predefinite del disco inferiori. Di conseguenza, questo errore potrebbe verificarsi con i job che passano dallo shuffle basato sui worker.
- Il disco di avvio del worker si riempie perché registra più di 50 voci al secondo.
Per risolvere il problema, segui questi passaggi:
Per visualizzare le risorse disco associate a un singolo worker, cerca i dettagli dell'istanza VM per le VM worker associate al tuo job. Parte dello spazio su disco è utilizzato dal sistema operativo, dai file binari, dai log e dai container.
Per aumentare lo spazio del disco permanente o del disco di avvio, modifica l'opzione della pipeline per le dimensioni del disco.
Tieni traccia dell'utilizzo dello spazio su disco nelle istanze VM worker utilizzando Cloud Monitoring. Consulta la sezione Ricevere metriche delle VM worker dall'agente Monitoring per istruzioni su come configurare questa operazione.
Cerca problemi di spazio sul disco di avvio visualizzando l'output della porta seriale sulle istanze VM worker e cercando messaggi come:
Failed to open system journal: No space left on device
Se hai molte istanze VM worker, puoi creare uno script per eseguire gcloud compute instances get-serial-port-output su tutte contemporaneamente.
Puoi esaminare l'output.
La pipeline Python non va a buon fine dopo un'ora di inattività del worker
Quando utilizzi l'SDK Apache Beam per Python con Dataflow Runner V2 su macchine worker con molti core CPU, utilizza l'SDK Apache Beam 2.35.0 o versioni successive. Se il job utilizza un container personalizzato, utilizza l'SDK Apache Beam 2.46.0 o versioni successive.
Valuta la possibilità di pre-creare il container Python. Questo passaggio può migliorare i tempi di avvio della VM e le prestazioni della scalabilità automatica orizzontale. Per utilizzare questa funzionalità, attiva l'API Cloud Build nel tuo progetto e invia la pipeline con il seguente parametro:
‑‑prebuild_sdk_container_engine=cloud_build.
Per ulteriori informazioni, consulta Dataflow Runner v2.
Puoi anche utilizzare un'immagine container personalizzata con tutte le dipendenze preinstallate.
RESOURCE_POOL_EXHAUSTED
Quando crei una risorsa Google Cloud Platform, si verifica il seguente errore:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers.
ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS: Instance 'INSTANCE_NAME' creation failed: The zone 'projects/PROJECT_ID/zones/ZONE_NAME' does not have enough resources available to fulfill the request. '(resource type:RESOURCE_TYPE)'.
Questo errore si verifica in caso di esaurimento temporaneo delle scorte per una risorsa specifica in una zona specifica.
Per risolvere il problema, puoi attendere o creare la stessa risorsa in un'altra zona.
Come soluzione alternativa, implementa un ciclo di nuovi tentativi per i tuoi job, in modo che quando si verifica un errore di esaurimento delle scorte, il job venga ritentato automaticamente finché le risorse non sono disponibili. Per creare un ciclo di nuovi tentativi, implementa il seguente flusso di lavoro:
- Crea un job Dataflow e recupera l'ID job.
- Esegui il polling dello stato del job finché non è
RUNNINGoFAILED.- Se lo stato del job è
RUNNING, esci dal ciclo di nuovi tentativi. - Se lo stato del job è
FAILED, utilizza l'API Cloud Logging per eseguire query sui log del job per la stringaZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS. Per maggiori informazioni, vedi Utilizzare i log della pipeline.- Se i log non contengono la stringa, esci dal ciclo di nuovi tentativi.
- Se i log contengono la stringa, crea un job Dataflow, recupera l'ID job e riavvia il ciclo di tentativi.
- Se lo stato del job è
Come best practice, distribuisci le risorse su più zone e regioni per tollerare le interruzioni.
Le istanze con acceleratori guest non supportano la migrazione live
L'invio di un job di una pipeline Dataflow non riesce e viene visualizzato il seguente errore:
UNSUPPORTED_OPERATION: Instance <worker_instance_name> creation failed:
Instances with guest accelerators do not support live migration
Questo errore può verificarsi quando hai richiesto un tipo di macchina worker con acceleratori hardware, ma non hai configurato Dataflow per utilizzare gli acceleratori.
Utilizza l'opzione di servizio --worker_accelerator Dataflow o il
suggerimento per le risorse accelerator per
richiedere acceleratori hardware.
Se utilizzi i modelli flessibili, puoi utilizzare l'opzione --additionalExperiments per
fornire le opzioni del servizio Dataflow. Se eseguita correttamente, l'opzione
worker_accelerator si trova nel riquadro Informazioni job del job nella
consoleGoogle Cloud .
Quota del progetto… o criteri di controllo dell'accesso che impediscono l'operazione
Si verifica il seguente errore:
Startup of the worker pool in zone ZONE_NAME failed to bring up any of the desired NUMBER workers. The project quota may have been exceeded or access control policies may be preventing the operation; review the Cloud Logging 'VM Instance' log for diagnostics.
Questo errore si verifica per uno dei seguenti motivi:
- Hai superato una delle quote di Compute Engine su cui si basa la creazione dei worker Dataflow.
- La tua organizzazione ha vincoli che vietano alcuni aspetti del processo di creazione dell'istanza VM, ad esempio l'account utilizzato o la zona di destinazione.
Per risolvere il problema, segui questi passaggi:
Esaminare il log dell'istanza VM
- Vai al visualizzatore Cloud Logging
- Nell'elenco a discesa Risorsa sottoposta ad audit, seleziona Istanza VM.
- Nell'elenco a discesa Tutti i log, seleziona compute.googleapis.com/activity_log.
- Scansiona il log per individuare eventuali voci relative all'errore di creazione dell'istanza VM.
Controlla l'utilizzo delle quote di Compute Engine
Per visualizzare l'utilizzo delle risorse Compute Engine rispetto alle quote di Dataflow per la zona di destinazione, esegui questo comando:
gcloud compute regions describe [REGION]Esamina i risultati delle seguenti risorse per verificare se qualcuna supera la quota:
- CPUS
- DISKS_TOTAL_GB
- IN_USE_ADDRESSES
- INSTANCE_GROUPS
- ISTANZE
- REGIONAL_INSTANCE_GROUP_MANAGERS
Se necessario, richiedi una modifica della quota.
Esamina i vincoli dei criteri dell'organizzazione
- Vai alla pagina Policy dell'organizzazione.
- Esamina i vincoli di quelli che potrebbero limitare la creazione di istanze VM per l'account che stai utilizzando (per impostazione predefinita, il service account Dataflow) o nella zona di destinazione.
- Se hai una policy che limita l'utilizzo di indirizzi IP esterni, disattiva gli indirizzi IP esterni per questo job. Per ulteriori informazioni sulla disattivazione degli indirizzi IP esterni, consulta Configurare l'accesso a internet e le regole firewall.
Timeout durante l'attesa di un aggiornamento dal worker
Quando un job Dataflow non va a buon fine, si verifica il seguente errore:
Root cause: Timed out waiting for an update from the worker. For more information, see https://cloud.google.com/dataflow/docs/guides/common-errors#worker-lost-contact.
Diverse cause possono portare a questo errore, tra cui:
- Sovraccarico di worker
- Tenere premuto il tasto di blocco dell'interprete globale
- Configurazione di DoFn a esecuzione prolungata
Sovraccarico del worker
A volte, si verifica un errore di timeout quando il worker esaurisce la memoria o lo spazio di swap. Per risolvere il problema, come primo passo prova a eseguire di nuovo il job. Se il job continua a non riuscire e si verifica lo stesso errore, prova a utilizzare un worker con più memoria e spazio su disco. Ad esempio, aggiungi la seguente opzione di avvio della pipeline:
--worker_machine_type=m1-ultramem-40 --disk_size_gb=500
La modifica del tipo di lavoratore potrebbe influire sul costo fatturato. Per saperne di più, vedi Risolvere gli errori di Dataflow per esaurimento della memoria.
Questo errore può verificarsi anche quando i dati contengono un tasto di scelta rapida. In questo scenario, l'utilizzo della CPU è elevato su alcuni worker per la maggior parte della durata del job. Tuttavia, il numero di worker non raggiunge il massimo consentito. Per saperne di più sui tasti di scelta rapida e sulle possibili soluzioni, consulta Scrivere pipeline Dataflow pensando alla scalabilità.
Per ulteriori soluzioni a questo problema, vedi È stata rilevata una scorciatoia ....
Python: Global Interpreter Lock (GIL)
Se il tuo codice Python chiama il codice C/C++ utilizzando il meccanismo di estensione Python,
controlla se il codice di estensione rilascia il Global Interpreter Lock (GIL) di Python nelle parti di codice
a elevato utilizzo di risorse di calcolo che non accedono allo stato di Python. Se il GIL non viene rilasciato per un periodo di tempo prolungato, potresti visualizzare messaggi di errore come:
Unable to retrieve status info from SDK harness <...> within allowed time e SDK worker appears to be permanently unresponsive. Aborting the SDK.
Le librerie che facilitano le interazioni con estensioni come Cython e PyBind
hanno primitive per controllare lo stato di GIL. Puoi anche rilasciare manualmente il GIL
e riacquisirlo prima di restituire il controllo all'interprete Python utilizzando le
macro Py_BEGIN_ALLOW_THREADS e Py_END_ALLOW_THREADS.
Per saperne di più, consulta Thread State and the Global Interpreter Lock
nella documentazione di Python.
Potrebbe essere possibile recuperare le analisi dello stack di un thread che contiene il GIL su un worker Dataflow in esecuzione nel seguente modo:
# SSH into a running Dataflow worker VM that is currently a straggler, for example:
gcloud compute ssh --zone "us-central1-a" "worker-that-emits-unable-to-retrieve-status-messages" --project "project-id"
# Install nerdctl to inspect a running container with ptrace privileges.
wget https://github.com/containerd/nerdctl/releases/download/v2.0.2/nerdctl-2.0.2-linux-amd64.tar.gz
sudo tar Cxzvvf /var/lib/toolbox nerdctl-2.0.2-linux-amd64.tar.gz
alias nerdctl="sudo /var/lib/toolbox/nerdctl -n k8s.io"
# Find a container running the Python SDK harness.
CONTAINER_ID=`nerdctl ps | grep sdk-0-0 | awk '{print $1}'`
# Start a shell in the running container.
nerdctl exec --privileged -it $CONTAINER_ID /bin/bash
# Inspect python processes in the running container.
ps -A | grep python
PYTHON_PID=$(ps -A | grep python | head -1 | awk '{print $1}')
# Use pystack to retrieve stacktraces from the python process.
pip install pystack
pystack remote --native $PYTHON_PID
# Find which thread holds the GIL and inspect the stacktrace.
pystack remote --native $PYTHON_PID | grep -iF "Has the GIL" -A 100
# Alternately, use inspect with gdb.
apt update && apt install -y gdb
gdb --quiet \
--eval-command="set pagination off" \
--eval-command="thread apply all bt" \
--eval-command "set confirm off" \
--eval-command="quit" -p $PYTHON_PID
Nelle pipeline Python, nella configurazione predefinita, Dataflow presuppone che ogni processo Python in esecuzione sui worker utilizzi in modo efficiente un core vCPU. Se il codice della pipeline aggira le limitazioni GIL, ad esempio utilizzando librerie implementate in C++, gli elementi di elaborazione potrebbero utilizzare risorse di più di un core vCPU e i worker potrebbero non ottenere risorse CPU sufficienti. Per risolvere il problema, riduci il numero di thread sui worker.
Configurazione di DoFn a lunga esecuzione
Se non utilizzi Runner v2, una chiamata a lunga esecuzione a DoFn.Setup
può generare il seguente errore:
Timed out waiting for an update from the worker
In generale, evita operazioni che richiedono molto tempo all'interno di DoFn.Setup.
Errori temporanei durante la pubblicazione nell'argomento
Quando il job di streaming utilizza la modalità di streaming almeno una volta e pubblica in un sink Pub/Sub, nei log del job viene visualizzato il seguente errore:
There were transient errors publishing to topic
Se il job viene eseguito correttamente, questo errore è benigno e puoi ignorarlo. Dataflow ritenta automaticamente l'invio dei messaggi Pub/Sub con un ritardo di backoff.
Impossibile recuperare i dati a causa di una mancata corrispondenza del token per la chiave
Il seguente errore indica che l'elemento di lavoro in fase di elaborazione è stato riassegnato a un altro worker:
Unable to fetch data due to token mismatch for key
Ciò si verifica più comunemente durante la scalabilità automatica, ma può accadere in qualsiasi momento. Qualsiasi attività interessata verrà ritentata. Puoi ignorare questo errore.
Problemi di dipendenza Java
Classi e librerie incompatibili possono causare problemi di dipendenza Java. Quando la pipeline presenta problemi di dipendenza Java, potrebbe verificarsi uno dei seguenti errori:
NoClassDefFoundError: questo errore si verifica quando un'intera classe non è disponibile durante il runtime. Può essere causato da problemi di configurazione generali o da incompatibilità tra la versione protobuf di Beam e i proto generati di un client (ad esempio, questo problema).NoSuchMethodError: questo errore si verifica quando la classe nel classpath utilizza una versione che non contiene il metodo corretto o quando la firma del metodo è cambiata.NoSuchFieldError: questo errore si verifica quando la classe nel classpath utilizza una versione che non ha un campo richiesto durante l'esecuzione.FATAL ERROR in native method: questo errore si verifica quando una dipendenza integrata non può essere caricata correttamente. Quando utilizzi uber JAR (shaded), non includere librerie che utilizzano firme (come Conscrypt) nello stesso JAR.
Se la pipeline contiene codice e impostazioni specifici per l'utente, il codice non può contenere versioni miste di librerie. Se utilizzi una libreria di gestione delle dipendenze, ti consigliamo di utilizzare l'elenco dei materiali delle librerie di Google Cloud Platform.
Se utilizzi l'SDK Apache Beam, per importare la BOM delle librerie corrette,
utilizza beam-sdks-java-io-google-cloud-platform-bom:
Maven
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.beam</groupId>
<artifactId>beam-sdks-java-google-cloud-platform-bom</artifactId>
<version>BEAM_VERSION</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Gradle
dependencies {
implementation(platform("org.apache.beam:beam-sdks-java-google-cloud-platform-bom:BEAM_VERSION"))
}
Per saperne di più, consulta Gestire le dipendenze delle pipeline in Dataflow.
InaccessibleObjectException in JDK 17 e versioni successive
Quando esegui pipeline con le versioni 17 e successive del Java Platform, Standard Edition Development Kit (JDK), potrebbe essere visualizzato il seguente errore nei file di log del worker:
Unable to make protected METHOD accessible:
module java.MODULE does not "opens java.MODULE" to ...
Questo problema si verifica perché a partire dalla versione 9 di Java, sono necessarie opzioni della macchina virtuale Java (JVM) del modulo aperto per accedere ai dettagli interni di JDK. In Java 16 e versioni successive, le opzioni JVM del modulo open sono sempre necessarie per accedere agli elementi interni di JDK.
Per risolvere il problema, quando passi i moduli alla pipeline Dataflow da aprire, utilizza il formato
MODULE/PACKAGE=TARGET_MODULE(,TARGET_MODULE)*
con l'opzione della pipeline jdkAddOpenModules. Questo formato
consente l'accesso alla libreria necessaria.
Ad esempio, se l'errore è
module java.base does not "opens java.lang" to unnamed module @...,
includi la seguente opzione della pipeline quando esegui la pipeline:
--jdkAddOpenModules=java.base/java.lang=ALL-UNNAMED
Per saperne di più, consulta la documentazione della classe
DataflowPipelineOptions.
Errore durante la segnalazione dell'avanzamento dell'elemento di lavoro
Per le pipeline Java, se non utilizzi Running V2, potresti visualizzare il seguente errore:
Error reporting workitem progress update to Dataflow service: ...
Questo errore è causato da un'eccezione non gestita durante un aggiornamento
dell'avanzamento di un elemento di lavoro, ad esempio durante la suddivisione di un'origine. Nella maggior parte dei casi, se il codice utente di Apache Beam genera un'eccezione non gestita, l'elemento di lavoro non va a buon fine e la pipeline non viene eseguita.Tuttavia, le eccezioni in Source.split vengono eliminate perché questa parte del codice si trova al di fuori di un elemento di lavoro. Di conseguenza, viene registrato solo un log errori.
Questo errore di solito è innocuo se si verifica solo a intermittenza. Tuttavia,
valuta la possibilità di gestire le eccezioni in modo controllato all'interno del codice Source.split.
Errori del connettore BigQuery
Le sezioni seguenti contengono errori comuni del connettore BigQuery che potresti riscontrare e i passaggi per risolverli o risolverli.
quotaExceeded
Quando utilizzi il connettore BigQuery per scrivere in BigQuery utilizzando gli inserimenti in streaming, la velocità effettiva di scrittura è inferiore al previsto e potrebbe verificarsi il seguente errore:
quotaExceeded
La velocità effettiva ridotta potrebbe essere dovuta al fatto che la pipeline supera la quota di inserimento di flussi di dati BigQuery disponibile. In questo caso, i messaggi di errore
relativi alle quote di BigQuery vengono visualizzati nei log dei worker Dataflow (cerca gli errori quotaExceeded).
Se visualizzi errori quotaExceeded, per risolvere il problema:
- Quando utilizzi l'Apache Beam SDK per Java, imposta l'opzione del sink BigQuery
ignoreInsertIds(). - Quando utilizzi l'SDK Apache Beam per Python, utilizza l'opzione
ignore_insert_ids.
Queste impostazioni ti rendono idoneo per un throughput di inserimento di flussi di dati di BigQuery di 1 GB al secondo per progetto. Per ulteriori informazioni sulle limitazioni relative alla deduplicazione automatica dei messaggi, consulta la documentazione di BigQuery. Per aumentare la quota di inserimento di flussi di dati di BigQuery oltre 1 GBps, invia una richiesta tramite la console Google Cloud .
Se non vedi errori relativi alla quota nei log dei worker, il problema potrebbe essere che i parametri predefiniti relativi al bundling o al batching non forniscono un parallelismo adeguato per la scalabilità della pipeline. Puoi modificare diverse configurazioni relative al connettore BigQuery Dataflow per ottenere il rendimento previsto durante la scrittura in BigQuery utilizzando gli inserimenti in streaming. Ad esempio, per l'SDK Apache Beam per Java, modifica
numStreamingKeys in modo che corrisponda al numero massimo di worker e valuta la possibilità di
aumentare insertBundleParallelism per configurare il connettore BigQuery in modo da
scrivere in BigQuery utilizzando più thread paralleli.
Per le configurazioni disponibili nell'SDK Apache Beam per Java, vedi BigQueryPipelineOptions, mentre per le configurazioni disponibili nell'SDK Apache Beam per Python, vedi la trasformazione WriteToBigQuery.
rateLimitExceeded
Quando utilizzi il connettore BigQuery, si verifica il seguente errore:
rateLimitExceeded
Questo errore si verifica se vengono inviate troppe
richieste API
a BigQuery in un breve periodo di tempo. BigQuery ha limiti di quota a breve termine.
È possibile che la pipeline Dataflow superi temporaneamente una quota di questo tipo. In questo scenario,
le richieste API
dalla pipeline Dataflow a BigQuery potrebbero non riuscire, il che
potrebbe comportare errori rateLimitExceeded nei log dei worker.
Dataflow riprova a eseguire queste operazioni non riuscite, quindi puoi ignorare
questi errori. Se ritieni che la tua pipeline sia interessata da errori
rateLimitExceeded, contatta l'assistenza clienti Google Cloud.
Errori vari
Le sezioni seguenti contengono errori vari che potresti riscontrare e i passaggi per risolverli o risolverli.
Impossibile allocare sha384
Il job viene eseguito correttamente, ma nei log del job viene visualizzato il seguente errore:
ima: Can not allocate sha384 (reason: -2)
Se il job viene eseguito correttamente, questo errore è benigno e puoi ignorarlo. A volte le immagini di base delle VM worker producono questo messaggio. Dataflow risponde e risolve automaticamente il problema sottostante.
Esiste una richiesta di funzionalità per modificare il livello di questo messaggio
da WARN a INFO. Per saperne di più, consulta
Riduzione del livello di log di errore di avvio del sistema Dataflow a WARN o INFO.
Errore durante l'inizializzazione del plugin dinamico prober
Il job viene eseguito correttamente, ma nei log del job viene visualizzato il seguente errore:
Error initializing dynamic plugin prober" err="error (re-)creating driver directory: mkdir /usr/libexec/kubernetes: read-only file system
Se il job viene eseguito correttamente, questo errore è benigno e puoi ignorarlo. Questo errore si verifica quando il job Dataflow tenta di creare una directory senza le autorizzazioni di scrittura necessarie e l'attività non va a buon fine. Se il job ha esito positivo, la directory non era necessaria oppure Dataflow ha risolto il problema sottostante.
Esiste una richiesta di funzionalità per modificare il livello di questo messaggio
da WARN a INFO. Per saperne di più, consulta
Riduzione del livello di log di errore di avvio del sistema Dataflow a WARN o INFO.
Oggetto non trovato: pipeline.pb
Quando elenchi i job utilizzando l'opzione
JOB_VIEW_ALL, si verifica
il seguente errore:
No such object: BUCKET_NAME/PATH/pipeline.pb
Questo errore può verificarsi se elimini il file pipeline.pb dai file di gestione temporanea
per il job.
Ignorare la sincronizzazione del pod
Il job viene eseguito correttamente, ma nei log del job viene visualizzato uno dei seguenti errori:
Skipping pod synchronization" err="container runtime status check may not have completed yet"
Oppure:
Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
Se il job viene eseguito correttamente, questi errori sono benigni e puoi ignorarli.
Il messaggio container runtime status check may not have completed yet si verifica
quando kubelet di Kubernetes salta la sincronizzazione dei pod perché
attende l'inizializzazione del runtime del container. Questo scenario si verifica
per diversi motivi, ad esempio quando il runtime del container è stato avviato
di recente o è in fase di riavvio.
Quando il messaggio include PLEG is not healthy: pleg has yet to be successful,
kubelet attende che il generatore di eventi del ciclo di vita del pod (PLEG) diventi
integro prima di sincronizzare i pod. PLEG è responsabile della generazione di eventi
utilizzati da kubelet per monitorare lo stato dei pod.
Esiste una richiesta di funzionalità per modificare il livello di questo messaggio
da WARN a INFO. Per saperne di più, consulta
Riduzione del livello di log di errore di avvio del sistema Dataflow a WARN o INFO.
Consigli
Per indicazioni sui suggerimenti generati da Dataflow Insights, consulta Insight.